我们是如何测试人工智能的(二)数据挖掘篇
前言
数据决定模型的上限,而算法调参只是尽量的帮你逼近那个上限,建模工程师 80% 的时间都是在跟数据打交道,国内在 AI 上的发展与国外最大的差距不是在算力上,而是高质量的数据。 相信大家在网络上都见过类似的说法,事实上这些说法都是正确的。并且对于测试人员来说也是一样的。 通过上一篇介绍效果测试的文章大家可以知道,目前已经有现成库帮我们去计算模型的评估指标,老实讲去计算这些指标没有一点难度,甚至可以说没什么技术含量,懂 python 的人都可以做。但是真正难的,是如何收集到符合场景要求的数据以及如何保证这些数据的质量,就连用 AI 测试 AI 这个方法,也需要先收集到符合要求的数据才能训练出可以用来测试的模型。 所以虽然我们是在测试 AI,但实际上我们掌握的最多的技能却是数据处理相关的,比如 spark, flink,opencv,ffmpeg 等等。 所以这一篇,我来科普一下在项目中,我们是如何处理数据的。
PS: 这一篇仍然是科普, 不会每一个点都扩展很详细的知识点。 还是以介绍工作内容为主
我们需要数据处理工具做什么
- 数据采集/挖掘:上篇文章中介绍了很多效果测试的方法, 但也说过符合测试场景要求的数据不会自动的飞到我们面前, 所以我们需要在茫茫多的数据中根据业务规则选取到我们需要的数据。
- 数据质量测试/监控:数据直接影响到模型效果, 所以我们需要针对数据进行测试和监控。 尤其在自学习场景中,如果数据出现问题需要及时的告警。
- 数据构造:往往应用于性能测试场景中,现在是卷大模型的时代,是比谁的训练样本更庞大的时代。 所以在性能测试中,往往需要构造非常大规模的数据进行心更难测试(数千万甚至数亿)。
- ETL/特征工程的测试:在整个建模过程中主要可以分为特征工程和模型训练:在结构化数据中特征工程会涉及到大量的拼表,时序特征计算等等操作。 在图像数据中会涉及到各种图像增强算法(二值化,灰度化,角点提取,滤波去噪等等),在 NLP 领域里会涉及到文本切片,切词,词向量,语料库构建等等。如果你面对的是一个人工智能平台,那么这些也就变成了测试对象。
- 数据标注:我们面对的大部分都是监督学习,所谓监督学习,就是算法在学习这份数据的时候, 我们需要告诉算法这条数据的答案。比如推荐系统里,你的数据里需要告诉算法当前用户是不是喜欢这个内容。反欺诈系统里,需要告诉算法这条数据是不是欺诈行为。 计算机视觉的目标检测场景中, 不仅要标注这张图片中是否有目标物体,还需要标注出物体的具体坐标(x,y,w,h: 中心点坐标和长度宽度,或者 4 个点的 x,y 坐标)。 不过好在结构化数据的标注非常简单, 就在表的对应列里写一个值就行了, 而计图片数据也有相关的数据标注工具可以使用。
那么接下来我们依次介绍一下这些工作的内容。
数据标注
先讲比较简单点的吧,从数据标注开始,当然大多数时候数据标注的工作是不需要测试人员来做的,一般都会有专门标注组来做这些基础的事情。但如果我们后续要训练自己的模型来辅助测试,一般就得自己来做数据标注的工作了(当然如果能为测试自己的需求申请到标注组的人力也是可以的, 但很多时候其实没这个必要,因为迁移学习的存在,我们不需要对大量的数据进行标注,所以有时候走流程去申请标注人员,还要去跟标注人员解释场景要求,所以很多时候倒不如自己上手比较快)。结构化数据是比较简单的,大多数时候就是一张表么,有一列叫做 label,你只要写上去就可以了。 如下图:

针对图片数据,一般需要对应的工具来标记分类的位置信息。 业界有很多的开源工具可以做到这一点, 各个厂商也会有自研的数据标注平台。 这里我以 labelme 为例。
labelme 的安装是比较简单的, pip install labelme 就可以了。 用户可以选择一个目录,labelme 会按顺序显示这些图片,然后用户需要画出目标物体的位置并且告诉这个目标数据哪个分类。 然后它会把标注信息生成一个 json 文件:
{
"version": "5.3.1",
"flags": {},
"shapes": [
{
"label": "0",
"points": [
[
12.597402597402663,
14.02597402597404
],
[
908.9397314013636,
1079.0
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "001.jpg",
"imageData": null,
"imageHeight": 1080,
"imageWidth": 1920
}
PS:由于选择使用了长方形的标注形式, 所以 json 文件中只记录了左上角和右下角的坐标信息。 如果有需要后面可以通过工具转成其他形式的坐标信息。
由于标注工作大部分时候跟测试人员关系不大, 所以这里先不过多讲解。
数据采集/挖掘
结构化数据
让我们先从结构化数据开始(因为最简单),上一篇文章中我们介绍效果测试时曾经说过要根据业务做分组的指标统计, 要根据用户画像,业务场景划分数据类型, 每种数据类型都要采集到足够的数据,这样才能更全面的评估模型针对不同场景,不同用户的效果如何。所以我们需要在茫茫多的数据中按照规则把这些数据筛选出来。 如果对自己的数据不熟悉,还需要使用一些数据统计的方法来统计一些数据信息, 比如计算一共有多少种用户职业,每种用户职业占比多少等等。玩 python 的同学通常都对 pandas 库比较熟悉,用 pandas 来计算处理这些数据还是比较方便的。 但很可惜的是大多数时候我们都无法使用这种方式来完成这部分工作。 因为人工智能是在大数据的基础之上的, 我们可能要面对数以百万,千万甚至亿的数据量。所以 pandas 往往无法满足我们的要求, 我们需要掌握至少一门分布式计算框架,我比较推荐 Spark,主要有三点:
- Spark 在结构化数据中算是万金油的,能适应绝大多数的数据存储系统。 并且它也有 dataframe 和 sql 两种高级 API 供用户选择, 喜欢 sql 的同学可以用 sql,喜欢 pandas 风格的同学可以使用 dataframe(我理解就是仿照 pandas 的接口开发出来的)
- Spark 本身也是一个机器学习包, 它专门有一个 machine learning 库,可以完成结构化数据领域中的大多数算法(并且支持分布式的运行)。 很多团队在做机器学习的时候都会选择使用 spark 来完成工作。 测试人员有些时候不是要在 UI 上或者通过接口对模型进行测试, 而是直接在底层直接对模型文件进行测试。 这时候如果算法团队是使用 spark ml 来实现的算法,那么也就需要测试人员调用 spark 的 API 来完成模型的加载,数据的处理,特征工程等操作。
下面演示一下做这种模型测试的 spark 代码。 我自己用 spark 训练出了一个模型, 然后用 spark 加载这个模型做模型的评估:
from pyspark.ml.tuning import TrainValidationSplitModel
from pyspark import SparkContext, SparkConf, SQLContext
from pyspark.sql import functions as F
from pyspark.sql.window import Window
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
dicts = [
['frank', '男', 16, '程序员', 3600, 1.0],
['alex', '女', 26, '项目经理', 3000, 1.0],
['frank', '男', 16, '程序员', 2600, 0.0],
['asdf', '男', 16, '程序员', 2600, 0.0],
['fragfsnk', '男', 16, '程序员', 2600, 0.0],
['frasdfgnk', '男', 16, '程序员', 2600, 0.0],
['frsdfgank', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfankdsaf', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank342', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank445', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank756', '男', 16, '程序员', 3600, 1.0],
['hdfg', '男', 16, '程序员', 2600, 0.0],
['frsdfncvgdfank', '男', 16, '程序员', 2600, 0.0],
['wert', '男', 16, '程序员', 2600, 0.0],
['sdfg', '男', 16, '程序员', 2600, 0.0],
['frssdffgdfank', '男', 16, '程序员', 2600, 0.0],
['asdf', '男', 16, '程序员', 2600, 0.0],
['zxcv', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank', '男', 16, '程序员', 2600, 0.0],
['vzxcv', '男', 16, '程序员', 2600, 0.0],
['zxcv', '男', 16, '程序员', 3600, 1.0],
['frsdfgdcvfank', '男', 16, '程序员', 3600, 1.0],
['frsdfgdcvfankasdf', '男', 16, '程序员', 3600, 1.0],
['asfghffgh', '男', 16, '程序员', 3600, 1.0],
['dfgh', '男', 16, '程序员', 3600, 1.0],
['frsdfgdcvbnmvbvfank', '男', 16, '程序员', 3600, 1.0],
['v', '男', 16, '程序员', 3600, 1.0],
['dasdfsadf', '男', 16, '程序员', 3600, 1.0],
['gghg', '男', 16, '程序员', 3600, 1.0],
]
rdd = sc.parallelize(dicts, 3)
dataf = sqlContext.createDataFrame(rdd, ['name', 'gender', 'age', 'title', 'price', 'label'])
# 计算时序特征,计算每种性别中历史最大的price值(模拟计算用户最大消费额的特征计算)
windowSpec = Window.partitionBy(dataf.gender)
windowSpec = windowSpec.orderBy(dataf.age)
windowSpec = windowSpec.rowsBetween(Window.unboundedPreceding, Window.currentRow)
dataf.withColumn('max_price', F.max(dataf.price).over(windowSpec)).show()
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
# 将非数值类型的字段转换为数值类型
stringIndexer = StringIndexer(inputCol="title", outputCol="title_num")
data_indexed = stringIndexer.fit(dataf).transform(dataf)
# 将类别特征进行独热编码
encoder = OneHotEncoder(inputCol="title_num", outputCol="title_onehot")
data_encoded = encoder.fit(data_indexed).transform(data_indexed)
# 将所有特征组合成一个特征向量
vectorAssembler = VectorAssembler(inputCols=["age", "title_onehot", "price"], outputCol="feature")
data_vector = vectorAssembler.transform(data_encoded)
# 从模型文件中加载模型,
model = TrainValidationSplitModel.load('../model')
predictions = model.transform(data_vector)
predictions.show()
result = predictions \
.withColumn('result', F.when((F.col('prediction') == 1.0) & (F.col('label') == 1.0), 'TP')
.when((F.col('prediction') == 1.0) & (F.col('label') == 0.0), 'FP')
.when((F.col('prediction') == 0.0) & (F.col('label') == 0.0), 'TN')
.when((F.col('prediction') == 0.0) & (F.col('label') == 1.0), 'FN')
.otherwise('')) \
.select('label', 'prediction', 'result') \
# .show()
result.show()
# 计算混淆矩阵与准招率。
TP = 0
FN = 0
FP = 0
TN = 0
rows = result.collect()
for row in rows:
if row['result'] == 'TP':
TP = TP + 1
if row['result'] == 'FP':
FP = FP + 1
if row['result'] == 'TN':
TN = TN + 1
if row['result'] == 'FN':
FN = FN + 1
recall = TP / (TP + FN)
precision = TP / (TP + FP)
print("recall: " + str(recall))
print("precision: " + str(precision))
上面的代码我们使用 spark 加载了模型, 并且进行了特征工程(选取特征列, 计算时序特征,将离散特征做独热编码,特征转换成特征向量), 特征工程结束后输入到模型中去预测结果, 最后计算模型的召回率和精准率。 这里需要注意的是:
- 我们测试模型的时候依然要做特征工程的, 要产出一个模型主要有两个重要的部分:特征工程和模型训练, 模型只接受经过特征工程后的数据。 所以不论是模型训练, 还是我们去测试, 都要先针对数据进行特征工程才能测试。 这也是为什么我说学习 spark 是个比较万金油的选择。 既能做数据处理, 也能用来完成模型的测试。
还有一个需要注意的是下面这段代码:
result = predictions \
.withColumn('result', F.when((F.col('prediction') == 1.0) & (F.col('label') == 1.0), 'TP')
.when((F.col('prediction') == 1.0) & (F.col('label') == 0.0), 'FP')
.when((F.col('prediction') == 0.0) & (F.col('label') == 0.0), 'TN')
.when((F.col('prediction') == 0.0) & (F.col('label') == 1.0), 'FN')
.otherwise('')) \
.select('label', 'prediction', 'result') \
这是一段用 spark dataframe 来处理数据的代码, 在 demo 里我是通过 spark 来计算出上一篇介绍过的混淆矩阵, 我们新建一个 result 列, 然后使用 when 方法去根据条件判断这份数据是属于混淆矩阵中的哪种情况并写入到新建的 result 列。 大家可以通过这段代码感受一下 dataframe 的编程风格, 实际上我们在做数据采集的时候,也差不多是这样的形式。spark 有很多种算子来帮我们采集数据。 当然也可以用一个简单的 spark sql 来完成数据采集:
select * from table_name where title = 'qa' and date between '2023-01-22 00:00:00' and '2023-01-22 23:59:59' limit 10000
上面的代码模拟了从一张表中采集一天内 title 是 qa 的数据,并且限制了 10000 条。 对于一些比较简单的采集任务,spark sql 的实现可能是更简单的。 不过有些时候我们可能需要一些公开数据集,或者其他业务的数据集来进行测试,这些数据集需要导入到我们的系统中。 而这些数据集可能不满足我们系统中的某些数据约束, 所以我们有时候需要进行一些数据的清洗工作。 下面我列一个我用 spark java 写的一个数据清洗脚本:
import generator.field.binary.BinaryIntLabelField;
import generator.field.random.RandomIntField;
import generator.field.random.RandomStringField;
import generator.table.XRange;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.DateType;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.sql.Date;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.*;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.functions.*;
import org.apache.spark.sql.functions;
/**
*
*/
public class Demo {
public static void main(String[] args) throws ParseException {
SparkConf conf = new SparkConf().setAppName("data produce")
.setMaster("local");
// SparkConf conf = new SparkConf().setAppName("data produce");
JavaSparkContext sc = new JavaSparkContext(conf);
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.sql.legacy.timeParserPolicy","LEGACY")
.getOrCreate();
// SparkContext sparkSC = spark.sparkContext();
Dataset edata = spark.read().option("header", true).option("delimiter", ",").option("multiLine", true).csv("/opt/bitnami/spark/ft_local/query-impala-80930.csv").toDF();
// Dataset edata = spark.read().option("header", true).option("delimiter", ",").option("multiLine", true).csv("/Users/cainsun/Documents/query-impala-80930.csv").toDF();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
java.util.Date start = format.parse("2023-05-01");// 构造开始日期
java.util.Date end = format.parse("2023-06-19");// 构造结束日期
DateFormat dateformat = new SimpleDateFormat("yyyyMMddhh");
int ds = Integer.parseInt(dateformat.format(new Date(new java.util.Date().getTime())));
Dataset dataset = edata.
withColumnRenamed("Insurance_myself", "s009").
withColumnRenamed("accept_insurance_occupation", "s010").
withColumnRenamed("agent_id", "s011").
withColumnRenamed("else_insurance", "s012").
withColumnRenamed("health_insurance", "s013").
withColumnRenamed("property_insurance_amount", "i002").
withColumnRenamed("property_insurance_name", "s014").
withColumnRenamed("insurance_period", "s015").
withColumnRenamed("property_insurance_type", "s016").
withColumnRenamed("insured_area", "s017").
withColumnRenamed("insured_birth", "s018").
withColumnRenamed("property_insured_gender", "s019").
withColumnRenamed("insured_relationship", "s020").
withColumnRenamed("payment_type", "s021").
withColumnRenamed("policy_holder_gender", "s022").
withColumnRenamed("policy_holder_name", "s023").
withColumnRenamed("property_product_id", "s024").
withColumnRenamed("social_security", "s025").
withColumnRenamed("insurance_id", "s026").
withColumnRenamed("property_accidents", "s027").
withColumnRenamed("property_area", "s028").
withColumnRenamed("property_brand", "s029").
withColumnRenamed("property_car_id", "s030").
withColumnRenamed("property_car_ower", "s031").
withColumnRenamed("property_certification_date", "s032").
withColumnRenamed("property_commercial_insurance_date", "s033").
withColumnRenamed("property_compulsory_insurance", "s034").
withColumnRenamed("property_compulsory_insurance_date", "s035").
withColumnRenamed("property_engine", "s036").
withColumnRenamed("insurance_coverage", "i003").
withColumnRenamed("property_insured_age", "i004").
withColumnRenamed("property_insured_credentials_id", "s037").
withColumnRenamed("property_is_commercial_insurance", "s038").
withColumnRenamed("property_is_person", "s039").
withColumnRenamed("property_last_payment_deadline", "s040").
withColumnRenamed("property_last_payment_year", "s041").
withColumnRenamed("property_next_payment", "s042").
withColumnRenamed("property_page_name", "s043").
withColumnRenamed("property_policy_id", "s044").
withColumnRenamed("property_policy_phone", "s045").
withColumnRenamed("property_product", "s046").
withColumnRenamed("property_register_date", "s047").
withColumnRenamed("property_transfer", "s048").
withColumnRenamed("property_vehicle_identify", "s049").
withColumnRenamed("terminate_reason", "s050").
withColumnRenamed("activity_name", "s051").
withColumnRenamed("source", "s052").
withColumnRenamed("is_continue", "s053").
withColumnRenamed("is_success", "s054").
withColumnRenamed("sign_day", "i005").
withColumnRenamed("insurance_contract_number", "s055").
withColumnRenamed("contact_entrance", "s056").
withColumnRenamed("question", "s057").
withColumnRenamed("serve_type", "s058").
withColumnRenamed("property_house_area", "s059").
withColumnRenamed("insured_name", "s060").
withColumnRenamed("property_policy_name", "s061").
withColumnRenamed("property_protection_plan", "s062").
withColumnRenamed("property_protection_scheme", "s063").
withColumnRenamed("property_relationship", "s064").
withColumnRenamed("check_fail_reason", "s065").
withColumnRenamed("biz_ID", "s066").
withColumnRenamed("claim_fail_reason", "s067").
withColumnRenamed("insurer_name", "s068").
withColumnRenamed("insurer_phone", "s069").
withColumnRenamed("insurer_reason", "s070").
withColumnRenamed("insurer_relation", "s071").
withColumnRenamed("reporter_name", "s072").
withColumnRenamed("reporter_phone", "s073").
withColumnRenamed("service_location", "s074").
withColumnRenamed("sortsof_insurance", "s075").
withColumnRenamed("signin_type", "s076").
withColumnRenamed("agent_type", "s077").
withColumnRenamed("insurance_effective_datetime", "s078").
withColumnRenamed("policy_holder_birth", "s079").
withColumnRenamed("policy_holder_credentials_NO", "s080").
withColumnRenamed("policy_holder_credentials_type", "s081").
withColumnRenamed("before_refer", "s082").
withColumnRenamed("task_type", "s083").
withColumnRenamed("failreason", "s084").
withColumnRenamed("expire_date", "s085").
withColumnRenamed("installment_insurance", "s086").
withColumnRenamed("insurance_commence", "s087").
withColumnRenamed("insurance_fail_reason", "s088").
withColumnRenamed("insured_Email", "s089").
withColumnRenamed("insured_adress", "s090").
withColumnRenamed("insured_annual_income", "i006").
withColumnRenamed("insured_credentials_no", "s091").
withColumnRenamed("insured_credentials_type", "s092").
withColumnRenamed("insured_live_area", "s093").
withColumnRenamed("insured_occupation", "s094").
withColumnRenamed("insured_phone", "s095").
withColumnRenamed("insured_social_security", "s096").
withColumnRenamed("payment_channel", "s097").
withColumnRenamed("renew_date", "s098").
withColumnRenamed("renew_date_30", "s099").
withColumnRenamed("renew_insurance", "s100").
withColumnRenamed("pay_fail_reason", "s101").
withColumnRenamed("gift_insurance", "s102").
withColumnRenamed("phone_number", "s103").
withColumnRenamed("consult_fail_reason", "s104").
withColumnRenamed("terminate_insurancefail_reason", "s105").
withColumnRenamed("service_name", "s106").
withColumnRenamed("duration", "i007").
withColumnRenamed("settlement_amount", "i008").
withColumnRenamed("program_name", "s107").
withColumnRenamed("handle_duration", "i009").
withColumnRenamed("member_baodan", "s108").
withColumnRenamed("is_upload_success", "s109").
withColumnRenamed("upload_fail_reason", "s110").
withColumnRenamed("operation_belong_position", "s111").
withColumnRenamed("operation_id", "s112").
withColumnRenamed("operation_name", "s113").
withColumnRenamed("operation_page", "s114").
withColumnRenamed("coupon_type", "s115").
withColumnRenamed("gift_type", "s116").
withColumnRenamed("policy_holder_phone", "s117").
withColumnRenamed("award_type", "s118").
withColumnRenamed("surrender_amount", "i010").
withColumnRenamed("renew_fail_reason", "s119").
withColumnRenamed("submit_fail_reason", "s120").
withColumnRenamed("page_belong", "s121").
withColumnRenamed("bank_acc_no", "s122").
withColumnRenamed("bank_name", "s123").
withColumnRenamed("policy_holder_Email", "s124").
withColumnRenamed("policy_holder_adress", "s125").
withColumnRenamed("policy_holder_annual_income", "i011").
withColumnRenamed("policy_holder_live_area", "s126").
withColumnRenamed("policy_holder_occupation", "s127").
withColumnRenamed("filing_entrance", "s128").
withColumnRenamed("tab_name", "s129").
withColumnRenamed("insurance_adress", "s130").
withColumnRenamed("insurance_plan", "s131").
withColumnRenamed("policy_holder_age", "s132").
withColumnRenamed("page_share_agentid", "s133").
withColumnRenamed("user_id", "uin").
withColumnRenamed("date", "ds").
withColumnRenamed("event", "event_code").
select("s009",
"s010",
"s011",
"s012",
"s013",
"i002",
"s014",
"s015",
"s016",
"s017",
"s018",
"s019",
"s020",
"s021",
"s022",
"s023",
"s024",
"s025",
"s026",
"s027",
"s028",
"s029",
"s030",
"s031",
"s032",
"s033",
"s034",
"s035",
"s036",
"i003",
"i004",
"s037",
"s038",
"s039",
"s040",
"s041",
"s042",
"s043",
"s044",
"s045",
"s046",
"s047",
"s048",
"s049",
"s050",
"s051",
"s052",
"s053",
"s054",
"i005",
"s055",
"s056",
"s057",
"s058",
"s059",
"s060",
"s061",
"s062",
"s063",
"s064",
"s065",
"s066",
"s067",
"s068",
"s069",
"s070",
"s071",
"s072",
"s073",
"s074",
"s075",
"s076",
"s077",
"s078",
"s079",
"s080",
"s081",
"s082",
"s083",
"s084",
"s085",
"s086",
"s087",
"s088",
"s089",
"s090",
"i006",
"s091",
"s092",
"s093",
"s094",
"s095",
"s096",
"s097",
"s098",
"s099",
"s100",
"s101",
"s102",
"s103",
"s104",
"s105",
"s106",
"i007",
"i008",
"s107",
"i009",
"s108",
"s109",
"s110",
"s111",
"s112",
"s113",
"s114",
"s115",
"s116",
"s117",
"s118",
"i010",
"s119",
"s120",
"s121",
"s122",
"s123",
"s124",
"s125",
"i011",
"s126",
"s127",
"s128",
"s129",
"s130",
"s131",
"s132",
"s133",
"uin",
"event_code",
"ds",
"time"
).withColumn("app_key", functions.lit("0MA005J3L9A7C4SB"))
.withColumn("event_time",functions.col("time").cast(DataTypes.TimestampType).cast(DataTypes.IntegerType))
.drop("time")
.withColumn("ds", functions.date_format(functions.col("ds"), "yyyyMMddhh"))
.withColumn("i002", functions.when(functions.col("i002").equalTo("NULL"), "0").otherwise(functions.col("i002")).cast(DataTypes.IntegerType))
.withColumn("i003", functions.when(functions.col("i003").equalTo("NULL"), "0").otherwise(functions.col("i003")).cast(DataTypes.IntegerType))
.withColumn("i004", functions.when(functions.col("i004").equalTo("NULL"), "0").otherwise(functions.col("i004")).cast(DataTypes.IntegerType))
.withColumn("i005", functions.when(functions.col("i005").equalTo("NULL"), "0").otherwise(functions.col("i005")).cast(DataTypes.IntegerType))
.withColumn("i006", functions.when(functions.col("i006").equalTo("NULL"), "0").otherwise(functions.col("i006")).cast(DataTypes.IntegerType))
.withColumn("i007", functions.when(functions.col("i007").equalTo("NULL"), "0").otherwise(functions.col("i007")).cast(DataTypes.IntegerType))
.withColumn("i008", functions.when(functions.col("i008").equalTo("NULL"), "0").otherwise(functions.col("i008")).cast(DataTypes.IntegerType))
.withColumn("i009", functions.when(functions.col("i009").equalTo("NULL"), "0").otherwise(functions.col("i009")).cast(DataTypes.IntegerType))
.withColumn("i010", functions.when(functions.col("i010").equalTo("NULL"), "0").otherwise(functions.col("i010")).cast(DataTypes.IntegerType))
.withColumn("i011", functions.when(functions.col("i011").equalTo("NULL"), "0").otherwise(functions.col("i011")).cast(DataTypes.IntegerType))
.filter(functions.col("event_code").equalTo("activityView")
.or(functions.col("event_code").equalTo("applyResult"))
.or(functions.col("event_code").equalTo("award"))
.or(functions.col("event_code").equalTo("baoQuanApply"))
.or(functions.col("event_code").equalTo("baoQuanResult"))
.or(functions.col("event_code").equalTo("baoQuanSumbit"))
.or(functions.col("event_code").equalTo("claimSettlement"))
.or(functions.col("event_code").equalTo("freeInsurancePhone"))
.or(functions.col("event_code").equalTo("freeInsuranceReceive"))
.or(functions.col("event_code").equalTo("payInsuranceResult"))
.or(functions.col("event_code").equalTo("prizeDraw"))
.or(functions.col("event_code").equalTo("propertyCarInfoComplete"))
.or(functions.col("event_code").equalTo("propertyCarInsuranceCheck"))
.or(functions.col("event_code").equalTo("propertyCarInsurancePay"))
.or(functions.col("event_code").equalTo("propertyCarInsurancePayResult"))
.or(functions.col("event_code").equalTo("propertyCarInsuranceRenewPay"))
.or(functions.col("event_code").equalTo("propertyCarInsuranceSubmit"))
.or(functions.col("event_code").equalTo("propertyImmediateInsuranceClick"))
.or(functions.col("event_code").equalTo("receivingClaims"))
.or(functions.col("event_code").equalTo("registFinish"))
.or(functions.col("event_code").equalTo("signIn"))
.or(functions.col("event_code").equalTo("task"))
.or(functions.col("event_code").equalTo("terminateInsuranceFinish"))
.or(functions.col("event_code").equalTo("$pageview"))
.or(functions.col("event_code").equalTo("$pageclose"))
.or(functions.col("event_code").equalTo("$pagestay"))
.or(functions.col("event_code").equalTo("$share"))
.or(functions.col("event_code").equalTo("$MPPageShow"))
.or(functions.col("event_code").equalTo("$MPPageHide"))
.or(functions.col("event_code").equalTo("$MPLaunch"))
.or(functions.col("event_code").equalTo("$MPShow"))
.or(functions.col("event_code").equalTo("$MPHide"))
.or(functions.col("event_code").equalTo("$MPShare"))
.or(functions.col("event_code").equalTo("$AppPageView"))
.or(functions.col("event_code").equalTo("$AppPageClose"))
.or(functions.col("event_code").equalTo("$AppInstall"))
.or(functions.col("event_code").equalTo("$AppStart"))
.or(functions.col("event_code").equalTo("$AppEnd"))
.or(functions.col("event_code").equalTo("$SessionStart"))
.or(functions.col("event_code").equalTo("$SessionEnd"))
.or(functions.col("event_code").equalTo("$Subscribe"))
.or(functions.col("event_code").equalTo("$Unsubscribe"))
.or(functions.col("event_code").equalTo("$MenuClick"))
.or(functions.col("event_code").equalTo("$FollowerSendMsg"))
.or(functions.col("event_code").equalTo("$TemplateMsgSend"))
.or(functions.col("event_code").equalTo("$TemplateMsgSendSuccess"))
.or(functions.col("event_code").equalTo("$TemplateMsgSendFailed"))
)
// .filter(functions.col("uin").cast(DataTypes.LongType).gt(0))
.withColumn("uin", functions.abs(functions.col("uin").cast(DataTypes.LongType)))
.toDF();
其他挖掘方法
其实挖掘数据没有太多的技术难点, 懂得大数据生态, 分布式计算的一般原理,再学习一个像 spark 这样的库就可以了。 我们可以用 spark sql 或者 dataframe 来去分析数据,并提出我们需要的数据。 这些 API 跟用正常的 sql 和 pandas 几乎没什么区别,只是换成了分布式计算场景而已。 这里就不详细的去讲了。 感兴趣同学可以去查阅相关资料, 后面我可能也会单独写一个大数据和 spark 的教程。
图像数据
图像数据比较复杂, 它主要分成图片数据和视频数据。 图片数据主要需要 opencv 这样的库进行处理, 视频数据主要依赖 ffmpeg。 我们一个个说吧, 先说视频数据。 首先需要声明的是在计算机视觉领域中的模型,也是针对图片进行处理的,而不是视频。 业务上可能对接的是视频数据,但最终也需要针对视频流进行解码/抽帧/图像增强/预处理等操作后把一张张图片交给模型处理。 所以本质上模型对着的都是图片。 但在测试中我们是针对整个系统进行测试的,在现实项目中系统的数据往往对接各种各样的摄像设备进行采集的,比如路边的各种摄像头。 所以我们需要去模拟视频数据进行测试。 而这时候我们需要 ffmpeg 完成视频数据的制作。
视频合成
在很多情况下测试人员手中符合场景要求的视频数据是很少的,为了能扩充数据,我们往往也会使用图片来合成视频数据。比如让一张图片连续播放多少秒来模拟视频。
ffmpeg -f image2 -r 1/10 -i %03d.jpg output.mp4
-f image2代表输入的格式,在这里我们输入的是一系列图片-r 1/10设置帧率(FPS,每秒刷新的帧数,文章后面详细讲解),1/10 代表一帧图片会播放 10s 钟-i %03d.jpg设置输入图片的规则
视频裁剪
在一些场景中,测试人员拿到的视频数据都是比较为原始的。比如在用 AI 模型识别安全生产的场景中(识别工人是否佩戴安全帽,安全带,手套,口罩,防护服等等),又或者识别社区烟雾/火灾这样的场景中, 摄像头可能是 24 小时全天候开启的,这其中有大量的时间段采集的视频数据是不符合测试场景的。很多时候只有一小部分符合测试要求, 所以这就需要讲视频进行一定的裁剪。
ffmpeg -ss 0 -t 10 -i transformer.mp4 begin.mp4
-ss 设置视频的开始时间
-t 设置时长
上述命令会将原始视频的第 0 秒开始,裁剪出 10s 的视频出来。 其中的-ss 也可以用 00:00:00 这样的时分秒格式。
视频拼接
有视频裁剪就有视频拼接,在需要输入视频流的场景中,我们需要把所有测试视频合并成一个大视频并根据视频生成视频流。所以我们有了视频拼接的场景:
先创建一个文本文件 filelist.txt:
file 'input1.mkv'
file 'input2.mkv'
file 'input3.mkv'
然后执行:
ffmpeg -f concat -i filelist.txt -c copy new.mp4
其余的场景先不列出来了, 这里面也是举一些例子。后面有时间会出详细的 ffmpeg 和 opencv 的教程。
图片数据
针对图片数据的处理也比较复杂,我们需要在茫茫多的图片中去筛选出符合我们场景需要的图片。 它非常的恶心就是几乎没什么自动化的方式能做这个事情, 它不像结构化数据,在上面说 spark 的时候我们就知道, 在结构化数据里每一列的意思都很清楚,我们可以通过简单的脚本就可以把我们需要的数据筛选出来。 但图片数据是没办法精准的过滤的。需要的是大量的人工筛选工作,这个很难绕的过去。
不过我们也是有一些方法能尽量减少人工介入的成本。 我这边想到的方法是 图片相似度计算 +yolov8 模型识别目标 +blip 模型识别更细节的目标:
图片相似度
很多数据的采集其实是从某一个视频中(也可能是从摄像头中采集出来的视频数据)进行抽帧而来的,比如用 ffmpeg 针对某个视频进行抽帧:ffmpeg -i meeting_01.mp4 -r 1/60 -f image2 ./test/%08d.000000.jpg 。 这是一段每秒抽一帧的命令, 但我们知道一个视频里计算 1s 抽一帧, 还是有很多重复的,比如我们很多数据来源也是从视频网站上下载而来的,或者从 BBC 上下载的公开视频。 里面很多采访画面,连续很长时间都是这个人在说话,几乎没有任何的动作改变和背景改变。连续的抽这样的图片其实很多都是重复的,没有意义,只要保留 1,2 张就可以了。 所以我们可以使用 opencv 来计算图片的相似度来去掉大量的重复的图片, 下面是一个计算两张图片之间的相似度的核心代码:
def compare(img1, img2):
img1 = cv2.resize(img1, (500, 500))
img2 = cv2.resize(img2, (500, 500))
hist1 = cv2.calcHist([img1], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
hist2 = cv2.calcHist([img2], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
# Normalize histograms
cv2.normalize(hist1, hist1, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
cv2.normalize(hist2, hist2, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
similarity = cv2.compareHist(hist1, hist2, cv2.HISTCMP_CORREL)
return similarity
上面代码是利用 opencv 取图片直方,然后通过直方对比两个图片之间的差异。
yolov 过滤图片
上次文章介绍 aigc 的测试方法时说过用 yolov + blip 可以组一些 bug 挖掘的工作。 我借鉴这个思路来做数据挖掘。 比如现在我们有一个人体行为/属性 识别的模型, 我们需要收集这个场景的数据。 但就如我之前所说,除了大量的重复图片外,还可能有很多图片中并没有人体存在(尤其是在路边的摄像头中采集的数据,没有人提的情况非常常见)。 而 yolov 是一个 80 分类的目标检测模型,其中就包括了人体(id 为 0),所以我们可以让 yolo 帮我们把没有人体的图片都过滤掉。
blip 进一步的过滤
blip 是一个多模态模型,它是用 4 亿个文本 - 图片 配对来进行训练的模型, 原理上它把图片数据和文本数据分别编码后形成了特征向量,然后计算图片向量和文本向量的余弦相似度。这样它就建立了一个图像 - 文本的映射关系。 我们就可以做很多事情, 比如给定一个图片, 你可以让 blip 生成一个针对这个图片的文本, 也可以给定一个文本和图片,让 blip 图判断它们的匹配程度, 也可以做图片分类。 这里我选择准备一个图片和针对这个图片的一个问题, 然后让 blip 回答这个问题。 比如它的官方 demo:
batch_size = 3
# create a batch of samples, could be multiple images or copies of the same image
image_batch = image.repeat(batch_size, 1, 1, 1)
# create a batch of questions, make sure the number of questions matches the number of images
question_1 = txt_processors["eval"]("Which city is this photo taken?")
question_2 = txt_processors["eval"]("What time is this during the day?")
question_3 = txt_processors["eval"]("Is it Singapore or London?")
question_batch = [question_1, question_2, question_3]
model.predict_answers(samples={"image": image_batch, "text_input": question_batch}, inference_method="generate")
上面的 demo 里我们问了图片中的 3 个问题, 而 blip 会回答我这几个问题。 所以我们可以利用这个特性来帮助我们过滤图片。 比如举一个我们真实的例子, 在我们做一个项目的时候, 在一个识别垃圾的模型中, 把人类手中拿的手机识别成了垃圾(酒瓶), 这个负样本是我们之前没有想到过的。 所以我们急切的需要一批人拿着手机的图片,拿着水杯的图片等等来进行补充测试。 这时候如果我们去跟数据组走流程申请数据(数据组可以爬取一些数据),或者在项目上去采集数据, 都比较慢了。 但我可以去已有的图片库中进行筛选,因为我们有好多模型,我们针对这些模型有好多的测试数据,这个是一个垃圾识别场景,但我们也有很多人体行为/属性识别的模型, 哪些模型有很多的人的图片。 其中就包含了有些人是拿着手机的。 所以我可以在迅速的在图片库中找到符合要求的图片。
PS: 有些同学会说直接百度一下,能找到很多图片, 但这里要说一下, 这在大多数时候是不行的。 跟人有关系的图片都是有数据安全风险的, 因为人是有隐私的, 相关法规和行业规则下,我们不能随便去网络上爬人的图片的。 所以在流程上,这些敏感数据是不能让测试人员随便去网上找的。 要提需求给数据组,数据组会找到安全合规的数据。 所以我们自己只能在已有的图片库里去筛选。
最终脚本
下面我给一个图片相似度 +yolov+blip 的脚本 Demo:
import os
import cv2
import torch
from PIL import Image
import numpy as np
from lavis.models import load_model_and_preprocess
from ultralytics import YOLO
import queue
import collections
filter_persion = True
questions = ['Is the person in the picture holding a phone?']
ori_imgs_dir = '../image'
output_imgs_dir = './filter_img/'
# 截取图片
def crop_image(img, x, y, w, h):
# 计算截取范围
x_min = int(x - w / 2)
y_min = int(y - h / 2)
x_max = int(x + w / 2)
y_max = int(y + h / 2)
# 截取图片
cropped_img = img[y_min:y_max, x_min:x_max]
return cropped_img
# 计算图片相似度的函数
def compare(img1, img2):
img1 = cv2.resize(img1, (500, 500))
img2 = cv2.resize(img2, (500, 500))
hist1 = cv2.calcHist([img1], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
hist2 = cv2.calcHist([img2], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])
# Normalize histograms
cv2.normalize(hist1, hist1, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
cv2.normalize(hist2, hist2, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
similarity = cv2.compareHist(hist1, hist2, cv2.HISTCMP_CORREL)
mean = np.mean((img1 - img2) ** 2)
return similarity
# 存储最近的60张图片, 用来判断图片相似度.
image_queue = collections.deque(maxlen=60)
# setup device to use
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model, vis_processors, txt_processors = load_model_and_preprocess(name="blip_vqa", model_type="vqav2", is_eval=True, device=device)
yolo_model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML建立并转移权重
# 读取图片
dir_path = ori_imgs_dir
for root, dirs, files in os.walk(dir_path):
files.sort()
for i, file in enumerate(files):
file_path = os.path.join(root, file)
org_img = cv2.imread(file_path)
# 调用yolo判断是不是有人类
imgs = [file_path]
results = yolo_model.predict(imgs, conf=0.9, classes=0)
if results[0].boxes.data.numel() == 0:
# 说明没有人类
continue
# 开始计算图片相似度
# 1. 计算yolo识别出来的人体的坐标并把目标扣出来
# 2. 挨个与缓存中的图片进行相似度对比, 如果相似度超过阈值,则跳过.
cropped_imgs = []
flag = False
for result in results:
boxes = result.boxes.xywh.numpy()
for i in range(boxes.shape[0]):
box = boxes[i]
x = box[0]
y = box[1]
w = box[2]
h = box[3]
cropped_img = crop_image(org_img, x, y, w, h)
cropped_imgs.append(cropped_img)
# 判断图片相似度
for item in image_queue:
for cropped_img in cropped_imgs:
same = compare(cropped_img, item)
if same > 0.8:
#print("compare: " + str(same) + " image1: " + pre_image_path + " image2: " + path)
flag = True
break
if flag:
break
if flag:
continue
# 开始通过blip模型,判断图片是否符合要求
raw_image = Image.open(file_path).convert("RGB")
#image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
for question in questions:
for i in cropped_imgs:
tmp = cv2.cvtColor(i, cv2.COLOR_BGR2RGB)
tmp = Image.fromarray(tmp)
image = vis_processors["eval"](tmp).unsqueeze(0).to(device)
question = txt_processors["eval"](question)
samples = {"image": image, "text_input": question}
answers = model.predict_answers(samples=samples, inference_method="generate")
print(answers)
if 'yes' in answers:
image_name = os.path.basename(file_path)
cv2.imwrite(output_imgs_dir + image_name, org_img)
flag = True
break
if flag:
break
if flag:
for i in cropped_imgs:
image_queue.append(i)
模型微调
上一篇讲解用 yolo+blip 来测试 AIGC 场景的时候说过 ,一般我们需要用迁移学习的原理做一些模型的微调来适应我们自己的场景。 我们以上面的数据挖掘工具为例子来讲解一下一般模型微调的过程。 在图片数据挖掘中,yolo 的原始模型会在图片中出现人体的部分身体就会判断有人存在(只有一双手,只有一个头), 而很多时候我们希望的图片是有人体的全部身体的(因为很多场景是人体属性和人体姿态识别,需要人的全身)。 所以为了把只有部分人体的图片过滤出去, 需要我们针对模型进行微调。 微调 yolov8 的代码如下:
from ultralytics import YOLO
import cv2
import numpy as np
# 加载模型
model = YOLO('yolov8n.yaml').load('./runs/detect/train37/weights/best.pt') # 从YAML建立并转移权重
# 训练模型
results = model.train(data='./mydata.yaml', epochs=15, freeze=10)
imgs = ['./datasets/test_data/images/train/022.jpg']
results = model.predict(imgs, conf=0.1, classes=0,show==true)
微调 yolo 的模型是非常简单的, 因为 yolo 有专门的开源项目并且把所有负载的计算过程都进行了封装,大家在 github 上搜索 ultralytics 就好。 但这里仍然需要我们进行一些准备工作(主要是准备数据)。 这里 yolo 要求我们把数据转换成 coco txt 格式(图片数据单独存放在一个目录, label 存放在另一个目录下,并且每个图片都有一个同名的 txt 文件作为 label 文件,label 文件中记录着图片中的分类和对应的坐标)。 如下图是 coco128 的文件目录:
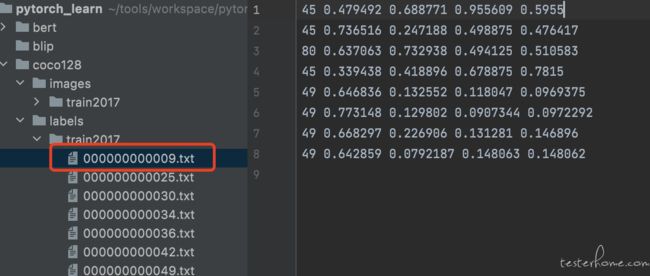
上面是 coco 数据集的格式, 每个图片都对应一个 txt 的 label 文件, 这个 label 文件里记录了这个图片中所有的目标的分类 ID 和坐标信息。然后我们需要准备一个 yaml 文件来描述数据:
path: ./coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
可以看到这个 yaml 文件描述了数据的路径和分类信息。 当准备好这样的数据后就可以运行之前显示的进行微调了。 我这里准备了 10 张只有一双手的图片,比如:
我的目的就不希望把只有一双手的图片判定成人, 所以用这些图片来微调模型。 我们看一下效果,经过我用 10 张图片微调的结果:
而在看一下原始的 yolov8 模型的结果:

可以看到原始的 yolov8 模型判断这张图片中有人的概率是 71% 而我用 10 张图片微调后的模型认为图片中有人体的概率是 69%,降低了 2%, 效果没有那么明显, 这是因为我只用了 10 张图片来微调的(数据量还是太少了),如果数据量可以扩充到 100 张,那么效果会更加明显。 如果我们有足够的数据,那么就可以让这个效果更加明显,也就是模型会判断只有一双手的图片的概率越来越低, 这样我们设置一个合理的阈值(比如 0.7,意思是只有概率大于 70% 的时候我们才认为图片中的这个目标是人类)。 那么这就是一个简单的模型微调的过程。
数据质量
很遗憾的是数据质量在非结构化数据领域中几乎很难能做什么事情, 因为我们很难能总结出一些好用的规则来判断什么样的图片是好的,什么样的图片是不好的。 当然一些非常容易判断的场景除外。 比如不知道大家在直播业务中是否有相关的测试需求,比如要判断画面是否有雪花,乱码,噪点这些。 这种倒是比较容易能够通过模型把他们揪出来。 一般我们可以微调一个 blip 模型,找到一些质量不好的图片,然后训练让 blip 能够识别这些质量不好的图片。 这样不管我们是做离线的自动化测试,还是在线的直播质量监控,都可以有用武之地。 大家也可以在 github 上搜索 blip 项目,那里面会有教程来演示如何微调 blip 来达到我们想要的效果。
而在结构化领域中,数据质量就比较容易了。 我们可以使用很多分布式计算技术,不管是 spark,hive 还是各种存储软件的 sql。都可以完成这个目的。 当然这里要说的是普通的 python 的方式无法处理大规模的数据,所以我们一定还是要利用分布式计算来完成相关的目标。 比如我们要开发一个数据质量监控或者测试数据本身的测试脚本。 那么可以使用 spark 来完成这个目的:
from pyspark import SparkContext, SparkConf, SQLContext
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# # 创建 SparkSession
# spark = SparkSession.builder \
# .appName("Quality Check for my_table") \
# .getOrCreate()
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
rdd = sc.parallelize(range(1000))
print(rdd.map(lambda x: '%s,%s' % ('男', '16')).collect())
dicts = [
['frank', 202355, 16, '[email protected]'],
['frank', 202355, 16, '[email protected]'],
['frank', 202355, 16, '[email protected]'],
['frank', 202355, 16, '[email protected]'],
['frank', 202355, 16, '336051asdf'],
['', 452345, 16, '336051asdf'],
]
rdd = sc.parallelize(dicts, 3)
dataf = sqlContext.createDataFrame(rdd, ['name', 'id', 'age', 'email'])
# 验证 id 字段必须是整数
id_filter = F.col("id").cast("int") >= 0
# 验证 name 字段必须是非空字符串
name_filter = F.col("name").isNotNull() & (F.col("name") != "")
# 验证 age 字段必须是大于等于 0 的整数
age_filter = F.col("age").cast("int") >= 0
# 验证 email 字段必须是有效的电子邮件地址
email_filter = F.col("email").rlike("^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$")
# 应用过滤条件
valid_data = dataf.filter(id_filter & name_filter & age_filter & email_filter)
# 输出符合质量要求的数据
valid_data.show()
# 输出不符合质量要求的数据
invalid_data = dataf.exceptAll(valid_data)
invalid_data.show()
上面是一个测试数据质量的 demo 脚本, 利用 spark dataframe 的 API 来完成对数据的扫描。 在业务中我们往往需要写很多校验规则来验证数据本身, 我经理过的最复杂的脚本是定制了 300 多条规则来检查一份数据是否符合质量标准。 在上一篇介绍自学习和数据闭环的时候有说过数据采集后需要一道数据质量预警,而在这一步我们一般就会利用上面这段代码这样的方式来针对数据进行测试。 由于数据量往往很大,所以我们往往使用 spark 这样的分布式计算技术来提升测试效率。
文本数据
文本数据的采集是非常难的, 我们可以在网络上找到非常庞大的文本并建立语料库, 但是为这些文本生成标注就非常难了。 假设你的团队在构建一个大模型, 这需要非常庞大的 文本 - 答案 数据。 除了要从专业的论文和专业的人员中获取相关数据之外, 项目中往往也会用以下几种方法来构建数据集:
- 问答挖掘模型:根据给定的文本或对话,提取出一个或多个问题 + 答案对。
- 文本摘要模型:将较长的文本或对话转换成简短,流畅而准确的摘要
- 权威模型借鉴:将文本输入到权威模型中(比如 gpt4),把权威模型输出的答案作为问题的答案(很显然这种方式很鸡贼,这也是为什么说我们很难超越 GPT 那样的模型,因为我们可能连答案都是从人家那抄的,还不一定抄的对不对)
也就是说,我们是用模型来去提取文本中的训练和测试数据。 其实还有一些其他的用模型来提取文本中的信息来生成训练和测试数据的方法,但这里就不详细说了,因为这些模型讲道理也不是测试人员做出来的。 一般会由算法团队来开发这些提取模型, 然后测试团队负责测试这些模型的效果。 具体如果评估效果可以参考我上一篇文章。
尾声
这次就先写这么多吧, 主要讲数据挖掘的一些方法。 这些事情比较繁琐但很重要, 毕竟评测模型的测试人员, 其实 80% 以上的时间都花在了处理数据上。
想看更多内容请进入我的知识星球, 我会定期更新原创的高质量测试开发教程
