学习笔记(二)MySQL并行复制与组提交
MySQL并行复制与组提交
-
-
- 1.并行复制背景
- 2. 重点
- 3. 开启并行复制
- 4. MySQL5.6基于schema的并行复制
-
- (1)优点
- (2)缺点
- 5. 基于binlog group commit✨
-
-
- 问题
-
- 6. 基于writeset
- 7. 如何让slave的并行复制和master的事务执行的顺序一致
- 8. 万恶之源
- 9. 并行复制推荐的参数
-
1.并行复制背景
主从延迟问题:
主从复制中IO线程和SQL线程都是单线程的,但master是多线程的,难免会有延迟,为了避免这个问题,多线程应运而生了。
可以通过监控 show slave status\G命令输出的Seconds_Behind_Master参数的值来检测主从延时
- NULL:表示io_thread或sql_thread有任何一个发生故障
- 0:表示主从复制良好
- 正值:表示主从已经出现延时,数字越大表示从库延迟越严重。
2. 重点
实际上就是开启多个SQL线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
是否能够并行,关键在于多事务之间是否有锁冲突。并行复制的原理就是如何避免锁冲突。
3. 开启并行复制
-
slave_parallel_workers=N (默认是0)
设置从库并行复制时使用的 worker 线程数。
-
slave_parallel_type=LOGICAL_CLOCK
设置并行复制的模式。
-
DATABASE模式:在这种模式下,从库的每个 worker 线程将为指定的数据库复制 binlog 事件。这种模式适用于多个数据库的情况,这种模式可能会导致事务的不一致和复制延迟等问题。 -
LOGICAL模式:在这种模式下,从库的每个 worker 线程将为指定的表复制 binlog 事件。这种模式使用基于行的复制方式,这种模式需要消耗更多的系统资源和存储空间。 -
TRANSACTION模式:在这种模式下,从库的每个 worker 线程将按照事务的顺序复制 binlog 事件。这种模式使用基于语句的复制方式,这种模式可能会导致锁等待和资源竞争等问题。slave_parallel_workers=4 stop slave SQL_THREAD; set global slave_parallel_type='LOGICAL_CLOCK'; start slave SQL_THREAD;
-
4. MySQL5.6基于schema的并行复制
slave-parallel-type=DATABASE ##不同库的事务,没有锁冲突
核心思想:
不同schema下的表并发提交时的数据不会相互影响,即slave节点可以用对relay log中不同的schema各分配一个类似SQL功能的线程,来重放relay log中主库已经提交的事务,保持数据与主库一致。
(1)优点
实现相对简单,对用户来说使用起来也简单
(2)缺点
由于是基于库的,并行的粒度非常粗,现在很多公司的架构是一库一实例,只有单schema,那么基于schema的复制就没什么用了。
还有主从事务的先后顺序也是。
5. 基于binlog group commit✨
5.7引入,用于在提交事务时将多个事务的 binlog 写入操作合并为一次写入,以减少磁盘 I/O 操作,提高 binlog 写入性能。
在 MySQL 8.0 及以上版本中,binlog group commit 已经成为默认的写入方式,不需要进行额外的设置。而在之前的版本中,需要通过设置 binlog_commit_wait_count 和 binlog_commit_wait_usec 参数来启用 binlog group commit 技术。
binlog_commit_wait_count: 指定了在自动提交事务时,需要等待写入到 binlog 文件中的事务数量。默认值为0,表示每次提交事务都会立即写入到binlog文件中。binlog_commit_wait_usec: 指定了在自动提交事务时,需要等待写入到 binlog 文件中的事务时间,单位为毫秒。默认值为0,表示每次提交事务都会立即写入到binlog文件中。
问题
哪些sql会被放在一个组里提交?假如1S之内提交了1000个事务,那这1000个事务都放在一个组里提交吗,还是有其他的规则
5.6版本后MySQL组提交引入队列机制保证 innodb commit顺序与binlog落盘顺序一致,并将事务分组,这个分组的数量通过 Binlog_group_commit_sync_no_delay_count 参数来限制,如果事务的数量提前达到了 Binlog_group_commit_sync_no_delay_count 参数设置的值,就不用继续等待了,就马上将 binlog 刷盘。
组内的binlog刷盘动作交给一个事务进行,实现组提交的目的。binlog提交将提交分为了3个阶段:
-
flush阶段:支撑 redo log 的组提交。
-
sync阶段:支持 binlog 的组提交。
-
commit阶段:承接 sync 阶段的事务,完成最后的引擎提交,使得 sync 可以尽早的处理下一组事务,最大化组提交的效率。
每个阶段都有一个队列,每个队列有一个mutex保护,预定进入队列的第一个线程为leader,其他线程为follower,所有事情交给leader去做,leader做完所有的动作之后,通知follower刷盘结束。
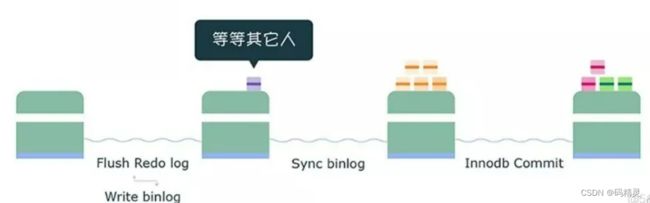
如果想提升 binlog 组提交的效果,可以通过设置下面这两个参数来实现:
binlog_group_commit_sync_delay= N,表示在等待 N 微妙后,直接调用 fsync,将处于文件系统中 page cache 中的 binlog 刷盘,也就是将「 binlog 文件」持久化到磁盘。
binlog_group_commit_sync_no_delay_count = N,表示如果队列中的事务数达到 N 个,就忽视binlog_group_commit_sync_delay 的设置,直接调用 fsync,将处于文件系统中 page cache 中的 binlog 刷盘。
如果在这一步完成后数据库崩溃,由于 binlog 中已经有了事务记录,MySQL会在重启后通过 redo log 刷盘的数据继续进行事务的提交。
commit 阶段
最后进入 commit 阶段,调用引擎的提交事务接口,将 redo log 状态设置为 commit。
可以通过以下两个参数查看事务是否在一个组内:
-
last_committed:- 相同值代表这些事务是在同一个组内
- 该值同时又是代表上一组事务的最大编号。
-
sequence_number:事务提交的序号,单调递增。

6. 基于writeset
当一个事务提交时,MySQL 8.0 会将该事务所修改的数据集合以writeset的形式记录在 binlog 中。在从库接收到该 binlog 事件时,可以快速地应用writeset,而无需在从库上执行事务的所有修改操作,从而提高了从库的数据复制性能。
在并行复制模式下,多个 worker 线程可以并行地从主库接收 binlog 事件,并同时应用writeset,从而提高了复制性能和并发性。
-
binlog_transaction_dependency_trackng=writeset表示开启依赖追踪功能,并使用
writeset作为事务依赖的追踪方式。- 默认是
COMMIT_ORDER,继续基于组提交方式 WRITESET:基于写集合决定事务依赖WRITESET_SESSION:基于写集合,但是同一个session中的事务不会有相同的last_commited
- 默认是
-
binlog_transaction_dependency_history_size=25000表示最多保存25000个事务的依赖追踪历史记录。
-
transaction_write_set_extraction=XXHASH64表示使用 XXHASH64 算法来处理事务的写集。
事务检测算法:MySQL会有一个变量来存储已经提交的事务HASH值,所有已经提交的事务所修改的主键(或唯一键)的值经过hash后都会与那个变量的集合进行对比,来判断改行是否与其冲突,并以此来确定依赖关系。
7. 如何让slave的并行复制和master的事务执行的顺序一致
5.7.19 之后,可以通过设置 slave_preserve_commit_order = 1
excecution阶段可以并行执行,binlog flush的时候,按顺序进行。 引擎层提交的时候,根据binlog_order_commit也是排队顺序完成。换句话说,如果设置了这个参数,master是怎么并行的,slave就怎么并行。
8. 万恶之源
innodb_thread_concurrency参数设置的太大了
该参数指定了InnoDB存储引擎在处理用户线程时,所允许的并发数。该参数的默认值为0,表示不限制并发线程数。
现象是:
- 机器不是很繁忙
- 但连接数非常多,thread_running非常高
- 一个简单的insert可能也慢
9. 并行复制推荐的参数

下一章我们讨论一下主从延迟原因和解决方法