从PDF提取内嵌字体的一些尝试和方法(文中有Python读取字体的PostScript名称等信息、Python自动化操作FontForge修改字体的脚本,需想学习下修改系统字体的可以进来了解下)
最近客户和我们提出一个标签唛头字体不正确的问题,用Adobe Illustrator打开后提示没有字体,之前我没有注意,直接导入了Adobe Illustrator替换的缺省字体,导致唛头的条码下面数字的字体不对了。具体请见下面的对比图:

刚开始接手这个问题的时候,我的想法很简单,就是到网上找一个一样的字体就好了,但是事实上却遇到了一系列的坑,当然我从中也学到了很多,请看我下面的分解教程。
首先,我使用了ChatGPT和Copilot搜索了下,怎么找相同的字体,它们推荐了我一些网站,至于效果,我只能说,如果使常用字体的话,还是有可能找到的比如这个网站
字体下载,字体大全,免费字体下载,在线字体|字客网 (fontke.com) https://www.fontke.com/而下面的这个网站是它的子网站,可以在线识别图片中的字体,并给出相似的字体
https://www.fontke.com/而下面的这个网站是它的子网站,可以在线识别图片中的字体,并给出相似的字体
识字体网-在线图片字体识别扫一扫网站 (likefont.com)
字客网提供了字体名称搜索和字体图片搜索,如果你没有字体,这个网站很推荐,虽然是收费网站,但是如果关注它的公众号,每月24号都能领一个z码,可以免费兑换一个字体,为什么我推荐这个网站那,因为最后我的字体问题,有一半是通过它解决的,因为我不能凭空造出完整的字体,那样工作量太大了。
当然了网上这种网站很多,我只是举个例子,大家还是根据实际情况寻找合适自己的。
接着说下去,我本来想既然已经是AI时代了,这种找字体的网站,必定能找到我需要的字体,但是实际并不是我想象的这么简单的,因为字体的差别其实是很大的,就是同一个名字的字体,还有不同的版本,甚至同一个版本也可能因为修改过,会也有细微差别。为了此文不要太长,我简单写下,使用这个网站的过程。
我通过上面的https://www.likefont.com/上传了我在PDF原稿标签里截取的数字的图片,并使图片长宽符合网站标准的,并调整了阈值使网站在识别每个字体时,都能显示出完整的字体,填入帮助网站识别的实际数字,请看下图:
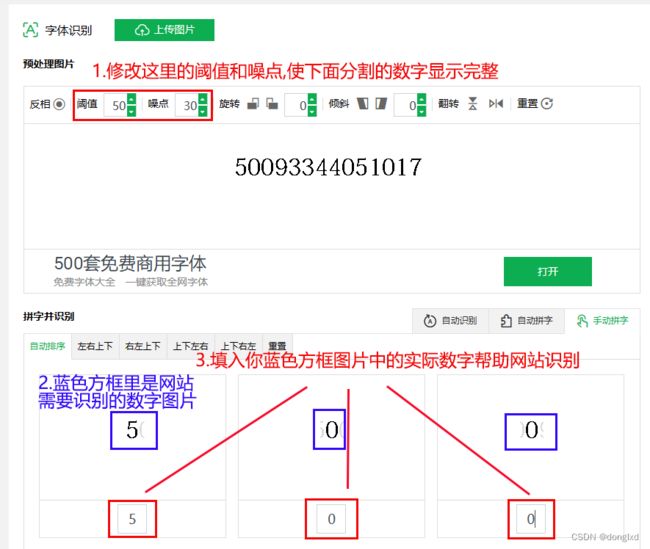
当上面图中的红框中的数字,都按照蓝框的数字填好后,下拉到最后有一个提交按钮,然后就等网站自动识别,我的结果如下:
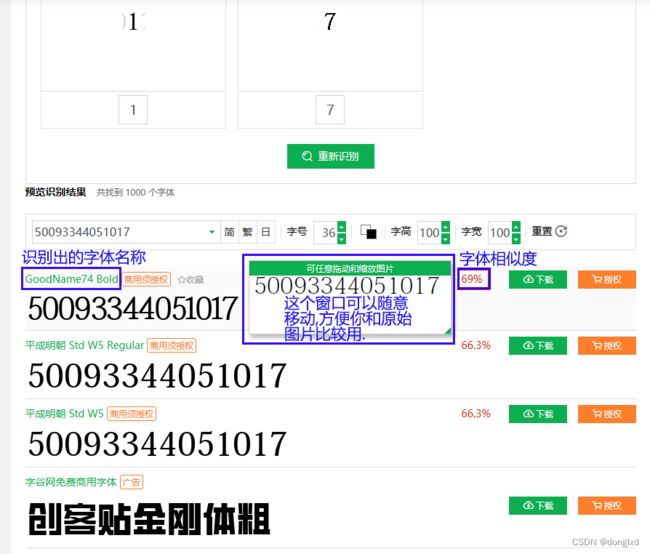
显然网站标注的相似度并没有参考价值,因为第一个字体和我的字体差的有点大(仔细看第一个数字5的上沿角就知道了),继续往下翻一翻,发现有一个字体看上去还有点像,如图:

请记住这个字体名称(ZauriSans Italic R Regular)既然差不多,我就下载下来看看,因为第一次游客下载好像并没有要收费,也不要z码,人品问题?
正当我兴匆匆导入到C:\Windows\Fonts安装字体并打开AI尝试后,发现两种字体还是很点差别的,因为AI打开后字体不对,所以我想了个办法,先用Adobe Acrobat Pro打开原稿PDF文档,放大倍数后,截一张高清条码的高清图片,然后覆盖到AI打开的错误字体的文档中,但是因为条码是图片,所以我只要调整比较后,插入的高清截图文字也就和原稿显示的差不了多少了,这时再把我们设置好的新字体数字调整透明度后叠上去,看看效果。
(PS:其实我事后写此文时,发现如果不用修改条码文字的话,使用高清截图覆盖也不失为一个临时方法,当然了,我今天主要想把我整个解决的思路分享给大家,因为现在进入AI时代后,大家潜意识有一种快消思维,也就是想马上获得一个问题的答案,而不是耐下心来,一步步的解决问题,GPT是没有错,但是我们搞技术的总会碰到GPT,甚至高手一下子解决不了的问题,这时我们就需要越挫越勇的耐心和坚定不移的恒心来解决问题了。)
实际的对比结果如下图:

我这里给大家看的图片是只修改了字体的大小,而没有在AI中修改字符设置,字符设置可以设置字体的长宽比例,我只是想说明一个问题,PDF中的字体也是拉伸过的,就是同一种字体也很难相同,除非是图片.
如上面的图片,大家一定想知道字符设置后的是怎么样的,我给大家看一下:
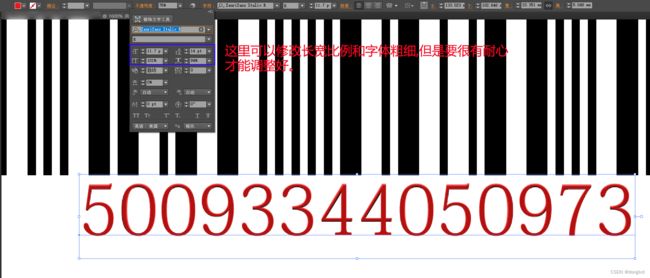
显然如果粗略看的话,相似度已经达到95%,但是把单个数字放大看的话,还是稍微有点点的不同.比如说5和7的上沿,如果是使用AI、PS的文稿绘图人员看到这里也就可以了,但是我们这里是CSDN论坛,不发点代码怎么也说不过去吧,所以程序员请看下面的部分。
下半部分,我将介绍怎么从PDF提取出字体,尽量做到还原原稿,首先,用Adobe Acrobat Pro打开PDF,点击文件-属性。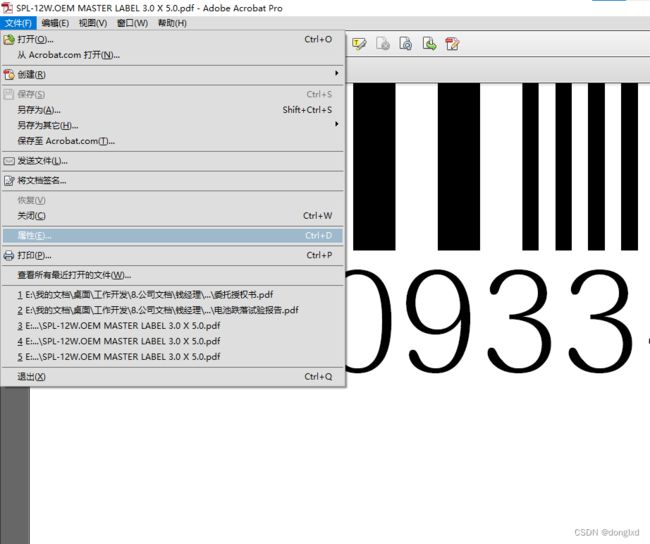
然后在打开的对话框中切换到字体,如图:
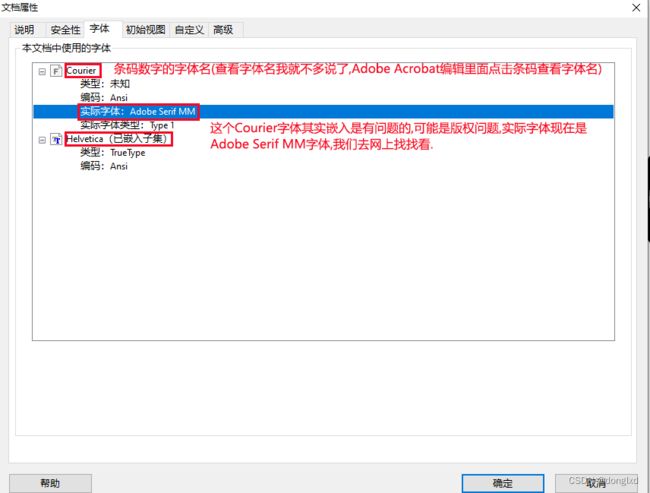
可以看到上图中条码字体是Courier的字体,而且是显示未知类型,下面的Helvetica是唛头中的其他文字字体不做研究.我尝试了下用在线网站和软件都导不出这个Courier字体,需要在线导出字体网站的同学可以看下面:
如何将PDF中的嵌入字体提取为有效字体文件?-腾讯云开发者社区-腾讯云 (tencent.com)https://cloud.tencent.com/developer/ask/sof/74498这个帖子中(http://www.extractpdf.com)这个网站还不叫靠谱点,但是导不出我的Courier字体,因为使用很方便,也就不介绍了。
现在也不管这个Adobe Serif MM是不是老外原始的字体,纯粹研究一下吧!从开始介绍的那个字体网站就能搜索到这个字体,如下链接:Adobe Serif MM-字体搜索-字客网 (fontke.com)
发现有很多版本,输入我的条码数字比较下,发现V0版本还比较像,那就下载试试吧,然后就是扫二维码加公众号,注册并领取z码后等24小时开通账号,来使用这个z码免费下载,请看如下截图们:


下载解压后,如图所示:

这个Adobe Serif MM.otf文件就是我们下载的字体,但是发现后缀没看到过,安装到C:\Windows\Fonts看看,发现记事本、word等都可以用这个字体,但是就是Adobe系列的识别不了,也尝试了下网上千奇百怪的方法,发现都没啥用,既然没方法,就靠自己,因为之前搜索中有一个帖子说,字体的文件名,和字体在AI等软件中显示的名字可能是不一样的,先看看这个字体的实际postscript的名称到底是多少, 本来简单点用fontforge查看的,但是里面的Element-Font Info里写了好几个名称,因为之前没深究过字体也没用过fontforge,不确定哪个是PostScript名称,如图:
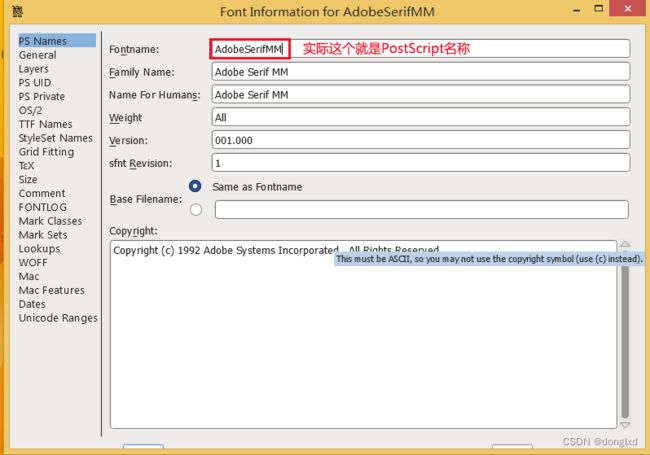
既然不了解,就扫扫盲,找到这个帖子
使用fontTools解析字体文件name数据表_字库文件 加载字体 head cmap glyf bitmap-CSDN博客https://blog.csdn.net/qq_37941538/article/details/123889167
这个作者也牛,用python透彻的分析了字体文件的结构,使用了python的fontTools库,安装方法:
pip install fonttools至于怎么获得PostScrpt的代码,作者只说明了原理,没有写出来,我就自己写了个,如下:
from fontTools.ttLib import TTFont
fontPath = "E:\\我的文档\\桌面\\Adobe Serif MM.otf"#替换你自己的字体路径
fontObj = TTFont(fontPath)
nameTable = fontObj["name"]
oldPlatformID = ""
b = ""
for s in nameTable.names:
if oldPlatformID != s.platformID:
if s.platformID == 0:
print("----------------平台:Unicode----------------")
elif s.platformID == 1:
print("----------------平台:Mac--------------------")
elif s.platformID == 3:
print("----------------平台:Window-----------------")
if s.platformID == 0:
b = "(U) "
elif s.platformID == 1:
b = "(M) "
elif s.platformID == 3:
b = "(W) "
if s.nameID == 0:
print(b,"Copyright:\t",s)
elif s.nameID == 1:
print(b,"Font Family:\t",s)
elif s.nameID == 2:
print(b,"Font Subfamily:\t",s)
elif s.nameID == 3:
print(b,"Unique font identifier:\t",s)
elif s.nameID == 4:
print(b,"Full font name:\t",s)
elif s.nameID == 5:
print(b,"Version:\t",s)
elif s.nameID == 6:
print(b,"PostScript:\t",s)
print("--------------------------------------------")
oldPlatformID = s.platformID
运行结果如下图:
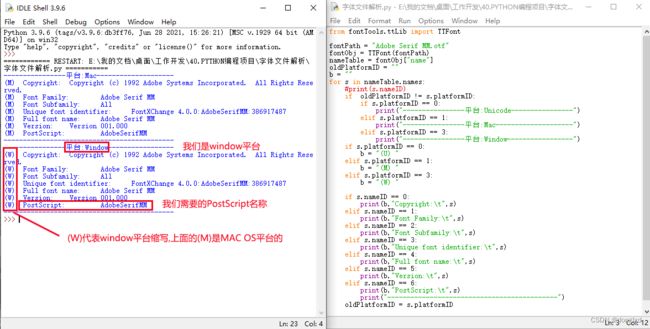
所以我们这个字体的AI中的名称应该为AdobeSerifMM,找了下,还是没有,不过这个脚本还是提供给大家研究。
既然此路走不通,喝口茶再想想吧。
刚刚在AI文件中翻来翻去的找,我突然看到了熟悉的一个名字,如图:

突然,一个奇妙的思路出现,既然AI找不到AdobeSerifMM,把这个AdobeSerifMM里的字体用FontForge替换到ZauriSans Italic R里面不就好了。然后,我在FontForge这个软件中(官方网站是这个FontForge 开源字体编辑器)一番尝试,找到基本方法,如下:
1.打开需要复制的字体文件(如:AdobeSerifMM)选中一个字符(需要导出的原字体AdobeSerifMM字符),比如说5,然后右击,在菜单中选择New outline Window
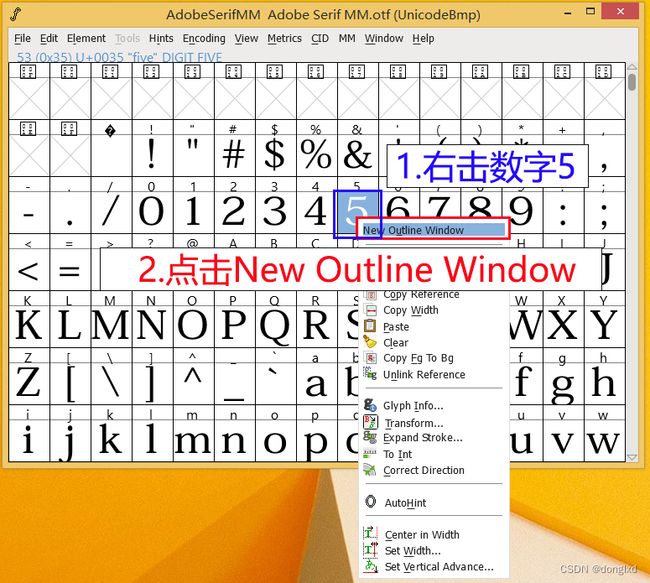
然后在弹出的窗口,点击File-Export导出数字5
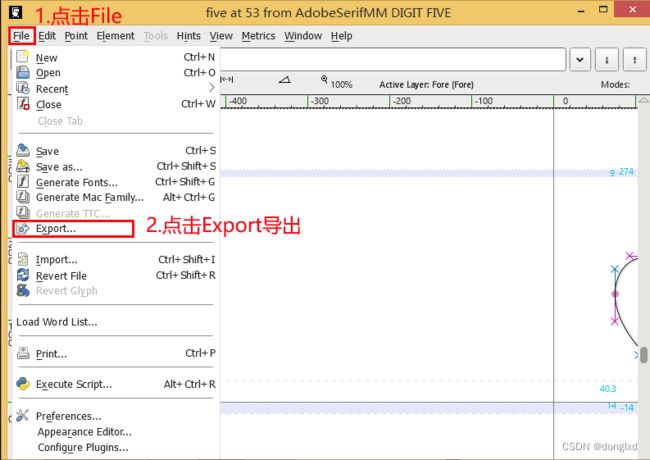
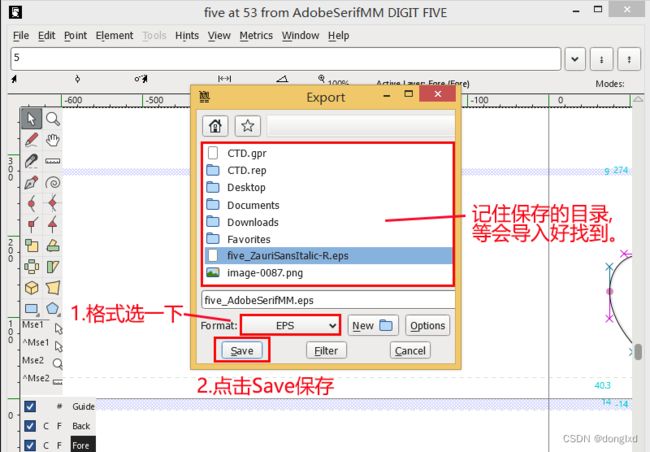
格式选择为EPS,点击Save保存.(因为这个软件没有中文,所以目录都是英文的,请记住保存目录,一般在我的文档中)

然后再打开刚刚我们AI中能识别的字体ZauriSansItalic-Regular.otf,点击下数字5,再点击File-Import导入.
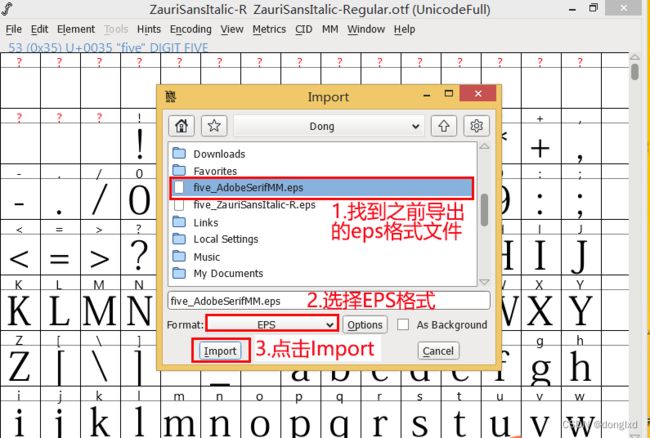
找到之前导出的EPS格式文件目录,选择导出格式为EPS格式,点击Import。
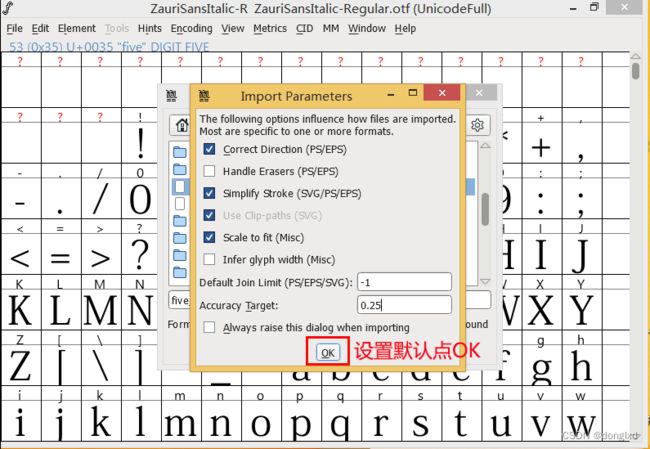 这里导入选项默认即可。
这里导入选项默认即可。 
可以比较下5傍边的4和6高度和宽度上字体都有点不一样,说明这个方法可行。
看了下FontForge的文档,好像支持Python,既然上面的方法可以字符互导, 我们用Python自动化操作看看,能不能成功。
与GPT一番扯皮后,有了基础代码,然后加了循环0-9数字并调试成功的代码如下:
import fontforge
import os
import tempfile # 导入tempfile模块
def setStr(source_font,font,code):
# 将源字体中的字符如“A”复制到一个变量中
source_glyph = source_font[code]
#如果不知道你的字符是什么名称请取消下一行注释
#下句代码会返回如(),
#这样你就知道你的字符名是nine,至于code的值可以参照fontforge软件中字符的序列号
#如0可以写成source_font[48],1可以写成source_font[49]
#print(source_glyph)
# 创建临时文件来保存SVG
temp_svg = tempfile.NamedTemporaryFile(suffix='.svg',delete=False)
source_glyph.export(temp_svg.name)
temp_svg.close()
# 如果字符已经存在,先移除它
if code in font:
font.selection.select(code) # 选择字符
font.clear() # 清除选中的字符
# 创建一个新的字形
font.createChar(source_glyph.encoding, code)
# 导入SVG轮廓
font[code].importOutlines(temp_svg.name)
font[code].width = source_glyph.width
font[code].vwidth = source_glyph.vwidth
try:
os.remove(temp_svg.name)
except OSError as e:
print("Error:delete %s : %s" % (temp_svg.name, e.strerror))
def main():
# 打开源字体(包含你想复制的字符)
source_font = fontforge.open('Adobe Serif MM.otf')
print("已读取源文件")
# 目标字体文件目录
target_fonts = 'ZauriSansItalic-Regular.otf'
#
# 遍历目标字体文件并粘贴字符
font = fontforge.open(target_fonts)
print("已读取目标文件")
num = ["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]
# 把源字体中的0-9数字替换到目标字体的0-9
for i in range(0,10):
print("数字" + str(i) + ": 替换中...")
setStr(source_font,font,num[i])
print("已完成")
#setStr(source_font,font,48)#测试数字0的另一种写法,只供调试code值所用,实际运行
#后面代码会报错.注意需把第12行代码取消注释,才能使用这个功能
# 保存更改
font.generate(target_fonts)
print("已更新文件")
font.close()
# 关闭源字体文件
source_font.close()
print("已关闭文件")
if __name__ == "__main__":
main()
编写代码时,有个坑,就是数字0-9的code变量都是英文(也就是num = ["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]),而A-Z的因为还是A-Z。
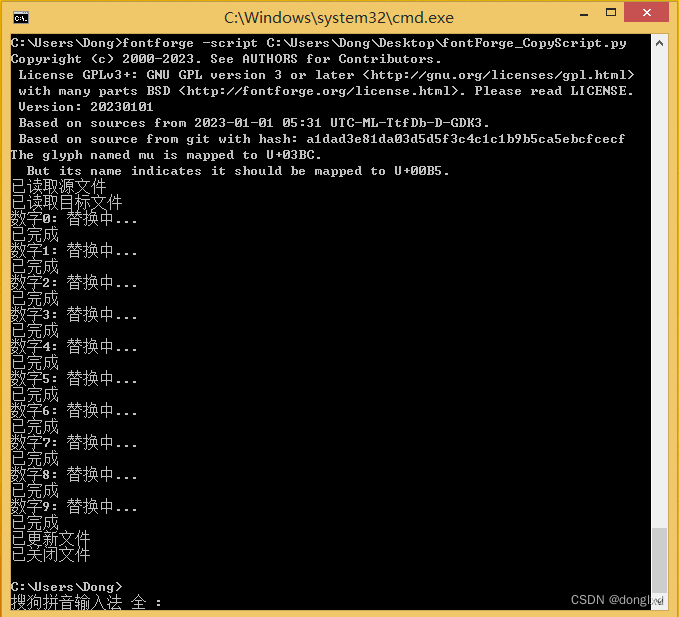
FontForge运行脚本的方法比较特殊,有两种,一种是在主程序的File菜单里选择Execute Script,然后把代码复制到框里运行,下面选择Python模式,但是这个方式的弊端就是看不出python脚本出错的位置,不方便调试。另一种是WINDOW命令提示符运行,如下格式:
fontforge -script C:\Users\Dong\Desktop\fontForge_CopyScript.py-script后的参数填写自己保存的py格式python脚本目录就可以了.如下图运行成功的截图:
(PS:注意代码中需传入自己的字体文件目录名,默认是在你window的USER目录,也就是你的用户名目录)
既然有了文件,把之前的老的ZauriSansItalic-Regular.otf,在C:\Windows\Fonts中删除掉,安装替换新数字的ZauriSansItalic-Regular.otf即可。
打开AI后,可以看到有着Adobe Serif MM数字的ZauriSansItalic-Regular.otf加载成功了,说明这个方法可行。我做了个对比图,比较替换前后ZauriSansItalic-Regular.otf的符合率.


显然原版的ZauriSansItalic-Regular.otf字体更符合PDF原档显示的字体,但是和老外原稿还是有点稍微不同,字体比较粗,可能是AI字符比例还没有到最佳状态,这就是后话了.
当然我们不是做了白用功,我们还是通过这个案例学到了很多python的运用,开拓了视野,任何知识学了总是有用的,说不定哪天你就会派到用处了,到时你就会感到,你今天看的东西物有所值了,谢谢耐心的粉丝能看完,你已经赢了!