网站流量日志分析
网站流量日志分析
通过分析用户的行为数据让更多的用户沉淀下来变成会员赚取更多的钱
-
如何进行网站分析
-
流量分析
质量分析: 在看中数量的同时需要关注流量的质量,即流量所能带来的价值
多维度细分: 维度指定是分析问题的角度,在不同的维度下,问题所展示的特性是不一样的
例如:

2.内容导航分析
从页面的角度分析用户的行为轨迹
3.转化分析(漏斗模型分析)
从转化目标分析,分析所谓的流失率或者转化率,层层递减逐级流失的描述模型
-
网站流量日志分析的数据处理流程
按照数据的流转流程进行,就是数据从哪里来到哪里去
- 数据采集
数据从无到有的过程:通过技术手段把客观事件量化成数据(传感器收集,服务器日志收集)
数据搬运过程:把一个存储介质中的数据搬运到另一个 存储介质中(Flume) - 数据预处理
目的:保证后续正式处理的数据是格式统一,干净规整的结构化数据
技术:任何语言只要能接受数据处理并且能输出数据,就可以使用
选择MapReduce 因为MR本身就是java程序,语言比较熟练,而且可以无缝调用java现有的开源库进行数据处理 而且MR本身就是分布式程序,在预处理的过程中,如果数据较大,可以使用分布式计算处理数据,提高效率 - 数据入库
库:面向分析的数据库,数据仓库Hive
入库:通过ETL(抽取,转化,加载)将不同数据源中的数据加载到数仓的分析主题之中 - 数据分析
根据业务需求,通过hive sql计算统计出各种不同的指标,数据分析是一个持续化过程 - 数据可视化
尽量使用图形表格的形式,把分析出的数据展示给别人看也称为数据报表
-
系统的架构
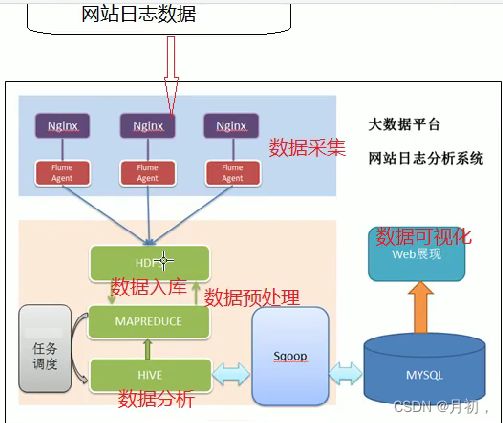
-
功能使用
- 数据采集
页面埋点JavaScript采集(Nginx);开源框架ApacheFlume数据传输 - 数据预处理
HadoopMapReduce 程序 - 数据仓库
Apache Hive - 数据导出
Apache Sqoop数据导出工具 - 数据可视化
定制开发web程序(echarts)JS - 整个过程的流程调度
Hadoop azkaban工具
1.数据采集功能如何实现
1.数据采集
- 网站日志文件
网站web服务器自带的日志记录功能 简单便捷的收集一些基础的属性信息 常见的web】服务器(Tomcat nginx apache server(httpd))
优点:简单便捷,自带功能 不需要配置就可以使用
缺点:收集信息确定 不利于维护 收集的信息不够完整全面 - 埋点JavaScript
何为埋点:在待采集数据的页面上,预先置入一段JavaScript代码,当用户某种行为满处代码条件时,触发JavaScript的执行,在执行过程中进行数据采集的工作。
目标:不以影响用户正常浏览体验作为标准 数据采集分析锦上添花
标准的UR:协议://主机:端口/资源路径?k1=v1&k2=v2
好处:可以根据业务需求 定制化手机属性信息 在不影响用户浏览体验的情况下进行数据收集
2.埋点js代码实现自定义收集用户数据
js和html页面耦合在一起 不利于后续js维护
把js单独提取变成一个文件 然后通过src属性引入页面 进行所谓解耦合
一台服务器身兼多职 压力过大 降低服务器请求压力
单独的去部署服务器 专门用于采集数据的请求响应
可能会产生跨域问题(限制js跨域的数据发送)
以请求图片的形式 把采集的数据拼接成为图片的参数 发送到指定的服务器上去 绕开js跨域问题
3.确定收集的信息
通常在收集数据之前结合业务需求分析 分析需求确定收集的信息有哪些字段和收集途径
- 可以通过nginx内置的日志收集功能获取到
- 可以通过页面上内置的对象常见属性获取到
- 可以自定义编写js代码进行相关属性的收集
4.埋点代码的编写
本来埋点代码的逻辑就是真正进行数据收集的逻辑,但是为了后续维护方便 把真正收集数据的js提取出变成js文件,在这种情况下,埋点代码就变成了如何把这个js文件引入到页面上
1.直接通过src属性引入
5.前端收集数据js
- 依然是一个匿名函数自调用的格式,保证被引入到页面上之后 自己可以调用自己执行且执行一次
- 通过页面内置对象获取一些属性信息
- 通过解析全局数据获取一些信息
- 把收集的属性信息按照url格式进行拼接 并进行url编码
- 页面创建一个图片标签 把标签的src属性指向后端收集数据的服务器
- 把收集数据拼接的参数放置请求图片url传递给后端
6.后端脚本
所谓后端就是接受解析前端发送采集数据的服务器
- 接受请求 解析参数 保存数据
- 响应图片 log.gif 1*1
- 响应cookie
注意搞清楚 nginx中location模块的具体职责:用于请求url资源路径的匹配
7.日志格式
考虑日志中字段之间的分隔符问题,以后有利于程序处理数据方便
常见的分隔符 制表符 空格 特殊符号 \001
8.日志切分
nginx默认把日志一直写在一个文件中access.log 不利于后续的维护移动操作处理
通过shell脚本给nginx进程发送usr1信号 告知其重载配置文件 在重载配置文件的时候 重新打开一个新的日志文件 在配合crontab定时器 从而完成间接的通过时间配置文件的滚动
注 :tomcat默认对外发布服务的路径是/var/www/html
nginx默认网址路径是 /usr/local/nginx/html/
2.数据预处理功能
1.在正式处理数据之前对收集的数据预先处理的操作
- 原因:不管通过任何手段手机的数据 往往是不利于直接分析的 数据中村砸死的格式规整的的差异
- 目的:把不干净的数据 格式不规则的数据 通过预处理变成格式统一规整的结构化数据
- 技术:MapReduce
2.预处理的编程思路
在使用mr编程的过程中牢牢把握住key是什么 因为mr中key有很多默认的属性
分区-->key 哈希 % reducetasknums
分组-->key相同的分为一组
排序-->按照key的字典序排序
3.MapReduce 编程技巧
- 涉及 多属性数据传递 通常采用建立javabean携带数据
- 有意识的重写对象toString方法并且以\001进行字段分割 便于后续数据入库
- 针对本次分析无效的数据 通常采用建立标记位的方式进行逻辑删除
3.数仓设计
3.1维度建模
以维度为标准,开展数据的分析需求
适用于面向分析领域的理论,比如分析型数据库,数据仓库 数据集市
事实表
分析主题的客观事件度量 是分析主题的数据聚集 试试表中一条记录往往对应的客观的一个时间,往往是一堆主键的聚集
维度表
所谓的维度表就是看待问题的角度 可以通过不同的维度去分析一个事实表 得出不同的分析结果 维度表可以跟事实表进行关联查询
Q:点击流模型数据算什么类型的表?
点击流模型数据既不是事实表 也不是维度表 是一个业务模型数据 可以称为事实表的业务延伸
3.2多维度数据分析
所谓的多维度数据分析就是指通过不同维度的聚集计算出某种度量值
常见度量值:max min count sum avg topN
举个例子:统计来自北京女性24岁未婚的过去三年购物金额最多的三个。
维度可以分为: 地域 性别 年龄 婚姻 时间
度量值:sum (订单金额)--->top3
3.3维度建模的三种模式
-
星型模式
一个事实表多个维度表,维度表之间没有关系 维度表跟事实表进行关联 企业数仓发展初期常见的模型 -
雪花模式
一个事实表多个维度表 维度表可以继续关联维度表 但是不利于后期的维护 企业中尽量避免演化该模型 -
星座模式
多个事实表 多个维度表 某些维度表可以共用 企业数仓发展中后期常见的模型
事实表:对应着数据预处理之后的原始网站日志情况
维度表:通常要结合业务决定分析的维度 要和事实表能够关联上 要以能够涵盖事实表位基本标准
3.4 数据入库ETL
- 常见ODS层表
1.表名通常以剪短的英文表示 不使用汉语拼音甚至中文
2.建表的时候表的字段顺序类型要和数据保持一致
3.通常企业中采用分区表进行优化,方便后续查询管理 - 导入ODS层表数据
原始日志表load data local inpath'/root/hivedata/part-m-00000' into table ods_weblog_origin partition(datestr = "20231201") ;点击流模型之pageviews表
load data local inpath'/root/hivedata/part-r-00000' into table ods_click_pageviews partition(datestr = "20231201") ;点击流模型之visit
load data local inpath'/root/hivedata/part-r-00000' into table ods_click_stream_visitpartition(datestr = "20231201") ;时间维度表数据
load data local inpath'/root/hivedata/dim_time.dat' into table t_dim_time ; -
宽表窄表的引入
为了分析方便,可以事实表中的一个字段切割提取多个属性出来构成新的字
段,因为字段变多了,所以称为宽表,原来的成为窄表。
又因为宽表的信息更加清晰明细,所以也可以称之为明细表。 -
宽表的实现
1.宽表的数据由何而来: 由原始窄表得到
2.宽表需要扩宽哪些字段:由业务而定
3.使用什么技术扩宽字段:insert into 宽名 select from 窄名 插入什么语句取决于返回的结果,所以查询的时候就需要使用hive语句进行拓宽操作
简单的拓宽可以使用字段截取:select substring(time_local,6,2)as month from ods_weblog_origin limit 1;来源url的高级拓宽:
select a.*,b.* from ods_origin a LATERAL VIEW parse_url(regexp_replace(http_referer,"\"",""), 'HOST','PATH','QUERY','QUERY:id') b as host,path,query,query_id; -
基础指标:
一些比较单一的指标,很容易判断理解如
pv:页面的加载总次数
uv:独立访客数
vv:会话次数 -
复合指标:
在基础指标之上,通过一些简单的计算产生的指标如
1.平均访客次数:一天之内人均会话数==总的会话次数(session)/总的独立访客数=vv/uv
2.平均访问深度:一天之内人均浏览页面数==总的页面浏览数/总的独立访客数==pv/uv
3.平均会话时长:平均每次会话的停留时长==总的会话停留时长./会话次数
4.首页跳出率:访问网站且该页面是首页/总的访问次数
4.指标分析
基础指标分析 :
1.pageview浏览次数(pv):一天之内网站被访问的总次数
分析依据:
- 数据表
- 分组字段 where过滤即可
- 度量值: count(*)
- SQL语句:
select count (*) from dw_weblog_detail t where t.datestr="20181101" and t.valid="true";
2.Unique Vistor 独立访客(UV):一天内不重复的访客数
- 数据表
- 分组字段 where过滤即可
- 度量值: count(distinct remove_addr)
- SQL语句:
select count(distinct remote_user)as uv from dw_weblog_detail t where t.datestr="20181101";
3.访问次数:一天内的会话次数(session数)
- 数据表
- 分组字段 where过滤即可
- 度量值: count(session) 如果使用 ods_click_pageviews进行计算 count(distinct session)
- SQL语句:
select count(t.session) as vv from ods_click_stream_visit t where t.datestr="20181101";
4.IP :一天内不重复的ip个数类似于uv独立访客
- 数据表
- 分组字段 where过滤即可
- 度量值: count(distinct remove_addr)
- SQL语句:
select count(distinct remote_user)as ip from dw_weblog_detail t where t.datestr="20181101";
2. 复杂指标分析
1.平均访问频度: 一天之内访问人均产生的会话次数
- 数据表
- 分组字段 where过滤即可
- 度量值:vv/uv
- SQL语句:
select vv/uv from dw_webflow_basic_info t where t.datestr="20181101"; --上述指标不符合客观规律 --原因:在计算基础指标的时候 uv使用的是宽表的数据 没有进行静态资源的过滤 --vv使用的是点击流模型的数据 在预处理阶段进行了静态资源的过滤 --一个采用过滤的一个采用未过滤的 计算的指标不合法 --解决方法 统统采用过滤后的静态资源进行计算 ods_click_stream_visit select count(t.session)/count(distinct t.remote_addr) from ods_click_stream_visit t where t.datestr="20181101";
2.平均访问时长 :一天内用户平均每次会话在网站的停留时长
总的停留时长/会话的次数
- 数据表:
- 分组字段 where过滤即可
- 度量值:sum(page_staylong)/count (distinct session)
- SQL语句:
select sum(t.page_staylong)/count (distinct t.session) from ods_click_pageviews t where t.datestr="20181101";
3.跳出率 计算/hadoop-mahout-roadmap的跳出率
- 数据表:
- 分组字段 where过滤即可
- 度量值:count
- 过滤条件:会话的访问页面次数为1,并且该页面是指定的页面
- SQL语句
select count (t.session) from ods_click_stream_visit t where t.datestr="20181101" and where t.pagevisits=1 and t.inpage="/hadoop-mahout-roadmap";
3.多维数据分析、
多维数据分析
- 维度:指的是看待问题的角度
- 本质:基于多个不同的维度进行聚集 计算出某种度量值(count sum max mix topN)
- 重点:确定维度 维度就是sql层面的分组字段
- 技巧:按xx 每xx 各xx
时间维度统计:
计算该处理批次一天内各小时的pv
- 数据表
- 分组字段:时间(day hour)day字段比较特殊 day是表分区字段 可以通过where 过滤
- 度量值:count(*)
- sql语句:
select t.hour,count(*) as pvs from dw_weblog_detail t where t.datestr="20181101" group by t.hour;
计算每天的pvs
方式一:dw_pvs_everyhour_oneday 将每个小时的pvs进行sum求和
select sum(pvs) from dw_pvs_everyhour_oneday t where datestr="20181101";
方式二:dw_weblog_detail 直接基于宽表计算出每天的pvs
select count(*) from dw_weblog_detail where datestr="20181101";
方式三:如果数据不是分区表 直接根据day进行分组
select
t.month,t.day,count(*) as pvs
from dw_weblog_detail t where t.datestr="20181101" group by t.month ,t.day;
事实表和维度表进行关联查询
关联查询的重点是join字段 跟时间相关的
sql:
insert into table dw_pvs_everyday
select count(*) as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) a
join dw_weblog_detail b
on a.month=b.month and a.day=b.day
group by a.month,a.day;拓展:使用维度表关联的方式计算每个小时的pvs
sql:
insert into table dw_pvs_everyhour
select count(*) as pvs,a.month as month,a.day as day,a.hour as hour from (select distinct month, day,hour from t_dim_time) a
join dw_weblog_detail b
on a.month=b.month and a.day=b.day and a.hour=b.hour
group by a.month,a.day,a.hour;按照来访维度,时间维度分析
统计每小时,各来访url产生的pv量
- 数据表
- 分组字段:时间维度,来访referer(url)
- 度量值:count()
- sql:
insert into table dw_pvs_referer_everyhour partition(datestr='20181101') select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt from dw_weblog_detail group by http_referer,ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,pv_referer_cnt desc;
统计每小时,各来访host的产生的pv数并排序
- 数据表
- 分组字段:时间维度(hour),来访维度(host)
- 度量值:count()
- sql:
select ref_host,month,day,hour,count(1) as ref_host_cnts
from dw_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;TopN问题
统计每小时各来访host的产生pvs数最多的前N个
- 数据表
- 分组字段:时间维度(hour),来访维度(host)
- 度量值:count()
- sql:
select t.hour,t.od,t.ref_host,t.ref_host_cnts from (select ref_host,ref_host_cnts,concat(month,day,hour) as hour, row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od from dw_pvs_refererhost_everyhour) t where od<=3;
5. SQL扩展
例如:
SELECT
count(sex) as nums
FROM (SELECT
a.*,b.*
FROM a join b on a.id=b.id
where ...
)t
where t.city="beijing"
group by t.sex
HAVING t.sex is not NULL
order by nums DESC limit 10 ;
-- 在编写select查询语句时 select确定之后要立马去寻找from关键字 因为后面跟的急速操作的表
--表可能是真实存在的表 如果是真实存在的表 那么直接使用
--表也可能不存在 设法通过查询把这个表查询出来 基于这个虚拟的表进行操作
--只有表确定之后 在结合业务确定返回的字段或者表达式
-- 嵌套子查询,先执行里面的查询语句 后执行外面的查询语句- group by 语法的限制
出现在表达式中字段要么是分组的的字段,要么是被聚合函数包围应用的字段。
6.分组窗口函数
- row_number 不考虑数据重复性
- rank 考虑数据重复性 挤占标号
- dense_rank 考虑数据重复性 不挤占标号
- ntile 适用于只关心整体的某些部分数据 比如前三分之一 需要先分成三个部分 取第一部分
优先满足桶号较小的部分 并且保证前后桶的数据相差不会超过2
*统计每日最热门的页面top10*
- 数据表
- 分组字段:时间维度(day) day比较特殊还是表的分区字段 、页面维度(request)
- 度量值:count(*)-->top10
- sql
select t.request,count(*) as pv from dw_weblog_detail t where t.datestr="20181101" group by t.request having t.request is not null order by pvs desc limit 10;
按照时间维度来统计独立访客及其产生的pv量(按照小时)
- 数据表
- 分组字段时间维度(hour) ,访客维度(remote_addr)
- 度量值count()
- sql
select t.hour, t.remote_addr,count(*)as pv from dw_weblog_detail t where t.datestr="20181101" group by t.hour , t.remote_addr order by t.hour ,pv desc
每天新老访客
--今天 (根据今天收集的数据进行去重统计)
select
distinct t.remote_addr as ip
from dw_weblog_detail t where t.datestr="20181101";
--历史
create table dw_user_dsct_history(
day string,
ip string
)
partitioned by(datestr string);
--框架
select
今天.ip
from 今天 left join 历史 on 今天.ip = 历史.ip
where 历史.ip is null;--新访客
select
今天.ip
from 今天 left join 历史 on 今天.ip = 历史.ip
where 历史.ip is not null;--老访客
查询今日所有回头访客以及次数,和单次访客
访问次数大于一就叫回头访客
- 数据表
- 分组字段:时间维度(day)是分区字段 where
- 度量值count(session)
- sql
--先计算每个用户产生的会话数 select t.remote_addr,count(t.session) as num from ods_click_stream_visit t where t.datestr="20181101" group by t.remote_addr; --方式一 采用嵌套查询的思路 select from( select from ods_click_stream_visit t where t.datestr="20181101" group by t.remote_addr) a where a.nums=1; --单次访客 select from( select from ods_click_stream_visit t where t.datestr="20181101" group by t.remote_addr) a where a.nums > 1; --回头访客 --方式二:采用having select t.remote_addr,count(t.session) as num from ods_click_stream_visit t where t.datestr="20181101" group by t.remote_addr having nums >1 --回头访客;
hive中的join总结 :
- join 语句最重要的是确定join的表和join字段
- 因为join的表可能是真实存在 也可能不存在
- 如果不存在 设法通过嵌套查询生成表结构 实质是一个虚拟表
- 如果实际到需求中的两元操作(好或者不好 来或者不来 新和旧) 都可以在join上进行扩展 因为join的结果本身也就是两种情况(null,not null)
7.数据导出
全量,增量
全量数据:所有的数据全部的数据
增量数据:从上次开始到当下中间新增的数据
1.全量数据的导出
hive-->hdfs
insert overwrite directory '/weblog/export/dw_pvs_referer_everyhour' row format delimited fields terminated by ',' STORED AS textfile select referer_url,hour,pv_referer_cnt from dw_pvs_referer_everyhour where datestr = "20181101";hdfs----->mysql
bin/sqoop export \
--connect jdbc:mysql://node03:3306/weblog \
--username root --password 123456 \
--table dw_pvs_referer_everyhour \
--fields-terminated-by '\001' \
--columns referer_url,hour,pv_referer_cnt \
--export-dir /weblog/export/dw_pvs_referer_everyhour2.增量数据导出
hdfs----->mysql
bin/sqoop export \
--connect jdbc:mysql://node03:3306/weblog \
--username root \
--password 123456 \
--table dw_webflow_basic_info \
--fields-terminated-by '\001' \
--update-key monthstr,daystr \
--update-mode allowinsert \
--export-dir /user/hive/warehouse/itheima.db/dw_webflow_basic_info/datestr=20181103/3.定时增量导出的导出
手动导入增量数据方法
insert into table dw_webflow_basic_info partition(datestr="20181104") values("201811","04",10137,1129,1129,103);
shell脚本定时增量导入
- 导出数据的时间最好不要写死 可以通过传参或者命令方式自动获取时间
- 参数属性值不要写死 集中定义变量 后续方便集中管理
- 配合定时调度工具完成周期性定时调度:linux contab 或者azkaban ooize
#!/bin/bash
export SQOOP_HOME=/export/servers/sqoop
if [ $# -eq 1 ]
then
execute_date=`date --date="${1}" +%Y%m%d`
else
execute_date=`date -d'-1 day' +%Y%m%d`
fi
echo "execute_date:"${execute_date}
table_name="dw_webflow_basic_info"
hdfs_dir=/user/hive/warehouse/itheima.db/dw_webflow_basic_info/datestr=${execute_date}
mysql_db_pwd=123456
mysql_db_name=root
echo 'sqoop start'
$SQOOP_HOME/bin/sqoop export \
--connect "jdbc:mysql://node03:3306/weblog" \
--username $mysql_db_name \
--password $mysql_db_pwd \
--table $table_name \
--fields-terminated-by '\001' \
--update-key monthstr,daystr \
--update-mode allowinsert \
--export-dir $hdfs_dir
echo 'sqoop end'
4.工作流调度
业务目标完成会包含各个不同的步骤 步骤之间或者步骤内部往往存在依赖关系,甚至需要周期性重复性执行,这时候就需要设定工作流 知道工作按照设定的流程进行
- 简单工作流可以使用linux crontab
- 复杂工作流 自己开发软件或者使用开源的azkaban
预处理模块的任务调度
- 把预处理阶段的3个mr程序打成可以执行的jar包
注意使用maven插件 需要指定吗main class 里面的输入输出路径不要写死 - 配置azkaban的job信息
- 把azkaban配置及其依赖资源打成一个zip压缩包
- 在azkaban的web页面创建工程,上传压缩包
- 在azkaban上可以进行两种选择:1.立即执行,2.配置定时调度
数据入库的调度
shell脚本编写
- 导入shell需要软件的环境变量
- 集中定义时间 目录 属性 等常量变量
- 程序主题结合流程控制编写
如何使用azkaban调度hive
- hive -e sql语句
- hive -f sql语句
数据可视化
-
何谓数据可视化
又称之为数据报表展示,属于数据应用中的一种,尽量使用图形表格的形式把分析的结果展示给被人看。
数据可视化的大量工作属于前端开发 我们需要掌握的是如何把数据分析处理 已经把数据按照要求传递给可视化的软件。
数据可视化是一种锦上添花的事。核心还是数据分析的过程。
-
echarts简单入门
-
在页面上引入echarts.js
-
在页面创建一个dom容器 有高有宽的范围
-
选择容器使用echarts api创建echarts 实例
var myChart = echarts.init(document.getElementById('main')); -
根据业务需求去echarts官网寻找对应的图形样式 复制其option
var option = { title: { text: 'ECharts 入门示例' }, tooltip: {}, legend: { data:['销量'] }, xAxis: { data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"] }, yAxis: {}, series: [{ name: '销量', type: 'bar', data: [5, 20, 36, 10, 10, 20] }] }; -
把option设置到创建的echarts 实例中
// 使用刚指定的配置项和数据显示图表。 myChart.setOption(option);
对我们来说需要思考如何把数据从后端动态加载返回至前端页面进行可视化展示。
-
-
数据可视化后端web工程
职责:把导出在mysql中的数据按照前端需要的格式查询返回给前端
技术: php java 本项目使用javaEE 基于SSm做数据查询 -
mybatis逆向工程
可以根据对应的数据库表你想生成与之对应的javabean mapper sql
最重要的是提供了一个所谓的example类 该类用于条件封装 满足与sql的增删改查操作
当业务简单 不实际多表操作的时候 可以直接使用逆向工程 是的dao层代码量降为零。