【MySQL】简简单单速通mysql数据库
基础介绍
什么是数据库
储存数据用文件就可以了为啥还搞个数据库?
文件保存数据有以下几个缺点:
文件安全性问题
文件不利于数据查询和管理
文件不利于储存海量数据
文件在程序中控制不方便
数据库存储介质:
磁盘
内存
为了解决上述问题,专家们设计出更加利于管理数据的东西--数据库,他能更有效地管理数据。数据库的水平是衡量一个程序员水平的重要指标。
主流数据库
SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
基本使用
MySQL安装
Centos 6.5下编译安装MySQL 5.6.14
http://blog.51cto.com/aiilive/2119890
CentOS 7 通过 yum 安装 MariaDB
https://zhuanlan.zhihu.com/p/49046496
Windows下安装MySQL5.7
http://blog.51cto.com/aiilive/2116476
Windows下安装MySQL5.7
https://www.xjqyc.cn/database/mysql/1607.html
连接服务器
输入:
mysql -h 127.0.0.1 -p 3306 -u root -p
输出:
Enter password: ****
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.21-log MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
注意:
没有写-h 127.0.0.1默认是本地连接
没有写-p 3306默认是连接3306端口号
使用案例
创建数据库:create database hellworld;
使用数据库:use helloworld;
创建数据库表:create table student(id int,name varchar(32),gender varchaer(2));
表中插入数据:insert into student (id,name,gender) values (1,'张三','男');
查询表中的数据:select * from student;
库的操作
创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name说明:
大写表示的是关键字
[]是可选项
CHARACTER SET:指定数据库采用的字符集
COLLATE:指定数据库字符集的校验规则
创建数据库案例
创建名为db1的数据库:create database db1;
创建一个使用utf8字符集的db2数据库:create database db2 charset=utf8;
说明:当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_general_ci
创建一个使用utf8字符集的db2数据库:create database db2 charset=utf8;
创建一个使用utf字符集,并带校对规则的db3数据库:creater database db3 charset=utf8 collate utf8_general_ci;
字符集和校验规则
查看系统默认字符集以及校验规则
show variables like 'character_set_database';
show variables like 'collation_database';查看数据库支持的字符集
show charset;字符集主要控制用什么语言。比如utf8就可以使用中文。
查看数据库支持的字符集和校验规则
show collation;校验规则对数据库的影响
不区分大小写的话:
create database test1 collate utf8_general_ci;
use test1;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');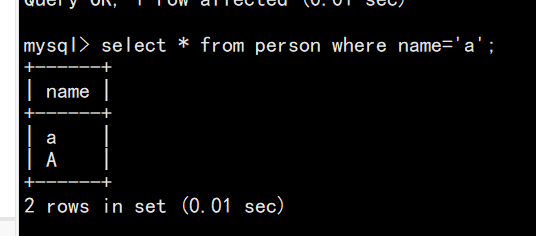

区分大小写:
create database test2 collate utf8_bin;
use test2;
create table person(name varchar(20));
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');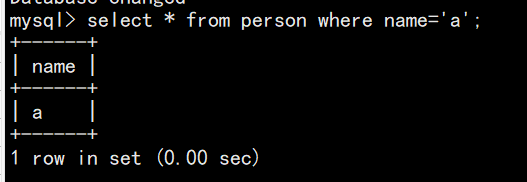
操纵数据库
查看数据库
show databases;
显示创建语句
show create database 数据库名;
示例:
mysql> show create database mytest;
+----------+----------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------+
| mysql | CREATE DATABASE `mytest` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+----------------------------------------------------------------+说明:
MySQL 建议我们关键字使用大写,但是不是必须的。
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
/*!40100 default.... */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
修改数据库
语法:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name说明:
对数据库修改主要指修改数据库的字符集,校验规则
实例:将mysql数据库字符集改成gbk
mysql> alter database mytest charset=gbk;
Query OK, 1 row affected (0.00 sec)
mysql> show create database mytest;
+----------+----------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------+
| mytest | CREATE DATABASE `mytest` /*!40100 DEFAULT CHARACTER SET gbk */ |
+----------+----------------------------------------------------------------+数据库删除
drop database [if exists] 数据库名;
执行删除之后的结果
数据库内部看不到对应的数据库
对应的数据库文件夹被删除,级联删除,里面的数据表全部被山
注意:不要随意删除数据库
备份和恢复
备份:
语法:
# mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
实例:
# mysqldump -P3306 -u root -p123456 -B mytest > D:/mytest.sql
这时,可以打开看看 mytest.sql 文件里的内容,其实把我们整个创建数据库,建表,导入数据的语句都装载这个文件中。
还原:
mysql> source D:/mysql-5.7.22/mytest.sql;
注意事项:
如果备份的不是整个数据库,而是其中的一张表,咋做
# mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
同时备份多个数据库
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原。
查看连接情况
语法:
show processliset
实例:
mysql> show processlist;
+----+------+-----------+------+---------+------+-------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+-------+------------------+
| 2 | root | localhost | test | Sleep | 1386 | | NULL |
| 3 | root | localhost | NULL | Query | 0 | NULL | show processlist |
+----+------+-----------+------+---------+------+-------+------------------+可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。
表的操作
创建表
语法:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;说明:
field表示列名
datatype表示列的类型
character set字符集,如果没有指定字符集,则以所在数据库的字符集为准
collate校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
创建表案例
create table users (
id int,
name varchar(20) comment '用户名',
password char(32) comment '密码是32位的md5值',
birthday date comment '生日'
) character set utf8 engine MyISAM;说明:
不同的存储引擎,创建表的文件不一样
users表存储引擎是myisam,在数据中有三个不同的文件,分别是
users.frm:表结构
users.MYD:表数据
users.MYI:表索引

备注:创建一个engine是innodb的数据库,观察存储目录
查看表结构
desc 表明;
修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
ALTER TABLE tablename ADD (column datatype [DEFAULT expr][,column datatype]...);
ALTER TABLE tablename MODIfy (column datatype [DEFAULT expr][,column datatype]...);
ALTER TABLE tablename DROP (column);案例:
在users表添加二条记录
mysql> insert into users values(1,'a','b','1982-01-04'),(2,'b','c','1984-01-04');
在users表添加以恶搞字段,用于保存图片路径
mysql> alter table users add assets varchar(100) comment '图片路径' after birthday;
插入新字段后,对原来表中的数据没有影响。
修改name,将其长度修改成60
mysql> alter table users modify name varchar(60);
删除password
mysql> alter table users drop password;
修改表名为employee
mysql> alter table users rename to employee;
将name列修改为xingming
mysql> alter table employee change name xingming varchar(60); --新字段需要完整定义
删除表
语法格式:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
示例:
drop table t1;
数据类型
数据类型分类
分类 |
数据类型 |
说明 |
数值类型 |
BIT(M) |
位类型。M指定位数,默认值是1,范围1-64 |
TINYINT[UNSIGNED] |
大夫好的范围-128~127,无符号范围0~255,默认是有符号的 |
|
BOOL |
使用0和1表示真和假 |
|
SMALLINT[UNSIGNED] |
带符号是-2^15次方到2^15-1,无符号是2^16-1 |
|
INT[UNSIGNED] |
带符号是-2^31次方到2^31-1,无符号是2^32-1 |
|
BIGINT[UNSIGNED] |
带符号是-2^63次方到2^63-1,无符号是2^64-1 |
|
FLOAT[(M,D)] [UNSIGNED] |
M指定显示长度,D指定小数位数,占用4字节 |
|
DOUBLE[(M,D)] [UNSIGNED] |
表示比float精度更大的小数,占用空间8字节 |
|
DECIMAL(M,D) [UNSIGNED] |
定点数M指定长度,D表示小数点的位数 |
|
文本、二进制类型 |
CHAR(SIZE) |
固定长度字符串,最大255 |
VARCHAR(SIZE) |
可变长度字符串,最大长度65535 |
|
BLOB |
二进制数据 |
|
TEXT |
大文本,不支持全文索引,不支持默认值 |
|
时间日期 |
DATE/DATETIME/TIMESTAMP |
日期类(yyyy-mm-dd)(yyyy-mm-dd hh:mm:ss)TIMESTAMP时间戳 |
String类型 |
ENUM类型 |
ENUM是一个字符串对象,其值来自表创建时在列规定中显示枚举的一列值 |
SET类型 |
SET是一个字符串对象,可以有零或多个值,其值来自表创建时规定的允许一列值。指定博爱阔多个set成员的set列值时各成员之间用逗号隔开。这样set成员值本身不能包含逗号。 |
数值类型
类型 |
字节 |
最小值 |
最大值 |
(带符号的/无符号的) |
(带符号的/无符号的) |
||
TINYINT |
1 |
-128 |
127 |
0 |
255 |
||
SMALLINT |
2 |
-32768 |
32767 |
0 |
65535 |
||
MEDIUMINT |
3 |
-8388608 |
8388607 |
0 |
16777215 |
||
INT |
4 |
-2147483648 |
2147483647 |
0 |
4294967295 |
||
BIGINT |
5 |
-9223372036854775808 |
9223372036854775807 |
0 |
18446744072709551615 |
TINYINT类型
数值越界测试:
mysql> create table tt1(num tinyint);
Query OK, 0 rows affected (0.02 sec)
mysql> insert into tt1 values(1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt1 values(128); -- 越界插入,报错
ERROR 1264 (22003): Out of range value for column 'num' at row 1
mysql> select * from tt1;
+------+
| num |
+------+
| 1 |
+------+
1 row in set (0.00 sec)说明:
在MySQL中,政协可以指定时有符号和无符号的,默认是有符号的;
可以同UNSIGNED类说明某个字段是无符号的;
无符号案例:
mysql> create table tt2(num tinyint unsigned);
mysql> insert into tt2 values(-1); -- 无符号,范围是: 0 - 255
ERROR 1264 (22003): Out of range value for column 'num' at row 1
mysql> insert into tt2 values(255);
Query OK, 1 row affected (0.02 sec)
mysql> select * from tt2;
+------+
| num |
+------+
| 255 |
+------+
1 row in set (0.00 sec)其他类型自己推导
注意:尽量不要使用unsigned,对于int类型可能存放不下的数据,int usigned同样可能村放不下,与其如此,还不如设计时,将int类型提升为bigint。
BIT类型
基本语法:
bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
举例:
mysql> create table tt4 ( id int, a bit(8));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into tt4 values(10, 10);
Query OK, 1 row affected (0.01 sec)
mysql> select * from tt4; #发现很怪异的现象,a的数据10没有出现
+------+------+
| id | a |
+------+------+
| 10 | |
+------+------+
1 row in set (0.00 sec)bit的使用注意事项:
bit字段在显示时,是按照ASCII码对应的值显示
mysql> insert into tt4 values(65, 65);
mysql> select * from tt4;
+------+------+
| id | a |
+------+------+
| 10 | |
| 65 | A |
+------+------+如果我们有这样的值,只能存放0或1,这样可以定义bit(1)也可以节省空间
mysql> create table tt5(gender bit(1));
mysql> insert into tt5 values(0);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt5 values(1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt5 values(2); -- 当插入2时,已经越界了
ERROR 1406 (22001): Data too long for column 'gender' at row 1小数类型
float
语法:
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节
案例:
小数:float(4,2)表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。
mysql> create table tt6(id int, salary float(4,2));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into tt6 values(100, -99.99);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt6 values(101, -99.991); #多的这一点被拿掉了
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt6;
+------+--------+
| id | salary |
+------+--------+
| 100 | -99.99 |
| 101 | -99.99 |
+------+--------+
2 rows in set (0.00 sec)案例:
如果定义的是float(4,2) unsigned 这时,因为把它指定为无符号的数,范围是 0 ~ 99.99
mysql> create table tt7(id int, salary float(4,2) unsigned);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into tt7 values(100, -0.1);
Query OK, 1 row affected, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+-------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------+
| Warning | 1264 | Out of range value for column 'salary' at row 1 |
+---------+------+-------------------------------------------------+
1 row in set (0.00 sec)
mysql> insert into tt7 values(100, -0);
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt7 values(100, 99.99);
Query OK, 1 row affected (0.00 sec)decimal
语法:
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
decimal(5,2)表示的范围是-999.99~999.99
decimal(5,2)unsigned表示的范围是0~999.99
decimal和float很像,但是有区别:
float和decimal表示的精度不一样
mysql> create table tt8 ( id int, salary float(10,8), salary2 decimal(10,8));
mysql> insert into tt8 values(100,23.12345612, 23.12345612);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt8;
+------+-------------+-------------+
| id | salary | salary2 |
+------+-------------+-------------+
| 100 | 23.12345695 | 23.12345612 | # 发现decimal的精度更准确,因此如果我们希望某个数据表示高精度,选择decimal
+------+-------------+-------------+说明:float的精度大约是7位
demical整数最大位数m为64。支持小数最大位数d是30.如果d被省略,默认为0。如果m被省略,默认为10。
建议:如果希望小鼠的精度高,推荐使用decimal。
字符串类型
char
语法:
char(L):固定长度字符串,L是可以存储的长度,单位为字符,最大长度可以为255
案例(char):
mysql> create table tt9(id int, name char(2));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into tt9 values(100, 'ab');
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt9 values(101, '中国');
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt9;
+------+--------+
| id | name |
+------+--------+
| 100 | ab |
| 101 | 中国 |
+------+--------+说明:
char(2)表示可以存放俩字符,可以是字母或者汉字,但是不能超过两个,最多设置255。
mysql> create table tt10(id int ,name char(256));
ERROR 1074 (42000): Column length too big for column 'name' (max = 255); use BLOB or TEXT insteadvarchar
语法:
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
案例:
mysql> create table tt10(id int ,name varchar(6)); --表示这里可以存放6个字符
mysql> insert into tt10 values(100, 'hello');
mysql> insert into tt10 values(100, '我爱你,中国');
mysql> select * from tt10;
+------+--------------------+
| id | name |
+------+--------------------+
| 100 | hello |
| 100 | 我爱你,中国 |
+------+--------------------+说明:
关于varchar(len),len的长度到底是多大,这个len值,和表编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字节数是 65532。
当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844[因为utf中,一个字符占用3个字节],如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符占用2字节)。
mysql> create table tt11(name varchar(21845))charset=utf8; --验证了utf8确实是不能超过21844
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type,not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs
mysql> create table tt11(name varchar(21844)) charset=utf8;
Query OK, 0 rows affected (0.01 sec)char和varchar比较
实际存储 |
char(4) |
varchar(4) |
char占用字节 |
varchar占用字节 |
abcd |
abcd |
abcd |
4*3 |
4*3+1 |
A |
A |
A |
4*3 |
1*3+1 |
Abcde |
/ |
/ |
超过数据长度 |
超过数据长度 |
如何选择定长或者变长字符串?
如果数据长度都一样就用char
如果数据长度有变化就用varchar
定长的磁盘空间比较浪费,效率高
变长的磁盘空间比较节省,效率低
定长的意义是,直接开辟好对应空间
变长的意义是,在不超过自己定义范围的情况下,用多少,开辟多少
日期和时间类型
常用的日期有如下三个:
date:日期‘yyy-mm-dd’占用三个字节
datetime:时间日期格式‘yyy-mm-dd hh:mm:ss’表示范围从1000到9999,占用八字节
timestamp:时间戳,从1970年开始的yyy-mm-dd hh:mm:ss格式和datetime完全一样,占用四字节
案例:
//创建表
mysql> create table birthday (t1 date, t2 datetime, t3 timestamp);
Query OK, 0 rows affected (0.01 sec)
//插入数据:
mysql> insert into birthday(t1,t2) values('1997-7-1','2008-8-8 12:1:1'); --插入两种时间
Query OK, 1 row affected (0.00 sec)
mysql> select * from birthday;
+------------+---------------------+---------------------+
| t1 | t2 | t3 |
+------------+---------------------+---------------------+
| 1997-07-01 | 2008-08-08 12:01:01 | 2017-11-12 18:28:55 | --添加数据时,时间戳自动补上当前时间
+------------+---------------------+---------------------+
//更新数据:
mysql> update birthday set t1='2000-1-1';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from birthday;
+------------+---------------------+---------------------+
| t1 | t2 | t3 |
+------------+---------------------+---------------------+
| 2000-01-01 | 2008-08-08 12:01:01 | 2017-11-12 18:32:09 | -- 更新数据,时间戳会更新成当前时间
+------------+---------------------+---------------------+enum和set
语法
enum:枚举,“单选”类型;
enum('选项1','选项2','选项3',...);
该设定只是提供了若干个选项的值,最终的一个单元格中,实际只存储了其中一个值;而且出于效率考虑,这些值实际存储的是“数字”,因为这些选项的每个选项一次对应如下数字:1,2,3,...最多65535个;当我们添加枚举值时,也可以添加对应的数字编号。
set:集合,“多选”类型
set('选项1','选项2','选项3',...);
该设定只是提供了若干选项的值,最终一个单元格中,设计可存储其中任意多个值;而且处于效率考虑,这些值实际存储的是数组,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,...最多64个。
说明:不建议在添加枚举值,集合值的时候采取数字的方式,不利于阅读。
案例:
mysql> create table votes(
-> username varchar(30),
-> hobby set('登山','游泳','篮球','武术'), --注意:使用数字标识每个爱好的时候,想想Linux权限,采用比特位位置来个set中的爱好对应起来
-> gender enum('男','女')); --注意:使用数字标识的时候,就是正常的数组下标
Query OK, 0 rows affected (0.02 sec)插入数据:
insert into votes values('雷锋', '登山,武术', '男');
insert into votes values('Juse','登山,武术',2);
select * from votes where gender=2;
+----------+---------------+--------+
| username | hobby | gender |
+----------+---------------+--------+
| Juse | 登山,武术 |女 |
+----------+---------------+--------+有如下数据:查找所有喜欢登山的人:
+-----------+---------------+--------+
| username | hobby | gender |
+-----------+---------------+--------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
| LiLei | 篮球 | 男 |
| HanMeiMei | 游泳 | 女 |
+-----------+---------------+--------+使用如下查询语句:
mysql> select * from votes where hobby='登山';
+----------+--------+--------+
| username | hobby | gender |
+----------+--------+--------+
| LiLei | 登山 | 男 |
+----------+--------+--------+不能擦汗寻出所有爱好为登山的人;
集合查询使用函数find_in_set函数;
find_in_set(sub,str_list):如果sub在str_list中,则返回下标;不在返回0;str_list用逗号分隔的字符串。
mysql> select find_in_set('a', 'a,b,c');
+---------------------------+
| find_in_set('a', 'a,b,c') |
+---------------------------+
| 1 |
+---------------------------+
mysql> select find_in_set('d', 'a,b,c');
+---------------------------+
| find_in_set('d', 'a,b,c') |
+---------------------------+
| 0 |
+---------------------------+查询爱好登山的人:
mysql> select * from votes where find_in_set('登山', hobby);
+----------+---------------+--------+
| username | hobby | gender |
+----------+---------------+--------+
| 雷锋 | 登山,武术 | 男 |
| Juse | 登山,武术 | 女 |
| LiLei | 登山 | 男 |
+----------+---------------+--------+表的约束
空属性
两个值:null(默认的)和not null(不为空)
数据库默认字段基本都是字段为空,但是实际开发时,尽可能保证字段不为空,因为数据为空没办法参与运算。
mysql> select null;
+------+
| NULL |
+------+
| NULL |
+------+
1 row in set (0.00 sec)
mysql> select 1+null;
+--------+
| 1+null |
+--------+
| NULL |
+--------+
1 row in set (0.00 sec)案例:
创建一个班级表,包含班级名和班级所在的教室。
站在正常的业务逻辑中:
如果班级没有名字,你不知道你在哪个班级
如果教室名字可以为空,就不知道在哪上课
所以我们在设计数据库表的时候,一定要在表中进行限制,满足上面条件的数据就不能插入到表中。这就是“约束”。
mysql> create table myclass(
-> class_name varchar(20) not null,
-> class_room varchar(10) not null);
Query OK, 0 rows affected (0.02 sec)
mysql> desc myclass;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| class_name | varchar(20) | NO | | NULL | |
| class_room | varchar(10) | NO | | NULL | |
+------------+-------------+------+-----+---------+-------+
//插入数据时,没有给教室数据插入失败:
mysql> insert into myclass(class_name) values('class1');
ERROR 1364 (HY000): Field 'class_room' doesn't have a default value默认值
默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候,用户可以选择性的使用默认值。
mysql> create table tt10 (
-> name varchar(20) not null,
-> age tinyint unsigned default 0,
-> sex char(2) default '男'
-> );
Query OK, 0 rows affected (0.00 sec)
mysql> desc tt10;
+-------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------------------+------+-----+---------+-------+
| name | varchar(20) | NO | | NULL | |
| age | tinyint(3) unsigned | YES | | 0 | |
| sex | char(2) | YES | | 男 | |
+-------+---------------------+------+-----+---------+-------+默认值的生效:数据在插入的时候不给该字段赋值,就使用默认值
mysql> insert into tt10(name) values('zhangsan');
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt10;
+----------+------+------+
| name | age | sex |
+----------+------+------+
| zhangsan | 0 | 男 |
+----------+------+------+
--注意:只有设置了default的列,才可以在插入值的时候,对列进行省略列描述
列描述:comment,没有实际含义,专门用来描述字段,会根据表创建语句保存,用来给程序员或DBA来进行了解。
mysql> create table tt12 (
-> name varchar(20) not null comment '姓名',
-> age tinyint unsigned default 0 comment '年龄',
-> sex char(2) default '男' comment '性别'
-> );
--注意:not null和defalut一般不需要同时出现,因为default本身有默认值,不会为空通过desc查看不到注释信息
mysql> desc tt12;
+-------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------------------+------+-----+---------+-------+
| name | varchar(20) | NO | | NULL | |
| age | tinyint(3) unsigned | YES | | 0 | |
| sex | char(2) | YES | | 男 | |
+-------+---------------------+------+-----+---------+-------+show可以
mysql> show create table tt12\G
*************************** 1. row ***************************
Table: tt12
Create Table: CREATE TABLE `tt12` (
`name` varchar(20) NOT NULL COMMENT '姓名',
`age` tinyint(3) unsigned DEFAULT '0' COMMENT '年龄',
`sex` char(2) DEFAULT '男' COMMENT '性别'
) ENGINE=MyISAM DEFAULT CHARSET=gbk
1 row in set (0.00 sec)zerofill
刚开始学习数据库时,很多人对数字类型后面的长度很迷茫。通过show看看tt3表的建表语句:
mysql> show create table tt3\G
***************** 1. row *****************
Table: tt3
Create Table: CREATE TABLE `tt3` (
`a` int(10) unsigned DEFAULT NULL,
`b` int(10) unsigned DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=gbk
1 row in set (0.00 sec)
可以看到int(10),这个代表什么意思呢?整型不是4字节码?这个10又代表什么呢?其实没有zerofill这个属性,括号内的数字是毫无意义的。a和b列就是前面插入的数据,如下:
mysql> insert into tt3 values(1,2);
Query OK, 1 row affected (0.00 sec)
mysql> select * from tt3;
+------+------+
| a | b |
+------+------+
| 1 | 2 |
+------+------+但是对列添加了zerofill属性后,显示的结果就有所不同了。修改tt3表的属性:
mysql> alter table tt3 change a a int(5) unsigned zerofill;
mysql> show create table tt3\G
*************************** 1. row ***************************
Table: tt3
Create Table: CREATE TABLE `tt3` (
`a` int(5) unsigned zerofill DEFAULT NULL, --具有了zerofill
`b` int(10) unsigned DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=gbk
1 row in set (0.00 sec)对a列添加了zerofill属性,再进行查找,返回如下结果:
mysql> select * from tt3;
+-------+------+
| a | b |
+-------+------+
| 00001 | 2 |
+-------+------+这次可以看到a的值由原来的1变成00001,这就是zerofill属性的作用,如果宽度小于设定的宽度(这里设置的是5),自动填充0。要注意的是,这只是最后显示的结果,在MySQL中实际存储的还是1。为什么是这样呢?我们可以用hex函数来证明。
mysql> select a, hex(a) from tt3;
+-------+--------+
| a | hex(a) |
+-------+--------+
| 00001 | 1 |
+-------+--------+可以看出数据库内部存储的还是1,00001只是设置了zerofill属性后的一种格式化输出而已。
主键
主键:primary key用来唯一的约束该字段里面的数据,不能重复,不能为空,一张表中最多只能有一个主键;主键所在的列通常是整数类型。
案例:
创建表的时候直接在字段上指定主键
mysql> create table tt13 (
-> id int unsigned primary key comment '学号不能为空',
-> name varchar(20) not null);
Query OK, 0 rows affected (0.00 sec)
mysql> desc tt13;
+-------+------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+-------+
| id | int(10) unsigned | NO | PRI | NULL | | <= key 中 pri表示该字段是主键
| name | varchar(20) | NO | | NULL | |
+-------+------------------+------+-----+---------+-------+主键约束:主键对应的字段中不能重复,一旦重复,操作失败。
mysql> insert into tt13 values(1, 'aaa');
Query OK, 1 row affected (0.00 sec)
mysql> insert into tt13 values(1, 'aaa');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'当表创建好以后但是没有主键的时候,可以再次追加主键
alter table 表名 add primary key(字段列表)删除主键
alter table 表名 drop primary key;mysql> alter table tt13 drop primary key;
mysql> desc tt13;
+-------+------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+-------+
| id | int(10) unsigned | NO | | NULL | |
| name | varchar(20) | NO | | NULL | |
+-------+------------------+------+-----+---------+-------+
复合主键
在创建表的时候,在所有字段之后,使用primary key(主键字段列表)来创建主键,如果有多个字段作为主键,可以使用复合主键。
mysql> create table tt14(
-> id int unsigned,
-> course char(10) comment '课程代码',
-> score tinyint unsigned default 60 comment '成绩',
-> primary key(id, course) -- id和course为复合主键
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> desc tt14;
+--------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+-------+
| id | int(10) unsigned | NO | PRI | 0 | | <= 这两列合成主键
| course | char(10) | NO | PRI | | |
| score | tinyint(3) unsigned | YES | | 60 | |
+--------+---------------------+------+-----+---------+-------+
mysql> insert into tt14 (id,course)values(1, '123');
Query OK, 1 row affected (0.02 sec)
mysql> insert into tt14 (id,course)values(1, '123');
ERROR 1062 (23000): Duplicate entry '1-123' for key 'PRIMARY' -- 主键冲突自增长
auto_increment:当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值+1操作,得到一个新的不同的值。通常和主键搭配使用,作为逻辑主键。
自增长的特点:
任何一个字段要做自增长,前提是本身是一个索引(key一栏有值)
自增长字段必须是整数
一张表最多只能有一个自增长
案例:
mysql> create table tt21(
-> id int unsigned primary key auto_increment,
-> name varchar(10) not null default ' ');
mysql> insert into tt21(name) values('a');
mysql> insert into tt21(name) values('b');
mysql> select * from tt21;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
+----+------+在插入后获取上次插入的 AUTO_INCREMENT 的值(批量插入获取的是第一个值)
mysql > select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 1 |
+------------------+索引:
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
唯一键
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以解决表中有多 个字段需要唯一性约束的问题。
唯一键的本质和主键差不多,唯一键允许为空,而且可以多个为空,空字段不做唯一性比较。
关于唯一键和主键的区别:
我们可以简单理解成,主键更多的是标识唯一性的。而唯一键更多的是保证在业务上,不要和别的信息出现重复。乍 一听好像没啥区别,我们举一个例子
假设一个场景(当然,具体可能并不是这样,仅仅为了帮助大家理解)比如在公司,我们需要一个员工管理系统,系统中有一个员工表,员工表中有两列信息,一个身份证号码,一个是员工工号,我们可以选择身份号码作为主键。
而我们设计员工工号的时候,需要一种约束:而所有的员工工号都不能重复。
具体指的是在公司的业务上不能重复,我们设计表的时候,需要这个约束,那么就可以将员工工号设计成为唯一键。
一般而言,我们建议将主键设计成为和当前业务无关的字段,这样,当业务调整的时候,我们可以尽量不会对主键做过大的调整。
案例:
mysql> create table student (
-> id char(10) unique comment '学号,不能重复,但可以为空',
-> name varchar(10)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(id, name) values('01', 'aaa');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student(id, name) values('01', 'bbb'); --唯一约束不能重复
ERROR 1062 (23000): Duplicate entry '01' for key 'id'
mysql> insert into student(id, name) values(null, 'bbb'); -- 但可以为空
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| 01 | aaa |
| NULL | bbb |
+------+------+外键
外键用于定义主表和从表之间的关系:外键约束主要定义在从表上,主表则必须是有主键约束或unique约束。当定义外键后,要求外键列数据必须在主表的主键列存在或为null。
语法:
foreign key (字段名) references 主表(列)
案例:
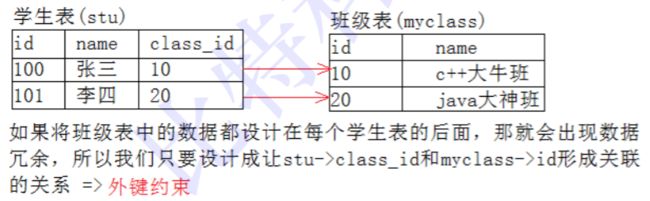
对上面的示意图进行设计:
先创建主键表
create table myclass (
id int primary key,
name varchar(30) not null comment'班级名'
);再创建从表
create table stu (
id int primary key,
name varchar(30) not null comment '学生名',
class_id int,
foreign key (class_id) references myclass(id)
);正常插入数据
mysql> insert into myclass values(10, 'C++大牛班'),(20, 'java大神班');
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into stu values(100, '张三', 10),(101, '李四',20);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0插入一个班级号为30的学生,因为没有这个班级,所以插入不成功
mysql> insert into stu values(102, 'wangwu',30);
ERROR 1452 (23000): Cannot add or update a child row:
a foreign key constraint fails (mytest.stu, CONSTRAINT stu_ibfk_1
FOREIGN KEY (class_id) REFERENCES myclass (id))插入班级id为null,比如来了一个学生,目前还没有分配班级
mysql> insert into stu values(102, 'wangwu', null);如何理解外键约束
首先我们承认,这个世界是数据很多都是相关性的。
理论上,上面的例子,我们不创建外键约束,就正常建立学生表,以及班级表,该有的字段我们都有。 此时,在实际使用的时候,可能会出现什么问题?
有没有可能插入的学生信息中有具体的班级,但是该班级却没有在班级表中?比如比特只开了比特100班,比特101班,但是在上课的学生里面竟然有比特102班的学生(这个班目前并不存在),这很明显是有问题的。
因为此时两张表在业务上是有相关性的,但是在业务上没有建立约束关系,那么就可能出现问题。
解决方案就是通过外键完成的。建立外键的本质其实就是把相关性交给mysql去审核了,提前告诉mysql表之间的约束关系,那么当用户插入不符合业务逻辑的数据的时候,mysql不允许你插入。
综合案例
有一个商店的数据,记录客户及购物情况,有以下三个表组成:
商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供应商provider)
客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证card_id)
购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
要求:
每个表的主外键
客户的姓名不能为空值
邮箱不能重复
客户的性别(男,女)
-- 创建数据库
create database if not exists bit32mall default character set utf8 ;
-- 选择数据库
use bit32mall;
-- 创建数据库表:
-- 商品
create table if not exists goods
(
goods_id int primary key auto_increment comment '商品编号',
goods_name varchar(32) not null comment '商品名称',
unitprice int not null default 0 comment '单价,单位分',
category varchar(12) comment '商品分类',
provider varchar(64) not null comment '供应商名称'
);
-- 客户
create table if not exists customer
(
customer_id int primary key auto_increment comment '客户编号',
name varchar(32) not null comment '客户姓名',
address varchar(256) comment '客户地址',
email varchar(64) unique key comment '电子邮箱',
sex enum('男','女') not null comment '性别',
card_id char(18) unique key comment '身份证'
);
-- 购买
create table if not exists purchase
(
order_id int primary key auto_increment comment '订单号',
customer_id int comment '客户编号',
goods_id int comment '商品编号',
nums int default 0 comment '购买数量',
foreign key (customer_id) references customer(customer_id),
foreign key (goods_id) references goods(goods_id)
);基本查询:表的增删查改
CRUD:Create创建、Retrieve读取、Update更新、Delete删除
Create
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...案例:
-- 创建一张学生表
CREATE TABLE students (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
sn INT NOT NULL UNIQUE COMMENT '学号',
name VARCHAR(20) NOT NULL,
qq VARCHAR(20)
);单行数据+全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
-- 注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认
的值进行自增。
INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);
Query OK, 1 row affected (0.02 sec)
INSERT INTO students VALUES (101, 10001, '孙悟空', '11111');
Query OK, 1 row affected (0.02 sec)
-- 查看插入结果
SELECT * FROM students;
+-----+-------+-----------+-------+
| id | sn | name | qq |
+-----+-------+-----------+-------+
| 100 | 10000 | 唐三藏 | NULL |
| 101 | 10001 | 孙悟空 | 11111 |
+-----+-------+-----------+-------+
2 rows in set (0.00 sec)多行数据+指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO students (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
Query OK, 2 rows affected (0.02 sec)
Records: 2 Duplicates: 0 Warnings: 0
-- 查看插入结果
SELECT * FROM students;
+-----+-------+-----------+-------+
| id | sn | name | qq |
+-----+-------+-----------+-------+
| 100 | 10000 | 唐三藏 | NULL |
| 101 | 10001 | 孙悟空 | 11111 |
| 102 | 20001 | 曹孟德 | NULL |
| 103 | 20002 | 孙仲谋 | NULL |
+-----+-------+-----------+-------+
4 rows in set (0.00 sec)插入否则更新
由于主键或者唯一键队医的值已经存在而导致失败
-- 主键冲突
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师');
ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY'
-- 唯一键冲突
INSERT INTO students (sn, name) VALUES (20001, '曹阿瞒');
ERROR 1062 (23000): Duplicate entry '20001' for key 'sn'可以选择性的进行同步更新操作语法
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')
ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';
Query OK, 2 rows affected (0.47 sec)
-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
-- 通过 MySQL 函数获取受到影响的数据行数
SELECT ROW_COUNT();
+-------------+
| ROW_COUNT() |
+-------------+
| 2 |
+-------------+
1 row in set (0.00 sec)
-- ON DUPLICATE KEY 当发生重复key的时候替换
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入
REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');
Query OK, 2 rows affected (0.00 sec)
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入Retrieve
语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...案例:
-- 创建表结构
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
-- 插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0SELECT列
全列查询
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。(索引待后面课程讲解)
SELECT * FROM exam_result;
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+----+-----------+-------+--------+--------+
7 rows in set (0.00 sec)指定列查询
-- 指定列的顺序不需要按定义表的顺序来
SELECT id, name, english FROM exam_result;
+----+-----------+--------+
| id | name | english |
+----+-----------+--------+
| 1 | 唐三藏 | 56 |
| 2 | 孙悟空 | 77 |
| 3 | 猪悟能 | 90 |
| 4 | 曹孟德 | 67 |
| 5 | 刘玄德 | 45 |
| 6 | 孙权 | 78 |
| 7 | 宋公明 | 30 |
+----+-----------+--------+
7 rows in set (0.00 sec)查询字段为表达式
-- 表达式不包含字段
SELECT id, name, 10 FROM exam_result;
+----+-----------+----+
| id | name | 10 |
+----+-----------+----+
| 1 | 唐三藏 | 10 |
| 2 | 孙悟空 | 10 |
| 3 | 猪悟能 | 10 |
| 4 | 曹孟德 | 10 |
| 5 | 刘玄德 | 10 |
| 6 | 孙权 | 10 |
| 7 | 宋公明 | 10 |
+----+-----------+----+
7 rows in set (0.00 sec)-- 表达式包含一个字段
SELECT id, name, english + 10 FROM exam_result;
+----+-----------+-------------+
| id | name | english + 10 |
+----+-----------+-------------+
| 1 | 唐三藏 | 66 |
| 2 | 孙悟空 | 87 |
| 3 | 猪悟能 | 100 |
| 4 | 曹孟德 | 77 |
| 5 | 刘玄德 | 55 |
| 6 | 孙权 | 88 |
| 7 | 宋公明 | 40 |
+----+-----------+-------------+
7 rows in set (0.00 sec)-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result;
+----+-----------+-------------------------+
| id | name | chinese + math + english |
+----+-----------+-------------------------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+-------------------------+
7 rows in set (0.00 sec)
为查询结果指定别名
语法:
SELECT column [AS] alias_name [...] FROM table_name;SELECT id, name, chinese + math + english 总分 FROM exam_result;
+----+-----------+--------+
| id | name | 总分 |
+----+-----------+--------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+--------+
7 rows in set (0.00 sec)结果去重
-- 98 分重复了
SELECT math FROM exam_result;
+--------+
| math |
+--------+
| 98 |
| 78 |
| 98 |
| 84 |
| 85 |
| 73 |
| 65 |
+--------+
7 rows in set (0.00 sec)-- 去重结果
SELECT DISTINCT math FROM exam_result;
+--------+
| math |
+--------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+--------+
6 rows in set (0.00 sec)WHERE条件
比较运算符:
运算符 |
说明 |
>,>=,<,<= |
大于,大于等于,小于,小于等于 |
= |
等于,NULL不安全,例如NULL=NULL结果是NULL |
<=> |
等于,NULL安全,例如NULL<=>NULL结果是TRUE(1) |
!=,<> |
不等于 |
BETWEEN a0 AND a1 |
范围匹配,[a0,a1],如果a0<=value<=a1,返回TRUE(1) |
IN (option , ...) |
若果是option中的任意一个值,返回TURE(1) |
IS NULL |
是NULL |
IS NOT NULL |
不是NULL |
LIKE |
模糊匹配,%表示任意多个(包含0)任意字符;_表示任意一个字符 |
逻辑运算符:
预算符 |
说明 |
AND |
多个条件必须都为TRUE(1),结果才是TRUE(1) |
OR |
热议一个条件为TRUE(1),结果都是TRUE(1) |
NOT |
条件为TRUE(1),结果为FALSE(0) |
案例:
英语不及格的同学及英语成绩 ( < 60 )
-- 基本比较
SELECT name, english FROM exam_result WHERE english < 60;
+-----------+--------+
| name | english |
+-----------+--------+
| 唐三藏 | 56 |
| 刘玄德 | 45 |
| 宋公明 | 30 |
+-----------+--------+
3 rows in set (0.01 sec)语文成绩在 [80, 90] 分的同学及语文成绩
-- 使用 AND 进行条件连接
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;
+-----------+-------+
| name | chinese |
+-----------+-------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+-------+
3 rows in set (0.00 sec)-- 使用 BETWEEN ... AND ... 条件
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
+-----------+-------+
| name | chinese |
+-----------+-------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+-------+
3 rows in set (0.00 sec)数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
-- 使用 OR 进行条件连接
SELECT name, math FROM exam_result
WHERE math = 58
OR math = 59
OR math = 98
OR math = 99;
+-----------+--------+
| name | math |
+-----------+--------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+--------+
2 rows in set (0.01 sec)-- 使用 IN 条件
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
+-----------+--------+
| name | math |
+-----------+--------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+--------+
2 rows in set (0.00 sec)姓孙的同学 及 孙某同学
-- % 匹配任意多个(包括 0 个)任意字符
SELECT name FROM exam_result WHERE name LIKE '孙%';
+-----------+
| name |
+-----------+
| 孙悟空 |
| 孙权 |
+-----------+
2 rows in set (0.00 sec)-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';
+--------+
| name |
+--------+
| 孙权 |
+--------+
1 row in set (0.00 sec)语文成绩好于英语成绩的同学
-- WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
+-----------+-------+--------+
| name | chinese | english |
+-----------+-------+--------+
| 唐三藏 | 67 | 56 |
| 孙悟空 | 87 | 77 |
| 曹孟德 | 82 | 67 |
| 刘玄德 | 55 | 45 |
| 宋公明 | 75 | 30 |
+-----------+-------+--------+
5 rows in set (0.00 sec)
总分在200分以下的同学
-- WHERE 条件中使用表达式
-- 别名不能用在 WHERE 条件中
SELECT name, chinese + math + english 总分 FROM exam_result
WHERE chinese + math + english < 200;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+--------+
2 rows in set (0.00 sec)语文成绩 > 80 并且不姓孙的同学
-- AND 与 NOT 的使用
SELECT name, chinese FROM exam_result
WHERE chinese > 80 AND name NOT LIKE '孙%';
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
+----+-----------+-------+--------+--------+
2 rows in set (0.00 sec)孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
-- 综合性查询
SELECT name, chinese, math, english, chinese + math + english 总分
FROM exam_result
WHERE name LIKE '孙_' OR (
chinese + math + english > 200 AND chinese < math AND english > 80
);
+-----------+-------+--------+--------+--------+
| name | chinese | math | english | 总分 |
+-----------+-------+--------+--------+--------+
| 猪悟能 | 88 | 98 | 90 | 276 |
| 孙权 | 70 | 73 | 78 | 221 |
+-----------+-------+--------+--------+--------+
2 rows in set (0.00 sec)
NULL的查询
-- 查询 students 表
+-----+-------+-----------+-------+
| id | sn | name | qq |
+-----+-------+-----------+-------+
| 100 | 10010 | 唐大师 | NULL |
| 101 | 10001 | 孙悟空 | 11111 |
| 103 | 20002 | 孙仲谋 | NULL |
| 104 | 20001 | 曹阿瞒 | NULL |
+-----+-------+-----------+-------+
4 rows in set (0.00 sec)
-- 查询 qq 号已知的同学姓名
SELECT name, qq FROM students WHERE qq IS NOT NULL;
+-----------+-------+
| name | qq |
+-----------+-------+
| 孙悟空 | 11111 |
+-----------+-------+
1 row in set (0.00 sec)
-- NULL 和 NULL 的比较,= 和 <=> 的区别
SELECT NULL = NULL, NULL = 1, NULL = 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL = 0 |
+-------------+----------+----------+
| NULL | NULL | NULL |
+-------------+----------+----------+
1 row in set (0.00 sec)
SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
1 row in set (0.00 sec)结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];注意:没有ORDER BY子句的查询,返回顺序是未定义的,永远不要以来这个顺序
案例:
同学及数学成绩,按数学成绩升序显示
SELECT name, math FROM exam_result ORDER BY math;
+-----------+--------+
| name | math |
+-----------+--------+
| 宋公明 | 65 |
| 孙权 | 73 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+--------+
7 rows in set (0.00 sec)同学及 qq 号,按 qq 号排序显示
-- NULL 视为比任何值都小,升序出现在最上面
SELECT name, qq FROM students ORDER BY qq;
+-----------+-------+
| name | qq |
+-----------+-------+
| 唐大师 | NULL |
| 孙仲谋 | NULL |
| 曹阿瞒 | NULL |
| 孙悟空 | 11111 |
+-----------+-------+
4 rows in set (0.00 sec)-- NULL 视为比任何值都小,降序出现在最下面
SELECT name, qq FROM students ORDER BY qq DESC;
+-----------+-------+
| name | qq |
+-----------+-------+
| 孙悟空 | 11111 |
| 唐大师 | NULL |
| 孙仲谋 | NULL |
| 曹阿瞒 | NULL |
+-----------+-------+
4 rows in set (0.00 sec)查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
-- 多字段排序,排序优先级随书写顺序
SELECT name, math, english, chinese FROM exam_result
ORDER BY math DESC, english, chinese;
+-----------+--------+--------+-------+
| name | math | english | chinese |
+-----------+--------+--------+-------+
| 唐三藏 | 98 | 56 | 67 |
| 猪悟能 | 98 | 90 | 88 |
| 刘玄德 | 85 | 45 | 55 |
| 曹孟德 | 84 | 67 | 82 |
| 孙悟空 | 78 | 77 | 87 |
| 孙权 | 73 | 78 | 70 |
| 宋公明 | 65 | 30 | 75 |
+-----------+--------+--------+-------+
7 rows in set (0.00 sec)查询同学及总分,由高到低
-- ORDER BY 中可以使用表达式
SELECT name, chinese + english + math FROM exam_result
ORDER BY chinese + english + math DESC;
+-----------+-------------------------+
| name | chinese + english + math |
+-----------+-------------------------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+-------------------------+
7 rows in set (0.00 sec)-- ORDER BY 子句中可以使用列别名
SELECT name, chinese + english + math 总分 FROM exam_result
ORDER BY 总分 DESC;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+--------+
7 rows in set (0.00 sec)查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
-- 结合 WHERE 子句 和 ORDER BY 子句
SELECT name, math FROM exam_result
WHERE name LIKE '孙%' OR name LIKE '曹%'
ORDER BY math DESC;
+-----------+--------+
| name | math |
+-----------+--------+
| 曹孟德 | 84 |
| 孙悟空 | 78 |
| 孙权 | 73 |
+-----------+--------+
3 rows in set (0.00 sec)筛选分页的结果
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
-- 第 1 页
SELECT id, name, math, english, chinese FROM exam_result
ORDER BY id LIMIT 3 OFFSET 0;
+----+-----------+--------+--------+-------+
| id | name | math | english | chinese |
+----+-----------+--------+--------+-------+
| 1 | 唐三藏 | 98 | 56 | 67 |
| 2 | 孙悟空 | 78 | 77 | 87 |
| 3 | 猪悟能 | 98 | 90 | 88 |
+----+-----------+--------+--------+-------+
3 rows in set (0.02 sec)-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result
ORDER BY id LIMIT 3 OFFSET 3;
+----+-----------+--------+--------+-------+
| id | name | math | english | chinese |
+----+-----------+--------+--------+-------+
| 4 | 曹孟德 | 84 | 67 | 82 |
| 5 | 刘玄德 | 85 | 45 | 55 |
| 6 | 孙权 | 73 | 78 | 70 |
+----+-----------+--------+--------+-------+
3 rows in set (0.00 sec)
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result
ORDER BY id LIMIT 3 OFFSET 6;
+----+-----------+--------+--------+-------+
| id | name | math | english | chinese |
+----+-----------+--------+--------+-------+
| 7 | 宋公明 | 65 | 30 | 75 |
+----+-----------+--------+--------+-------+
1 row in set (0.00 sec)Update
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]对查询结果进行列值更新
案例:
将孙悟空同学的数学成绩变更为 80 分
-- 更新值为具体值
-- 查看原数据
SELECT name, math FROM exam_result WHERE name = '孙悟空';
+-----------+--------+
| name | math |
+-----------+--------+
| 孙悟空 | 78 |
+-----------+--------+
1 row in set (0.00 sec)
-- 数据更新
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 查看更新后数据
SELECT name, math FROM exam_result WHERE name = '孙悟空';
+-----------+--------+
| name | math |
+-----------+--------+
| 孙悟空 | 80 |
+-----------+--------+
1 row in set (0.00 sec)将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
-- 一次更新多个列
-- 查看原数据
SELECT name, math, chinese FROM exam_result WHERE name = '曹孟德';
+-----------+--------+-------+
| name | math | chinese |
+-----------+--------+-------+
| 曹孟德 | 84 | 82 |
+-----------+--------+-------+
1 row in set (0.00 sec)
-- 数据更新
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
Query OK, 1 row affected (0.14 sec)
Rows matched: 1 Changed: 1 Warnings: 0
-- 查看更新后数据
SELECT name, math, chinese FROM exam_result WHERE name = '曹孟德';
+-----------+--------+-------+
| name | math | chinese |
+-----------+--------+-------+
| 曹孟德 | 60 | 70 |
+-----------+--------+-------+
1 row in set (0.00 sec)将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
-- 更新值为原值基础上变更
-- 查看原数据
-- 别名可以在ORDER BY中使用
SELECT name, math, chinese + math + english 总分 FROM exam_result
ORDER BY 总分 LIMIT 3;
+-----------+--------+--------+
| name | math | 总分 |
+-----------+--------+--------+
| 宋公明 | 65 | 170 |
| 刘玄德 | 85 | 185 |
| 曹孟德 | 60 | 197 |
+-----------+--------+--------+
3 rows in set (0.00 sec)
-- 数据更新,不支持 math += 30 这种语法
UPDATE exam_result SET math = math + 30
ORDER BY chinese + math + english LIMIT 3;
-- 查看更新后数据
-- 思考:这里还可以按总分升序排序取前 3 个么?
SELECT name, math, chinese + math + english 总分 FROM exam_result
WHERE name IN ('宋公明', '刘玄德', '曹孟德');
+-----------+--------+--------+
| name | math | 总分 |
+-----------+--------+--------+
| 曹孟德 | 90 | 227 |
| 刘玄德 | 115 | 215 |
| 宋公明 | 95 | 200 |
+-----------+--------+--------+
3 rows in set (0.00 sec)
-- 按总成绩排序后查询结果
SELECT name, math, chinese + math + english 总分 FROM exam_result
ORDER BY 总分 LIMIT 3;
+-----------+--------+--------+
| name | math | 总分 |
+-----------+--------+--------+
| 宋公明 | 95 | 200 |
| 刘玄德 | 115 | 215 |
| 唐三藏 | 98 | 221 |
+-----------+--------+--------+
3 rows in set (0.00 sec将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用
-- 没有 WHERE 子句,则更新全表
-- 查看原数据
SELECT * FROM exam_result;
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 80 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 70 | 90 | 67 |
| 5 | 刘玄德 | 55 | 115 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 95 | 30 |
+----+-----------+-------+--------+--------+
7 rows in set (0.00 sec)
-- 数据更新
UPDATE exam_result SET chinese = chinese * 2;
Query OK, 7 rows affected (0.00 sec)
Rows matched: 7 Changed: 7 Warnings: 0
-- 查看更新后数据
SELECT * FROM exam_result;
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 2 | 孙悟空 | 174 | 80 | 77 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 90 | 67 |
| 5 | 刘玄德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
+----+-----------+-------+--------+--------+
7 rows in set (0.00 sec)Delete
删除数据
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]案例:
删除孙悟空同学的考试成绩
-- 查看原数据
SELECT * FROM exam_result WHERE name = '孙悟空';
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 2 | 孙悟空 | 174 | 80 | 77 |
+----+-----------+-------+--------+--------+
1 row in set (0.00 sec)
-- 删除数据
DELETE FROM exam_result WHERE name = '孙悟空';
Query OK, 1 row affected (0.17 sec)
-- 查看删除结果
SELECT * FROM exam_result WHERE name = '孙悟空';
Empty set (0.00 sec)删除整张表数据
注意:删除表操作要慎用
-- 准备测试表
CREATE TABLE for_delete (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
Query OK, 0 rows affected (0.16 sec)
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (1.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 查看测试数据
SELECT * FROM for_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)-- 删除整表数据
DELETE FROM for_delete;
Query OK, 3 rows affected (0.00 sec)
-- 查看删除结果
SELECT * FROM for_delete;
Empty set (0.00 sec)-- 再插入一条数据,自增 id 在原值上增长
INSERT INTO for_delete (name) VALUES ('D');
Query OK, 1 row affected (0.00 sec)
-- 查看数据
SELECT * FROM for_delete;
+----+------+
| id | name |
+----+------+
| 4 | D |
+----+------+
1 row in set (0.00 sec)
-- 查看表结构,会有 AUTO_INCREMENT=n 项
SHOW CREATE TABLE for_delete\G
*************************** 1. row ***************************
Table: for_delete
Create Table: CREATE TABLE `for_delete` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)截断表
语法:
TRUNCATE [TABLE] table_name注意:这个操作慎用
只能对整表操作,不能像 DELETE 一样针对部分数据操作;
实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚;
会重置 AUTO_INCREMENT 项。
-- 准备测试表
CREATE TABLE for_truncate (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
Query OK, 0 rows affected (0.16 sec)
-- 插入测试数据
INSERT INTO for_truncate (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (1.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 查看测试数据
SELECT * FROM for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)-- 截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
TRUNCATE for_truncate;
Query OK, 0 rows affected (0.10 sec)
-- 查看删除结果
SELECT * FROM for_truncate;
Empty set (0.00 sec)-- 再插入一条数据,自增 id 在重新增长
INSERT INTO for_truncate (name) VALUES ('D');
Query OK, 1 row affected (0.00 sec)
-- 查看数据
SELECT * FROM for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | D |
+----+------+
1 row in set (0.00 sec)
-- 查看表结构,会有 AUTO_INCREMENT=2 项
SHOW CREATE TABLE for_truncate\G
*************************** 1. row ***************************
Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...案例:删除表中的的重复复记录,重复的数据只能有一份
-- 创建原数据表
CREATE TABLE duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
-- 插入测试数据
INSERT INTO duplicate_table VALUES
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0思路:
-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
CREATE TABLE no_duplicate_table LIKE duplicate_table;
Query OK, 0 rows affected (0.00 sec)
-- 将 duplicate_table 的去重数据插入到 no_duplicate_table
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 通过重命名表,实现原子的去重操作
RENAME TABLE duplicate_table TO old_duplicate_table,
no_duplicate_table TO duplicate_table;
Query OK, 0 rows affected (0.00 sec)
-- 查看最终结果
SELECT * FROM duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec聚合函数
函数 |
说明 |
COUNT([DISTINCE]EXPR) |
返沪查询到数据的数量 |
SUM([DISTINCT]EXPR) |
返回查询到数据的总和,不是数字没有意义 |
AVG([DISTINCT]EXPR) |
返回查询到数据的平均值,不是数字没有意义 |
MAX([DISTINCT]EXPR) |
返回查询到数据的最大值,不是数字没有意义 |
MIN([DISTINCT]EXPR) |
返回查询到数据的最小值,不是数字没有意义 |
案例:
统计班级共有多少同学
-- 使用 * 做统计,不受 NULL 影响
SELECT COUNT(*) FROM students;
+----------+
| COUNT(*) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
-- 使用表达式做统计
SELECT COUNT(1) FROM students;
+----------+
| COUNT(1) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)统计班级收集的 qq 号有多少
-- NULL 不会计入结果
SELECT COUNT(qq) FROM students;
+-----------+
| COUNT(qq) |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)统计本次考试的数学成绩分数个数
-- COUNT(math) 统计的是全部成绩
SELECT COUNT(math) FROM exam_result;
+---------------+
| COUNT(math) |
+---------------+
| 6 |
+---------------+
1 row in set (0.00 sec)
-- COUNT(DISTINCT math) 统计的是去重成绩数量
SELECT COUNT(DISTINCT math) FROM exam_result;
+------------------------+
| COUNT(DISTINCT math) |
+------------------------+
| 5 |
+------------------------+
1 row in set (0.00 sec)统计数学成绩总分
SELECT SUM(math) FROM exam_result;
+-------------+
| SUM(math) |
+-------------+
| 569 |
+-------------+
1 row in set (0.00 sec)
-- 不及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;
+-------------+
| SUM(math) |
+-------------+
| NULL |
+-------------+
1 row in set (0.00 sec)
统计平均总分
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
+--------------+
| 平均总分 |
+--------------+
| 297.5 |
+--------------+返回英语最高分
SELECT MAX(english) FROM exam_result;
+-------------+
| MAX(english) |
+-------------+
| 90 |
+-------------+
1 row in set (0.00 sec)返回 > 70 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 70;
+-------------+
| MIN(math) |
+-------------+
| 73 |
+-------------+
1 row in set (0.00 sec)group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;案例:
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表) EMP员工表 DEPT部门表 SALGRADE工资等级表
如何显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from EMP group by deptno;显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from EMP group by deptno, job;显示平均工资低于2000的部门和它的平均工资
统计各个部门的平均工资
select avg(sal) from EMP group by deptnohaving和group by配合使用,对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;
--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。