Java 集合List相关面试题

作者简介: 过去日记,致力于Java、GoLang,Rust等多种编程语言,热爱技术,喜欢游戏的博主。
本文收录于java面试题系列,大家有兴趣的可以看一看
相关专栏Rust初阶教程、go语言基础系列、spring教程等,大家有兴趣的可以看一看
Java并发编程系列,设计模式系列、go web开发框架 系列正在发展中,喜欢Java,GoLang,Rust,的朋友们可以关注一下哦!
文章目录
-
- List相关面试题
-
- 数组
-
- 数组概述
- 寻址公式
- 操作数组的时间复杂度
- ArrayList源码分析
-
- 成员变量
- 构造方法
- ArrayList源码分析
- 面试题-ArrayList list=new ArrayList(10)中的list扩容几次
- 面试题-如何实现数组和List之间的转换
- 链表
-
- 单向链表
- 单向链表时间复杂度分析
- 双向链表
- 双向链表时间复杂度分析
- 面试题-ArrayList和LinkedList的区别是什么?
List相关面试题
数组
数组概述
数组(Array)是一种用连续的内存空间存储相同数据类型数据的线性数据结构。
int[] array = {22,33,88,66,55,25};

我们定义了这么一个数组之后,在内存的表示是这样的:

现在假如,我们通过arrar[1],想要获得下标为1这个元素,但是现在栈内存中指向的堆内存数组的首地址,它是如何获取下标为1这个数据的?

寻址公式
为了方便大家理解,我们把数组的内存地址稍微改了一下,都改成了数字,如下图
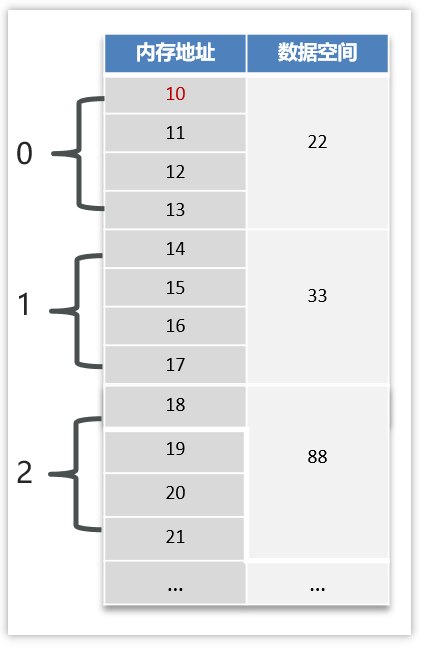
在数组在内存中查找元素的时候,是有一个寻址公式的,如下:
arr[i] = baseAddress + i * dataTypeSize
baseAddress:数组的首地址,目前是10
dataTypeSize:代表数组中元素类型的大小,目前数组重存储的是int型的数据,dataTypeSize=4个字节
arr:指的是数组
i:指的是数组的下标
有了寻址公式以后,我们再来获取一下下标为1的元素,这个是原来的数组
int[] array = {22,33,88,66,55,25};
套入公式:
array[1] =10 + i * 4 = 14
获取到14这个地址,就能获取到下标为1的这个元素了。
操作数组的时间复杂度
1.随机查询(根据索引查询)
数组元素的访问是通过下标来访问的,计算机通过数组的首地址和寻址公式能够很快速的找到想要访问的元素
public int test01(int[] a,int i){
return a[i];
// a[i] = baseAddress + i \* dataSize
}
代码的执行次数并不会随着数组的数据规模大小变化而变化,是常数级的,所以查询数据操作的时间复杂度是O(1)
2. 未知索引查询O(n)或O(log2n)
情况一:查找数组内的元素,查找55号数据,遍历数组时间复杂度为O(n)
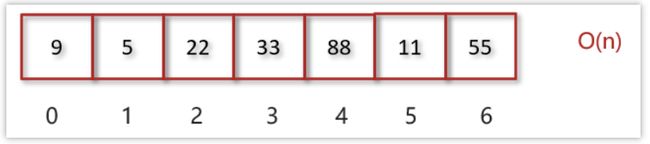
情况二:查找排序后数组内的元素,通过二分查找算法查找55号数据时间复杂度为O(logn)

3.插入O(n)
数组是一段连续的内存空间,因此为了保证数组的连续性会使得数组的插入和删除的效率变的很低。
假设数组的长度为 n,现在如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。如下图所示:

新增之后的数据变化,如下

所以:
插入操作,最好情况下是O(1)的,最坏情况下是O(n)的,平均情况下的时间复杂度是O(n)。
4.删除O(n)
同理可得:如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了,时间复杂度仍然是O(n)。
ArrayList源码分析
分析ArrayList源码主要从三个方面去翻阅:成员变量,构造函数,关键方法
以下源码都来源于jdk1.8
成员变量

DEFAULT_CAPACITY = 10; 默认初始的容量**(CAPACITY)
EMPTY_ELEMENTDATA = {}; 用于空实例的共享空数组实例
DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};用于默认大小的空实例的共享空数组实例
Object[] elementData; 存储元素的数组缓冲区
int size; ArrayList的大小(它包含的元素数量)
构造方法

第一个构造是带初始化容量的构造函数,可以按照指定的容量初始化数组
第二个是无参构造函数,默认创建一个空集合

将collection对象转换成数组,然后将数组的地址的赋给elementData
ArrayList源码分析
添加数据的流程
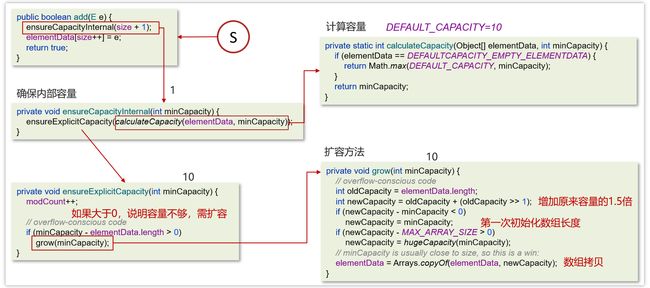
结论:
- 底层数据结构
ArrayList底层是用动态的数组实现的
- 初始容量
ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- 扩容逻辑
ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
-
添加逻辑
-
确保数组已使用长度(size)加1之后足够存下下一个数据
-
计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
-
确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
-
返回添加成功布尔值。
-
面试题-ArrayList list=new ArrayList(10)中的list扩容几次
难易程度:☆☆☆
出现频率:☆☆

参考回答:
该语句只是声明和实例了一个 ArrayList,指定了容量为 10,未扩容
面试题-如何实现数组和List之间的转换
难易程度:☆☆☆
出现频率:☆☆
如下代码:
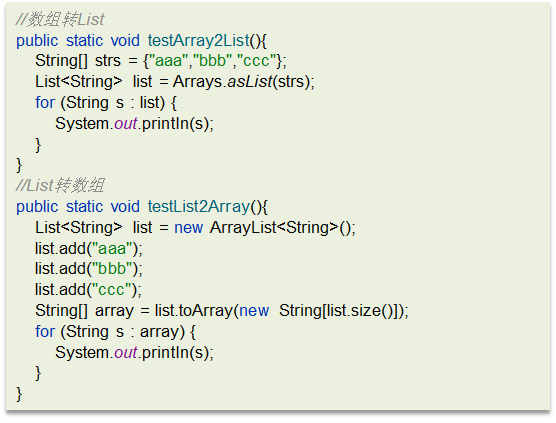
参考回答:
-
数组转List ,使用JDK中java.util.Arrays工具类的asList方法
-
List转数组,使用List的toArray方法。无参toArray方法返回 Object数组,传入初始化长度的数组对象,返回该对象数组
面试官再问:
1,用Arrays.asList转List后,如果修改了数组内容,list受影响吗
2,List用toArray转数组后,如果修改了List内容,数组受影响吗

)
数组转List受影响
List转数组不受影响
再答:
1,用Arrays.asList转List后,如果修改了数组内容,list受影响吗
Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址
2,List用toArray转数组后,如果修改了List内容,数组受影响吗
list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响
链表
单向链表
-
链表中的每一个元素称之为结点(Node)
-
物理存储单元上,非连续、非顺序的存储结构
-
单向链表:每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。记录下个结点地址的指针叫作后继指针 next

代码实现参考:

链表中的某个节点为B,B的下一个节点为C 表示: B.next==C
单向链表时间复杂度分析
(1)查询操作

-
只有在查询头节点的时候不需要遍历链表,时间复杂度是O(1)
-
查询其他结点需要遍历链表,时间复杂度是O(n)
(2)插入和删除操作

- 只有在添加和删除头节点的时候不需要遍历链表,时间复杂度是O(1)
- 添加或删除其他结点需要遍历链表找到对应节点后,才能完成新增或删除节点,时间复杂度是O(n)
双向链表
而双向链表,顾名思义,它支持两个方向
-
每个结点不止有一个后继指针 next 指向后面的结点
-
有一个前驱指针 prev 指向前面的结点
参考代码


对比单链表:
-
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址
-
支持双向遍历,这样也带来了双向链表操作的灵活性
双向链表时间复杂度分析

(1)查询操作
-
查询头尾结点的时间复杂度是O(1)
-
平均的查询时间复杂度是O(n)
-
给定节点找前驱节点的时间复杂度为O(1)
(2)增删操作
-
头尾结点增删的时间复杂度为O(1)
-
其他部分结点增删的时间复杂度是 O(n)
-
给定节点增删的时间复杂度为O(1)
面试题-ArrayList和LinkedList的区别是什么?
-
底层数据结构
-
ArrayList 是动态数组的数据结构实现
-
LinkedList 是双向链表的数据结构实现
-
-
操作数据效率
- ArrayList按照下标查询的时间复杂度O(1)【内存是连续的,根据寻址公式】, LinkedList不支持下标查询
- 查找(未知索引): ArrayList需要遍历,链表也需要链表,时间复杂度都是O(n)
- 新增和删除
- ArrayList尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
- LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
-
内存空间占用
-
ArrayList底层是数组,内存连续,节省内存
-
LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
-
-
线程安全
- ArrayList和LinkedList都不是线程安全的
- 如果需要保证线程安全,有两种方案:
- 在方法内使用,局部变量则是线程安全的
- 使用线程安全的ArrayList和LinkedList