redis---相关笔记
redis的的百易教程
Redis快速入门 -Redis教程™
redis命令参考:
Redis 命令参考 — Redis 命令参考
Linux下载安装redis
1:redis下载:
wget http://download.redis.io/releases/redis-4.0.0.tar.gz
1.1: 提示错误
-bash: wget: command not found
解决: 安装下载命令的控制器 : CentOS系统: yum install wget -y
Debian/Ubuntu系统: apt-get install -y wget
1.2: 安装gcc : yum install gcc-c++
2: 解压: tar -zxvf redis-4.0.0.tar.gz
3:安装: make install
4:redis启动: redis-server
指定端口启动: redis-server -port 6380
5:redis客户端启动: redis-cli
启动客户端, 连接指定端口的redis : redis-cli -p 6380
启动客户端, 连接指定服务器的redis: redis-cli -h 127.0.0.1 -port 6379
客户端连接cluster集群: redis-cli -c -h 10.11.12.129 -p 6380
6: redis服务端的 指定配置文件启动:
redis的配置文件: redis.conf ;
cp redis.conf redis-6380.conf ; 然后修改端口, 输出日志文件, 日志文件位置;
vi redis-6380.conf ;
参数: bind 127.0.0.1 地址;绑定主机的地址, 访问的时候就拿这个地址访问
daemonize no 改为yes , 以守护进程方式启动, redis将以服务的形式存在,
日志将不再打印到命令窗口中
port 6379 端口改为6380 ;
logfile "" 日志文件 改为"6380.log"
dir ./ 日志文件的位置: 改为具体位置 dir /opt/data
dbfilename dump.rdb :设置本地数据库文件名: 一般格式为: dump-端口号.rdb
dump-6380.rdb
rdbcompression yes : 默认为yes, 设置存储至本地数据库时 是否采用压缩数据
rdbchecksum yes : 默认为yes, 设置是否进行RDB文件格式校验,
该校验过程在写文件和读文件过程均进行; 有约10%的性能消耗
save 900 2 : 在满足 在900秒内有2个key的值发生变化时,进行持久化;
持久化用的是 bgsave的方式;
appendonly yes : 开启AOF功能; , 默认为关闭状态;
appendfsync always : 每次 --- AOF持久化方式的三种策略;
appendfilename appendonly-6380.aof : AOF持久化文件名,默认名字叫 appendonly.aof;
AOF文件的保存路径和RDB文件的保存路径保持一致即可;
auto-aof-rewrite-min-size 60MB : 自动重写, 大小到60m时,进行重写;
auto-aof-rewrite-percentage 100 : 自动重写, 比例到100%时,进行重写;
databases 16 : 设置数据库数量, 默认16; 16个区域;
maxclients 0 : 设置同一时间最大客户端连接数,默认为0, 无限制;
当客户端连接到达上限,redis会关闭新的连接;
timeout 300 : 客户端闲置等待最长时长 300秒单位, 达到最大值后关闭连接;
如需关闭功能,设置为0 ;
redis-server redis-6380.conf 指定配置文件 方式启动; 日志会输出到 /opt/6380.log
6.1: 停止Redis命令 redis-cli shutdown / redis-cli -p 6380 shutdown
7: 持久化: RDB的启动方式-- bgsave
bgsave 命令是针对save阻塞问题做的优化;
redis内部所有涉及到RDB操作都采用bgsave的方式;
8: RDB优缺点:
优: 1:存储效率高, 压缩成的一个二进制文件;
2:恢复速度要 比AOF快;
3:可以把快照的备份到其他机器上去; 利于备份,全量备份;
4: 存的全数据, 数据量大;
缺: 1:利用配置,间歇时间 会丢失数据;
2:bgsave 每次运行时, 另开进程, 牺牲掉一些性能;
3:redis在多个版本中, RDB快照后的文件格式的版本不统一, 比如4.0版本的读不出2.0的, 版本 间的数据格式没有兼容; 咋办, 先把2.0的读出来,存数据库,再写到4.0;
9: 持久化: RDB和 AOF; 在RDB快照和 AOF只记录每步操作, 优先使用AOF;AOF是主流方式;
AOF: 重启时,重新执行 aof文件中记录的每步命令,达到恢复数据的目的;
10: AOF写数据的三种策略(appendfsync):
1: always :每次 ; 数据零误差,性能较低;
2: everysec : 每秒; 数据准确性较高,性能较高,在突然宕机的情况下丢失一秒的数据;
3: no : 交由系统控制; 整体过程不可控;
11: AOF的重写: 随着命令的不断写入, aof文件越来越大;
aof重写将多条命令整合成最终命令, 压缩文件大小;
重写的作用: 降低磁盘占用量; 提高持久化效率; 提高恢复效率;
重写的规则: 已经过期的不再写入文件;
忽略无效指令: set name 1 ; set name 2; 直接是保留set name 2 ;
对同一数据的多条指令合并为一条指令; lpush list1 ; lpush list2;--lpush list 1 2;
重写的方式: 1 手动重写: bgrewriteaof (后台另起进程 进行操作)
2 自动重写: auto-aof-rewrite-min-size 60MB
auto-aof-rewrite-percentage 100
12:事务:
multi : 设置事务的起始位置, 此命令后的 所有指令都加入到事务中 , 创建了一个任务队列;
exec : 设置事务的结束位置, 同时执行事务, 与multi成对出现,成对使用
-- 加入的事务的命令 先进入到任务队列中, 并没有立即执行, 只有执行exec命令时才开始执行;
discard : 取消事务, 终止当前事务, 发生在 mutli之后, exec之前 ; 把任务队列 销毁;
例: multi 开启事务
set age 15 ; get age; set age16 ; 加入任务队列
exec ; 执行
例: mutli 开启事务
set age 15 ; get age ; set age17 ; 发现给值错误了
discard ; 取消事务;
事务的注意事项:
1: 语法错误,指令写错了, 在整个事务的所有命令都不执行;
2: 运行错误: 指令写对了, 数据类型搞错了, 例: list进行incr操作;
正确的指令执行, 运行错误的命令不执行;(数据已经执行的命令,需要手动回滚)
13:锁:
watch key1 , key2 ; 对key添加监控锁, 在执行exec之前如果 监控的key发生了改变, 终止事务;
unwatch ; 取消对所有的key的 监视;
redis 应用基于状态控制的批量任务执行;
watch key1 ; 是在事务之前进行 监控; 在开启事务 里面是不能 进行监控的;
例: watch name ;
multi ; set age 15 ; get age ; set age 16 ; | set name lisi ;
exec ; 这时的事务已经终止, 无法执行;
14: 分布式锁:
expire lock_num second : 设置一个公共锁, 设置为由时间的是为了 避免忘记删除锁, 导致别人无法再获取锁, 称死锁; lock_num 为 文明行为, 大伙约定的一个名字;
del lock_num ; 释放锁, 就是删除操作;
在a获取到锁的时候, b来获取锁是获取不成功的;
15:数据库的 删除策略:
1: 定时删除: 节约内存,占用CPU
2: 惰性删除: 内存占用严重, CPU利用率高
3: 定期删除: 内存定期随机清理, 每秒花费固定的CPU资源维护内存; 随机抽查,重点抽查;
(设置超时时间的key, 在过期后,是不会删除掉的,还在内存中)
16: 逐出算法:
内存是有限的, 内存满会导致内存溢出;
配置文件 redis.conf文件中 配置 :
maxmemory-policy volatile-lru : 挑选最近最少使用的数据淘汰;
volatile-lfu : 挑选最近使用次数最少的数据淘汰;
volatile-ttl : 挑选将要过期的数据淘汰;
volatile-random : 任意选择数据淘汰;
redis4.0中默认策略: 禁止驱逐策略: no-enviction
17: 高级数据类型:
1: HyperLogLog类型 , redis 应用于独立信息统计
基本操作:
pfadd key element [element ...] 添加数据
pfcount key [key ...] 统计数据
pfmerge destkey sourcekey [sourcekey...] 合并数据
基数:
基数是数据集去重后元素个数
HyperLogLog 是用来做基数统计的,运用了LogLog的算法
{1, 3, 5, 7, 5, 7, 8} 基数集: {1, 3, 5 ,7, 8} 基数:5
{1, 1, 1, 1, 1, 7, 1} 基数集: {1,7} 基数:2
相关说明:
用于进行基数统计,不是集合,不保存数据,只记录数量而不是具体数据
核心是基数估算算法,最终数值存在一定误差
误差范围:基数估计的结果是一个带有 0.81% 标准错误的近似值
耗空间极小,每个hyperloglog key占用了12K的内存用于标记基数
pfadd命令不是一次性分配12K内存使用,会随着基数的增加内存逐渐增大
Pfmerge命令合并后占用的存储空间为12K,无论合并之前数据量多少
2: Bitmaps类型 : redis 应用于信息状态统计
基础操作:
getbit key offset 获取指定key对应偏移量上的bit值
setbit key offset value 设置指定key对应偏移量上的bit值,value只能是1或0
扩展操作:
bitop op destKey key1 [key2...]
对指定key按位进行交、并、非、异或操作,并将结果保存到destKey中
and:交
or:并
not:非
xor:异或
bitcount key [start end] 统计指定key中1的数量
3: GEO : redis 应用于地理位置计算
GEO类型的基本操作
添加坐标点 geoadd key longitude latitude member [longitude latitude member ...]
获取坐标点 geopos key member [member ...]
计算坐标点距离 geodist key member1 member2 [unit]
添加坐标点
获取坐标点
计算经纬度
georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]
georadiusbymember key member radius m|km|ft|mi [withcoord] [withdist] [withhash] [count count]
geohash key member [member ...]
18: 主从复制:
主从复制即将master中的数据即时、有效的复制到slave中
特征:一个master可以拥有多个slave,一个slave只对应一个master
职责:
master: 主服务器
写数据
执行写操作时,将出现变化的数据自动同步到slave
读数据(可忽略)
slave: 从服务器
读数据
写数据(禁止)
从 连接 主:
1: 服务端启动 redis-server redis-6379.conf
服务端启动 redis-server redis-6380.conf
客户端连接6380客户端: redis-cli -p 6380
连接方式一: 客户端发送指令
slaveof ip 端口 , 在从6380 连接 主6379 : slaveof 127.0.0.1 6379 , ok 连接成功;
主,从, 的日志 都会打印连接的信息;
info 命令, 也可以查看 连接的信息;
连接方式二: 启动时加连接参数
redis-server redis-6380.conf --slaveof 127.0.0.1 6379
连接方式三: 服务器配置文件 配置参数:
在redis-6380.conf 配置文件 配置参数: slaveof 127.0.0.1 6379
redis-server redis-6380.conf 启动 6380服务端 即完成 从6380连接主6379
2: 主从断开连接指令:
客户端发送命令: 进入客户端后的命令 slaveof no one
说明: slave断开连接后,不会删除已有数据,只是不再接受master发送的数据;
3: 主从复制的工作流程:


19: 哨兵:
是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的
master并将所有slave连接到新的master ;
哨兵也是一台redis服务器,只是不提供数据服务; set, get 操作不了;
通常哨兵配置数量为单数;
哨兵的配置文件: sentinel.conf
启动哨兵: redis-sentinel sentinel-26379.conf ; redis-sentinel sentinel-26380.conf ;
查看sentinel.conf 内容 : cat sentinel.conf | grep -v "#" 查看文件, 过滤掉注释
port 26379 哨兵服务对外的端口
dir /tmp 目录
sentinel monitor mymaster 127.0.0.1 6379 2 监控的主服务 mymaster 是 127.0.0.1 6379
2: 超过2个哨兵任务他挂了,他就挂了;
2为判断标准数, 总哨兵数的 一半+1 ;
sentinel down-after-milliseconds mymaster 30000 连接主服务mymaster 超过30秒没响应,认为挂了;
sentinel parallel-syncs mymaster 1 在新的主服务启动后, 进行数据同步;
1表示 同时给1个从同步数据;
配置几条线开始数据同步
sentinel failover-timeout mymaster 180000 同步数据 超时设定, 180秒
20: redis集群
将所有的存储空间计划切割成16384份,每台主机保存一部分,每份代表的是一个存储空间,不是一个key的保存空间, 将key按照计算出的结果放到对应的存储空间;
各个数据库相互通信,保存各个库中槽的编号数据
一次命中,直接返回
一次未命中,告知具体位置
21.0 : cluster集群结构搭建:
1: 配置文件 redis-6379.conf : 添加配置:
cluster-enabled yes 启动节点, 启动cluster节点;
cluster-config-file nodes-6379.conf 每个cluster都有一个自己的配置文件,区分不同的配置文件
cluster-node-timeout 15000 节点服务响应的超时时间, 15秒
2: 复制 redis.conf 到 redis-6379.conf , redis-6380.conf , redis-6381.conf, redis-6382.conf,redis-6383.conf,redis-6384.conf
3: 指令是 redis-trib.rb, 目录 cd /redis-4.0/src
这个指令需要按照 ruby, gem 指令包; 执行安装gem命令: yum install rubygems -y
4: 执行指令:
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
create : 创建 cluster集群
--replicas 1 : 指定 1个主master 带1个从 slave; --replicas 2 : 指定1个主带2从;
21.1: 问题: 执行命令 错误提示: redis requires Ruby version >= 2.4.0 ; redis 对 ruby版本 有要求;
解决: 升级ruby, 升级之前装个rvm; rvm安装成功后, 查看ruby版本: rvm list known ;
选择版本安装: rvm install 2.5 ; 查看安装完成后的版本: ruby -v ;
安装 redis-xxx.gem: gem install redis ;
21.2: rvm安装:
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
curl -sSL https://rvm.io/pkuczynski.asc | gpg2 --import -
curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
引用连接: Linux rvm 安装教程_Wjhsmart的博客-CSDN博客
21.3: 问题: 在执行该启动命令后
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382
*** ERROR: Invalid configuration for cluster creation.
*** Redis Cluster requires at least 3 master nodes.
*** This is not possible with 4 nodes and 1 replicas per node.
*** At least 6 nodes are required.
***错误:创建集群的配置无效。
*** Redis集群需要至少3个主节点。
***这是不可能的4个节点和每个节点1个副本。
***至少需要6个节点。
4个节点不够,得至少要6个:
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
21.4: 在cluster集群后, 多个redis把整个空间进行了划分; 在存取数据时发生变化;
客户端连接: redis-cli -c -p 6380 ; set name 222 ; 会自动分配到对应的空间;
21.5: cluster的nodes.conf 文件 , 记录了主从的信息, 当主,从,有挂掉,有启动的时候, 该文件的信息会随之改变, 更新主从的信息;
cat nodes-6384.conf 查看主从的信息;
cluster nodes 查看主从的信息;
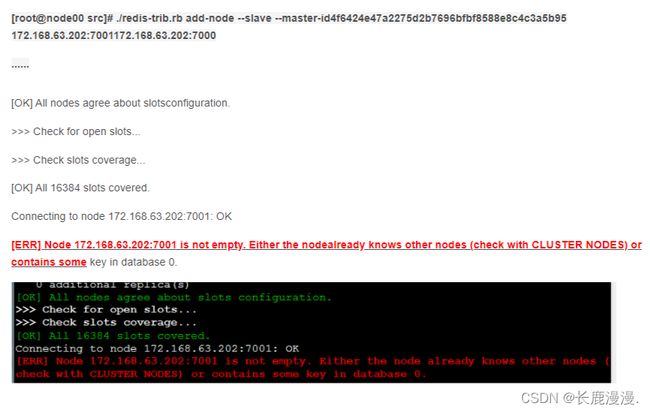
21.6: redis 的 cluster启动报错: 提示新增的Node不为空:
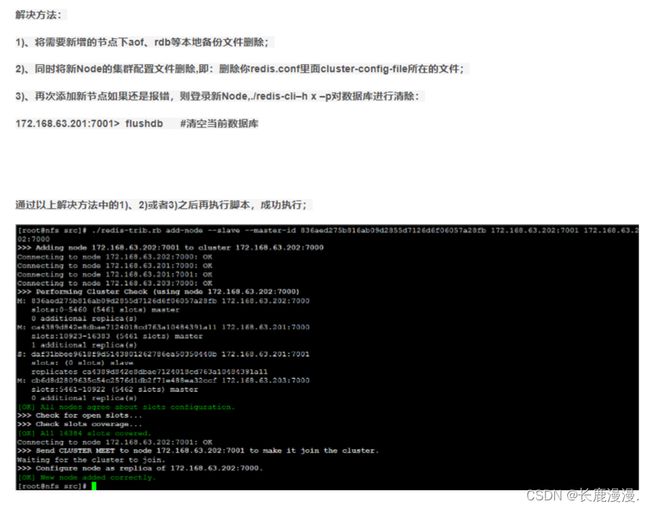
解决方法:
1)、将需要新增的节点下aof、rdb等本地备份文件删除;
2)、同时将新Node的集群配置文件删除,即:删除你redis.conf里面cluster-config-file所在的文件;
引用: [ERR] Node is not empty. Either the node already knows other nodes (check with C_漫天雪_昆仑巅-CSDN博客 https://blog.csdn.net/vtopqx/article/details/50235737 然后重新启动;
https://blog.csdn.net/vtopqx/article/details/50235737 然后重新启动;
Redis (全称:Remote Dictionary Server 远程字典服务)是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它是一个运行在内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
我们平时在项目中设计数据访问的时候往往都是采用直接访问数据库,采用数据库连接池来实现,但是如果我们的项目访问量过大或者访问过于频繁,将会对我们的数据库带来很大的压力。为了解决这个问题从而redis数据库脱颖而出,redis数据库出现时是以非关系数据库的光环展示在广大程序猿的面前的,后来redis的迭代版本支持了缓存数据、登录session状态(分布式session共享)等。所以又被作为内存缓存的形式应用到大型企业级项目中。
Redis是什么?
主流的理解有以下三种
1.key value store.是一个以key-value形式存储的数据库,定位直指MySQL,用来作为唯一的存储系统。
2.memory cache.是一个把数据存储在内存中的高速缓存,用来在应用和数据库间提供缓冲,替代memcachd。
3.data structrue server.把它支持对复杂数据结构的高速操作作为卖点,提供某些特殊业务场景的计算和展现需求。比如排行榜应用,Top 10之类的。
Redis特点
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。这主要归功于这些数据都存在于内存中,并且是单线程。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子性 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe(发布/订阅)、通知,、key 过期、Lua 脚本、事务、Pipeline(管道,即当指令到达一定数量后,客户端才会执行)等等特性。
兼容性强 – 支持多种编程语言。支持Java、PHP、Golang、Python、Ruby、Lua、Nodejs等。
高可用和分布式 – Redis-Sentinel(v2.8)支持高可用,Redis-Cluster(v3.0)支持分布式
Redis使用场景
1、缓存——热数据
这是 Redis 使用最多的场景。Redis 能够替代 Memcached,让你的缓存从只能存储数据变得能够更新数据,因此你不再需要每次都重新生成数据。
2、计数器
诸如统计点击数、转发数、评论数等应用。由于单线程,可以避免并发问题,保证不会出错,而且100%毫秒级性能!爽。 命令:INCRBY 当然爽完了,别忘记持久化,毕竟是redis只是存了内存!
3、消息队列
相当于消息系统,运行稳定并且快速,支持模式匹配,能够实时订阅与取消频道,和ActiveMQ,RocketMQ等工具类似,但是个人觉得简单用一下还行,如果对于数据一致性要求高的话还是用RocketMQ等专业系统。 由于redis把数据添加到队列是返回添加元素在队列的第几位,所以可以做判断用户是第几个访问这种业务 队列不仅可以把并发请求变成串行,并且还可以做队列或者栈使用
4、位操作(大数据处理)
用于数据量上亿的场景下,例如几亿用户系统的签到,去重登录次数统计,某用户是否在线状态等等。 腾讯10亿用户,要几毫秒内查询到某个用户是否在线,你能怎么做?千万别说给每个用户建立一个key,然后挨个记(你可以算一下需要的内存会很恐怖,而且这种类似的需求很多,腾讯光这个得多花多少钱。。)这里要用到位操作——使用setbit、getbit、bitcount命令。
原理是: redis内构建一个足够长的数组,每个数组元素只能是0和1两个值,然后这个数组的下标index用来表示我们上面例子里面的用户id(必须是数字哈),那么很显然,这个几亿长的大数组就能通过下标和元素值(0和1)来构建一个记忆系统,上面我说的几个场景也就能够实现。用到的命令是:setbit、getbit、bitcount。
5、分布式锁与单线程机制
验证前端的重复请求(可以自由扩展类似情况),可以通过redis进行过滤:每次请求将request Ip、参数、接口等hash作为key存储redis(幂等性请求),设置多长时间有效期,然后下次请求过来的时候先在redis中检索有没有这个key,进而验证是不是一定时间内过来的重复提交 秒杀系统,基于redis是单线程特征,防止出现数据库“爆破” 全局增量ID生成,类似“秒杀”
6、最新列表
例如新闻列表页面最新的新闻列表,如果总数量很大的情况下,尽量不要使用select a from A limit 10这种low货,尝试redis的 LPUSH命令构建List,一个个顺序都塞进去就可以啦。不过万一内存清掉了咋办?也简单,查询不到存储key的话,用mysql查询并且初始化一个List到redis中就好了。
7、排行榜
谁得分高谁排名往上。命令:ZADD(有续集,sorted set)
原文: Redis 的概念理解 - 知乎
------------------------------------------------------------
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
这里就不将redis是怎么安装和配置的了,大家自行在CSDN的其他博客看看,这个博客主要分享的是,Java使用jedis库去操作redis。本篇涉及了redis的5种基本数据类型的最基本操作:string、list、set、hash、zset,以及简单的redis消息队列的使用。
jedis是官方推荐的,使用java操作redis的类库,目前官网的最新稳定版是2.9,推荐大家使用maven或者gradle去构建项目,maven所需的jedis的依赖如下
其实这个依赖只有3个jar包,jedis-2.9.0.jar,commons-pool-1.6.jar,commons-pool2-2.4.2.jar,后面的两个common的pool包,是配置jedis的连接池用的,如果不想使用连接池,那么只要导入jedis-2.9.0.jar就够了。
不多说了,直接上代码吧,jedis的这些api,和redis-cli命令是一样的,所以只要熟悉redis-cli的命令,那个jedis的api就可以驾轻就熟了。
redis.clients
jedis
2.9.0
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.JedisPubSub;
import redis.clients.jedis.ZParams;
/**
* redis常用api
*
* @author Kazz
*
*/
public class RedisDemo {
private static JedisPool jedisPool = null;
public static void main(String[] args) throws Exception {
// 这个是最简单的redis连接示例,不过不推荐,推荐使用数据库连接池
// Jedis jedis = new Jedis("192.168.8.128", 6379);// 连接 Redis 服务
// jedis.auth("123456"); // 设置密码
// System.out.println("Server is running: " + jedis.ping());//
// 查看服务是否运行
init();
string();
list();
set();
sets();
hash();
zset();
zsets();
publisher();
subscribe();
}
/**
* 初始化redis连接池
*/
private static void init() {
JedisPoolConfig config = new JedisPoolConfig(); // Jedis连接池
config.setMaxIdle(8); // 最大空闲连接数
config.setMaxTotal(8);// 最大连接数
config.setMaxWaitMillis(1000); // 获取连接是的最大等待时间,如果超时就抛出异常
config.setTestOnBorrow(false);// 在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的;
config.setTestOnReturn(true);
jedisPool = new JedisPool(config, "192.168.8.128", 6379, 5000, "123456", 0); // 配置、ip、端口、连接超时时间、密码、数据库编号(0~15)
}
/**
* string类型的基本操作,string是redis的最基本数据类型,很多操作都是其他数据类型能用的,如del、exists、expire
*
* @throws Exception
*
*/
private static void string() throws Exception {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
jedis.set("testString", "123"); // 往redis中放入字符串
System.out.println("从redis中获取刚刚放进去的testString:" + jedis.get("testString"));
jedis.incr("testString"); // 自增,不存在testInt则自增结果是1,如果不是字符串,自增会报JedisDataException
System.out.println("从redis中获取自增后的testString:" + jedis.get("testString"));
jedis.decr("testString"); // 自减,效果同自增
System.out.println("从redis中获取自减后的testString:" + jedis.get("testString"));
// incrby方法可以自定要增加多少
jedis.append("testString", "456abcd"); // 在后面追加
System.out.println("从redis中获取追加后的testString:" + jedis.get("testString"));
String sub = jedis.substr("testString", 2, 6); // 切割字符串
System.out.println("substr方法的返回值:" + sub);
System.out.println("从redis中获取切割后的testString:" + jedis.get("testString")); // 可以看出,substr方法并不会破坏原有值,只是取出来加工而已
jedis.rename("testString", "newString"); // 字段改名,值不会变
System.out.println("testString改名成newString后,值为:" + jedis.get("newString"));
String type = jedis.type("newString");// 获取其数据类型
System.out.println("newString的数据类型是:" + type);
long length = jedis.strlen("newString"); // 获取字符串长度
System.out.println("newString的字符串长度为:" + length);
jedis.set("testString6", "哈哈");
jedis.set("testString7", "呵呵");
jedis.set("testString8", "helloword");
jedis.set("testString99", "SMSP");
Set keys = jedis.keys("*"); // 获取所有符合条件的键
System.out.println("返回redis中所有的键:" + keys);
keys = jedis.keys("*String?");
System.out.println("返回redis中所有正则符合*String?的键:" + keys);
jedis.del("testString"); // 字符串删除
System.out.println("从redis删除testInt后,testInt是否还存在:" + jedis.exists("testString"));
System.out.println();
jedis.set("testString2", "你好啊!!!");
jedis.expire("testString2", 2); // 设置有效期,单位是秒
System.out.println("从redis中获取testString2的值为:" + jedis.get("testString2"));
Thread.sleep(3000);
System.out.println("3秒后从redis中获取testString2的值为:" + jedis.get("testString2")); // 过期了,会找不到该字段,返回null
// ttl方法可以返回剩余有效时间,expire如果方法不指定时间,就是将该字段有效期设为无限
System.out.println();
System.out.println();
jedis.close();
}
/**
* list类的基本操作,有序可重复
*
*/
private static void list() {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
// 列表的插入与获取(可以重复)
jedis.lpush("testList", "Redis"); // 从左边插入
jedis.lpush("testList", "Mongodb");
jedis.lpush("testList", "Mysql");
jedis.lpush("testList", "Mysql");
jedis.rpush("testList", "DB2"); // 从右边插入
List list = jedis.lrange("testList", 0, -1); // 从左到右遍历,3个参数分别是,key,开始位置,结束位置(-1代表到最后)
for (int i = 0; i < list.size(); i++) {
System.out.printf("从redis中获取刚刚放进去的testList[%d]: %s\n", i, list.get(i));
}
System.out.println();
String lpop = jedis.lpop("testList"); // 删掉最左边的那个
String rpop = jedis.rpop("testList"); // 删掉最右边的那个
System.out.printf("被删的左边元素是:%s,被删的右边元素是:%s\n", lpop, rpop);
list = jedis.lrange("testList", 0, -1);
for (int i = 0; i < list.size(); i++) {
System.out.printf("从redis中获取被删除后的testList[%d]: %s\n", i, list.get(i));
}
System.out.println();
jedis.ltrim("testList", 1, 2); // 裁剪列表,三个参数分别是,key,开始位置,结束位置
list = jedis.lrange("testList", 0, -1);
for (int i = 0; i < list.size(); i++) {
System.out.printf("从redis中获取被裁剪后的testList[%d]: %s\n", i, list.get(i));
}
jedis.del("testList"); // 删除列表
System.out.println("从redis删除testList后,testList是否还存在:" + jedis.exists("testList"));
System.out.println();
System.out.println();
jedis.close();
}
/**
* 集合类型的基本操作,无序不重复
*/
private static void set() {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
jedis.sadd("testSet", "lida", "wch", "chf", "lxl", "wch"); // 添加元素,不可重复
Set set = jedis.smembers("testSet"); // 获取集合中的全部元素
System.out.println("从testSet中获取的元素:" + set);
long length = jedis.scard("testSet"); // 求集合的长度
System.out.println("\n获取testSet的长度:" + length);
System.out.println();
jedis.srem("testSet", "wch"); // 从testSet移除wch
set = jedis.smembers("testSet");
System.out.println("从testSet中获取移除后的的元素:" + set);
System.out.println();
boolean exist = jedis.sismember("testSet", "lida"); // 判断元素是否包含在该集合中
System.out.println("检查lida是否包含在testSet中:" + exist);
System.out.println();
String spop = jedis.spop("testSet");// 随机的移除spop中的一个元素,并返回它
System.out.println("testSet中被随机移除的元素是:" + spop);
System.out.println();
jedis.del("testSet"); // 删除整个集合
System.out.println("删除后,testSet是否还是存在:" + jedis.exists("testSet"));
System.out.println();
System.out.println();
jedis.close();
}
/**
* 集合之间的运算,交集、并集、差集
*/
private static void sets() {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
jedis.sadd("set1", "a", "b", "c", "d");
jedis.sadd("set2", "b", "c", "e");
Set set = jedis.sdiff("set1", "set2"); // 求两个集合的差集(只会返回存在于1,但2不存在的)
System.out.println("求出两个集合之间的差集:" + set); // 会输出a和d
// 还有一个sdiffstore的api,可以把sdiff的计算结果赋值到另一个set中,下面的交集和并集也类似
System.out.println();
set = jedis.sinter("set1", "set2"); // 求两个集合的交集
System.out.println("求出两个集合之间的交集:" + set); // 会输出b和c
System.out.println();
set = jedis.sunion("set1", "set2"); // 求两个集合的并集
System.out.println("求出两个集合之间的并集:" + set);
System.out.println();
System.out.println();
jedis.close();
}
/**
* 散列的基本操作,键值对里面还有键值对,经常用来存储多个字段信息,也可以理解为存放一个map,散列是redis的存储原型
*/
private static void hash() {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
Map map = new HashMap();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
map.put("k4", "123");
jedis.hmset("hash1", map); // 存放一个散列
Map getMap = jedis.hgetAll("hash1"); // 从redis中取回来
System.out.println("从redis中取回的hash1散列:" + getMap.toString());
System.out.println();
List hmget = jedis.hmget("hash1", "k1", "k3"); // 从散列中取回一个或多个字段信息
System.out.println("从hash1散列中两个字段来看看:" + hmget);
System.out.println();
jedis.hdel("hash1", "k1"); // 删除散列中的一个或者多个字段
getMap = jedis.hgetAll("hash1");
System.out.println("从redis中取回的被删除后的hash1散列:" + getMap);
System.out.println();
long length = jedis.hlen("hash1"); // 求出集合的长度
System.out.println("散列hash1的长度为:" + length);
System.out.println();
boolean exists = jedis.hexists("hash1", "k5"); // 判断某个字段是否存在于散列中
System.out.println("k5字段是否存在于散列中:" + exists);
System.out.println();
Set keys = jedis.hkeys("hash1"); // 获取散列的所有字段名
System.out.println("hash1的所有字段名:" + keys);
System.out.println();
List values = jedis.hvals("hash1"); // 获取散列的所有字段值,实质的方法实现,是用上面的hkeys后再用hmget
System.out.println("hash1的所有字段值:" + values);
System.out.println();
jedis.hincrBy("hash1", "k4", 10); // 给散列的某个字段进行加法运算
System.out.println("执行加法运行后的hash1散列:" + jedis.hgetAll("hash1"));
System.out.println();
jedis.del("hash1"); // 删除散列
System.out.println("删除hash1后,hash1是否还存在redis中:" + jedis.exists("hash1"));
System.out.println();
System.out.println();
jedis.close();
}
/**
* 有序集合的基本使用,zset是set的升级版,在无序的基础上,加入了一个权重,使其有序化
* 另一种理解,zset是hash的特殊版,一样的存放一些键值对,但这里的值只能是数字,不能是字符串
* zset广泛应用于排名类的场景
*/
private static void zset() {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
Map map = new HashMap();
map.put("wch", 24.3); // 这里以小组成员的年龄来演示
map.put("lida", 30.0);
map.put("chf", 23.5);
map.put("lxl", 22.1);
map.put("wch", 24.3); // 这个不会被加入,应该重复了
jedis.zadd("zset1", map); // 添加一个zset
Set range = jedis.zrange("zset1", 0, -1); // 从小到大排序,返回所有成员,三个参数:键、开始位置、结束位置(-1代表全部)
// zrange方法还有很多衍生的方法,如zrangeByScore等,只是多了一些参数和筛选范围而已,比较简单,自己看看api就知道了
System.out.println("zset返回的所有从小大到排序的成员:" + range);
System.out.println("");
Set revrange = jedis.zrevrange("zset1", 0, -1); // 从大到小排序,类似上面的range
System.out.println("zset返回的所有排序的成员:" + revrange);
System.out.println("");
long length = jedis.zcard("zset1"); // 求有效长度
System.out.println("zset1的长度:" + length);
System.out.println();
long zcount = jedis.zcount("zset1", 22.1, 30.0); // 求出zset中,两个成员的排名之差,注意不是求长度,
System.out.println("zset1中,22.1和30.0差了" + zcount + "名");
System.out.println();
long zrank = jedis.zrank("zset1", "wch"); // 求出zset中某成员的排位,注意第一是从0开始的
System.out.println("wch在zset1中排名:" + zrank);
System.out.println();
double zscore = jedis.zscore("zset1", "lida"); // 获取zset中某成员的值
System.out.println("zset1中lida的值为:" + zscore);
System.out.println();
jedis.zincrby("zset1", 10, "lxl"); // 给zset中的某成员做加法运算
System.out.println("zset1中lxl加10后,排名情况为:" + jedis.zrange("zset1", 0, -1));
System.out.println();
jedis.zrem("zset1", "chf"); // 删除zset中某个成员
// zrem还有衍生的zremByScore和zremByRank,分别是删除某个分数区间和排名区间的成员
System.out.println("zset1删除chf后,剩下:" + jedis.zrange("zset1", 0, -1));
System.out.println();
jedis.close();
}
/**
* 有序集合的运算,交集、并集(最小、最大、总和)
*/
private static void zsets() {
Jedis jedis = jedisPool.getResource();
jedis.flushDB(); // 清空数据库
Map map1 = new HashMap();
map1.put("wch", 24.3); // 这里以小组成员的年龄来演示
map1.put("lida", 30.0);
map1.put("chf", 23.5);
map1.put("lxl", 22.1);
Map map2 = new HashMap();
map2.put("wch", 24.3);
map2.put("lly", 29.6);
map2.put("chf", 23.5);
map2.put("zjl", 21.3);
jedis.zadd("zset1", map1);
jedis.zadd("zset2", map2);
System.out.println("zset1的值有:" + jedis.zrangeWithScores("zset1", 0, -1));
System.out.println("zset2的值有:" + jedis.zrangeWithScores("zset2", 0, -1));
System.out.println();
jedis.zinterstore("zset_inter", "zset1", "zset2"); // 把两个集合进行交集运算,运算结果赋值到zset_inter中
System.out.println("看看两个zset交集运算结果:" + jedis.zrangeWithScores("zset_inter", 0, -1));
jedis.zunionstore("zset_union", "zset1", "zset2");// 把两个集合进行并集运算,运算结果赋值到zset_union中
System.out.println("看看两个zset并集运算结果:" + jedis.zrangeWithScores("zset_union", 0, -1));
System.out.println("可以看出,zset的交集和并集计算,默认会把两个zset的score相加");
ZParams zParams = new ZParams();
zParams.aggregate(ZParams.Aggregate.MAX);
jedis.zinterstore("zset_inter", zParams, "zset1", "zset2"); // 通过指定ZParams来设置集合运算的score处理,有MAX MIN SUM三个可以选择,默认是SUM
System.out.println("看看两个zset交集max运算结果:" + jedis.zrangeWithScores("zset_inter", 0, -1));
//zrangeWithScores返回的是一个Set类型,如果直接把这个集合打印出来,会把zset的key转成ascii码,看起来不直观,建议还是使用foreach之类的遍历会好看一些
jedis.close();
}
/**
* 发布消息,类似于mq的生产者
*/
private static void publisher() {
new Thread() {
public void run() {
try {
Thread.sleep(1000); // 休眠一下,让订阅者有充足的时间去连上
Jedis jedis = jedisPool.getResource();
jedis.flushAll();
for (int i = 0; i < 10; i++) {
jedis.publish("channel", "要发送的消息内容" + i); // 每隔一秒推送一条消息
System.out.printf("成功向channel推送消息:%s\n", i);
Thread.sleep(1000);
}
jedis.close();
} catch (Exception e) {
e.printStackTrace();
}
};
}.start();
}
/**
* 订阅消息,类似与mq的消费者
*
*/
private static void subscribe(){
Jedis jedis = jedisPool.getResource();
jedis.flushAll();
JedisListener listener = new JedisListener();
listener.proceed(jedis.getClient(), "channel"); // 开始监听channel频道的消息
//listener.unsubscribe(); //取消监听
jedis.close();
}
/**
* 重写监听器的一些重要方法,JedisPubSub里面的这些回调方法都是空的,不重写就什么事都不会发生
*
* @author Kazz
*
*/
private static class JedisListener extends JedisPubSub {
/**
* 收到消息后的回调
*/
@Override
public void onMessage(String channel, String message) {
System.out.println("onMessage: 收到频道[" + channel + "]的消息[" + message + "]");
}
@Override
public void onPMessage(String pattern, String channel, String message) {
System.out.println("onPMessage: channel[" + channel + "], message[" + message + "]");
}
/**
* 成功订阅频道后的回调
*/
@Override
public void onSubscribe(String channel, int subscribedChannels) {
System.out
.println("onSubscribe: 成功订阅[" + channel + "]," + "subscribedChannels[" + subscribedChannels + "]");
}
/**
* 取消订阅频道的回调
*/
@Override
public void onUnsubscribe(String channel, int subscribedChannels) {
System.out.println(
"onUnsubscribe: 成功取消订阅[" + channel + "], " + "subscribedChannels[" + subscribedChannels + "]");
}
@Override
public void onPUnsubscribe(String pattern, int subscribedChannels) {
System.out.println(
"onPUnsubscribe: pattern[" + pattern + "]," + "subscribedChannels[" + subscribedChannels + "]");
}
@Override
public void onPSubscribe(String pattern, int subscribedChannels) {
System.out.println(
"onPSubscribe: pattern[" + pattern + "], " + "subscribedChannels[" + subscribedChannels + "]");
}
}
}
原文链接:https://blog.csdn.net/z23546498/article/details/73556260