vit细粒度图像分类(一)CADF学习笔记
1.摘要:
目的 基于Transformer架构的网络在图像分类中表现出优异的性能。然而,注意力机制往往只关注图像中的显著性特征,而忽略了其他区域的次级显著信息,基于自注意力机制的Transformer也是如此。为了获取更多的有效信息,从有区别的潜在性特征中学习到更多的可判别特征,提出了一种互补注意多样性特征融合网络(comple⁃mentary attention diversity feature fusion network,CADF),通过关注次显特征和对通道与空间特征协同编码,以增强特征多样性的注意感知。
方法 CADF 由潜在性特征模块(potential feature module,PFM)和多样性特征融合模块
(diversity feature fusion module,DFFM)组成。PFM模块通过聚合空间与通道中感兴趣区域得到显著性特征,再对特征的显著性进行抑制,以强制网络挖掘潜在性特征,从而增强网络对微小判别特征的感知。DFFM模块探索特征间的相关性,对不同尺寸的特征交互建模,以得到更加丰富的互补信息,从而产生更强的细粒度特征。
结果 本文方法可以端到端地进行训练,不需要边界框和多阶段训练。在 CUB-200-2011(Caltech-UCSDBirds-200-2011)、Stanford Dogs、Stanford Cars以及FGVC-Aircraft (fine-grained visual classification of aircraft) 4个基准数据集上验证所提方法,准确率分别达到了 92. 6%、94. 5%、95. 3% 和 93. 5%。实验结果表明,本文方法的性能优于当前主流方法,并在多个数据集中表现出良好的性能。在消融研究中,验证了模型中各个模块的有效性。结论 本文方法具
有显著性能,通过注意互补有效提升了特征的多样性,以此尽可能地获取丰富的判别特征,使分类的结果更加精准。
2.问题
细粒度目的是对属于同一基础类别的图像进行更加细致的子类划分。例如区分野生鸟类、汽车等。
由于类别之间具有细微的类间差异以及较大的类内差异,难以捕获特定区域的细微差异进行分类。
2.1发现
AlexNet (Krizhevsk等,2012)首次利用卷积神经网络(convolutional neural network,CNN)对图像进行分类,在大规模数据集中取得了当时最好的结果,但是网络提取特征的能力相对较弱。随着深度学习发展,促进了目标检测(Ren等,2017)、场景分割(Long等,2015)和行人识别(郑鑫 等,2020)的研究,但在细粒度分类中的应用依旧难以尽如人意,这是由于网络难以提取判别特征而造成的。此外,基于CNN方法的准确性也遇到了瓶颈。
2.2发展
Transformer (Dosovitskiy等,2021)在分类任务中取得了巨大成功,表明具有先天注意机制的Trans⁃former直接应用于图像块序列就可以捕获图像中的重要区域。且在一系列针对下游任务的扩展工作中证实了其具有强大的捕获全局和局部特征的能力,在多个领域取得了很好的效果,但是其计算消耗过于庞大。
与基于CNN的方法相比,基于Transformer的方法可以编码更长的序列并通过计算不同补丁之间的
相关性来提取全局特征。但是,应该注意的是,Transformer模块与所有其他注意机制一样,往往只注意目标中最显著的特征,忽略了其他区域的次级显著特征,而这些忽略的信息中也含有重要的可判别特征。
在基于CNN的细粒度图像分类方法中,类似的注意力机制(Zhao 等,2021),例如 SE(squeezeand excitation)模 块(Hu 等 ,2018)、CAM(channelattention module)(Park 等,2018)和 CBAM(convolu⁃tional block attention module)(Woo等,2018),都具有相同的问题。为了增强注意力机制的特征表示,以获得更多的特征,MAMC(multi-attention multi-classconstraint)(Sun等,2018)提出了OSME (one squeezemulti-excitation)模块来提取目标中多个注意力区域特征,然后利用度量学习引导注意力学习具有语义信息的特征。但是优化这类度量学习有很大的困难,且涉及样本选择问题。FBSM(feature boosting,suppression, and diversification)(Song和Yang,2021)提升特征图中最显著区域以获得特定部分的表示,并对其抑制以学习其他潜在区域。然而,上述注意力机制是基于CNN的,不能直接应用于基于Trans⁃former 的 网 络 中 。 CAFM(complemental attentionmulti-feature fusion network)(Miao 等,2021)提出补充注意模块以提升网络的判别能力,但是只应用于深层网络,忽略了浅层网络中的潜在性特征,且没有考虑多尺度特征的判别能力。
2.3创新
为了在基于 Transformer 的方法中从次显著区域提取更多的判别特征,通过抑制特征显著性的方法来使潜在性特征脱颖而出,同时利用不同层获取的特征图来挖掘判别区域。由于最后一个卷积层倾向于关注整个图像,但不同尺度之间存在高相似性,这导致捕获判别部分的能力降低。较早层的神经元的感受野相对较小,因此这些神经元可以内在地捕获部分区域。
基于这种思想,本文提出了一种互补注意多样性特征融 合 网 络(complementary attention diversity featurefusion network,CADF),在关注潜在性特征的同时,利用不同层感受野的差异来逐步学习多样性特征。在 CADF中,提出了一种潜在性特征模块(potentialfeature module,PFM),对特征的显著性进行抑制,并将显著性抑制后的特征传入网络,以此进一步挖掘特征中的类别信息。由于单独提取的特征难以表示图像的全部信息,为了实现特征多样性,提出了多样性 特 征 融 合 模 块(diversity feature fusion module,DFFM),采用多分支结构提取多个判别特征,并通过聚合其他部分的补充特征以丰富特征间的信息多样性。此外,使用组合损失进行协同优化,实现对网络中各个模块的精准反馈。
3.网络
CADF由潜在性特征模块(PFM)和多样性特征融合模块(DFFM)组成,架构如图1所示。骨干网络为Swin Transformer。首先将潜在性特征模块(PFM)分别插入到不同的stage中,以此尽可能学习到多个有区别的特定部分表示,再将不同阶段的多尺度特征输入到多样性特征融合模块(DFFM),通过对特征进行交互建模以增强每个特征特定表示,最终利用特征融合得到多样性特征。
3.1整体结构

3.2 潜在性特征模块(PFM)
输入一幅图像,网络提取图像中最重要的区域而忽略其他次要区域来对其信息进行编码,这对于
细粒度分类来说是次优的。为了提取更多的可判别特征,提出了潜在性特征模块(PFM),通过抑制最显著的区域来迫使网络挖掘更多的潜在特征。PFM模块如图2(a)所示。
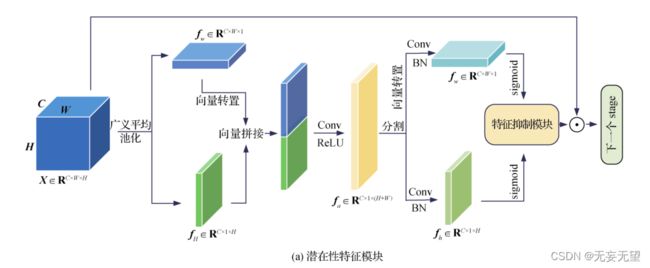
做了两次不同方向的广义池化,相当于做了两次卷积,对输入图像进行特征提取,也即fw和fh分别是通道和空间上的特征表示,之后接入特征抑制模块。观察发现从把输入接了过来,相当于是一种残差处理,然后将输入和特征抑制模块的结果叠加在一起。
没看代码,感觉为了网络能继续下去,这个地方应该是用的add方式,图像输入和特征抑制模块的尺度大小相同,这样的话改动就不大,不过这样看来这个特征抑制模块相当于注意力机制中的特征权重重标定。
而且进一步来说,stag2中含有次显特征,并且由于特征抑制模块的作用,在stag2中次显特征已经被拔高到显著层级上,很难保证会不会对后续提取次显造成困扰,如果是concat叠加应该影响不大,但如果是add加和的话影响就无法避免。按照作者的思路,应该是在骨干网络的基础上,从每一个stag1横向引出一个PFM,得到结果后再与原来的stag融合,最后接入多样性网络。有点麻烦,但可以实现。
这里面感觉最重要的就是显著性抑制这个框,怎么实现显著性抑制的,是一个已经成熟的模块吗?
假定输入的特征表示为 X ∈ R C × W × H ,其中, C , W和 H 分别表示特征的通道、宽度和高度。首先对输入特征进行映射处理,借助CA(coordinate attention)(Hou等,2021)的思想,对特征分别沿空间两个方向进行聚合特征变换,产生一对方向感知特征图,这样保留了竖直和水平方向的空间信息,且在后续操作中不仅可以捕获跨通道信息,还考虑了方向与位置信息,使模型更准确地定位到并识别目标区域。使 用广义平均池化(generalized average pooling,GeM)
(Radenović等,2019) 进行处理,计算为
将获得的特征进行拼接得到聚合特征。为保证拼接维度对应,先对 f W 进行转置再进行拼接,然后使用卷积和激活函数对聚合后的特征进行处理,并使用批量归一化(batch normalization, BN)加速网络训练,具体为
为了获得潜在性信息,需要对得到的权重特征g h 和 g w 进行显著性抑制,迫使网络能够关注潜在性特征,以不断挖掘特征中的次显信息,提取更多的判别特征,如图2(b)所示。首先使用通道平均池化对特征进行压缩,得到权重参数 M ,再将其映射到与原
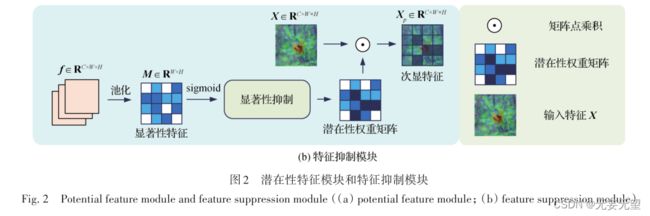
将两次池化的图像特征进一步池化,比较标准的注意力机制结构,通过显著性抑制显著性特征来获取潜在性权重矩阵,通过调整权重的方法降低显著性特征的重要性,提高次显特征的贡献,属于特征提取增强操作。
3.3 多样性特征融合模块(DFFM)
特征多样性在细粒度图像分类中起着至关重要的作用,因此提出了一种多样性特征融合模块(DFFM)来增强特征的丰富性。DFFM由坐标特征交 互 模 块(coordinate feature interaction module,CFIM)和特征融合两个部分组成。CFIM对不同特征间的通道和空间信息进行交互建模以增强特征丰富性,再经过特征融合模块来增强特征特定部分的信息,得到多样性特征。CFIM模块如图3所示。

广义平均池化可以理解为卷积,用于提取和聚合图像特征,先向量拼接,再向量分割,论文中没有提到这么做的作用,由于输入是两个不同层次的图像特征,个人感觉是想要将两个层次的特征进行交互,类似于ECA注意力机制,或真是ASFF中的不同尺度特征自适应融合。整个坐标特征交互模块的作用就是将输入的三个层次的图像特征进行相互的融合,起到特征融合增强的作用。
3.4 组合损失优化
在训练阶段,使用交叉熵损失函数来计算每个显著性特征 Y i 的分类损失,将特征通过全局平均池
化(global average pooling,GAP)和分类层(classifier)进行变换, f i = Cls i (GAP(Y i )), i = 1,2,3 ,Cls为分类层变换,GAP为全局平均池化。处理后再使用soft⁃max函数计算分类概率,具体为
4.实验
4.1实验设置
4.1.1 数据集

4.1.2 实验细节
本文网络在 NVIDIA 2080Ti GPU 上的 PyTorch中实现。使用在 ImageNet 分类数据集上预训练的
Swin Transformer预训练参数来初始化模型的权重参数。采用Adam W优化器进行优化,动量为0. 9,并使用余弦退火调度器。批量大小设置为6,主干层的学习率设置为0. 000 1,新增层设置为0. 000 01,使用0. 05的权重衰减。训练期间,输入图像的大小调整为550 × 550像素,并随机裁剪为448 × 448像素,且使用随机水平翻转来进行数据增强。在测试时,输入图像的尺寸调整为550 × 550像素,并从中心裁剪为448 × 448像素。设置超参数β = 0. 5, λ = 1。
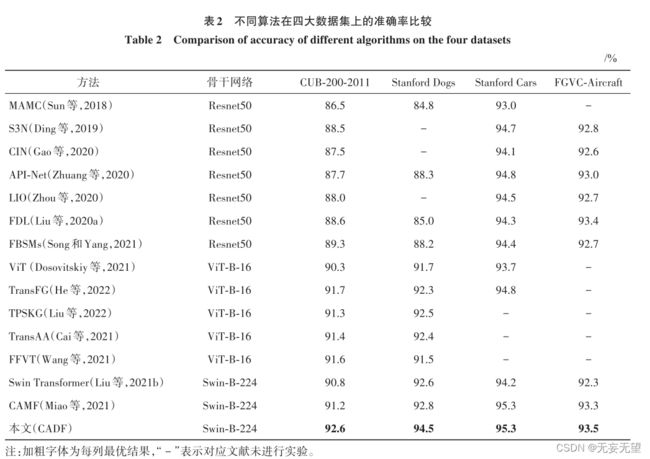
4.2对比试验
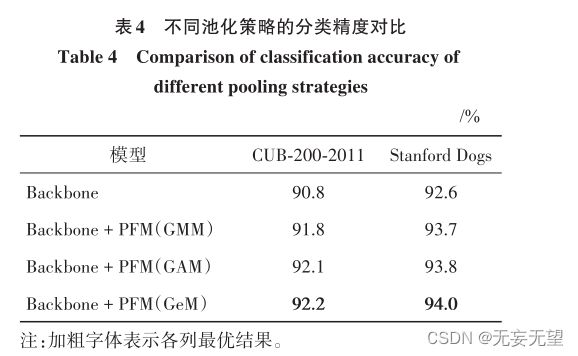
4.3消融实验


5.结论
本文提出了一种互补注意多样性特征融合网络模型,通过将潜在性特征模块插入到Transformer不
同阶段中,可有效挖掘潜在性特征,同时多样性特征交互使得网络能够学习到更丰富的特征。
潜在性特征模块对特征显著性进行抑制,从而迫使网络关注次显信息,以此挖掘更多的可判别特征。
在此基础上,为了增强特征的多样性,提出了多样性特征融合模块。该模块由坐标特征交互模块和特征融合模块组成,其中,坐标特征交互模块对多尺度特征进行交互建模以增强特征丰富性,再经过特征融合模块来增强特征特定部分的信息,实现特征多样性。两个模块相互协同,极大提升了模型精度。
此外,对模型中各个模块进行了消融实验,结果证明了网络中各个模块的有效性。提出的网络可端对端的进行训练,不需要边界框的标注,在 4 个数据集上进行实验,本文方法均达到先进性能。