51-13 多模态论文串讲—BEiT v3 论文精读
BEiT-3的核心思想是将图像建模为一种语言,这样我们就可以对图像、文本以及图像-文本对进行统一的mask modeling。Multi-way transformer模型可以有效地完成不同的视觉和视觉语言任务,使其成为通用建模的一个有效选择。
同时,本文也对多模态大模型作了一个简单的总结。
接下来,我们来看BEiT-3论文,题目是Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks。BEiT-3的这个目标,非常明确,他就是想做一个更大一统框架,不论是从模型上要统一,而且从训练的目标函数上要统一。还有就是模型大小,数据集大小,怎么scale也要统一。作者管这个叫做big convergence。那如果简单用一句话来概括?BEiT-3就是把图像也看成了是一种语言,他们题目的意思说image as foreign language。他们在文章中,把这个image叫做Imglish,文本叫做English,把这个图像文本叫做parallel sentence。这个时候,因为不论是图像还是文本,我都可以用mask modeling去做。不需要ITC、ITM、MLM loss或者Word patch alignment各种loss。那模型层面,他就用的是他们之前VLMo提出的那个MoME。在这篇论文里,作者又重新起了个名字,管他们之前提出的那个框架叫做multi-way transformers,可能是受Google pathway的影响吧。总之到最后,这就是一个非常简单,而且非常容易扩展的一个框架。模型就是multi-way transformer一个,目标函数也就一个mask modeling。但是效果,出奇的好。
我们往下看,BEIT-3采取了CoCa这种多边形图的形式去展现它有到底有多强。

那我们可以看到在这个图里面,作者还新加了蓝色的这个flamingo,然后他们的BEiT-3,就是这个紫色的这条线,完完全全把之前所有的方法,全都包进去了。而且在每个任务上的提升,也都不小。而且最重要的是,BEiT-3这种灵活的结构,就是一个模型,但是它在推理的时候,可以拆成各种各样的部分去做下游任务,就导致它可以做Unimodel的这个图像问题。比如说classification,segmentation,detection,他通都可以做。然后,就是他本来要做的,这种各种各样的多模态的任务,当然language的任务他也是可以做的。只不过这里,之前的工作也没有比,所以他这里也就不用比。那因为BEiT-3的这个效果,也确实是非常强,所以作者在这个图一之后,紧跟着又跟了一个表一,放在了第二页。去具体展示了一下,BEiT-3到底做了任务,然后之前的这个SOTA到底是哪些方法,然后上面具体提升了多少。
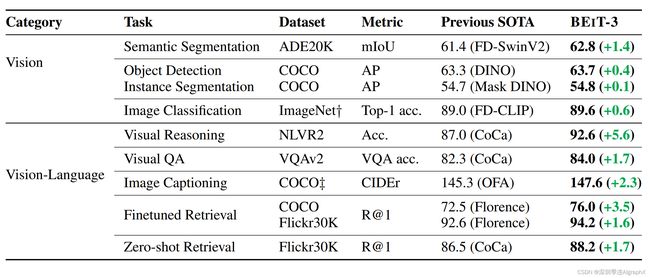
我们这里可以看到,比如说在ADE20K上,BEiT-3就达到62.8,其实到现在为止应该还都是一、二吧,我看paper with code上最高是62.9。然后object detection,在CoCo上也已经刷到了,惊人的是63.7,当然现在好像已经65点几了,大家刷coco的这个积极性还是非常高,目标检测是真卷不动。然后在ImageNet上,BEiT-3达到89.6。你是可能会想,Coca不都已经90多了吗?当时作者在这里打了个记号。说这个性能,SOTA的这个性能,是没有用额外的private data训练,但是,CoCa用了JFT300m,这个Google自己有的数据集,所以别人没法复现。
然后如果看多模态这边,我们也可以发现,像NLVR2这个数据集上,这个BEiT-3比之前的CoCa高了5.6个点,这个提升是非常恐怖的,而且别的几个多模态任务,这个BEiT-3表现也都非常。所以说别看BEiT-3就是一个模型结构,只用了一个目标函数,而且它的数据,也没有用很多,微软真的是很亲民。他这篇文章专门还强调了,他使用的这个预训练数据集,全都是public data set,都是你可以下到的,您是可以去得到差不多一样的数据集,然后去复现它的模型的。
所以这个从侧面说明了两个问题,第一个,就是说不是目标函数越多越好,不是说你给他加更多的regularization,它这个模型就一定会训练的更好,还是得看loss之间,有没有互相弥补的特性。而且还有就是你这个当模型变大,数据变大的时候,你还需不需要其他的这个loss函数,那比如说CLIP,也就用了这个对比学习就训练的很好了。那BEiT-3,就用mask model也就训练很好了。所以真的是越简单的方法,它skill越好,而且越能应用。第二个,就是说数据也不一定是越多越好,那CoCa,就用了10倍于训练CLIP的数据量,可能几十倍于BEiT-3用的这个数据量,但BEiT-3的这个性能,还反超了Coa,所以更多时候,这个数据的质量是非常关键。
BEiT-3,其实从方法上来说,它就是之前,BEiT,BEiT v2,VLBEiT,VLMo,他们一系列的工作的一个集合体。本身,它其实没有提出什么新的东西,都是在之前的工作里,都已经提到过了,这篇就是把它做大做强。 展示了一下,到底一个unified framework,达到一个什么样的性能。
那BEiT-3的这个引言部分,真的是写的非常非常好,如果有同学对多模态学习感兴趣,或者接下来想做多模态的研究,那我建议一定要把这个第一段读一下。
作者上来就给这个引言部分起了个标题,叫做the big convergence,就是大一统。
文章说,最近我们观察到,不论是在这个language,还是在vision,还是在这个多模态领域,我们都观测到这个big convergence。就是说我们在超级多的这个数据集上,去做大规模的预训练,一旦这个模型训练好之后,它的这个特征,就已经非常好了,可以直接transfer到这个下游任务上去。那尤其是当你这个模型足够大,数据足够多的时候,你有可能就能训练出来一个有通用性能的一个foundation model。这个foundation model,可能就已经能去解决,各种各样的这个模态,或者各种各样的下游任务了,非常的强大。那foundation model这个概念,其实也就是去年还是前年提出的,基本上22年做大模型的,都喜欢把他们的模型叫做foundation model,所以一瞬间,出来了很多很多的foundation model。那作者说,在这篇工作里,他们就是想把这个大一统,继续往前再推一步,就是彻底把这个多模态,尤其是vision language的这个预训练做得很好,而且主要是从以下的这三个方面来讲这个大一统。
那第一个方面,就是说从这个模型角度来说,这个transformer真的是非常关键。之前我们讲transformer,还有vision transformer的时候,我就说过,我非常喜欢transformer这个结构,原因,不是因为这个结构它有多强,因为最近你看在这个视觉这边的这个CNN和transformer,还在争到底是谁性能更好,或者说谁更适合做这个视觉任务,但这个,其实已经无所谓了。因为未来,肯定是多模态的,未来肯定是一个模型,去做所有的modality,这样去做所有的task,肯定是一个大一统的框架。那在这个大一统的框架下,CNN就不太适合做其他的modality,但是transformer,又适合做很多的modality,所以就从这一点上讲,Transformer已经胜出了。所以作者接下来说,这个transformer刚开始是从NLP那边用的,然后,逐渐用到了这个vision和这个多模态领域。现在,对于这个vision language model,对于多模学习来说,有几个常用的这个方式,比如说,CLIP就是Dual encoder这种的方式,他就非常适合做这种快速的retrieval。还有,就是这种encoder-decoder的框架去做这种generation task,我们刚讲这个BLIP、CoCA这都属于这类。还有,就是这种fusion-encoder architecture,就是只用encoder,有多模态融合部分,ALBEF、VLMo那都属于这一类,他们就能做很好的这个image text encoding。作者说,不论是哪一个方向,这些模型,在遇到这个下游任务的时候,因为这个输入的形式,可能有时候会改变,或者输出的形式,有时候会改变,所以这个模型,就需要根据下游任务去做一些改进,它不是真正意义上的就是训练好一个模型之后,你拿去用就可以了,而是说你训练好这个模型之后,你遇到各种各样的任务,你还得去修改。那这个就还不够方便,而且,离他们说的这种general purpose model,就还有一段距离,所以作者这篇文章里就说,我们想提出BEiT-3,用multi-way transformer,去进一步的往这个方向去push。
接下来,对于这个大一统方向的第二个点,就是这个预训练的目标函数。作者说,其实到目前为止,这个mask data modeling,就已经成功的被应到各个这个modality里了,比如说最开始的完形填空这个BERT,然后Image这边,他们就是自己的这个BEit,还有这个image text pair这边就是他们自己的VLBEiT。总之,就用这种掩码学习,就已经能够很好的去学习图像,文本,或者多模态的这种特征了。那作者这里就想,那我能不能真的就用这一个目标函数,就把这个模型训练的非常好?因为,如果你用更多的这个目标函数,你这个训练速度,肯定会变慢,也就是他这里说的,如果你用其他的这个pretraining objective,比如说ITM的话,你这个当数据和模型变大的时候,计算就不高效了,你就很难去在短时间内训练出来一个大模型。另外也有优化和调参的问题在里面,如果你只有一个loss,那你这个loss weight,就没啥可调的了,但是如果你现在有三四个loss,那这loss和loss之间的weight该怎么调?你是不是得跑好几个大模型去对比一下该选用什么loss weight?那同时,有的loss之间可能互补,有的loss之间可能互斥。比如说之前我们说想让那个ITM工作的更好,我们还得用ITC去帮助他选择Hard negative,然后才能去做ITM,这就无形中增加了很多的复杂度,和很多这种调参度就太人工了,他就不好skill up。所以作者说,在这篇文章中,我们就用了一个这个pretraining task,就是mask then predict。然后我们就把这个图像看成是一个foreign language叫Imglish。因为反正图像过完这个vision transformer embedding以后,它就变成了一个sequence of token,那这样他们就能把这个文本和图像,用同样的方式去处理,本质上就没有任何区别。而且如果这样子去处理,对于这个多模态的这个图像文本来说,也就可以把它看成是一个parallel sentence,就是句子一,后面跟了个句子二,就没有什么不同了,一切,都变成NLP了。当然这也从侧面说明,mask data modeling这个目标函数,真的是非常的强。
最后作者,又讨论一下第三个方面,就是如何把这个模型,还有数据集的这个大小,全都scaling up,因为只有scaling up,用了更多的数据,有一个capacity很大的模型,他才有可能用一个模型去解决所有的事情。所以在BEiT-3里,作者说也把这个模型的size扩展到了B级,而且也把数据集也扩展的非常大,但即使如此,作者团队还是坚持,就使用这种public available的这个data resource。所以学术界,就比较容易去这个复现,非常的难能可贵。
如果我们接下来看BEIT的这个方法本身,也就看这个图。

就会发现,真的很简单,而且它就是VLMo,所以没什么好讲的。那对于模型本身而言,它就是用了这个multi-way transformer,就是之前的这个MoME。它前面的这个自注意力,全都是shared,只有后面这个feed forward network是不一样的。根据不同的modality,我们练不同的expert,这是vision,这是language,这是vision language。然后通过调整,不同的这个input modality,然后去选择这个模型,到底该走哪一支,最后来得到模型的这个输出。至于训练的时候的这个目标函数,就是这个mask data modeling,它有可能是遮住了图像,有可能是遮住了文本,总之就是完形填空,你去这个恢复它就可以了。所以说,非常直接,而且就像VLMo里讲的一样,它也很灵活。
我们现在如果直接去看这个图三

也就是说当一训练完了之后,我们要去做这个下游任务的transfer的时候,作者这里说BEiT-3也非常的强大。如果你只用这边的这个vision encoder,就可以去做所有这个图像这边的任务,包括分类、分割和检测。那如果你只用language这边的encoder,你就可以去做那边的各种任务,反正是用MLM训练出来的,所以BERT能做,BEiT-3都能做。那接下来,就是看多模态了,如果你有vision和language,最后有vision language这种fusion encoder形式,你就比较容易去做这种vison language understanding task,这种VQA,VR这种任务。那如果你想像CLIP一样,去做比较高效的这种image text retrieval,你就可以把这两个vision和language分开做,变成双塔结构。那如果fine tune的话,你还可以再用ITC去fine tune一下就好了。最后,就是如果你做生成,你做captioning这种任务,如像我们讲过BLIP和CoCa,就是文本这边mask,然后你用image grounded这个text encoder去预测这个mask掉的词到底什么,然后可以做image captioning。所以说,BEiT-3,就跟一个积木一样,也就跟一个乐高一样,他每一个训练好的那个transformer block,或者每一个训练好的那个SA或者这个FFN,你都可以随意的去拼和组合,从而达到你想要的各种结果。
那最后,我们可以快速的对多模态大模型做一下总结。
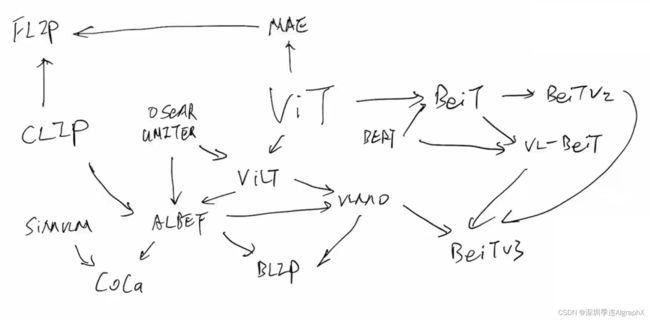
我们可以从最中间的这个vision transform ViT开始说。多模态学习之前,都是OSCAR或者UNITER的这些工作,但他们的缺陷,都是因为里面用了一个object detection的模型,去做这个视觉特征的抽取,这个就太慢,而且太贵了。所以说在vision transformer出来之后,这个ViLT的作者就想到说,我可以把这个vision这边,就用一个vision transformer去代替,就一个embedding层就足够了,这样大大的简化了这个模型结构,所以,结合ViT和这个OSCAR,推出了这个ViLT。
ViLT是ICML 21的工作,Clip也是ICML 21的工作。经过一番这个总结,经验和对比,ALBEF的作者就发现了,说Clip比较高效,适合做这种image text retrieval,原始的这些方法,因为这个Modality fusion做的很好,多模态任务非常强,而这个ViLT这个结构比较简单,所以说最后,综合3家的长处,就推出了ALBEF这么一个fusion encoder的模式,从而取得了不错的结果。
因为ALBEF也release了代码,而且结果不错,模型也比较简单,所以在它之上,又延伸出来了很多工作。那比如说之前,这个SimVLM,就是用encoder,decoder去做多模态的。然后作者在的ALBEF、SimVLM基础上推出了这个CoCa。用contrast和caption两个loss就训练出了一个强大的模型。
那同时,另外一个分支,就是有了这个ViLT,而且有了这个ALBEF之后,微软的研究者,就推出了这个VLMo,就用这个共享参数的方式推出一个统一的做多模态的框架。
然后,基于这种参数共享的思想,基于这种可以用很多很多,这个text branch,作者又推出了这个BLIP模型,能做非常好的这个Capfilter的功能,而且它的capfilter模型,也非常的好用,能够像一个普适的工具一样,用到各种各样的情形中去。
我们再回到这个vision transformer。那vision transformer在他的文章中,也做了mask data modeling的方式,去做self supplied learning,但是当时的效果,不是很好。但是大家,整个community,都觉得mask data modeling是一个非常promising的这个方向,所以大家,就顺着BERT的这个思想,这个微软的研究者就提出了BEiT。当时的口号,就是这是计算机视觉界的BERT Moment。
然后在BEiT的基础上,很快又推出了BEiT v2,但是这个,主要是做这个视觉task,并不是做多模态的。然后,因为BEiT可以在视觉上做mask model,然后BERT,可以在文本上做mask model,作者就想那视觉和文本是不是可以合在一起?所以说,又推出了这个vision language BEiT,即VL-BEiT。
最后,在他们一系列的这个实验,经验的这个积累之下,作者最后把BEiT v2,VLMO和VL-BEiT等3个工作合起来,推出了多模态的BEiT-3,大幅超过了之前的这个CoCa,BLIP在单模态和多模态上的各种表现。
再回到ViT,那对于mask data modeling来说,你也可以mask and predict不同的东西。譬如BEiT就是去predict那个patch。另外耳熟能详的工作MAE,mask auto encoder,就是去mask predict pixel。当然不论是恢复patch还是恢复pixel,其实vision transformer那篇paper,原来它都已经做了,但是效果都不是很好,然后BEiT和MAE,都把这个效果推高到很高的一个高度。然后MAE,它有一个非常好的一个特性,就是说他在视觉那端,他把大量的这个patch,全都给mask之后,他只把那些没有mask的那些patch,扔给了这个vision transform 去学习,这样就大大减少了这个计算量。
那这个东西,当然不是视觉里独有的了,所以就引出了最近新出的另外一篇比较有名的工作,也有很多同学说能不能讲一下这篇FLIP,Facebook新出的论文,就是fast language image prediction。
但其实,他的想法真的是非常非常的直接,就是把MAE的这个有用的这个特性,用到Clip的这个结构里,它的模型就是Clip,没有任何的改变,只不过是在视觉这端,它跟MAE一样,都是只用那些没有mask的token,把那些mask的就删掉了,这样无形之中,就把sequence length降低了很多,所以这个训练就快了,也就是他说的这个fast language image prediction。
当然Flip这篇论文,做了超级多的实验,最后也做了model和data,还有这个训练Schedule上各种这个scaling的实验。所以大家如果有时间,也可以去读一下,但是从方法本身上来说,它就是在Clip的基础上用MAE的思想。
最后,想说的一点,就是多模态学习的进展,实在是太快了,除了我们这两期讲到的这么多多模态的工作之外,最近还有很多非常非常引人入胜的工作。
比如说有一个系列,就是用language去做interface。他的意思就是说,即使你像BLip,VLMO,BEiT-3,这种模型它可以像积木一样,你想做什么任务,你就去拼出来你想要的模型,然后你再去fine tune得到你想要的结果。这个还是不够统一,它不是真正意义上的unified framework,它只是更灵活的把很多模型给拼到一起了,那真正unified,真正大一统的框架到底应该长什么样?当然有很多思路了,其中一个,如说微软的metaLM,还有Google的这个PaLI。他们称模型就是一个encoder decoder,然后有图像的输入,有文本的输入,但是至于这个模型,不论是在预训练的时候,还是在下游任务的时候做什么,完全是由文本那边的prompt决定。它的输出,永远都是文字,就不论你是什么任务,它的输出都是文字,它是一个text generation task。然后这个时候,如果你做VQA,那你的文本,就说我现在在做VQA,这是我的问题,然后你,就生成一个答案给我。那如果你现在是在做图像分类,那你就把图像给他,然后文本那边,你就告诉他prompt说我现在在做分类,然后这时候,他就会把这个图像的这个label,直接给你生成出来,它不是0123456这种label了,它直接就生成,这是狗还是猫,就是这种带有语义的词了,所以就是text generation。它通过调整各种各样的prompt,也就是这里说的这个language interface,就只需要调整的language,那这个模型,就知道你在做什么任务,然后就会给出相应的这个文本的输出,然后来告诉你答案。那在这个意义下?这个模型真的是很少被改动,所以算得上是一个unified framework。
另外,还有一系列工作,最近也是非常的火热,叫做generalist model,翻译过来,可能就叫通才模型,或者通用模型。它也是一个意思,就是说不论是在训练的时候,还是在做下游任务的时候,我都想用一个模型,直接训练好之后做就完了,我不想在根据这个下游任务再去调整我的模型结构,或者再给它加一个task specific head,比如说分类头,检测头,分割头这种。那最近也有一些工作,比如说这个unified-IO,还有Uni-Perceiver v2。虽然说这一系列工作,暂时看起来,它的性能还没有那么的炸裂,那么的好,但是我觉得,在现在这个卷的速度之下,可能也就是今年的NeurIPS,就会出来一系列这种generalist model,不仅模型简单,而且效果,应该也能够超过之前的那种task specific模型。
https://arxiv.org/pdf/2208.10442.pdf
多模态论文串讲·下【论文精读·49】_哔哩哔哩_bilibili