音频格式之MP3:(2)MP3编解码原理详解
系列文章目录
音频格式的介绍文章系列:
音频编解码格式介绍(1) ADPCM:adpcm编解码原理及其代码实现
音频编解码格式介绍(2) MP3 :音频格式之MP3:(1)MP3封装格式简介
音频编解码格式介绍(2) MP3 :音频格式之MP3:(2)MP3编解码原理详解
音频编解码格式介绍(3) AAC :音频格式之AAC:(1)AAC简介
音频编解码格式介绍(3) AAC :音频格式之AAC:(2)AAC封装格式ADIF,ADTS,LATM,extradata及AAC ES存储格式
音频编解码格式介绍(3) AAC :音频格式之AAC:(3)AAC编解码原理详解
文章目录
- 系列文章目录
- 1 编码原理及流程
-
- 1.1 功能模块说明
-
- 1.1.1 混合滤波器组
- 1.1.2 心理声学模型
- 1.1.3 量化编码
- 1.2 编码流程
-
- 1.2.1 Step 1:prediction
- 1.2.2 Step 2:子带分离(Analysis Subband Filter)
- 1.2.3 Step 3:MDCT
- 1.2.4 Step 4: Joint Stereo(联合立体声)
- 1.2.5 Step 5:位元分配(bit allocation)
- 1.2.6 Step 6:量化
- 1.2.7 Step 7:Huffman编码
- 1.2.8 Step 8:生成帧
- 2 解码流程
-
- 2.1 预处理(Preprocessing)
- 2.2 Huffman decoding
- 2.3 反量化(Requantization)
- 2.4 重排序(Reordering)
- 2.5 立体声解码(Stereo decoding)
- 2.6 混叠消除(Alias reduction)
- 2.7 IMDCT
- 2.8 子带合成滤波(Synthesis filter bank)
- 资料下载
-
- 代码下载地址:
- ISO/IEC 11172 全部1-3部分全文下载:
- ISO/IEC 13818全部1-9部分全文下载 :
- 参考网址
本文主要介绍MP3,即MPEG1 Layer-3
本文网址:https://blog.csdn.net/littlezls/article/details/135458169
1 编码原理及流程
1.1 功能模块说明
MP3编码主要由3大功能模块组成,包括混合滤波器组(子带滤波器和MDCT),心理声学模型,量化编码(比特和比特因子分配和哈夫曼编码)。
1.1.1 混合滤波器组
这部分包括子带滤波器组和MDCT两部分。子带滤波器组编码完成样本信号从时域到频域的映射,并将规定的音频信号通过带通滤波器组分解成32个子带输出。子带滤波器组输出的32个子带是等带宽的,而由心理声学模型得出的临界带宽则不是等带宽的,所以为了使得进行编码的各个比例因子带与临界频带相匹配,需要对每个子带信号做MDCT变换。将子带滤波器组的输出送到MDCT滤波器组后,每组将细分为18条频线,共产生576条频线。然后利用心理声学模型中计算出来的子带信号的信掩比,决定分配给576条谱线的比特数。
1.1.2 心理声学模型
心理声学模型利用了人耳听觉系统的遮蔽效应特性,移除大量的不相关信号,从而达到压缩音频数据的效果。为了精确地计算遮蔽阈值,要求信号有更好的频域解析度,因此在使用心理声学模型前先对信号进行傅立叶变换。MPEG-I提供了两种心理声学模型,第一种模型计算简单,在高比特率编码时提供适当精度,第二种模型比较复杂,一般在较低比特率编码时使用。MP3编码中一般使用心理声学模型二。心理声学模型的目的就是求出各个子带的掩蔽域值,并以此控制量化过程。心理声学模型实现过程一般是先用FFT求出信号的频谱特性,根据频谱特性找出各频率点上的音调成分(有些称为音乐成分)和非音调成分(或称噪音成分);根据掩蔽域曲线确定各个音调成分和非音调成分在其它频率点的掩蔽域值;最后求出各频率点的总体掩蔽域,并折算到编码子带中。对于子带滤波器组输出的谱值量化后产生的噪声,如果能够被控制在掩蔽域值以下,则最终的压缩数据被解码后的结果与原始信号可以不加区分。一个给定信号的掩蔽能力取决于它的频率和响度,所以心理声学模型的最终输出是信掩比SMR(signal-to-maskradio),即信号强度与掩蔽阈值的比率。
1.1.3 量化编码
当PCM讯号被分成好几个频段并经过一系列的处理后,最后经过MDCT,将波型转换为一连串的系数。这些系数就由Huffman编码器会选择最 合适的Huffman表来做最后的压缩。 Huffman编码一般是双路工作的,但是在某些需要精密编码的情况下,它会进行四路工作。编码器一般会有很多的Huffman编码表,很多时候为了更好 的声音质量和更有效屏蔽量化噪音,编码器甚至能为每一个频段选择最合适的Huffman编码表。
不过编码不是一次就能成功的,要采取Try and Error的方式循环进行。因为编码器一方面要削减量化噪音,让它在人耳遮蔽曲线以下;另一方面要保证bitrate满足要求。实际上这里就是要确定两个 数值:一个是确定bitrate的步进值(gain value),另一个是削减量化噪音的增益因子(ScaleFactor),这两个系数会在正式编码之前确定下来,确定过程由两个嵌套的迭代回路完成:失 真控制回路(Distortion Control Loop)和量化速率控制回路(Nonuniform Quantization Rate Control Loop)
◆内部迭代回路 (Rate Loop )
量化以后的数据送进Huffman编码器,当发现比特数大于可用流量时,编码器会返回信息,让Rate Loop调整步进值以增大量化步长,从而让数据流量减小。循环会一直进行,尝试不同的量化步长,直到Huffman编码以后的数据流量足够小。因为这个回 路是用来控制码率的,所以叫做Rate Loop。
◆外部迭代回路 (noise control loop)
显然,这个回路的作用就是控制量化噪音(quantization noise),让其保持在听觉心理学提供的屏蔽临界线(masking threshold)以下。每一个频段都会有一个增益因子,一开始编码器以1.0作为默认因子,如果量化噪音量超过允许的值,那么回路就会调整增益因子, 来把量化噪音降下来。更少的量化噪音意味着流量增大,码率需要提高,所以增益因子每次改变以后,Rate Loop都要进行调整,让码率符合要求。
所以两个回路是嵌套工作的,互相协调,中止条件是量化噪音降到屏蔽临界线以下而码率也足够小。良好的编码器会让两个回路有条不紊的工作,因为一旦处理不好就很容易陷入死循环。
1.2 编码流程
编码流程图如下:
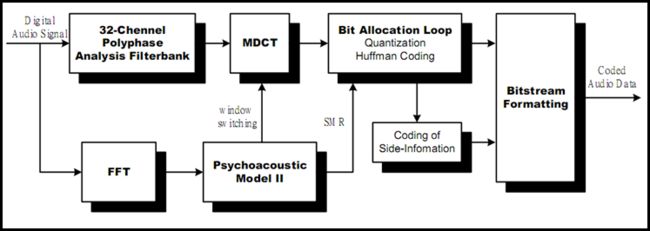
MP3一帧包含1152个声音取样,一帧分为2节(granule)。mp3编码时,首先将原始的PCM数据送入滤波器组,分成32个等频宽的子频带,然后再通过MDCT(modified discrete coding transform),将每个子带,转换成18个次频带。然后根据第二声学模型提供的SMR(signal-to-mask ratio),对每一个子频带信号,做位元分配和编码。
1.2.1 Step 1:prediction
根据第二声学模型做预测,预测结果得到的SMR会作为位元分配的依据。第二声学模型中几个重要依据如下:
静音阈值曲线、时域掩蔽效应、频域掩蔽效应、临界频带。
1.2.2 Step 2:子带分离(Analysis Subband Filter)
首先将原始的PCM数据送入滤波器组,分成32个等频宽的子频带。

下图是ISO11172-3标准给出的FIGURE 3-C.1 Analysis subband filter flow chart。其步骤为

【a】输入32个音频samples
【b】建立一个数组x[n], for n=0~511用于保存输入的采样值。将x[n]看做一个最多能容纳512个元素的队列,x[511]为队首,x[0]为队尾, 每次接收新的samples前将队首32个元素移出,将samples放入队尾。
【c】加窗滤波器处理,窗函数系数为C[i],i=0~512,通过实现窗函数滤波器
【d】计算64个Yi值,表达式如流程图中所示
【e】计算32个子带滤波器采样值Si,这里使用到矩阵M[i][k],
M[i][k] = cos [(2i + 1)(k - 16)p/64] ,
for i = 0 to 31, and k = 0 to 63.
实际计算时可以将非线性的运算用查Table的方法以减小运算的复杂度。
1.2.3 Step 3:MDCT
MDCT滤波器将32个子带中每一个子带的的信号在频域上进一步划分,长块进行18点(18个频域采样点)的MDCT变换,短块进行6点(6个频域采样点)的MDCT变换,以窗为单位分3次进行。MDCT包括三部分:MDCT窗框、MDCT、长窗假象处理。
(a)MDCT加窗
4种窗及使用情形如下:

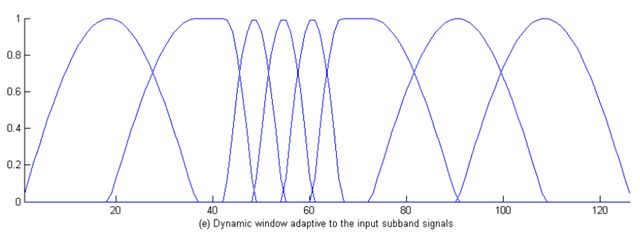
窗框的选择依据第二声学模型,规则通常如下:子频带音频讯号稳定时,采用长窗来提供最细的频谱解析度;子频带变动较大时,采用短窗提供较大的时域解析度。决定好窗框以后,就可以以窗框为单位进行MDCT运算。如果是长窗,需要针对混跌做假象处理。
(b)MDCT
作用:将时域信号转换成频域信号
In the case of long blocks ( block_type 0,1,3 ) there are 36 coefficents in the time domain and 18 in the frequency domain.
In the case of short blocks (block_type 2 ) there are 3 transformations with short length. This leads to 12 coefficents in the time and 6 in the frequency domain.
©长窗假象处理(混叠消除)
什么是长窗假象:使用长窗时,频谱上可见邻近的子频带间有明显的重叠现象,处于重叠区间的讯号将会同时影响两个子频带。
假象处理的方式:将处在相对应位置的频线之能量做一定比例的增减,蝶形运算。
MDCT的表达式为:
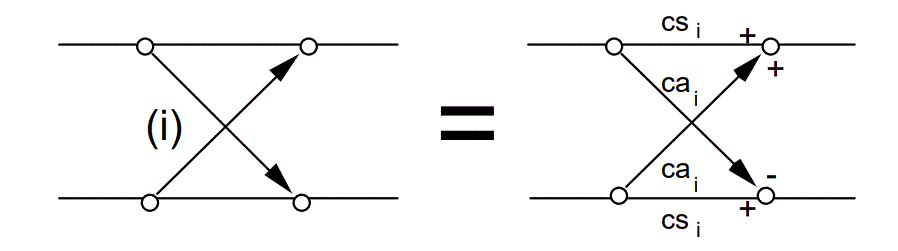 计算一样可以通过蝶形图运算来提高效率,蝶形运算中最重要的是系数值,使用短窗框的MDCT运算点数为12,长窗框则为36。
计算一样可以通过蝶形图运算来提高效率,蝶形运算中最重要的是系数值,使用短窗框的MDCT运算点数为12,长窗框则为36。
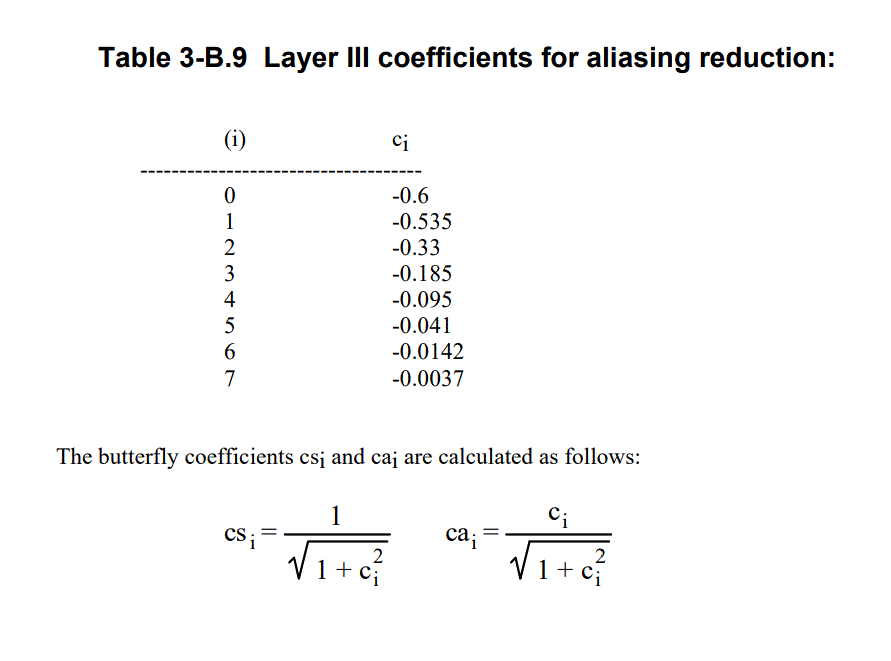
ISO 11172-3的ANNEX_AB.DOC文档中Table 3-B.9给出了蝶形运算的系数如下
附:Step2和Step3的综合图为:
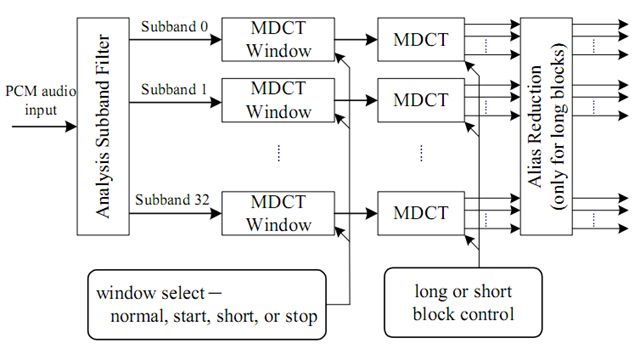
1.2.4 Step 4: Joint Stereo(联合立体声)
编码依据:2个声道存在相干性,方法有:
Intensity Stereo(IS):Human hearing is predominantly less acute at perceiving the direction of certain audio frequencies
Mid/Side (M/S) stereo :The mid channel is L + R. The side channel is L − R
1.2.5 Step 5:位元分配(bit allocation)
根据第二声学模型的预测结果,进行位元分配;位元分配是一个反复调整的过程。
1.2.6 Step 6:量化
以缩放因子频带为单位,进行量化。缩放因子频带内使用相同的缩放因子。
mp3中一帧数据含有1152个PCM数据,分成2节(granual)。每节含有576个PCM数据,这576个值在不同的节类型有不同的定义。如下所述:
(a)该节为长块:这576个值代表576条频率线上的值,是时域上的576个pcm值经过时频变换的结果。这576条频率线从低到高分成32个子带,每个子带含18条频率线。同时,也将这576个数据分成若干个缩放因子带,每个缩放因子带共用一个缩放因子。长块的缩放因子带在44kHz按如下表格划分,其中,418-575不属于任何一个缩放因子带,使用系统提供的默认缩放因子:

(b)该节为短块:这576个值代表192条频率线的值,192条频率线分32个子带,每条子带包括6条频率线。每条频率线有3个值,分别属于3个窗 (windows_0,windows_1,windows_2)。192条频率线也被分成若干缩放因子带,在44.1kHz时划分如下图,其中,136-191使用默认缩放因子。
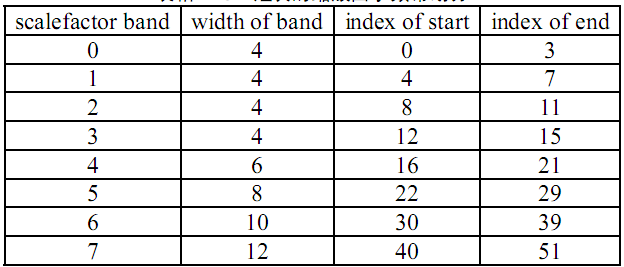
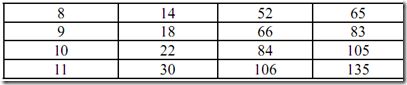
这576个值得排列顺序为,先是按缩放因子带从低到高排列;缩放因子带内,按windows_0,windows_2,windows_3排列;每一个window中,频率线从低到高排列。
(c)该节为混合块: 解出来的值分2个部分,第一部分(前36个值)是长块,代表36条频率线;第二部分(后540个值)为短块,代表180个频率线。2部分的排列方式分别于长块和短块相同。
综上,有:
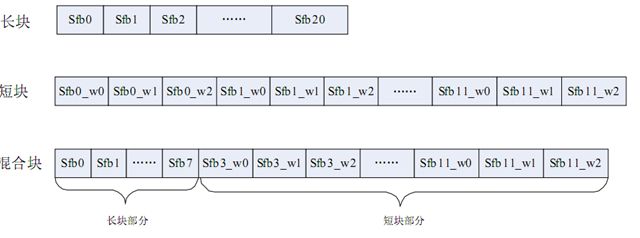 附: 缩放因子
附: 缩放因子
缩放因子带在逆量化时共用的缩放因子,缩放因子被编码于main_data中,欲解码缩放因子,首先得知道缩放因子所占的比特数,在side information的scale_compress[gr][ch]提供这样的信息,所用的bit数通过查如下表才能得到。slen 1和slen 2针对那些缩放因子带,由块类型决定。

1.2.7 Step 7:Huffman编码
(a)Huffman码表选择
当从一个缩放因子频带过渡到另一个缩放因子频带时,Huffman码表可能发生改变;需要进行编码的576个值分为大值区、小值区、零值区:

不同的区域使用不同的Huffman表编码,大值区每2个值一起编码,小值区每4个值一起编码,零值区无需编码,大值区以缩放因子频带为单位,分为3个region。每个region使用不同的Huffman表。一共有32个Huffman表供选择。
(b)huffman编码(略)
注:大值区的Huffman表有一个参数linbits,用来指定Huffman表是否能用来编码大于15的数。
1.2.8 Step 8:生成帧
加上Frame Header和Side Information,生成帧。
2 解码流程

2.1 预处理(Preprocessing)
preprocessing:主要完成Header和side information的解码。
2.2 Huffman decoding
Huffman decoding:选择Huffman table,进行解码。
2.3 反量化(Requantization)
Requantization:逆量化,短块和长块使用不同的公式。公式如下:

2.4 重排序(Reordering)
Reodering:由于编码时对短块和混合块中的短块进行了重排,具体见编码部分,故解码时需要重新排序
2.5 立体声解码(Stereo decoding)
Stero decoding:立体声解码。
2.6 混叠消除(Alias reduction)
Alias reduction:长块间需要消除混跌。
2.7 IMDCT
IMDCT:每做一次MDCT产生36个输出。昨晚IMDCT后,需再做加窗运算。IMDCT做完后,再无长块、短块概念,得到的结果是从低到高的32个子带,每个子带18个值。
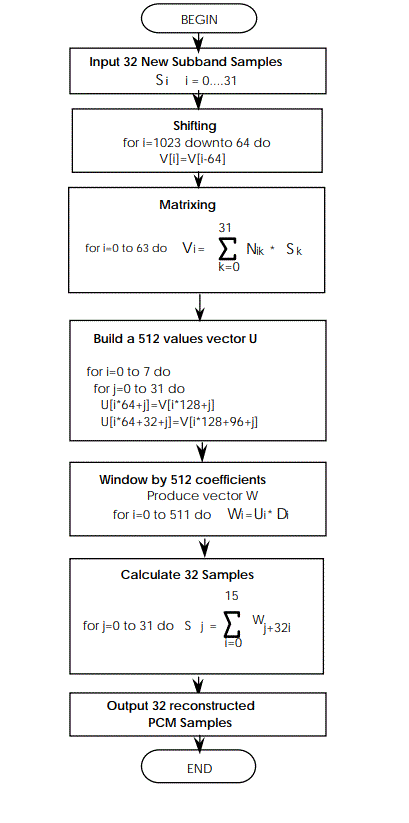
2.8 子带合成滤波(Synthesis filter bank)
子带合成滤波:先是把32个子带中,每个子带取一个数据,组成的32个值送入一个1024的FIFO中;接着把这1024个值中取出一半,对其做加窗运算,加窗系数由MP3官方协议的表格提供;最后对加窗结果进行叠加得到32个时域PCM输出。
资料下载
代码下载地址:
https://github.com/npc-github-octocat/Helix_Mp3
https://sourceforge.net/projects/lame/files/lame/
MPEG-1 (即ISO/IEC 11172)
MPEG-2(即ISO/IEC 13813)
MPEG-4(即ISO/IEC 14496)
ISO/IEC 11172 全部1-3部分全文下载:
https://download.csdn.net/download/littlezls/88754692
ISO/IEC 13818全部1-9部分全文下载 :
https://download.csdn.net/download/littlezls/88754693
参考网址
[1] : MP3文件格式与编码原理解码流程详解
https://blog.csdn.net/yuyin86/article/details/7097933/
[2] :MP3编码技术原理
https://blog.csdn.net/sunnylgz/article/details/7615410
[3] :MP3编码原理概述[转]
https://blog.csdn.net/myleeming/article/details/3318002
[4] :MP3编码分析
https://blog.csdn.net/xiahouzuoxin/article/details/7849249
[5] : Mp3解码算法流程
https://blog.csdn.net/jeffchenbiao/article/details/7332863
[6] : MP3解码算法原理解析
https://www.jianshu.com/p/58df71a19901
[7] : 【2017年整理】mp3解码算法原理详解
https://www.docin.com/p-1913003116.html