Redis淘汰策略、持久化、主从同步与对象模型
淘汰策略
Redis是内存数据库,内存是稀缺资源。内存有限的情况下,如果使用额度已满,还继续往里面写入新数据的话,就需要淘汰掉一些占据内存的数据。
如果使用了expire或者pexpire指令设置key的过期时间,那么淘汰策略一般优先选择淘汰过期key的策略。存储key-value的结构体(struct redisObject)中有一个属性,LRU_BITS,大小为24位,一般存储着过期时间、使用次数等属性,其中有8位存储着使用次数,最大可计数到256次。
Redis.conf文件中与淘汰策略相关的设置:
- maxmemory,redis最大可使用的内存。
- maxmemory-policy,淘汰策略,默认是noeviction。
- maxmemory-samples,淘汰策略的采样方式。
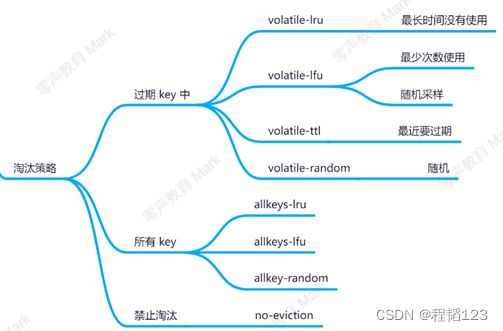
其中,可选的淘汰策略如下,思维导图的一个末端代表了一种淘汰策略,例如第一个末端volatile-lru代表从过期key中淘汰最长时间没有使用的key,allkeys-lru末端代表从所有key中淘汰最长时间没有使用的key。
持久化
Redis作为一个内存数据库,一旦关闭,内存就会丢失。把数据载入到磁盘中,就是在实现持久化。
持久化的方式可基于AOF,RDB和混合使用。
AOF
append of file。将所有写操作记录追加到文件的末尾,redis重启的时候就把所有的写操作执行一遍进行数据恢复。该方法会产生大量的冗余数据。
AOF的always方法:redis每次写操作都先把操作记录持久化进入磁盘,再将执行结果返回给用户,是一种同步策略,在主线程中进行操作。
#Conf文件修改:
appendonly yes
appendfilename "appendonly.aof"
appendfsync alwaysAOF的every sec方法:先把写操作的记录写入一块缓存中,另起一个线程每秒钟把缓存刷入磁盘中,是一种异步策略。
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
流程:操作记录被写入aof_buf➡调用write函数把记录从aof_buf刷入内核的page cache(内核高速缓冲区)➡调用fsync函数把数据从page cache刷入磁盘。
AOF的方式,其实就对应着调用操作流程的调用方式。
注意:如果机器断电了,可能会造成内存丢失。但如果只是进程退出,会调用close函数,自动刷内存。
RDB
Redis Database,将内存中的数据以快照的形式保存到磁盘上的二进制文件中,实现数据的持久化。如何实现内存快照?fork一个子进程,由这个子进程把快照到的数据存入磁盘中。
进程把数据存储于虚拟内存当中,虚拟内存通过页表映射到物理内存上。
RDB的写时复制过程:
- fork一个子进程。
- 子进程复制了父进程的页表,映射到同一块物理内存。
- 子进程和父进程的页表的标记位都被设置为只读。
- 父进程依然对外提供服务,当有新的操作产生的时候,系统会为父进程复制一块新的物理内存,重新构建映射关系。
#Conf文件修改:
save 300 10
#表示300s内如果由10个key被修改那么就储存一次。
Aof-rewrite
在 aof 的基础上,满足一定策略则 fork 进程,根据当前内存状态,转换成一系列的 redis 命令,序列化成一个新的 aof 日志文件中,序列化完毕后再将操作期间发生的增量 aof
日志追加到新的 aof 日志文件中,追加完毕后替换旧的 aof 日志文件;以此达到对 aof 日志瘦身的目的;
Rdb-aof混用
通过fork子进程,根据内存数据生成rdb文件。在rdb持久化期间,对redis的写操作会记录到重写缓冲区,当rdb持久化结束,附加到aof文件末尾。
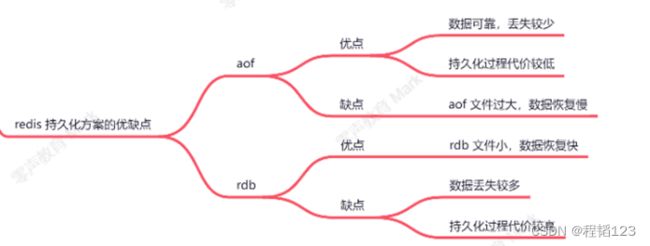
持久化策略优缺点对比
大key
大key指的是value很大的key,一般是有很多项目的hash或者zset。一般会加大fsync的时候和写时复制的压力。
Redis的高可用设置
高可用:Redis可以在合理的时间给前台合理的回复。
实现高可用的关键:1、要有数据备份。2、当主节点宕机要能进行节点切换。
高可用设置目的:在某个redis节点发生宕机之后,依然可以在合理的时间给前台合理的回复。
数据备份
主从复制
主redis数据库发生数据变更的时候,要复制到从redis节点中。
同步复制:每次操作主redis的时候,都要先复制到从redis中,再给前台返回结果,缺点是速度慢。
异步复制:每次操作主redis的时候,操作成功直接返回,从redis在后台自行拉取数据。缺点是从redis 的数据可能与主redis不一致,从redis的数据可能不是最新的。
主从数据库的主被动关系
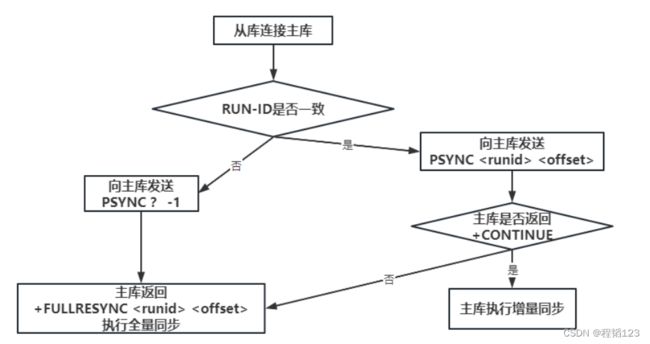
从数据库主动向主数据库建立连接。因为主从复制支持从数据库任意时间复制主数据库,主动权交给从数据库才能实现。
从数据库主动从主数据库拉数据。从数据库需要可以自由地选择获取主数据库的哪部分数据,以及如果主从断连,从数据库重连后可以续上复制。
全量复制与增量复制
主数据库一般有一个环形缓冲区,存储着数据,从数据库持有一个复制偏移量。复制偏移量代表了从数据库复制到的范围,如果和主数据库环形缓冲区的偏移量有差别,说明差别对应的部分说明还没复制到。
如果复制偏移量在环形缓冲区当前的偏移量的值的范围当中,说明增量数据没有覆盖住环形缓冲区一圈,可以进行增量更新。
如果复制偏移量不在环形缓冲区当前的偏移量的值的范围当中,说明增量数据已经覆盖住环形缓冲区一圈,可以进行全量更新。
节点切换
哨兵模式
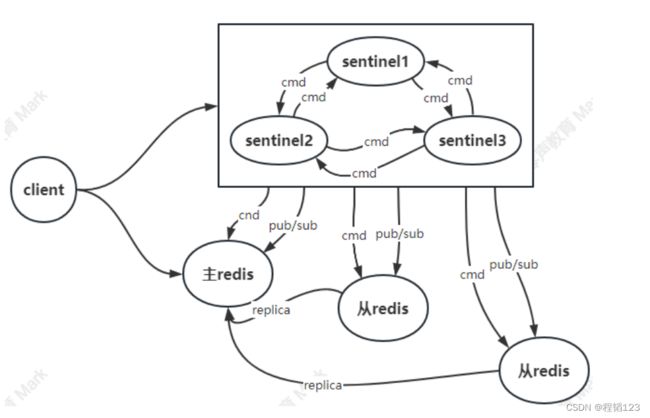
哨兵集群:不存储数据,仅仅用于监控主节点是否宕机,监控哪个从节点的数据更新。如果发生了宕机,通知client和新的从redis建立连接。
哨兵模式是 Redis 可用性的解决方案;它由一个或多个 sentinel实例构成 sentinel 系统;该系统可以监视任意多个主库以及这些主库所属的从库;当主库处于下线状态,自动将该主库所属的某个从库升级为新的主库;
客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再连接主节点进行数据交互,同时通过subscribe监听来自sentinel的信息。当主节点发生故障时, sentinel会将最新的主库地址告诉客户端。通过这样客户端无须重启即可自动完成节点切换
哨兵模式因为过于复杂、部署麻烦,并且不能解决扩容、及时性等问题,实务中很少使用它来解决高可用方案。
Redis cluster集群
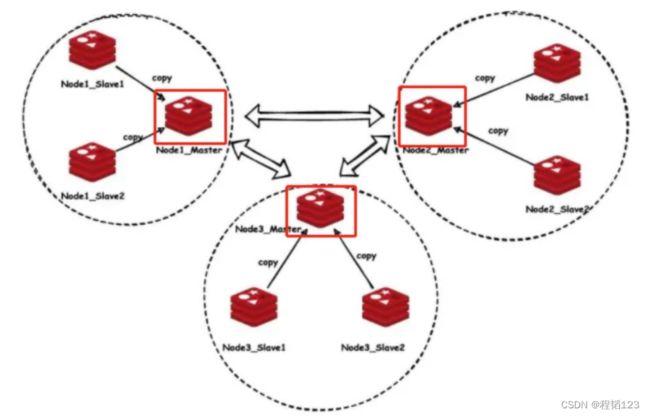
以上图为例介绍cluster集群的特征:
- 去中心化:如图所示,有3个主节点,而不是只有1个中心节点。可以通过任意节点的端口(包括从节点)去读取数据。
- 主节点对等:主节点的关系是对等的,如果给其中一个节点写入数据,另外两个主节点是不会发生变化的。
- 主从切换:如果两个主节点判断另外一个节点发生了宕机,那么另一个主节点的从节点会顶上成为新的主节点。
- 解决了数据扩容问题:一个主节点满了之后可以向增加新的主节点写入新数据。
Redis cluster集群的实现
1、创建文件夹
# 创建 6 个文件夹
mkdir -p 7001 7002 7003 7004 7005 7006
cd 7001
vi 7001.conf
# 7001.conf 中的内容如下2、编辑 7001.conf
注意路径是否需要修改
pidfile "/home/mark/redis-data/7001/7001.pid"
logfile "/home/mark/redis-data/7001/7001.log"
dir /home/mark/redis-data/7001/
port 7001
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
3、复制配置
cp 7001/7001.conf 7002/7002.conf
cp 7001/7001.conf 7003/7003.conf
cp 7001/7001.conf 7004/7004.conf
cp 7001/7001.conf 7005/7005.conf
cp 7001/7001.conf 7006/7006.conf
4、修改配置
sed -i 's/7001/7002/g' 7002/7002.conf
sed -i 's/7001/7003/g' 7003/7003.conf
sed -i 's/7001/7004/g' 7004/7004.conf
sed -i 's/7001/7005/g' 7005/7005.conf
sed -i 's/7001/7006/g' 7006/7006.conf5、创建启动配置
#!/bin/bash
redis-server 7001/7001.conf
redis-server 7002/7002.conf
redis-server 7003/7003.conf
redis-server 7004/7004.conf
redis-server 7005/7005.conf
redis-server 7006/7006.conf6、智能创建集群
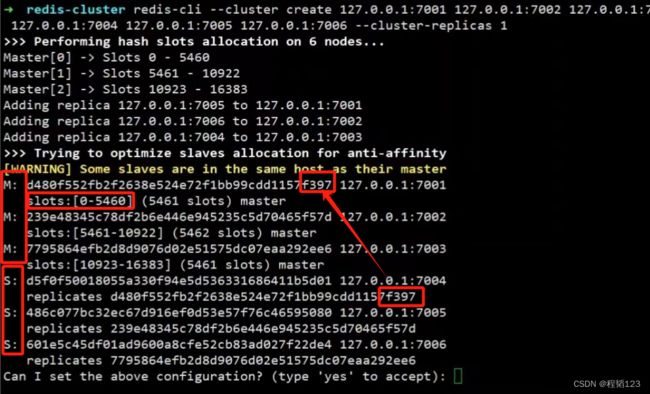
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 17、集群创建结果
如果创建了3个主节点,3个从节点,其中7004是7001的从节点,以此类推。
slots是给各个主节点设置的,举例:当有一个新的key被set的时候,redis会对这个key做一个hash,得到的hash值会对3取余,得到0-16383范围内的值,根据这个值找到对应的槽位,把数据存入相应的节点中。目的是为了负载均衡,让各个节点承受的压力一致。
8、设置获取值
redis-cli -c -p 7001
set name mark注意虽然是往7001里set key,但是可能会被重定向到其他节点上。如果要get key,可以从任意节点get key,包括从节点。