实现稳定的联合显著性检测和联合目标分割
1 Title
Toward Stable Co-Saliency Detection and Object Co-Segmentation(Bo Li; Lv Tang; Senyun Kuang; Mofei Song; Shouhong Ding)【IEEE Transactions on Image Processing 2022】
2 Conclusion
This paper present a novel model for simultaneous stable co-saliency detection (CoSOD) and object co-segmentation (CoSEG). Inspired by RNN-based model, this paper first propose a multi-path stable recurrent unit (MSRU), containing dummy orders mechanisms (DOM) and recurrent unit (RU). Proposed MSRU not only helps CoSOD (CoSEG) model captures robust inter-image relations, but also reduces order-sensitivity, resulting in a more stable inference and training process.
Moreover, this paper design a cross-order contrastive loss (COCL) that can further address order-sensitive problem by pulling close the feature embedding generated from different input orders.
3 Good Sentences
1、Since there is much noise information in single image or image-pair features and the appearance as well as the location of co-salient object varies across different images or image-pair, only simple adding operation cannot capture these variations.(The situation of method which based on CNN)
2、Since there is much noise information in single image or image-pair features and the appearance as well as the location of co-salient object varies across different images or image-pair, only simple adding operation cannot capture these variations.(The problem of the method which based on RNN)
3、For an input image group with an arbitrary size, our network first uses CNN to extract the semantic features of all images. Then the single image representation (SIR) branch processes each image individually to learn the intra-saliency.(The principal of the proposed method)
introduction
图像的联合显著性检测(CoSOD)和联合目标分割(CoSEG)是计算机视觉领域的两个重要课题,通常作为计算机视觉的下游任务。这两项任务高度相关,但又不完全相同。对于一组图像,为了准确地检测(分割)共存对象(即不同的图像中相同的目标对象),这两项任务都需要对常见对象之间的协同关系进行建模。尽管共存对象从语义信息的角度来说是同类,但它们的显式类别属性在 CoSOD 或 CoSEG 任务中是未知的。也就是说,CoSOD或CoSEG方法不应该通过使用对特定类别标签或其他信息(如时间关系)的监督学习得到常见对象的一致性关系。
CoSOD捕获单个图像中潜在的联合显著性物体的显著性(Intra-saliency)。核心问题是如何稳定地模拟图像组之间的显著性间关系。
基于CNN和基于图的方法的主要缺点是它们需要恒定的输入数据,并且CNN方法存在子组不稳定性。在处理包含可变数量图像的图像组时,这些基于CNN的方法和基于图形的方法通过将图像组划分为图像对或图像子组来检测共同突出的对象。
基于RNN的方法可以调整每个图像组中不固定数量的图像,并利用图像组中的所有可用信息。但是RNN方法存在顺序敏感性问题,RNN只广泛应用于具有严格顺序关系的任务。
针对上述问题,本文首先提出了一种包含虚拟顺序机制(DOM)和递归单元(RU)的多路径稳定递归单元(MSRU),为了捕捉长程关系,本文设计了一种新型的复位门式非局部交叉注意力(NLCA)和新型的更新门式协同注意力特征投影模块(CFPM),以充分挖掘图像组中的公共语义。
在捕获图像组不同图像之间显著性关系后,另一个单个图像表示提取分支(SIR)单独处理每个图像,以学习单个图像内的显著性关系。最后,通过非局部注意力进一步融合了这两个分支的输出,这鼓励了群体和单一表征之间的丰富交互,以促进鲁棒的协同显著性检测推理。
此外,本文还设计了一种跨顺序对比损失(COCL)来进一步消除不同输入顺序的影响,它能够拉近由不同顺序生成的群特征嵌入。增强网络鲁棒性。
 标联合显著性检测,本文的方法与目前先进的工作比较
标联合显著性检测,本文的方法与目前先进的工作比较
Related Work
联合对象检测和联合目标分割我在综述的论文看过了,这里只关注RNN,循环神经网络的部分。
RNN最流行的变体包括长短期记忆(LSTM)和门控循环单元(GRU)。常见的LSTM单元由一个单元和三个门(忘记门、输入门和输出门)组成,旨在能够学习长期依赖关系。最近,RNN(尤其是 LSTM 和 GRU)被引入到时空任务(称为卷积 RNN)中。而在联合显著性检测任务中,显著性物体的位置在不同图像中差异很大。LSTM 或 GRU 中的不同门无法处理这些复杂的变化。为了解决这个问题,RCAN提出了协同注意力机制来很好地模拟这些相互关系。然而,RCAN 的主要缺点是它使网络对数据输入顺序很敏感。因此,在本文中,进一步设计了一种多路径稳定递归循环MSRU来解决顺序敏感问题。
Proposed Method

所提出的网络结构如图所示,联合显著性检测旨在从一组相关的N个图像![]() 中获取所有相关对象的掩码
中获取所有相关对象的掩码![]() 。对于任意大小的输入图像组,该网络首先使用 CNN 提取所有图像的语义特征。然后,单图像表示 (SIR) 单独处理每个图像以学习图像的内部显著性
。对于任意大小的输入图像组,该网络首先使用 CNN 提取所有图像的语义特征。然后,单图像表示 (SIR) 单独处理每个图像以学习图像的内部显著性![]() 同时,多路径稳定循环单元(MSRU)循环探索图像组中的所有图像以学习鲁棒组表示
同时,多路径稳定循环单元(MSRU)循环探索图像组中的所有图像以学习鲁棒组表示 ![]() 。最后,通过非局部融合模块进一步融合这两个分支的输出,以实现稳定的联合显著性检测。网络的损失函数包含联合显著性损失和跨顺序对比损失(COCL)。
。最后,通过非局部融合模块进一步融合这两个分支的输出,以实现稳定的联合显著性检测。网络的损失函数包含联合显著性损失和跨顺序对比损失(COCL)。
Intra-Saliency Learning
作为联合显著性检测的基本规则,了解每个图像的独特属性以捕获单个图像中潜在的联合对象非常重要,于输入组![]() 中的每个图像
中的每个图像![]() ,首先使用预先训练的VGG16来提取语义特征,按照这个短链接深度监督目标检测将另一条侧路径连接到 VGG-16 中的最后一个池化层,这样就能从主干网络中得到了六个侧面特征:Conv1-2、Conv2-2、Conv3-3、Conv4-3、Conv5-3和Conv6-3。在将从VGG中提取的侧面特征发送到SIR之前,我们首先使用 1×1 卷积运算来减少其通道数以节省计算。 简单起见,我们将侧面特征Conv6-3命名为
,首先使用预先训练的VGG16来提取语义特征,按照这个短链接深度监督目标检测将另一条侧路径连接到 VGG-16 中的最后一个池化层,这样就能从主干网络中得到了六个侧面特征:Conv1-2、Conv2-2、Conv3-3、Conv4-3、Conv5-3和Conv6-3。在将从VGG中提取的侧面特征发送到SIR之前,我们首先使用 1×1 卷积运算来减少其通道数以节省计算。 简单起见,我们将侧面特征Conv6-3命名为![]() 所以镜像组的侧面特征可以写成
所以镜像组的侧面特征可以写成![]() ,然后在
,然后在![]() 构建SIR块以捕获每个图像的内部显著性
构建SIR块以捕获每个图像的内部显著性![]() ,SIR 包含三个卷积块,每个块包含一个
,SIR 包含三个卷积块,每个块包含一个![]() ,3×3 卷积运算,然后是批量归一化和 ReLU 激活函数,本文在三个层次的骨干网络(Conv4-3、Conv5-3 和 Conv6-3)上捕获了显著性内和显著性之间的关系。为了简单起见,本文仅展示了 Conv6-3 中的图内显著性学习和图间显著性关系捕获。
,3×3 卷积运算,然后是批量归一化和 ReLU 激活函数,本文在三个层次的骨干网络(Conv4-3、Conv5-3 和 Conv6-3)上捕获了显著性内和显著性之间的关系。为了简单起见,本文仅展示了 Conv6-3 中的图内显著性学习和图间显著性关系捕获。
Inter-Saliency Relations Capturing
由于图像组内的图像以不同的方式(例如共同对象、相似类别和相关场景)在上下文中相互关联,因此学习包含组图像之间的相关性和交互性的鲁棒组表示对于联合显著性引用极为重要。,MSRU可以收集不同阶次的特征,用于最终的群特征生成。
 多路径稳定循环单元(MSRU),其中包含虚拟顺序机制(DOM)和循环单元(RU)
多路径稳定循环单元(MSRU),其中包含虚拟顺序机制(DOM)和循环单元(RU)
包含N个图像的图像序列的特征表示记为: ![]() 。首先通过
。首先通过![]() 的滑动窗口将原始序列划分为几个子组
的滑动窗口将原始序列划分为几个子组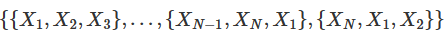 。将图像序列视为一个循环。那么每个子图像组的组特征可以表示为
。将图像序列视为一个循环。那么每个子图像组的组特征可以表示为![]() ,本文首先从三个不同的阶次生成每个子图像组的多路径特征表示
,本文首先从三个不同的阶次生成每个子图像组的多路径特征表示![]() ,然后用
,然后用![]() 来生成最终的特征
来生成最终的特征![]()
MSRU,如上图所示,包含虚拟顺序机制(DOM)和循环单元(RU)。可以看出,如果一个子组![]() 只包含三个图像
只包含三个图像![]() OM 将生成该组的三个不同顺序 {“ ”, “ ”, “ X1→X2→XN X2→XN→X1 XN→X1→X2 ”}。然后,我们提出一个 RU 来生成这三个不同阶的三个组特征表示。最后,我们将这三个组特征表示连接起来,实现该子组的多路径组
OM 将生成该组的三个不同顺序 {“ ”, “ ”, “ X1→X2→XN X2→XN→X1 XN→X1→X2 ”}。然后,我们提出一个 RU 来生成这三个不同阶的三个组特征表示。最后,我们将这三个组特征表示连接起来,实现该子组的多路径组![]() 特征表示。
特征表示。
RU

以前的RCAU的两个关键模块是复位门和更新门。复位门的目标是利用图像组的特征与当前图像之间的共同关系来抑制当前图像中的噪声数据,但是简单恶的卷积效果不是很好,如果这两个特征的共显著性区域差异很大,简单的卷积运算不能很好地抑制噪声数据。
本文设计了一种新的非局域交叉注意力(NLCA)来完全抑制噪声数据。具体来说,NLCA的输入是组特征表示和单图像表示![]() 。运行过程:第一步:
。运行过程:第一步:![]() 使用
使用![]() (表示第k个图像子组的第n个特征)进行初始化,对于 Query 分支,在上添加一个 1×1 卷积层,并将特征重塑为
(表示第k个图像子组的第n个特征)进行初始化,对于 Query 分支,在上添加一个 1×1 卷积层,并将特征重塑为![]() ,在
,在![]()
![]() 的转置相乘之后,用 softmax 函数来计算空间注意力图
的转置相乘之后,用 softmax 函数来计算空间注意力图 A的每个像素值定义为
A的每个像素值定义为 其中 i∈[1,L] , A(i,j) 测量图像组特征中的第j个位置对单个图像特征中的第i个位置的影响。
其中 i∈[1,L] , A(i,j) 测量图像组特征中的第j个位置对单个图像特征中的第i个位置的影响。
同时,与 Key 分支一样,从 Value 分支生成特征![]() ,对其的转置与A进行矩阵相乘得到去噪特征
,对其的转置与A进行矩阵相乘得到去噪特征![]()
 ,最后把reshape
,最后把reshape![]() ,并加上
,并加上![]()
更新门的目标是确定组特征中应保留哪些组信息,以及应从当前图像特征更新哪些新信息,本文提出了一个共注意力特征投影模块(CFPM),将图像和组特征投影到公共特征子空间,这有助于弥合组特征和图像特征之间的差距。
 蓝色 复位门,红色 更新门
蓝色 复位门,红色 更新门
首先,采用金字塔池化模块(PPM )来降低特征图![]() 和
和![]() 的维度,PPM 由四个尺度的特征条柱组成,将它们展平并连接起来,形成一个大小
的维度,PPM 由四个尺度的特征条柱组成,将它们展平并连接起来,形成一个大小![]() C为通道数,
C为通道数,![]() 的自亲和(self-affinity)矩阵可以被定义为:
的自亲和(self-affinity)矩阵可以被定义为: ,其中,
,其中,![]() 是特异特征相似度矩阵,它们的大小固定为
是特异特征相似度矩阵,它们的大小固定为![]() ,并且矩阵是不对称。
,并且矩阵是不对称。![]() 代表可学习参数,进一步组合这两个矩阵:
代表可学习参数,进一步组合这两个矩阵:![]()
最后使用逐行归一化矩阵![]() 来辅助组特征和图像特征的更新:
来辅助组特征和图像特征的更新:

在本文中,上述过程将重复三次,以获得一个顺序的组特征![]() 最后,将三个不同阶次的组特征连接起来,生成每个子组的多路径组特征
最后,将三个不同阶次的组特征连接起来,生成每个子组的多路径组特征![]() 。
。
Co-Saliency Detection With Fused Representation
将组特征广播到每个图像,这允许网络利用图像之间的协同信息和独特属性。因此,图像组表示![]() 和图像单一表示
和图像单一表示![]() 的相互作用被充分利用,本文提出了一种非局域融合模块,很好地融合单个表示和组特征,并得到最终的协同显著性图
的相互作用被充分利用,本文提出了一种非局域融合模块,很好地融合单个表示和组特征,并得到最终的协同显著性图![]()
LOSS
为了更好地优化网络,本文提出了联合显著性损失![]() 和跨顺序对比损失
和跨顺序对比损失![]() ,
,![]() 包含交叉熵损失和感知群损失,可以帮助网络获得良好的联合显著性结果。
包含交叉熵损失和感知群损失,可以帮助网络获得良好的联合显著性结果。![]() 通过拉近不同输入顺序生成的特征嵌入,可以进一步改善顺序敏感问题,从而实现更稳定的推理和训练过程。
通过拉近不同输入顺序生成的特征嵌入,可以进一步改善顺序敏感问题,从而实现更稳定的推理和训练过程。
Co-Saliency Loss:
让![]() 和其ground-truth
和其ground-truth![]() 表示训练样本的集合,其中 N 是图像的数量。联合显著性检测后,联合显著性结果为
表示训练样本的集合,其中 N 是图像的数量。联合显著性检测后,联合显著性结果为![]()
使用交叉熵损失作为每个图像的单独监督:
![]()
除了交叉熵损失外,还提出了一个感知群体训练目标,以进一步探索训练组中整个图像![]() 的交互关系。在分组训练目标的设计中,同时考虑了两个标准,包括 1) 共同目标物体之间的高交叉图像相似度和 2) 检测到的共同目标物体与其他图像(如背景和非常见物体)之间的高清晰度。应用三元组损失作为组约束。具体来说,对于图像
的交互关系。在分组训练目标的设计中,同时考虑了两个标准,包括 1) 共同目标物体之间的高交叉图像相似度和 2) 检测到的共同目标物体与其他图像(如背景和非常见物体)之间的高清晰度。应用三元组损失作为组约束。具体来说,对于图像![]() 可以通过联合检测掩码
可以通过联合检测掩码![]() 和其ground-truth
和其ground-truth![]() 生成三个掩码图像
生成三个掩码图像![]() 其中,⊗为哈达玛乘
其中,⊗为哈达玛乘![]() ,
,![]() 为掩码图像,表示从
为掩码图像,表示从![]() 检测到的共同目标对象,
检测到的共同目标对象,![]() 分别表示真实的共同目标对象以及
分别表示真实的共同目标对象以及![]() 中不重合的区域。然后将感知提取器ϕ 应用于所有掩码图像
中不重合的区域。然后将感知提取器ϕ 应用于所有掩码图像![]() ,可以获取对应得感知特征
,可以获取对应得感知特征![]() ,在每个
,在每个![]() 上应用三元组损失
上应用三元组损失![]() 作为训练目标,
作为训练目标, 其中,b是边距,E表示两个特征向量之间的欧氏距离,分组训练目标使用铰链损失函数
其中,b是边距,E表示两个特征向量之间的欧氏距离,分组训练目标使用铰链损失函数![]() ,也可以使用softmax替代。
,也可以使用softmax替代。
总得Co-Saliency Loss ![]()

Cross-Order Contrastive Loss
MSRU使网络对输入顺序不敏感。然而现有的对比损失不能直接应用于 CoSOD 任务,因为它们的目的是帮助网络区分不同输入的特征嵌入。数据增强用于将单视图数据嵌入到不同的空间中,这有助于网络学习单视图数据的独特特征嵌入。在 CoSOD 任务中,利用对比损失来进一步拉近不同的组特征,并使本文提出的模型对输入顺序不敏感。
因此,我们提出了跨顺序一致性挖掘,利用一个顺序中样本的高度相似性来指导另一个顺序的学习过程。它根据嵌入相似性挖掘不同顺序之间的正对,以促进不同顺序之间的知识交换,然后可以提高每个顺序中隐藏正对的大小,并且提取的组特征将包含不同顺序的知识,从而产生更规则的嵌入空间。
 通过 MSRU 从不同顺序的图像组中随机生成 q=10 组特征,样本
通过 MSRU 从不同顺序的图像组中随机生成 q=10 组特征,样本![]() 和
和![]() 是由同一图像组的不同顺序生成的,存储在
是由同一图像组的不同顺序生成的,存储在![]() 中,N是不同顺序的总数,
中,N是不同顺序的总数,
样本![]() 的对比上下文是
的对比上下文是![]() 和
和![]() 之间的相似集
之间的相似集![]() ,使用关系挖掘器
,使用关系挖掘器 ![]() 获取正样本
获取正样本![]() :
:
如果想用顺序 u 的知识来指导顺序 v 对比学习,它包含两个方面:1):选择顺序为 u 的最相似对(正)作为顺序为 v 的正集,即![]()
![]() 2):不直接拉近不同顺序生成的组特征嵌入,这会导致崩溃问题。而是拉近了不同样本的相似性
2):不直接拉近不同顺序生成的组特征嵌入,这会导致崩溃问题。而是拉近了不同样本的相似性![]() ,然后拉近相似度,通过以下损失函数
,然后拉近相似度,通过以下损失函数 ,总损失可以记作
,总损失可以记作![]() 。
。
最终,整个网络联合训练,总体损失函数为![]()