VITS:Conditional Variational Autoencoder with Adversarial Learning forEnd-to-End Text-to-Speech——TTS
笔记地址:https://flowus.cn/share/4c8c251b-cb8e-4f21-aa9e-139c1c3cf883
【FlowUs 息流】Vits
论文地址:
proceedings.mlr.press
Abstract
与传统的two-stage TTS(即文字→mel频谱→声音)相比,是一种parallel end-to-end TTS,提升了效率且声音自然。
其它parallel方法主要存在音质不佳情况,Vits使用了variational inference augmented with normalizing flows and an adversarial training process,等技术,使得声音听起来更加自然。variational inference augmented with normalizing flows:这些技术被用于提高生成模型的表达能力,使生成的语音更加自然和富有表现力。adversarial training process:进一步优化模型性能,提高生成语音的质量。
提出stochastic duration predictor:通过这个预测器,系统能够从给定文本合成具有多样化节奏的语音,增强语音的自然度和多样性。
uncertainty modeling和stochastic duration predictor的运用下,系统能够理解和表达one-to-many关系,反映了语言的自然多样性。
评价指标:使用LJSpeech数据集,MOS指标评定
1.Introduction
这部分介绍了TTS系统发展的过程,并解释了Vits在之前基础上所做的工作
TTS系统将给定的文本信息,合成为原始语音波形,传统上通常通过两阶段来完成。
First Stage:从预处理文本生成中间语音表示,如Mel频谱或语言特征(linguistic features)
Second Stage:根据第一阶段的中间表示生成原始波形
在First Stage,自回归的TTS方法如tacotron能够合成真实的语音,但问题是它的序列生成过程难以充分利用现代并行处理器
为了提高合成速度克服回归系统限制,提出了几种非自回归方法
从预训练的教师网络中提取注意力图,如fastspeech就采取了这样的方式,以降低学习文本和频谱图之间对齐的难度
基于似然的方法:进一步消除对外部对齐器的依赖,通过估计或学习对齐来最大化目标Mel频谱图的似然
在Second Stage,从频谱图到原始波形图的过程,多使用生成对抗网络GAN。基于GAN的前馈网络采用多个判别器,每个判别器在不同尺度或周期上区分样本,实现了高质量的原始波形合成
传统上TTS通常通过以上两个Stage完成,但这仍然存在问题,主要因为它需要序列训练或微调。后期模型的训练依赖于前期模型生成的样本。系统依赖于预定义的中间特征,这限制了使用学习到的隐藏表示来进一步提升性能的可能性。
VITS方法的创新之处:
端到端的并行训练:VITS采用了变分自编码器(VAE)的框架,将TTS系统的两个模块通过潜在变量连接起来,实现高效的端到端学习。
表达力的提升:为了提高合成的高质量语音的表达能力,VITS应用了标准化流(normalizing flows)在条件先验分布上,并在波形领域采用了对抗训练。
多样性和自然性:为了解决文本到语音中的一对多问题(即同一文本可以有多种不同的语音表达方式),VITS提出了一种随机持续时间预测器,这使得从输入文本合成具有不同节奏的语音成为可能。通过对潜在变量的不确定性建模和随机持续时间预测器,VITS能够捕捉到仅通过文本无法表示的语音变化。
优越的性能:VITS在生成自然 sounding speech 和采样效率方面都优于当时公开可用的最佳TTS系统Glow-TTS结合HiFi-GAN。
2.Method
VITS是一种基于变分推断(Variational Inference)和对抗学习(adversarial learning)的端到端文本到语音转换(TTS)方法,全称为:Variational Inference with adversarial learning for end-to-end Text-to-Speech
2.1Variational Inference
2.1.1Overview
VITS是一种条件变分自编码器(Conditional VAE),其目标是最大化变分下界(也称为证据下界,ELBO)。该方法旨在处理无法直接计算的数据的边际对数似然 logpθ(x∣c)。VITS不仅包括变分推断,还包括对齐估计和对抗训练以提高合成质量。

公式解释:
- 公式表达了ELBO的数学形式,即 logpθ(x∣c)≥Eqϕ(z∣x)[logpθ(x∣z)−logpθ(z∣c)qϕ(z∣x)]。
- pθ(z∣c) 表示给定条件 c 下潜在变量 z 的先验分布。
- pθ(x∣z) 是数据点 x 的似然函数。
- qϕ(z∣x) 是潜在变量 z 的近似后验分布。
- ELBO由两部分组成:重建损失 logpθ(x∣z) 和KL散度 -logpθ(z∣c)qϕ(z∣x),这两项的和被用来作为训练损失。
2.1.2Reconstruction Loss
重构建损失是训练阶段用来提高生成语音质量的关键步骤,这个方法利用了梅尔频谱图与人耳感知的接近性,来提升合成语音的感知质量。
重建目标选择:
在计算重建损失时,VITS不使用原始的波形数据作为目标,而是使用梅尔频谱图(mel-spectrogram),记为 xmel。梅尔频谱图是一种更紧凑的数据表示形式,它基于人类听觉感知的非线性梅尔尺度。
潜在变量到波形域的上采样:
潜在变量 z 通过解码器上采样到波形域 y^,然后将波形 y^ 转换为梅尔频谱图域 x^mel。
计算重建损失:
重建损失 Lrecon 是预测的梅尔频谱图 x^mel 与目标梅尔频谱图 xmel 之间的L1范数(绝对值误差和)。数学表示为

最大似然估计:
这种重建损失可以看作是在假设数据分布符合拉普拉斯分布的条件下的最大似然估计,忽略了常数项。
选择梅尔频谱图的理由:
作者选择在梅尔频谱图域定义重建损失,是因为梅尔尺度近似模拟了人类的听觉系统响应,这有助于改进生成语音的感知质量。
梅尔频谱图的计算方式:
从原始波形到梅尔频谱图的转换不需要可训练的参数,仅使用短时傅里叶变换(STFT)和线性投影到梅尔尺度上。这个转换只在训练期间使用,而在实际推理过程中不使用。
高效端到端训练:
在实践中,并不对整个潜在变量 z 进行上采样,而是使用部分序列作为解码器的输入,这就是所谓的窗口化生成器训练。这种方法被用于高效的端到端训练。
2.1.3KL-Divergence
通过这种方式,VITS系统能够在没有对齐真值标签的情况下,通过变分推断估计潜在变量的分布,并利用正规化流增加先验分布的表达性,从而在保持变分推断属性的同时生成高质量的语音样本。
先验编码器的输入条件:
先验编码器的输入条件 c 包括从文本中提取的音素 ctext 和音素与潜在变量之间的对齐 A。这里的对齐 A 是一个硬性单调注意力矩阵(hard monotonic attention matrix),它有 ∣ctext∣×∣z∣ 的维度,表示每个输入音素在时间上扩展多长,以与目标语音对齐。
对齐的估计:
由于对齐没有真值标签,需要在每次训练迭代中估计对齐,这一点将在2.2.1节中讨论。
后验编码器的输入:
在问题设定中,目的是为后验编码器提供更高分辨率的信息。因此,使用目标语音的线性尺度频谱图 xlin 作为输入,而不是梅尔频谱图。修改的输入不会违反变分推断的属性。
KL散度的计算:

其中 z 由后验分布 qϕ(z∣xlin) 采样得到,后者是一个参数化的正态分布。
先验和后验编码器的参数化:
使用分解的正态分布来参数化先验和后验编码器。
提高先验分布的表达性:
为了生成更真实的样本,增加先验分布的表达性是很重要的。因此,使用正规化流 fθ(来自Rezende & Mohamed, 2015的工作)对分解的正态先验分布进行变换。正规化流允许一个简单分布通过变量变换的规则转换成一个更复杂的分布。
正规化流的应用:
正规化流的应用在先验分布,变换的雅可比行列式用于在变换过程中保持概率分布的完整性。

2.2Alignment Estimation
2.2.1Montonic Alignment Search
由于在训练时没有对齐的真实标签,因此在训练阶段的每一次迭代时都需要估计文本和音频之间的对齐。MAS在VITS中用于动态地估计输入文本到目标语音的最优对齐,这是训练过程中的一个关键步骤,因为正确的对齐对于生成高质量的语音至关重要。通过这种对齐,VITS能够确保在合成过程中每个音素都能得到适当的时间展开,从而在听觉上保持语音的自然流畅。
对齐的定义:
对齐 A 是输入文本和目标语音之间的时间映射,确定了输入文本中的每个音素(或字)与目标语音中的特定时间段如何对应。
MAS的原理:
MAS是一种寻找最优对齐的算法,目的是找到一个对齐 A^,它可以最大化给定输入 ctext 和潜在流 f 参数化数据的似然 p(x∣ctext,A^)。
由于人类在阅读文本时是按顺序不跳跃地读的,因此对齐被限制为单调非跳跃的。
对齐估计的数学表达:

使用正态分布来寻找最优对齐 A。这个过程涉及搜索所有可能的对齐候选 A^,以找到最大化似然的那个。
MAS与ELBO的关系:
在VITS的背景下,由于目标是最大化ELBO而不是精确的对数似然,因此MAS需要被重新定义为寻找最大化ELBO的对齐。
这实际上归结为找到一个对齐 A^,它最大化了潜在变量 z 的对数似然。
MAS在VITS中的应用:

公式(6)描述了在VITS设置中,MAS的目标是找到最大化 logpθ(z∣ctext,A^) 的对齐 A^,即最大化潜在变量 z 在给定文本和对齐的条件下的先验分布的对数似然。
因为公式(5)和公式(6)在形式上相似,可以直接使用原始的MAS实现而无需修改。
动态规划的使用:
Kim等人(2020年)提到,为了找到最优对齐,使用了动态规划方法,这是一种有效的算法,可以在多个可能的对齐序列中快速找到最优解。
2.2.3Duration Prediction from text
计算时长:
文本中的每个输入标记(比如音素)的时长可以通过对估计的对齐矩阵中的每一行进行求和来计算。这个时长可以用来训练一个确定性的时长预测器,但这种方法无法表达人在不同语速下的发音方式。
随机时长预测器的设计:
为了生成类似人类的语音节奏,设计了一个随机时长预测器。这个预测器是基于流的生成模型,通常通过最大似然估计来训练。但是直接应用最大似然估计有其难点,因为每个输入音素的时长是离散的整数,需要去量化以适用于连续的归一化流,并且是标量,这限制了因可逆性而进行的高维转换。
变分去量化和数据增强:

为了解决这些问题,引入了变分去量化(variational dequantization)和变分数据增强(variational data augmentation)。具体地,引入了两个随机变量 u 和 ν,它们与时长序列 d 的时间分辨率和维度相同。将 u 限制在 [0, 1) 范围内,使得 d−u 成为一系列正实数,并且将 ν 和 d 在通道维度上拼接,形成更高维的潜在表示。
目标函数和训练损失:
通过近似后验分布 qφ(u, ν|d, ctext) 采样这两个变量。结果目标是音素时长的对数似然的变分下界。训练损失 Ldur 是变分下界的负数。在训练过程中,应用停止梯度操作符,以防止输入条件的梯度反向传播,这样时长预测器的训练就不会影响其他模块。
采样过程:
S采样过程相对简单。音素时长通过随机噪声通过随机时长预测器的逆变换采样得到,然后转换为整数。
2.3Adversarial Training
VITS使用对抗训练来提升语音质量,
GAN由两部分组成:生成器 G 和判别器 D。生成器 G 负责生成数据,而判别器 D 则区分生成的数据和真实数据。在这项工作中,使用了两种类型的损失函数来训练这两个网络:

对判别器的对抗损失 Ladv(D):
这个损失函数是用于训练判别器 D,使其能够更好地区分生成的输出和真实的波形 y。这里使用的是最小二乘损失函数,它有利于提高训练过程的稳定性。该函数针对两个目标:使判别器 D 对于真实数据 y 的判断尽可能接近1(即认为数据是真实的)。使判别器 D 对于生成数据 G(z) 的判断尽可能接近0(即认为数据是生成的)。
对生成器的对抗损失 Ladv(G):
这个损失函数是用于训练生成器 G,使其生成的数据在判别器 D 看来无法与真实数据区分。目的是让生成器 G 生成的数据 G(z),在经过判别器 D 评估后,尽可能得到接近1的判断,即判别器认为生成数据是真实的。
特征匹配损失 Lfm(G):
特征匹配损失用于进一步训练生成器 G,它关注于在判别器的隐藏层上进行重建损失的计算。这种损失函数与变分自编码器(VAEs)中的元素级重建损失不同,因为它不是直接在输出层比较生成数据和真实数据,而是在判别器内部的多个隐藏层进行比较。这样可以帮助生成器学习生成在特征层面上与真实数据更为接近的数据,从而改善生成数据的质量。
这三个损失函数共同作用,帮助生成对抗网络学习如何生成看起来和真实波形更接近的语音数据。其中 T 代表判别器中层的总数,而 Dl 输出第 l 层的特征映射。
2.4Final Loss
结合VAE和GAN的训练过程,训练conditional VAE的总损失为:

2.5Model Architecture

总体结构由后验编码器(posterior encoder),先验编码器(prior encoder),解码器(decoder),鉴别器(discriminator)和随机持续时间预测器(stochastic duration predictor)组成。后验编码器和鉴别器只用于训练。
VITS模型是如何实现训练过程的:
文本编码器(Text Encoder): 首先,文本编码器接收文本信息,这里是以音素(Phonemes)的形式呈现。文本编码器将这些音素转换为一个连续的上下文表示 ctext,这为生成语音的语音学特征提供了基础。
后验编码器(Posterior Encoder): 后验编码器接收一个线性频谱图(Linear Spectrogram)作为输入,并将其编码为一个潜在的表示 z。这个潜在表示试图捕捉输入语音的重要特征。
对齐搜索(Monotonic Alignment Search): 这个步骤涉及到将文本表示和潜在的语音表示对齐。这通常是一个挑战,因为文本到语音中需要将不同长度的文本序列与语音序列对应起来。
流(Flow): 流是一个可逆的神经网络,它可以将潜在表示 z 转换为一个更结构化的空间 fθ(z),其中可能更容易从中采样和生成新的数据点。
投影(Projection): 这个步骤将上下文表示 ctext 投影到与潜在表示 z 相同的空间。
随机持续时间预测器(Stochastic Duration Predictor): 这部分模型负责预测每个音素的持续时间,这是生成自然听起来的语音的关键因素。
梯度停止(Stop Gradient): 梯度停止是一种技术,用于防止在训练过程中的某些部分传递梯度,以便可以独立地训练模型的其他部分。
噪声(Noise): 噪声项可能被添加到潜在表示中,以鼓励模型学习生成多样化的输出,这是变分推断方法的常见做法。
解码器(Decoder): 最后,解码器接收流输出 fθ(z),以及文本和持续时间信息,生成最终的原始波形。解码器负责将所有信息合成为可听的语音。
2.5.1Posterior Encoder
后验编码器
- 训练阶段:后验编码器用于估计给定真实语音数据时的潜在变量分布。它接收真实的语音波形作为输入,并输出这些波形对应的潜在表示(均值和方差)。这个潜在表示用于计算重构损失,帮助训练生成器更准确地重建输入波形。
- 推理阶段:后验编码器不会被使用,因为在实际应用中,我们没有真实的目标语音波形来估计其潜在表示。
2.5.2Prior Encoder
先验编码器,在图中又被写作Text Encoder
- 训练阶段:先验编码器用于估计没有给定真实语音数据时的潜在变量分布,即在训练时用于生成潜在变量的分布。这个分布通常被设计得更为广泛,以便能够捕获可能产生的各种不同语音波形。
- 推理阶段:在生成新的语音波形时,先验编码器是活跃的。它接收文本信息作为输入,并通过文本编码器和正规化流转换成潜在变量的分布。然后,从这个分布中采样潜在变量,以此来驱动解码器生成语音波形。
2.5.3Decoder
- 解码器基本上是HiFi-GAN V1生成器的结构。这个生成器包括多个转置卷积层,每一个转置卷积层后面都跟着一个多感受野融合模块(MRF)。
- MRF的输出是具有不同感受野大小的残差块输出的总和。这种设计使得解码器能够同时捕获不同时间尺度上的语音特性,有助于提高生成波形的质量。
- 在多说话人设置中,解码器会添加一个线性层来变换说话人嵌入,将其加到输入的潜在变量 z 中,这样可以确保生成的语音能反映不同说话人的特征。
2.5.4Discriminator
- 判别器的架构遵循HiFi-GAN中提出的多周期判别器。多周期判别器由多个基于马尔可夫窗的子判别器组成,每个子判别器处理输入波形的不同周期模式。
- 这些子判别器可以捕捉波形中不同时间尺度的特性,从而有效地评价生成波形的真实性和自然度。它们帮助训练生成器更好地模仿真实语音的细节。
2.5.5Stochastic Duration Predictor
- 随机时长预测器从条件输入 htext 估计音素时长的分布。它的目的是预测每个音素的持续时间,这对于生成自然的语音节奏非常关键。
- 为了有效地参数化随机时长预测器,堆叠了带膨胀和深度可分离卷积层的残差块。这些残差块可以处理不同时间尺度的信息,对于预测音素时长非常有用。
- 此外,随机时长预测器应用了神经样条流(neural spline flows),它们是通过使用单调有理二次样条函数的可逆非线性变换,提高了变换的表达能力,同时参数数量相对于常用的仿射耦合层并没有显著增加。
- 在多说话人设置中,随机时长预测器也会添加一个线性层来变换说话人嵌入,并将其加到输入 htext 中,以确保时长预测能够适应不同说话人的特点。
3.Experiments
3.1Datasets
LJ Speech数据集:
- 这是一个包含一个说话人的13,100个短音频剪辑的数据集,总时长约24小时。
- 音频格式为16位PCM,采样率为22kHz,并且在使用时没有进行任何处理。
- 数据集被随机分为训练集(12,500个样本),验证集(100个样本),和测试集(500个样本)。
VCTK数据集:
- 这个数据集包含109位不同口音的英语母语说话人的约44,000个短音频剪辑,总时长约44小时。
- 音频格式同样为16位PCM,原始采样率为44kHz,但为了实验需要,将采样率降低到了22kHz。
- 数据集也被随机分为训练集(43,470个样本),验证集(100个样本),和测试集(500个样本)。
3.2Preprocessing
对于后验编码器的输入:
- 使用线性频谱图,这是通过短时傅立叶变换(STFT)从原始波形中获得的。
- FFT大小、窗口大小和跳跃大小分别设置为1024、1024和256。
重构损失计算:
- 使用80频带的梅尔尺度频谱图,通过将梅尔滤波器银行应用于线性频谱图获得。
对于先验编码器的输入:
- 使用国际音标(IPA)序列。
- 将文本序列使用开源软件转换为IPA音素序列,转换后的序列在实施Glow-TTS时被插入了空白标记。
3.3Training
优化器:
- 使用AdamW优化器进行网络训练,其超参数设置为 β1=0.8,β2=0.99,并且权重衰减 λ=0.01。
学习率调度:
- 学习率的调整是通过每个epoch乘以一个 0.99981 的衰减因子来实现的,初始学习率设为 2×10−4。
窗口生成器训练:
- 为了减少训练时间和内存使用,采用了窗口生成器训练方法,即仅生成原始波形的一部分。这意味着随机抽取潜在表示的一小段(窗口大小为32),而不是整个潜在表示,并且从真实的原始波形中抽取对应的音频段作为训练目标。
混合精度训练:
- 在4个NVIDIA V100 GPU上使用混合精度训练。
批量大小和训练步数:
- 每个GPU的批量大小设置为64,模型训练步数最多达到800k步。
3.4Experimental Setup for Comparison
与其他模型的比较:
- 与目前公开可用的最佳模型进行比较,包括自回归模型Tacotron 2和基于流的非自回归模型Glow-TTS作为第一阶段模型,以及HiFi-GAN作为第二阶段模型。
预训练权重:
- 使用这些模型的公开实现和预训练权重进行比较。
HiFi-GAN的微调:
- 理论上,两阶段的TTS系统可以通过顺序训练达到更高的合成质量,因此包含了与第一阶段模型预测输出配合微调至100k步的HiFi-GAN。
微调的选择:
- 通过实验发现,使用Tacotron 2在教师强制模式下生成的梅尔频谱图对HiFi-GAN进行微调,可以为Tacotron 2和Glow-TTS带来更好的质量,因此选择了质量更高的HiFi-GAN版本与Tacotron 2和Glow-TTS结合。
固定随机性:
- 由于每个模型在采样过程中都有一定的随机性,因此在实验中固定了控制随机性的超参数。Tacotron 2的预网络(pre-net)中的dropout概率设置为0.5,Glow-TTS的先验分布的标准差设置为0.333。对于VITS,随机时长预测器的输入噪声的标准差设置为0.8,并将先验分布的标准差乘以一个0.667的缩放因子。
4.Results
4.1Speech Synthesis Quality

MOS测试:
- MOS(Mean Opinion Score)测试是通过众包方式进行的,评价者依据自然度在1到5分的标准对音频样本打分。
- 为了保证评分的公正性,每个音频样本只被评价一次,并且所有音频都经过了归一化处理,以消除音量差异对评分的影响。
VITS的性能:
- 根据表1,VITS模型在MOS测试中的表现超越了其他文本到语音(TTS)系统,并且接近真实语音的MOS。
- 使用确定性时长预测器的VITS(DDP)在TTS系统中的MOS评估中排名第二,说明即使使用与Glow-TTS相同的确定性时长预测器架构,VITS的性能也非常出色。
时长预测器的影响:
- 实验结果表明,随机时长预测器比确定性时长预测器生成的音素时长更加真实。
- VITS的端到端训练方法即使在保持相似的时长预测器架构的情况下,也能生成比其他TTS模型更优质的样本。

消融实验:
- 正规化流的作用:
- 在表2中,可以看出没有正规化流的模型与基线模型相比,MOS下降了1.52分,这证明了先验分布的灵活性对合成质量有显著影响。
- 输入的频谱类型:
- 将后验输入的线性频谱图替换为梅尔频谱图导致了质量下降(MOS下降了0.19分),说明高分辨率信息对于VITS改善合成质量是有效的。
4.2Generalization to Muti-Speaker Text-to-Speech
- 模型对比:
- VITS模型与Tacotron 2、Glow-TTS和HiFi-GAN进行了比较,这些模型已经展示了它们在多说话人语音合成方面的能力。
- VCTK数据集训练:
- 所有模型都在VCTK数据集上进行了训练,这个数据集包含了不同口音的英语母语说话人,是评估模型处理多样化语音特征的理想选择。
- 说话人嵌入的应用:
- 根据2.5节的描述,VITS模型添加了说话人嵌入来处理多说话人特性。对于Tacotron 2,说话人嵌入与编码器输出一起广播和拼接,而对于Glow-TTS,按照先前工作的方法应用了全局条件。
- 评估方法:
- 评估方法与4.1节中描述的相同,采用MOS测试来评价模型合成语音的自然度。
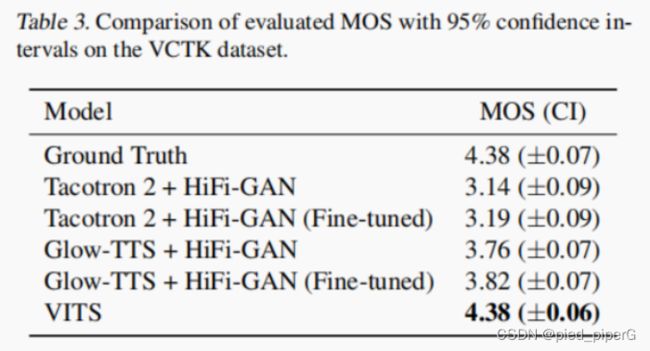
- VITS的性能:
表3显示,VITS模型在MOS评分上高于其他所有模型,甚至达到了与真实语音相同的评分(4.38 ± 0.06)。
- 模型的多样性学习能力:
这个结果表明,VITS模型不仅能够学习和表达多样化的语音特征,而且能够以端到端的方式实现,这是在多说话人语音合成中非常重要的。
4.3Speech Variation

侧重于说明VITS模型通过其随机时长预测器不仅能够生成不同长度的话语,而且能够捕捉和表现出于说话人身份相关的音长和音调的特征。展现VITS生成语音自然的特点
语音长度的多样性:
- 图2a展示了每个模型生成的100个话语样本长度的直方图。
- 由于Glow-TTS使用确定性时长预测器,因此只能生成固定长度的话语样本。
- 相比之下,VITS模型生成的样本显示出与Tacotron 2类似的长度分布,这意味着VITS能够产生不同长度的话语,反映了真实语音中存在的长度变化。
说话人依赖的音素时长学习:
- 图2b显示了在多说话人设置中,VITS模型针对每个说话人身份生成的100个话语样本的长度分布。
- 这表明VITS模型能够学习到与说话人身份相关的音素时长特征。
音调和节奏的多样性:
- 通过YIN算法从10个话语样本中提取的F0(基频)轮廓显示,VITS模型能够生成具有多样化音调和节奏的语音。
- 在多说话人场景下,VITS模型能够表达每个说话人身份的不同音调和音长特征。
4.4Synthesis Speed

基频轮廓:
- 基频轮廓是用来表示语音信号中音调变化的图形,基频(F0)是语音中声波的基础频率,它关联着我们感知到的音高。
- 图中展示了VITS、Tacotron 2、Glow-TTS以及多说话人设置下的VITS模型生成的语音样本的F0轮廓。
VITS的多样性:
- VITS的F0轮廓(图3a)显示了丰富的节奏和音高变化,说明VITS能够合成具有不同音调和节奏的语音。
- 在多说话人设置下(图3d),VITS模型能够为不同的说话人身份生成具有显著不同长度和音调的语音样本。
Tacotron 2和Glow-TTS的比较:
- Tacotron 2(图3b)和Glow-TTS(图3c)也显示了它们生成的语音样本的F0轮廓,但从图中不容易直接判断其与VITS的比较。
合成速度:
合成速度的比较:
- 与并行的两阶段TTS系统(如Glow-TTS和HiFi-GAN)相比,作者还比较了VITS模型的合成速度。
速度测试方法:
- 作者通过测量从音素序列生成原始波形的整个过程的同步耗时来评估合成速度,测试使用了LJ Speech数据集测试集中随机选取的100个句子。
测试配置:
- 使用单个NVIDIA V100 GPU进行测试,批量大小设置为1。
测试结果:
- 表4中应该展示了不同模型的合成速度的比较结果。由于VITS模型不需要为生成预定义的中间表示(如梅尔频谱图)的额外模块,所以在抽样效率和速度上有了显著提升。
6.Conclusion
VITS系统:
- 提出了一种并行的文本到语音合成系统(TTS),即VITS,它能够以端到端的方式学习和生成语音。
随机时长预测器:
- 引入了随机时长预测器来表达语音的多样化节奏,这是VITS系统的一个关键特点,它增加了合成语音的自然度和多样性。
直接从文本合成语音:
- VITS系统能够直接从文本合成自然听起来的语音波形,无需经过预定义的中间语音表示,这简化了传统TTS系统中的合成流程。
实验结果:
- 实验结果表明,VITS在性能上超过了传统的两阶段TTS系统,并且达到了接近人类质量的水平。
应用前景:
- 作者希望提出的方法能够在多种语音合成任务中替代当前使用的两阶段TTS系统,以提高性能并简化训练流程。
挑战与未来研究方向:
- 即使VITS整合了TTS系统中两个分离的生成流程,文本预处理仍然是一个问题。研究自监督学习的语言表示可能是一个移除文本预处理步骤的潜在方向。