如何使用 OpenCV parallel_for_并行化代码
目标
本教程的目的是演示如何使用 OpenCV 框架轻松并行化代码。为了说明这个概念,我们将编写一个程序来对图像执行卷积运算。完整的教程代码在这里。parallel_for_
前提
并行框架
第一个前提条件是使用并行框架构建 OpenCV。在 OpenCV 4.5 中,以下并行框架按此顺序提供:
- 英特尔线程构建模块(第三方库,应显式启用)
- OpenMP(集成到编译器,应显式启用)
- APPLE GCD(系统范围,自动使用(仅限 APPLE))
- Windows RT 并发(系统范围,自动使用(仅限 Windows RT))
- Windows 并发(运行时的一部分,自动使用(仅限 Windows - MSVC++ >= 10))
- Pthreads(线程)
如您所见,OpenCV 库中可以使用多个并行框架。一些并行库是第三方库,必须在构建之前在 CMake 中显式启用,而其他并行库则在平台中自动可用(例如 APPLE GCD)。
竞争条件
当多个线程尝试写入或同时读取和写入特定内存位置时,会发生争用条件。基于此,我们可以将算法大致分为两类:-
- 只有单个线程将数据写入特定内存位置的算法。
- 例如,在卷积中,即使多个线程可能在特定时间从一个像素读取,也只有一个线程写入特定像素。
- 多个线程可以写入单个内存位置的算法。
- 查找轮廓、特征等。此类算法可能要求每个线程同时向全局变量添加数据。例如,在检测特征时,每个线程会将其图像各自部分的特征添加到公共向量中,从而创建争用条件。
卷积
我们将使用执行卷积的示例来演示如何使用 并行化计算。这是一个不会导致竞争条件的算法示例。parallel_for_
理论
卷积是一种简单的数学运算,广泛用于图像处理。在这里,我们将一个较小的矩阵(称为内核)滑动到图像上,像素值和内核中相应值的乘积之和为我们提供了输出中特定像素的值(称为内核的锚点)。根据内核中的值,我们得到不同的结果。在下面的示例中,我们使用一个 3x3 内核(锚定在其中心)并在 5x5 矩阵上进行卷积以生成 3x3 矩阵。可以通过用合适的值填充输入来改变输出的大小。
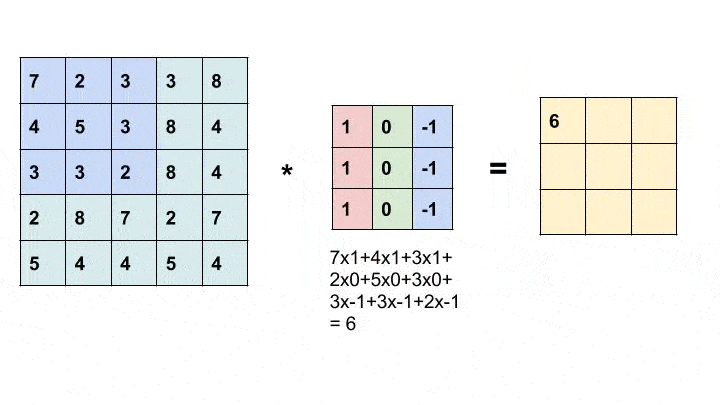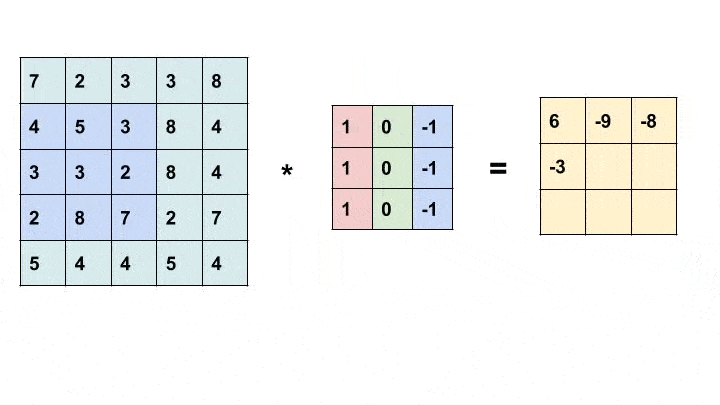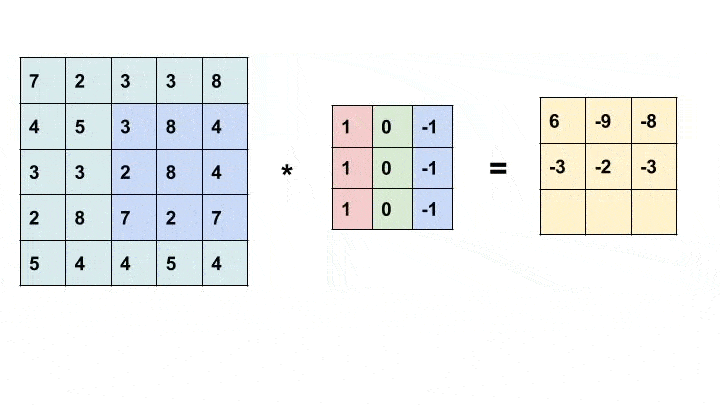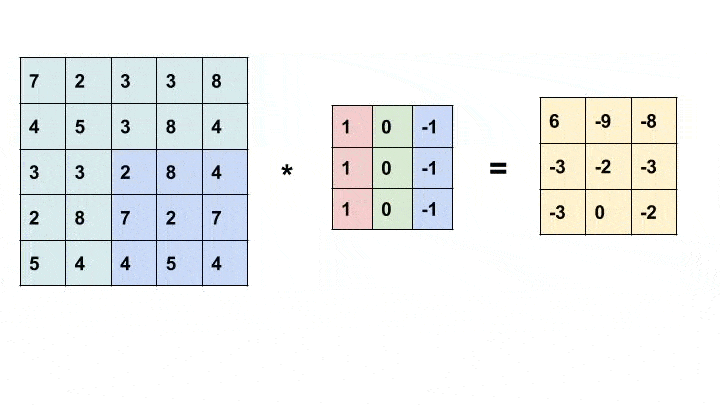
有关不同内核及其作用的更多信息,请查看此处
在本教程中,我们将实现最简单的函数形式,该函数采用灰度图像(1 个通道)和奇数长度的方形内核并生成输出图像。该操作不会就地执行。
注意
我们可以临时存储一些相关的像素,以确保我们在卷积期间使用原始值,然后就地进行。但是,本教程的目的是介绍parallel_for_函数,就地实现可能过于复杂。
伪代码
InputImage src, OutputImage dst, kernel(size n)
makeborder(src, n/2)
for each pixel (i, j) strictly inside borders, do:
{
value := 0
for k := -n/2 to n/2, do:
for l := -n/2 to n/2, do:
value += kernel[n/2 + k][n/2 + l]*src[i + k][j + l]
dst[i][j] := value
}
对于 n 大小的内核,我们将添加一个大小为 n/2 的边框来处理边缘情况。然后,我们运行两个循环来沿内核移动,并将乘积相加
实现
顺序实现
void conv_seq(Mat src, Mat &dst, Mat 内核){int rows = src.rows, cols = src.cols;dst = Mat(rows, cols, src.type());照顾边缘值make border = kernel.rows / 2;int sz = kernel.rows / 2;copyMakeBorder(src, src, sz, sz, sz, sz, BORDER_REPLICATE);for (int i = 0; i <行; i++){uchar *dptr = dst.ptr(i);for (int j = 0; j < cols; j++){double 值 = 0;for (int k = -sz; k <= sz; k++){当我们创建 PTR 时,由于内存访问效率更高,结果会稍快一些。乌查尔 *sptr = src.ptr(i + sz + k);for (int l = -sz; l <= sz; l++){值 += kernel.ptr<double>(k + sz)[l + sz] * sptr[j + sz + l];}}dptr[j] = saturate_cast(值); }}}
我们首先制作一个与 src 大小相同的输出矩阵 (dst),并在 src 图像中添加边框(以处理边缘情况)。
然后,我们依次遍历 src 图像中的像素,并计算内核和相邻像素值的值。然后,我们将值填充到 dst 图像中的相应像素。
并行实现
在查看顺序实现时,我们可以注意到每个像素依赖于多个相邻像素,但一次只编辑一个像素。因此,为了优化计算,我们可以利用现代处理器的多核架构,将图像拆分为条纹,并并行对每个条纹进行卷积。OpenCV cv::p arallel_for_ 框架自动决定如何有效地拆分计算,并为我们完成大部分工作。
注意
尽管特定条带中的像素值可能取决于条带外的像素值,但这些只是只读操作,因此不会导致未定义的行为。
我们首先声明一个继承自 cv::P arallelLoopBody 的自定义类,并覆盖 .virtual void operator ()(const cv::Range& range) const
并行卷积(Mat src, Mat &dst, Mat kernel): m_src(src), m_dst(dst), m_kernel(内核){sz = kernel.rows / 2;}virtual void operator()(const Range &range) const CV_OVERRIDE{for (int r = range.start; r < range.end; r++){int i = r / m_src.cols, j = r % m_src.cols;double 值 = 0;for (int k = -sz; k <= sz; k++){乌查尔 *SPTR = m_src.ptr(i + sz + k);for (int l = -sz; l <= sz; l++){值 += m_kernel.ptr<double>(k + sz)[l + sz] * sptr[j + sz + l];}}m_dst.ptr(i)[j] = saturate_cast(值); }}};
中的范围表示将由单个线程处理的值的子集。根据要求,可能有不同的方法来拆分范围,这反过来又会改变计算。operator ()
例如,我们可以
-
拆分图像的整个遍历,按如下方式获取 [row, col] 坐标(如上图所示):
virtual void operator()(const Range &range) const CV_OVERRIDE{for (int r = range.start; r < range.end; r++){int i = r / m_src.cols, j = r % m_src.cols;double 值 = 0;for (int k = -sz; k <= sz; k++){乌查尔 *SPTR = m_src.ptr(i + sz + k);for (int l = -sz; l <= sz; l++){值 += m_kernel.ptr<double>(k + sz)[l + sz] * sptr[j + sz + l];}}m_dst.ptr(i)[j] = saturate_cast(值); }}然后,我们将按以下方式调用 parallel_for_ 函数:
parallelConvolution obj(src, dst, 内核);parallel_for_(范围(0, 行 * 列), obj); -
拆分行并计算每一行:
virtual void operator()(const Range &range) const CV_OVERRIDE{for (int i = range.start; i < range.end; i++){uchar *dptr = dst.ptr(i);for (int j = 0; j < cols; j++){double 值 = 0;for (int k = -sz; k <= sz; k++){乌查尔 *sptr = src.ptr(i + sz + k);for (int l = -sz; l <= sz; l++){值 += kernel.ptr<double>(k + sz)[l + sz] * sptr[j + sz + l];}}dptr[j] = saturate_cast(值); }}}在本例中,我们调用具有不同范围的 parallel_for_ 函数:
parallelConvolutionRowSplit obj(src, dst, 内核);parallel_for_(范围(0, rows), obj);注意
在我们的例子中,两种实现的执行方式相似。在某些情况下,可能允许更好的内存访问模式或其他性能优势。
要设置线程数,可以使用:cv::setNumThreads。您还可以使用 cv::p arallel_for_ 中的 nstripes 参数指定拆分次数。例如,如果您的处理器有 4 个线程,则设置或设置应与默认相同,它将使用所有可用的处理器线程,但仅在两个线程上拆分工作负载。
cv::setNumThreads(2)nstripes=2
注意
C++ 11 标准允许通过删除类并将其替换为 lambda 表达式来简化并行实现:parallelConvolution
结果
在
- 512x512 输入,5x5 内核:
This program shows how to use the OpenCV parallel_for_ function and compares the performance of the sequential and parallel implementations for a convolution operation Usage: ./a.out [image_path -- default lena.jpg] Sequential Implementation: 0.0953564s Parallel Implementation: 0.0246762s Parallel Implementation(Row Split): 0.0248722s
- 512x512 输入,带 3x3 内核
This program shows how to use the OpenCV parallel_for_ function and compares the performance of the sequential and parallel implementations for a convolution operation Usage: ./a.out [image_path -- default lena.jpg] Sequential Implementation: 0.0301325s Parallel Implementation: 0.0117053s Parallel Implementation(Row Split): 0.0117894s
并行实现的性能取决于您拥有的 CPU 类型。例如,在 4 核 - 8 线程 CPU 上,运行时可能比顺序实现快 6 到 7 倍。有许多因素可以解释为什么我们没有实现 8 倍的加速:
- 创建和管理线程的开销,
- 并行运行的后台进程,
- 4 个硬件内核(每个内核有 2 个逻辑线程)和 8 个硬件内核之间的区别。
在本教程中,我们使用了水平渐变滤镜(如上面的动画所示),它生成了一个突出显示垂直边缘的图像。

在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用
这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取

