AAAI 2024优秀论文汇总!包含图神经网络、多模态、时间序列等热门方向
AAAI人工智能会议在AI领域极具声望,第38届AAAI人工智能年度会议即将在2024年2月于加拿大的温哥华举办,这个会议汇集了全球最顶尖的研究者,探讨各种前沿话题。
今天就给大家整理了13篇AAAI 2024优秀论文,包含了图神经网络、多模态、时间序列等热门方向,这些研究不仅展示了AI领域的最新成果,还指出了未来的研究方向,让我们一起来看看这些论文吧!
图神经网络
1、Fine-tuning Graph Neural Networks by Preserving Graph Generative Patterns
通过保留图生成模式对图神经网络进行微调
简述:本文提出了G-Tuning方法,用于调整预训练的GNN以保留下游图的生成模式。通过利用图子基的线性组合,有效地近似了图的生成模式,从而提高了模型在迁移学习实验中的性能,与现有算法相比,G-Tuning在域内和域外迁移学习实验中分别平均改进0.5%和2.6%。

2、Joint Learning Neuronal Skeleton and Brain Circuit Topology with Permutation Invariant Encoders for Neuron Classification
联合学习神经元骨架和脑回路拓扑结构与排列不变编码器进行神经元分类
简述:本文提出了NeuNet,一个结合神经元形态和拓扑信息的框架,它由骨架编码器、连接组编码器和读出层组成,骨架编码器通过一维卷积处理神经骨架点数据,连接组编码器使用图神经网络捕获神经回路拓扑信息,读出层融合上述信息并输出分类结果。研究人员从人脑皮层和果蝇大脑的VEM图像发布新数据集,实验证明模型精度分别为0.9169和0.9363。

多模态
3、Prompt-based Distribution Alignment for Unsupervised Domain Adaptation
基于提示的无监督域自适应分布对齐
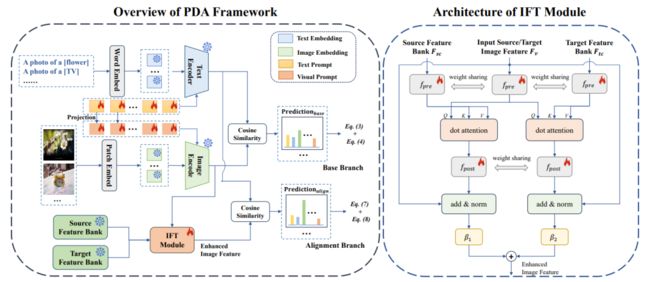
简述:本文提出了一种基于提示的分布对齐(PDA)方法,将领域知识纳入提示学习。PDA采用双分支范式,基分支确保类间差异,对齐分支通过构建特征库和图像引导特征调整(IFT)来最小化域差异。两分支相互促进,增强VLM的UDA适应性。实验证明PDA在三个基准上达到最先进性能。
4、MmAP : Multi-modal Alignment Prompt for Cross-domain Multi-task Learning
MmAP:跨域多任务学习的多模态对齐提示
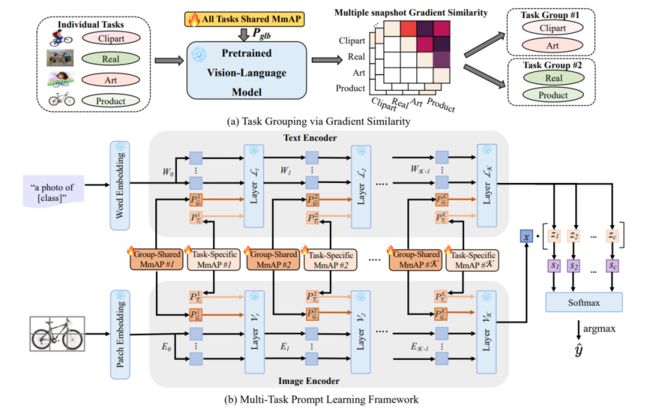
简述:本文提出了一种集成视觉语言模型CLIP的多任务学习框架,该模型具有强大的零样本泛化能力,并开发了多模态对齐提示(MmAP),研究人员在微调过程中对齐文本和视觉模态。通过任务分组和特定任务的MmAP,提高了高相似性任务的互补性,同时保留了每个任务的独特特征。实验表明,该方法在两个大型多任务学习数据集上实现了显著的性能改进,同时只使用了大约0.09%的可训练参数。
5、Structure-CLIP: Towards Scene Graph Knowledge to Enhance Multi-modal Structured Representations
Structure-CLIP:迈向场景图知识以增强多模态结构化表示
简述:本文提出了端到端框架Structure-CLIP,通过集成场景图知识增强多模态结构化表示。该框架使用场景图指导语义负例构建,并提出知识增强编码器利用场景图知识进一步增强结构化表示。实验表明,Structure-CLIP在VG-Attribution和VG-Relation数据集上取得最先进性能,并在MSCOCO上显著增强结构化表示能力。

时间序列
6、MSGNet: Learning Multi-Scale Inter-Series Correlations for Multivariate Time Series Forecasting
MSGNet:学习多变量时间序列预测的多尺度序列间相关性
简述:本文提出了MSGNet,一种深度学习模型,通过频域分析和自适应图卷积捕获多时间尺度下的序列相关性。模型结合自注意力机制和自适应混合跳图卷积层,以学习不同时间尺度内的相关性。实验证明其在多个真实世界数据集上的有效性,并展示了MSGNet的泛化能力和可解释性。

7、Fully-Connected Spatial-Temporal Graph for Multivariate Time Series Data
多变量时间序列数据的全连接时空图
简述:本文提出了一种名为全连接时空图神经网络(FC-STGNN)的新方法,能够解决现有方法无法捕获不同时间戳下的不同传感器(DEDT)之间的相关性的问题,它包括FC图构造和FC图卷积两个关键组件。通过设计衰减图模拟ST依赖关系,并使用移动池化GNN层捕获ST依赖性。通过大量实验,证明了FC-STGNN在多个MTS数据集上的有效性,并优于SOTA方法。

异常检测
8、VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
VadCLIP:调整视觉语言模型以进行弱监督视频异常检测
简述:本文提出了一种用于弱监督视频异常检测的新方法VadCLIP,它利用冻结的CLIP模型,无需预训练和微调。它通过双分支利用CLIP的视觉和语言关联,一个分支进行粗粒度分类,另一个分支进行细粒度语言-图像对齐。VadCLIP在XD-Violence和UCF-Crime基准上分别实现了84.51%的AP和88.02%的AUC,优于最先进的方法。

9、DiAD: A Diffusion-based Framework for Multi-class Anomaly Detection
DiAD:基于扩散的多类异常检测框架
简述:本文提出了DiAD,一个基于Difusion的多类异常检测框架。它包括像素空间AE、与扩散去噪网络相连的SG网络和预训练特征提取器。SG网络重建异常区域并保留语义信息,引入SFF块提高重建精度,预训练特征提取器处理输入和重建图像,生成异常图。实验在MVTec-AD和VisA数据集上证明了这个方法的有效性,超过了最先进的方法。

对比学习
10、TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning
TimesURL:用于通用时间序列表示学习的自监督对比学习
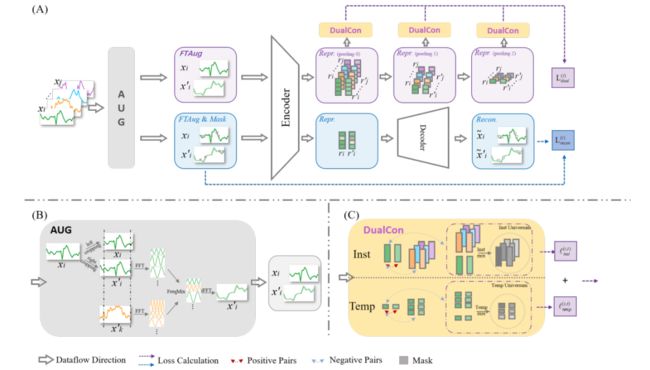
简述:本文提出了TimesURL,一种新型自监督框架,引入基于频率的时间增强以保持时间属性,构建双Universums作为硬负对,并引入时间重建和对比学习来捕获不同级别的信息。TimesURL可学习高质量通用表示,并在6个下游任务中实现最佳性能,包括短期和长期预测、插补、分类、异常检测和迁移学习。
11、Improving the Robustness of Knowledge-GroundedDialogue via Contrastive Learning
通过对比学习提高基于知识的对话的稳健性
简述:本文提出了一个基于实体的对比学习框架,用于增强KGD的鲁棒性,该框架利用实体信息创建正负样本,分别涉及语义无关和语义相关的扰动。实验在三个基准数据集上证明该方法有效,取得了新的先进性能,尤其在嘈杂和少样本设置中优于比较模型。

目标检测
12、Far3D: Expanding the Horizon for Surround-view 3D Object Detection
Far3D:扩大环视 3D 物体检测的视野
简述:本文提出了一种名为Far3D的新型框架,通过生成自适应的3D查询来增强3D全局查询,并引入透视感知聚合模块来捕获远距离物体的判别特征。Far3D还提出了一种3D去噪方法,以解决远程任务中的错误传播问题。在Argoverse 2和nuScenes数据集上,Far3D展示了最先进的性能,特别是在长距离和宽视野范围内。

13、Weakly Supervised Open-Vocabulary Object Detection
弱监督开放词汇对象检测
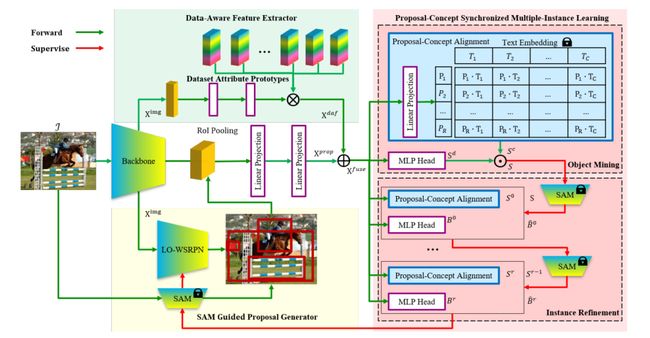
简述:本文提出了一种新的弱监督开放词汇目标检测框架WSOVOD,为了扩展传统的WSOD,以检测新概念并利用仅图像级注释的多样化数据集。为此,采用了三种策略:数据集级特征适应、图像级显著性对象定位和区域级视觉语言对齐。实验在Pascal VOC和MS COCO上表明,WSOVOD在近距离目标定位和检测任务中取得了新的进展,并支持跨数据集和开放词汇学习,性能与成熟的FSOVOD相当甚至更好。
码字不易,欢迎大家点赞评论收藏!
关注下方《享享学AI》
回复【AAAI2024】获取完整论文