Flink问题解决及性能调优-【Flink不同并行度引起sink2es报错问题】
最近需求,仅想提高sink2es的qps,所以仅调节了sink2es的并行度,但在调节不同算子并行度时遇到一些问题,找出问题的根本原因解决问题,并分析整理。
实例代码
--SET table.exec.state.ttl=86400s; --24 hour,默认: 0 ms
SET table.exec.state.ttl=2592000s; --30 days,默认: 0 ms
CREATE TABLE kafka_table (
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map<string,string>,
cur map<string,string>,
cus map<string,string>,
account_id AS IF(cur['account_id'] IS NOT NULL , cur['account_id'], src ['account_id']),
publish_time AS IF(cur['publish_time'] IS NOT NULL , cur['publish_time'], src ['publish_time']),
msg_status AS IF(cur['msg_status'] IS NOT NULL , cur['msg_status'], src ['msg_status']),
send_type AS IF(cur['send_type'] IS NOT NULL , cur['send_type'], src ['send_type'])
--event_time as cast(IF(cur['update_time'] IS NOT NULL , cur['update_time'], src ['update_time']) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
--WATERMARK FOR event_time AS event_time - INTERVAL '1' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't1',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'properties.group.id' = 'g1',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
-- 'properties.enable.auto.commit',= 'true' -- default:false, 如果为false,则在发生checkpoint时触发offset提交
'format' = 'json'
);
CREATE TABLE es_sink(
send_type STRING
,account_id STRING
,publish_time STRING
,grouping_id INTEGER
,init INTEGER
,init_cancel INTEGER
,push INTEGER
,succ INTEGER
,fail INTEGER
,init_delete INTEGER
,update_time STRING
,PRIMARY KEY (group_id,send_type,account_id,publish_time) NOT ENFORCED
)
with (
'connector' = 'elasticsearch-6',
'index' = 'es_sink',
'document-type' = 'es_sink',
'hosts' = 'http://xxx:9200',
'format' = 'json',
'filter.null-value'='true',
'sink.bulk-flush.max-actions' = '1000',
'sink.bulk-flush.max-size' = '10mb'
);
CREATE view tmp as
select
send_type,
account_id,
publish_time,
msg_status,
case when UPPER(opt) = 'INSERT' and msg_status='0' then 1 else 0 end AS init,
case when UPPER(opt) = 'UPDATE' and send_type='1' and msg_status='4' then 1 else 0 end AS init_cancel,
case when UPPER(opt) = 'UPDATE' and msg_status='3' then 1 else 0 end AS push,
case when UPPER(opt) = 'UPDATE' and (msg_status='1' or msg_status='5') then 1 else 0 end AS succ,
case when UPPER(opt) = 'UPDATE' and (msg_status='2' or msg_status='6') then 1 else 0 end AS fail,
case when UPPER(opt) = 'DELETE' and send_type='1' and msg_status='0' then 1 else 0 end AS init_delete,
event_time,
opt,
ts
FROM kafka_table
where (UPPER(opt) = 'INSERT' and msg_status='0' )
or (UPPER(opt) = 'UPDATE' and msg_status in ('1','2','3','4','5','6'))
or (UPPER(opt) = 'DELETE' and send_type='1' and msg_status='0');
--send_type=1 send_type=0
--初始化->0 初始化->0
--取消->4
--推送->3 推送->3
--成功->1 成功->5
--失败->2 失败->6
CREATE view tmp_groupby as
select
COALESCE(send_type,'N') AS send_type
,COALESCE(account_id,'N') AS account_id
,COALESCE(publish_time,'N') AS publish_time
,case when send_type is null and account_id is null and publish_time is null then 1
when send_type is not null and account_id is null and publish_time is null then 2
when send_type is not null and account_id is not null and publish_time is null then 3
when send_type is not null and account_id is not null and publish_time is not null then 4
end grouping_id
,sum(init) as init
,sum(init_cancel) as init_cancel
,sum(push) as push
,sum(succ) as succ
,sum(fail) as fail
,sum(init_delete) as init_delete
from tmp
--GROUP BY GROUPING SETS ((send_type,account_id,publish_time), (send_type,account_id),(send_type), ())
GROUP BY ROLLUP (send_type,account_id,publish_time); --等同于以上
INSERT INTO es_sink
select
send_type
,account_id
,publish_time
,grouping_id
,init
,init_cancel
,push
,succ
,fail
,init_delete
,CAST(LOCALTIMESTAMP AS STRING) as update_time
from tmp_groupby
发现问题
由于groupby或join聚合等算子操作的并行度与sink2es算子操作的并行度不同,上游算子同一个key的数据可能会下发到下游多个不同算子中。
导致sink2es出现多个subtask同时操作同一个key(这里key作为主键id),报错如下:
...
Caused by: [test1/cfPTBYhcRIaYTIh3oavCvg][[test1][2]] ElasticsearchException[Elasticsearch exception [type=version_conflict_engine_exception, reason=[test1][4_1_92_2024-01-15 16:30:00]: version conflict, required seqNo [963], primary term [1]. current document has seqNo [964] and primary term [1]]]
at org.elasticsearch.ElasticsearchException.innerFromXContent(ElasticsearchException.java:510)
at org.elasticsearch.ElasticsearchException.fromXContent(ElasticsearchException.java:421)
at org.elasticsearch.action.bulk.BulkItemResponse.fromXContent(BulkItemResponse.java:135)
at org.elasticsearch.action.bulk.BulkResponse.fromXContent(BulkResponse.java:198)
at org.elasticsearch.client.RestHighLevelClient.parseEntity(RestHighLevelClient.java:653)
at org.elasticsearch.client.RestHighLevelClient.lambda$performRequestAsyncAndParseEntity$3(RestHighLevelClient.java:549)
at org.elasticsearch.client.RestHighLevelClient$1.onSuccess(RestHighLevelClient.java:580)
at org.elasticsearch.client.RestClient$FailureTrackingResponseListener.onSuccess(RestClient.java:621)
at org.elasticsearch.client.RestClient$1.completed(RestClient.java:375)
at org.elasticsearch.client.RestClient$1.completed(RestClient.java:366)
at org.apache.http.concurrent.BasicFuture.completed(BasicFuture.java:122)
at org.apache.http.impl.nio.client.DefaultClientExchangeHandlerImpl.responseCompleted(DefaultClientExchangeHandlerImpl.java:177)
at org.apache.http.nio.protocol.HttpAsyncRequestExecutor.processResponse(HttpAsyncRequestExecutor.java:436)
at org.apache.http.nio.protocol.HttpAsyncRequestExecutor.inputReady(HttpAsyncRequestExecutor.java:326)
at org.apache.http.impl.nio.DefaultNHttpClientConnection.consumeInput(DefaultNHttpClientConnection.java:265)
at org.apache.http.impl.nio.client.InternalIODispatch.onInputReady(InternalIODispatch.java:81)
at org.apache.http.impl.nio.client.InternalIODispatch.onInputReady(InternalIODispatch.java:39)
at org.apache.http.impl.nio.reactor.AbstractIODispatch.inputReady(AbstractIODispatch.java:114)
at org.apache.http.impl.nio.reactor.BaseIOReactor.readable(BaseIOReactor.java:162)
at org.apache.http.impl.nio.reactor.AbstractIOReactor.processEvent(AbstractIOReactor.java:337)
at org.apache.http.impl.nio.reactor.AbstractIOReactor.processEvents(AbstractIOReactor.java:315)
at org.apache.http.impl.nio.reactor.AbstractIOReactor.execute(AbstractIOReactor.java:276)
at org.apache.http.impl.nio.reactor.BaseIOReactor.execute(BaseIOReactor.java:104)
at org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor$Worker.run(AbstractMultiworkerIOReactor.java:588)
... 1 more
[CIRCULAR REFERENCE:[test1/cfPTBYhcRIaYTIh3oavCvg][[test1][2]] ElasticsearchException[Elasticsearch exception [type=version_conflict_engine_exception, reason=[test1][4_1_92_2024-01-15 16:30:00]: version conflict, required seqNo [963], primary term [1]. current document has seqNo [964] and primary term [1]]]]
问题原因
Flink中存在八种分区策略,常用Operator Chain链接方式有三种分区器:
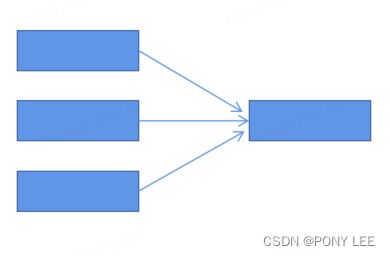
- forward:上下游并行度相同,且不发生shuffle,直连的分区器
- hash:将数据按照key的Hash值下发到下游的算子中
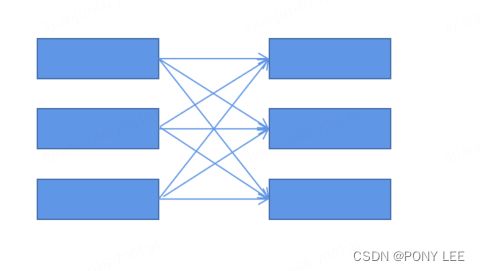
- rebalance:数据会被循环或者随机下发到下游算子中,改变并行度若无keyby,默认使用RebalancePartitioner分区策略
rebalance分区器,可能会将上游算子的同一个key随机下发到下游不同算子中,因而引起报错,如下图:
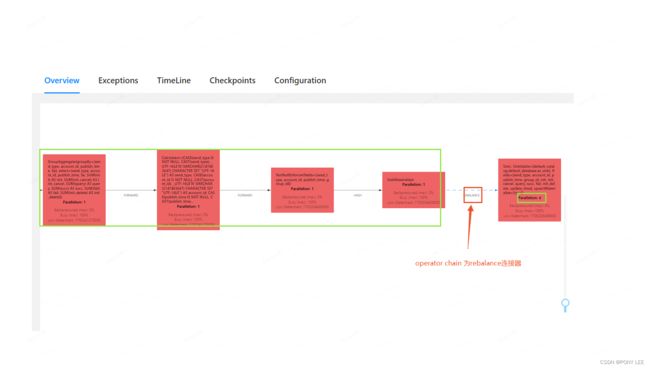
 模型如下:
模型如下:
解决方案
-
分组聚合算子与sink2es算子配置成相同的并行度,即使用forward分区器,如下图:


模型如下:

-
sink2es算子的并行度配置为1,如下图:
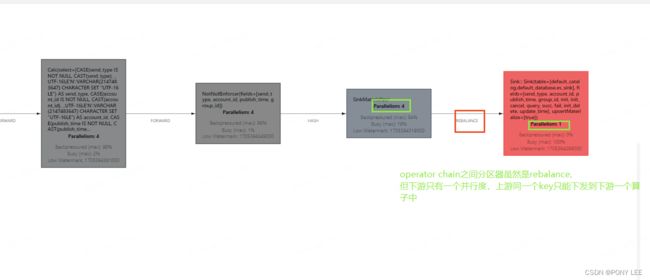 模型如下:
模型如下:
总结
归根结底就是需要保证:上游subtask中同一个key只能下发到下游一个subtask中。