来聊聊大厂常用的分布式ID生成方案
写在文章开头
随着数据日益增加,项目需要进行分库分表来分摊压力,为了保证数据ID唯一,必须有一套适配当前分库分表的分布式ID生成方案,而这套方案必须具备以下条件:
- 全局唯一:分布式ID必须全局唯一,确保数据可以被唯一确定。
- 高性能:高并发场景下分布式ID必须快速响应生成。
- 高并发:分库分表数据存储大概率会出现高并发量的请求,所以这套方案必须在高并发场景下快速生成id。
- 高可用: 需要无限接近百分百的可用,避免因为因为分布式ID生成影响其他业务运行。
- 易用:方案必须易于使用,不大量侵入业务代码。
- 递增:尽可能保证递增,确保ID有序插入以保证插入性能和索引维护开销。
所以本文就基于上述要求针对市面主流的几种分布式ID算法的特点和适用场景展开深入探讨:

你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:写代码的SharkChili,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。

常见算法
UUID
UUID有着全球唯一的特性,只需一行简单的代码,即可快速生成一个UUID:
public static void main(String[] args) {
log.info("uuid:{}", UUID.randomUUID());
}
输出结果:
uuid:9fea8ab3-0789-4719-aa70-8849cbc59916
符合全局唯一、高性能、高并发、高可用、易用的特性。但是它却有以下缺点:
- 字符串类型:因为是字符类型,占用大量存储空间。
- 无序:因为生成的无规律,因为大量的随机添加势必导致MySQL底层大量的B+ tree的节点分裂,耗费大量计算资源,严重影响数据库性能,进而导致查询耗时增加。
所以UUID虽在性能、唯一性、可用性上有着保证,但其生成结果会加剧数据库的负担,所以不是很推荐用作分布式ID。
数据库主键自增
我们也可以专门使用一张数据表生成唯一自增的id,通过数据库auto_increment特性自增i唯一且有序的分布式ID:
CREATE TABLE id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
);
这种做法优点就是实现简单且单调递增,ID也是数值类型,所以查询速度很快,但它也有以下缺点:
- 单点性能瓶颈:所有的ID都需要依赖这张数据表生成,如果出现单点故障,很可能导致服务瘫痪。
- 性能瓶颈:单个数据库一下子接收大量请求连接接入,可能扛不住高并发的压力。
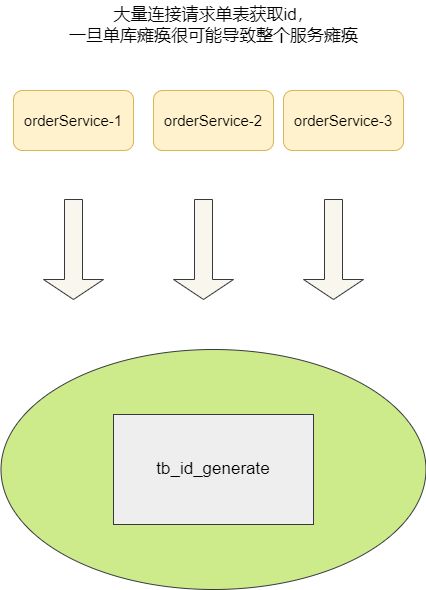
分库分表主键自增
针对上述问题,我们提出使用多库多表生成分布式ID以保证高可用,例如我们现在就使用双主模式,每个库分别存放一张id分配表(id_allocation ),表1的id从1开始,表2的id从2开始,各自的步长都为2:
-- ID分配表1,从1开始自增,步长为2
CREATE TABLE db1.id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
) AUTO_INCREMENT=1;
-- ID分配表2,从2开始自增,步长为2
CREATE TABLE db2.id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
) AUTO_INCREMENT=2;
为了保证压力均摊,我们可以针对服务采用轮询或者哈希算法请求不同的数据库获取唯一ID:
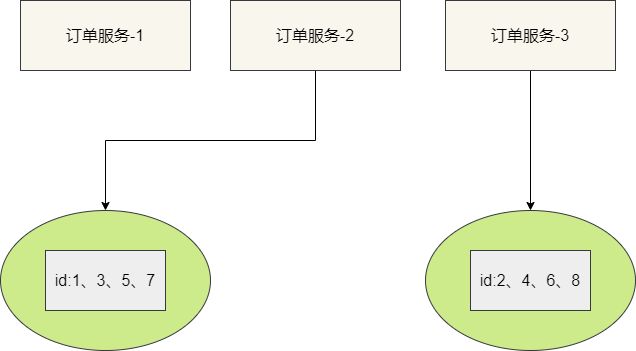
该方案很好的解决的DB单点问题,但是每个库的压力仍然很大,依旧无法满足高并发的场景。
号段式
号段式分布式ID生成是当下比较主流的实现方案之一,它的整体思路是在专门建立一张数据表划分当前业务的ID分配段,每次加载一批号段到内存中,然后所有的服务都从这个号码段中获取ID,直至这个号码段用完,然后再到数据库中再划动一批到内存中使用,对应的建表SQL如下所示:
CREATE TABLE id_allocation (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前已用最大id',
step int(20) NOT NULL COMMENT '号段分配步长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
)
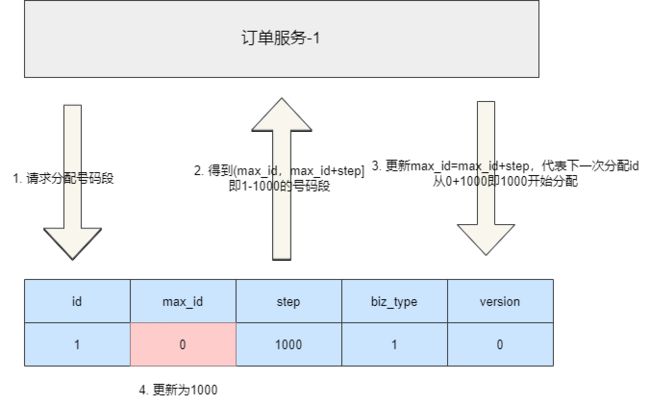
我们假设现在有一个订单服务要采用号段式进行ID分配,我们在这张表中初始化订单服务的数据,可以看到订单服务初始化的数据,max_id为0,即表示当前这个业务还未分配任何id,业务类型为1,step为1000,即代表每次有服务来请求时就分配1000个id段给请求服务,而version则是保证多服务请求数据一致性的乐观锁版本号:
INSERT INTO id_allocation (id, max_id, step, biz_type, version) VALUES (1, 0, 1000, 1, 0);
到数据查询当前业务的号码段,查询数据库得到结果是max_id为0以及step为1000,这意味着当前这个业务的id已经用到了0(还未使用过),而可用范围为1000,所以号码段为[max_id+1,max_id+step]即1~1000,将数据库加载到数据库之后,携带版本号将数据的max_id更新为max_id+step,如此一来下次id分配就从1000开始:
update table set max_id=max_id+step
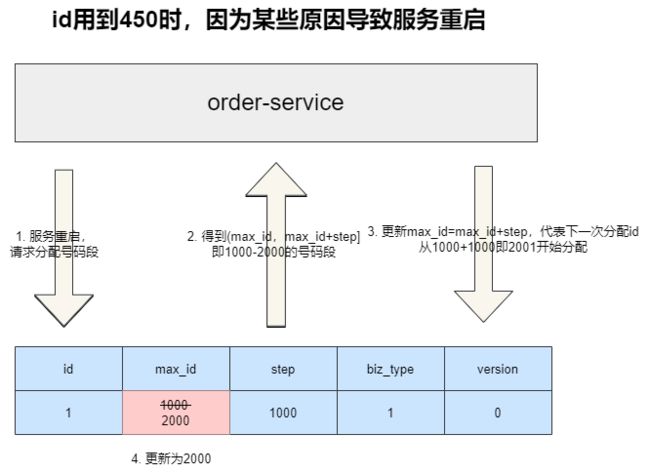
为了避免因为服务崩溃等情况导致内存中的号码段丢失,我们需要如下两个步骤的处理避免ID冲突:
- 每一次服务重启时,先加载一批号码段到内存中,然后更新数据库中的
max_id,尽管这么做可能导致一部分的id浪费,但是这种即用即更新很好的解决的id冲突的问题。
- 编写AOP切面或者其他任何方式,当捕获到ID冲突异常后,直接更新内存中的号码段,在业务上尽可能直接解决意外冲突。
可以说这种方案通过数据库结合内存缓冲了数据库的压力,既保证的唯一性,又能够抗住高并发,对于扩容,我们也可以通过在数据库中增加配置,以调整id范围。而它的缺点也很明显,它很可能因为服务宕机或者内存丢失的原因,导致一段id全部丢弃导致一定的号码段浪费。
当然这种方案现如今也有了比较成熟的框架,详情可以参考美团这个项目:
Meituan-Dianping/Leaff
基于redis
我们也可以尝试通过redis原子操作获取唯一id,无论是安全还是性能表现都很出色,所以在高并发场景下也有着不错的发挥。
127.0.0.1:6379> set seq_id 1
OK
127.0.0.1:6379> INCR seq_id
(integer) 2
127.0.0.1:6379> INCR seq_id
(integer) 3
127.0.0.1:6379> INCR seq_id
(integer) 4
127.0.0.1:6379>
当然这种方案也有着一定的缺点:
- 若我们使用
rdb持久化机制,一旦redis宕机等原因导致缓存丢失,再次从redis中获取的id很可能出现冲突。 - 若使用aof会导致每一条命令都会进行持久化,但也会导致重启数据恢复时间过长。
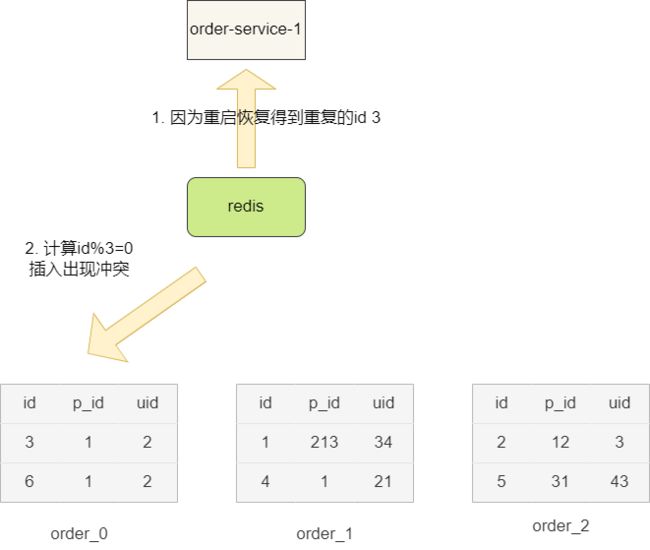
所以我们建议通过redis混合持久化机制结合redis高可用架构保证分布式id生成的可靠性,并在业务处理上对这类id冲突进行一定的兜底处理。
雪花算法
雪花算法是twitter开发是一中id生成算法,它由于1位正数位,41位时间错,5位workerid和12位的自增序列生成,通过雪花算法在毫秒级情况下可以生成大量id,性能出色,且是有序自增的,类型也是long类型,所以整体上符合大量场景的需要,如果我们分库分表算法的需要有规律的分片键,还可以针对性的改造雪花算法,但它需要考虑一下问题:
- 时钟回拨问题:我们都知道雪花算法有41位是时间戳组成,在高并发场景下回拨时间很可能出现相同的时间戳,很可能造成id冲突的场景。
- 无法满足多分片键场景,雪花算法虽能保证id唯一,对于单一条件绰绰有余,一旦遇到多分片键依赖单id的场景就显得力不从心了。举个例子,在商城下单后,我们通过雪花算法生成唯一订单号,根据
hash算法id%table得到分表名称。这样的话,我们通过订单号可以快速定位到分表并查询到数据。但是从用户角度来说,他希望通过自己的uid定位到订单号就无迹可寻了,所以针对多分片键的场景使用雪花算法可以需要结合基因法进行一番改造。
常规用法
以下是开源工具类hutool提供的雪花工具类,只需两行代码即可生成唯一键。
@Slf4j
public class Main {
public static void main(String[] args) {
Snowflake snowflake = new Snowflake();
log.info("snowflake:{}", snowflake.nextId());
}
}
输出结果如下:
12:23:24.412 [main] INFO com.sharkchili.distIdFactory.Main - snowflake:1740226920726044672
为了验证唯一性,笔者在单位时间内连续生成100w的雪花id:
@Slf4j
public class Main {
public static void main(String[] args) {
Set<Long> idSet = new HashSet<>();
Snowflake snowflake = new Snowflake();
for (int i = 0; i < 100_0000; i++) {
idSet.add(snowflake.nextId());
}
log.info("idSe sizet:{}", idSet.size());
}
}
从输出结果来看,常规用法下没有出现id碰撞:
12:35:27.167 [main] INFO com.sharkchili.distIdFactory.Main - idSe sizet:1000000
基因拼接法
这是针对多shard_colunmn改造雪花id的解决方案,即拿雪花id的部分bit存放我们的其他shard_column的hash值。
举个简单的例子,假如我们现在有16张分表,分表算法采用hash法,即订单id%16,为了保证通过uid即用户id也能快速查到,我们将订单id的一部分拼接上uid的hash结果。
代码如下所示,假设用户id为189,我们在生成oid后将uid%16拼接到oid末尾,这样我们实现下述查询就非常高效了:
- 根据订单id查询订单信息。
- 根据uid定位所有该用户订单。
- 根据订单信息查询当前用户信息。
/**
* 基因替换法基础示例
*/
@Slf4j
public class BaseGene {
private static int TABLE_COUNT = 16;
public static void main(String[] args) {
//用户自增id为189
int userId = 189;
//为该用户生成订单时,将用户id作为基因拼接到订单后3位
long orderId = Long.parseLong(System.currentTimeMillis() + "189");
log.info("userId:{} orderId:{}", userId, orderId);
int tableNoByUid = userId % TABLE_COUNT;
//拿到后3位定位到用户id,从而定位分表
long orderIdGene = orderId % 1000;
int tableNoByOrderIdGene = (int) (orderIdGene % TABLE_COUNT);
log.info("tableNoByUid :{} tableNoByOrderIdGene:{}", tableNoByUid, tableNoByOrderIdGene);
}
}
了解基因拼接法之后,我们就基于雪花id的源码改造出基因法的生成算法:
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
/**
* @param datacenterId 数据中心
* @param machineId 机器标识
*/
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
}
使用示例如下:
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
这里我们假设为考虑业务发展,将来可能扩展到32个库,所以针对最后12bit我们拿7位所谓序列号,留有5位作为我们的基因,所以改造后的代码如下:
public synchronized long nextId(int gene) {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
// log.info("时间戳部分:{}", (currStmp - START_STMP) << TIMESTMP_LEFT);
// log.info("数据中心部分:{}", datacenterId << DATACENTER_LEFT);
// log.info("机器标识部分:{}", machineId << MACHINE_LEFT);
log.info("序列号部分:{} ", sequence);
// log.info("基因:{}", gene);
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence & 4064 //序列号部分,前移7位,可变部分5位,所以1ms最多生成32个不重复
| gene; //改为我们的基因
}
同理为了测试单用户生成的订单id这个基因法的碰撞数,笔者将时间戳改为相同时间:
/**
* 写死时间,这样唯一不同的只有低位的12 bit即0-4095
*
* @return
*/
private long getNewstmp() {
return timeMillis;
}
测试代码如下:
public static void main(String[] args) {
GeneSnowflake snowFlake = new GeneSnowflake(2, 3);
Set<Long> idSet = new HashSet<>();
int uId = 189;
int TABLE_COUNT = 32;
for (int i = 0; i < 128; i++) {
long id = snowFlake.nextId(uId % TABLE_COUNT);
log.info(" 生成id:{}", id);
idSet.add(id);
}
log.info("生成的id数量:{}", idSet.size());
}
可以看到生成的结果为单位时间只能生成128个不重复的id,也就是说在时间戳一样的情况下,同一个时间戳可以生成7bit即128个不重复的id。
12:46:09.135 [main] INFO com.sharkchili.distIdFactory.GeneSnowflake - 生成的id数量:128
小结
我是sharkchili,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号:
写代码的SharkChili,同时我的公众号也有我精心整理的并发编程、JVM、MySQL数据库个人专栏导航。

参考
一口气说出9种分布式ID生成方式,阿里面试官都懵了
:https://zhuanlan.zhihu.com/p/152179727
一文搞懂分库分表算法,通俗易懂(基因法、一致性 hash、时间维度)
:https://blog.csdn.net/qq_42875345/article/details/132662916