ICLR2024:Adobe研究院开发出无扩散的生成式3D大模型
论文标题:
LRM: LARGE RECONSTRUCTION MODEL FOR SINGLE IMAGE TO 3D
论文作者:
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, Hao Tan
**导读:**Adobe Research与澳大利亚国立大学的研究人员合作开发了一种名为LRM的新型AI大模型。该模型具有惊人的能力,仅需5秒钟就能将2D图像转化为高质量的3D模型。这项工作也是首个具有5亿个可学习参数的大规模三维重建模型。LRM能够在短短的5秒内,通过单个输入图像预测物体的3D模型,并通过海量的多视图数据集(约100万个对象)进行端到端训练,以生成高质量的3D重建结果!©️【深蓝AI】编译
1. 工作概述
研究人员提出了一个大型重建模型(LRM),它可以在短短5秒内从单张输入图像中生成对应物体的三维模型。这项工作与以前许多在小规模数据集上训练的ShapeNet等方法相比,LRM采用了一种高度可扩展的基于具有5亿个可学习参数的transformer架构,直接从输入图像中推理NeRF三维表达。研究者在包含大约100万对象的大量多视图数据上以端到端方式训练模型,这种高容量模型和大规模训练数据的结合使得到的模型具有高度的可泛化性,并从各种数据测试输入中产生高质量的三维重建。
▲视频|手机拍摄生成(整小点排成一排)©️【深蓝AI】编译
▲视频|Iamgenet数据集图片生成(整小点排成一排)©️【深蓝AI】编译
2. 关键技术
 ▲图1|pipeline图©️【深蓝AI】编译
▲图1|pipeline图©️【深蓝AI】编译
LRM的整体架构是一个基于完全可微的transformer的编码器-解码器框架,用于单图像到NeRF重建。LRM应用一个预先训练过的视觉模型(DINO)来对输入的图像进行编码,其图像特征通过交叉注意由一个大型transformer解码器投影到三维三平面空间进行表示。然后使用多层感知器来预测体积渲染的点颜色和密度。整个网络使用简单的图像重建损失对大约100万个3D数据进行端到端训练。
●图像编码器:
使用一个经过自蒸馏训练的模型DINO,用它来学习对图像中显著内容的结构和纹理。相比其他面向语义的表示等视觉特征ImageNet预训练ResNet或CLIP,精细的结构和纹理信息更重要,因为后续LRM要使用它来重建三维空间的几何和颜色。
●图像到三平面解码器:
研究人员实现了一个基于transformer的解码器,将图像和编码器捕捉的特征投射到可学习的空间位置编码上,并将它们转换为三平面表示。这个解码器是一个先验网络,用大规模的数据进行训练,以提供必要的几何和外观信息,来补偿单图像重建的模糊性。
3. 实验效果
评估LRM的性能任意图像,研究人员图像重建数据来自 Objaverse, MvImgNet, ImageNet, Google Scanned Objects, Amazon Berkeley Objects , 真实世界拍摄的图片以及使用Adobe Firefly工具生成的。
下图可视化了一些从单个图像中进行重建的示例(包括在各种数据集下,具有不同纹理的不同主题的真实、生成和渲染图像)。示例中不仅复杂的几何模型被正确地建模(如椅子、盘子和擦拭),而且模型最终也保存了物体图片上的高频细节,如木孔雀的纹理。从长颈鹿、企鹅和熊等例子。并且我们能够看到,LRM可推断出语义上合理的形状遮挡部分,这意味着已经学习了有效的交叉形状先验,都反映了该模型的强大的泛化能力。
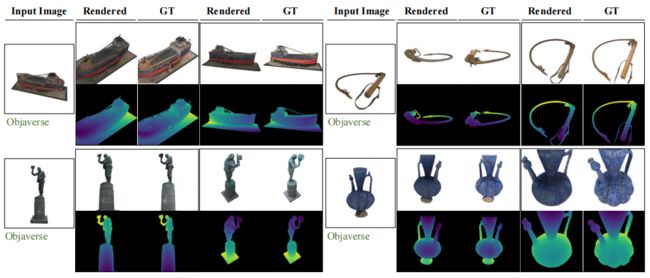

 ▲图2|各个数据集生成实验©️【深蓝AI】编译
▲图2|各个数据集生成实验©️【深蓝AI】编译
研究人员将LRM与通过使用二维扩散模型生成多视图图像的One-2-3-45进行了比较,可以看到,LRM产生了更清晰的细节和一致的表面。在图的最后一行中,两个例子测试了One-2-3-45显示了更糟糕的重建结果。
 ▲图3|与 One-2-3-45对比©️【深蓝AI】编译
▲图3|与 One-2-3-45对比©️【深蓝AI】编译
4. 总结与未来展望
LRM在训练和推理方面非常有效;它是一个完全可微的网络,可以端到端训练,需要简单的图像重建损失,只需5秒就可以呈现高保真的3D形状,从而可以广泛应用于现实中。在大规模学习的时代,这种研究思路能够激发未来的研究,以探索数据驱动的三维大型重建模型,这些模型可以很好地推广到任意的拍摄图像。
未来的研究方向主要在两方面:
1)扩大模型和训练数据:最简单的设计和最小正则化,LRM可以很容易地扩展到一个更大、更深的网络,包括但不限于应用一个更大的图像编码器,增加更多的注意力层图像三平面解码器,提高三平面表示的分辨率。另一方面,LRM只需要多视图图像进行监督,因此可以在训练中利用广泛的三维、视频和图像数据集。研究人员希望这两种方法在提高模型的泛化能力和重建质量方面都有良好的前景。
2)对多模态三维生成模型的扩展:LRM模型通过利用文本到图像的生成模型首先创建2维图像,构建了从语言生成新的三维形状的路径。研究人员建议学习到的表达性三平面表示可以直接应用于搭建从文本描述到生成3D模型,以实现高效的文本到3D的生成和编辑。
编译|Northeast corn
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。