知识库-kafka shell脚本用法
| 脚本名称 | 用途描述 |
| connect-distributed.sh | 连接kafka集群模式 |
| connect-standalone.sh | 连接kafka单机模式 |
| kafka-acls.sh | todo |
| kafka-broker-api-versions.sh | todo |
| kafka-configs.sh | 配置管理脚本 |
| kafka-console-consumer.sh | kafka消费者控制台 |
| kafka-console-producer.sh | kafka生产者控制台 |
| kafka-consumer-groups.sh | kafka消费者组相关信息 |
| kafka-consumer-perf-test.sh | kafka消费者性能测试脚本 |
| kafka-delegation-tokens.sh | todo |
| kafka-delete-records.sh | 删除低水位的日志文件 |
| kafka-log-dirs.sh | kafka消息日志目录信息 |
| kafka-mirror-maker.sh | 不同数据中心kafka集群复制工具 |
| kafka-preferred-replica-election.sh | 触发preferred replica选举 |
| kafka-producer-perf-test.sh | kafka生产者性能测试脚本 |
| kafka-reassign-partitions.sh | 分区重分配脚本 |
| kafka-replay-log-producer.sh | todo |
| kafka-replica-verification.sh | 复制进度验证脚本 |
| kafka-run-class.sh | todo |
| kafka-server-start.sh | 启动kafka服务 |
| kafka-server-stop.sh | 停止kafka服务 |
| kafka-simple-consumer-shell.sh | deprecated,推荐使用kafka-console-consumer.sh |
| kafka-streams-application-reset.sh | todo |
| kafka-topics.sh | topic管理脚本 |
| kafka-verifiable-consumer.sh | 可检验的kafka消费者 |
| kafka-verifiable-producer.sh | 可检验的kafka生产者 |
| trogdor.sh | todo |
| zookeeper-security-migration.sh | todo |
| zookeeper-server-start.sh | 启动zk服务 |
| zookeeper-server-stop.sh | 停止zk服务 |
| zookeeper-shell.sh | zk客户端 |
详细用法说明与测试
connect-distributed.sh&connect-standalone.sh
Kafka Connect 是一款可扩展并且可靠地在 Apache Kafka 和其他系统之间进行数据传输的工具。 可以很简单的快速定义 connectors 将大量数据从 Kafka 移入和移出. Kafka Connect 可以摄取数据库数据或者收集应用程序的 metrics 存储到 Kafka topics,使得数据可以用于低延迟的流处理。 一个导出的 job 可以将来自 Kafka topic 的数据传输到二级存储,用于系统查询或者批量进行离线分析。
Kafka Connect 功能包括(操作太复杂,想要详细了解可以访问:Kafka 中文文档 - ApacheCN 第八节查看):
- Kafka connectors 通用框架: - Kafka Connect 将其他数据系统和Kafka集成标准化,简化了 connector 的开发,部署和管理
- 分布式和单机模式 - 可以扩展成一个集中式的管理服务,也可以单机方便的开发,测试和生产环境小型的部署。
- REST 接口 - submit and manage connectors to your Kafka Connect cluster via an easy to use REST API
- offset 自动管理 - 只需要connectors 的一些信息,Kafka Connect 可以自动管理offset 提交的过程,因此开发人员无需担心开发中offset提交出错的这部分。
- 分布式的并且可扩展 - Kafka Connect 构建在现有的 group 管理协议上。Kafka Connect 集群可以扩展添加更多的workers。
- 整合流处理/批处理 - 利用 Kafka 已有的功能,Kafka Connect 是一个桥接stream 和批处理系统理想的方式。
kafka-broker-api-versions.sh
./kafka-broker-api-versions.sh --bootstrap-server kafka-tt-0.kafka-tt:9092
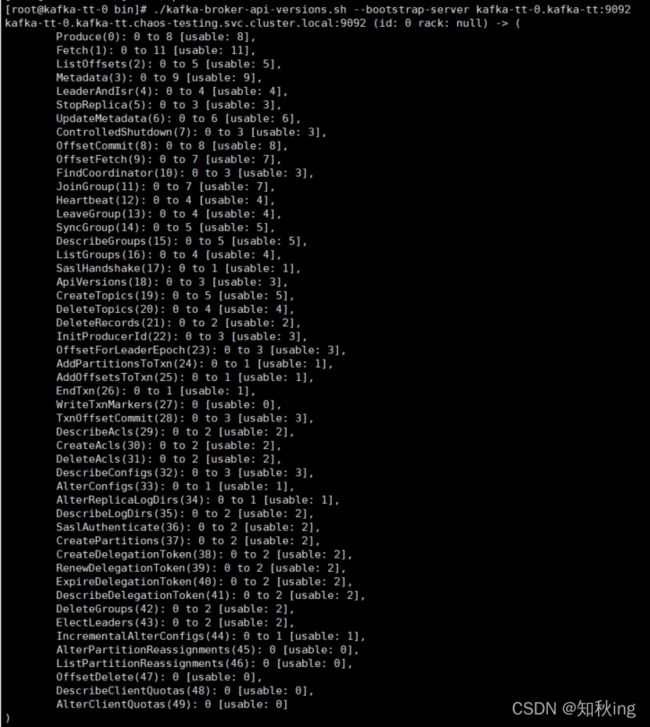
kafka双向兼容版本。
kafka-configs.sh
配置管理脚本
详细使用:脚本kafka-configs.sh用法解析 - 李志涛 - 博客园
kafka-console-producer.sh
kafka 生产者控制台
用法:bin/kafka-console-producer.sh --broker-list localhost:9092 --topic aaa
,如果连接集群,那么broker-list参数格式为:HOST1:PORT1,HOST2:PORT2,HOST3:PORT3

kafka-console-consumer.sh
kafka 消费者控制台
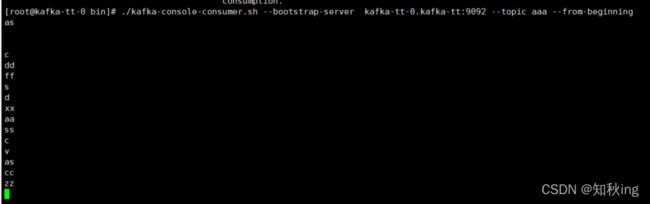
# 消费数据(从latest消费)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic
# 消费数据(从头开始消费)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --from-beginning
# 消费数据(最多消费多少条就自动退出消费)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --max-messages 1
# 消费数据(同时把key打印出来)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --property print.key=true
# 旧版
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test_topic
kafka-consumer-groups.sh
查看消费者组
查看所有消费者组:bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
![]()
查看某个消费者组:bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group console-consumer-42747 --describe,输出结果如下:

输出结果列中LAG表示消费者当前offset和broker中LOG-END-OFFSET之间的差距,理想结果是0,表水没有任何延迟。如果这个值比较大,需要注意。
kafka-consumer-perf-test.sh
perf是performance的缩写,所以这个脚本是kafka消费者性能测试脚本。
用法:bin/kafka-consumer-perf-test.sh --broker-list localhost:9092 --group testGroup --topic aaa --messages 1024
kafka-delete-records.sh
用法:bin/kafka-delete-records.sh --bootstrap-server 10.0.55.229:9092,10.0.55.229:9093,10.0.55.229:9094 --offset-json-file offset.json,offset.json文件内容,表示删除afei这个topic下分区为3的offset少于10的消息日志(不会删除offset=10的消息日志
kafka-log-dirs.sh
显示文件挂载目录,分区信息
用法:bin/kafka-log-dirs.sh --bootstrap-server localhost:9092 --describe --topic-list aaa
![]()
kafka-producer-perf-test.sh
perf是performance的缩写,所以这个脚本是kafka生产者性能测试脚本。
kafka-server-start.sh
启动脚本
kafka-server-stop.sh
关闭脚本
kafka-topics.sh
创建topic:bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic aaa --partitions 3 --replication-factor 1
删除topic: bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic aaa,broker的delete.topic.enable一定要是true才能成功删除topic,否则删除命令会被忽视。
修改topic: bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic aaa --partitions 5,修改topic时只能增加分区数量。
查询topic: bin/kafka-topics.sh --zookeeper localhost:2181 --describe [ --topic aaa],查询时如果带上,那么表示只查询该topic的详细信息。这时候还可以带上 和任意一个参数。
说明:如果某些topic为了有序发送消息时会基于key,那么增加分区数量会导致key和分区的映射关系发生变化。如果这个影响不能接受,那么基于key的topic最好一开始就评估分区数量,将来尽量避免调整。
kafka-verifiable-consumer.sh
用法:bin/kafka-verifiable-consumer.sh --broker-list 10.0.55.229:9092,10.0.55.229:9093,10.0.55.229:9094 --topic afei --group-id groupName
这个脚本的作用是接收指定topic的消息消费,并发出消费者事件,例如:offset提交等。
kafka-verifiable-producer.sh
用法:bin/kafka-verifiable-producer.sh --broker-list 10.0.55.229:9092,10.0.55.229:9093,10.0.55.229:9094 --topic afei [--max-messages 64],建议使用该脚本时增加参数,否则会不停的发送消息。
这个脚本的作用是持续发送消息到指定的topic中,参数限制最大发送消息数。且每条发送的消息都会有响应信息,这就是和最大的不同:
afei这个topic有3个分区,使用kafka-verifiable-producer.sh发送9条消息。根据输出结果可以看出,往每个分区发送了3条消息。另外,我们可以通过设置参数一个比较大的值,可以压测一下搭建的kafka集群环境。
zookeeper-shell.sh
用法:bin/zookeeper-shell.sh localhost:2181[/path],如果kafka集群的zk配置了chroot路径,那么需要加上/path,例如,登陆zk后,就可以查看kafka写在zk上的节点信息。例如查看有哪些broker,以及broker的详细信息:
参考文献:
Kafka 中文文档 - ApacheCN
《深入理解Kafka核心设计与实践理论》