Apache Pulsar 为滴滴大数据运维带来了哪些收益?
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体。该系统源于 Yahoo,最初在 Yahoo 内部开发和部署,支持 Yahoo 应用服务平台 140 万个主题,日处理超过 1000 亿条消息。Pulsar 于 2017 年由 Yahoo 开源并捐赠给 Apache 软件基金会进行孵化,2018 年成为 Apache 软件基金会顶级项目。
滴滴大数据于 2021 年 01 月开始调研 Pulsar ,建立内部 Pulsar 2.7 版本分支;并于 2021 年 08 月 04 日,正式上线了第一个 Pulsar 数据通道同步任务集群,主要为数据开发平台-同步中心产品提供服务,涉及 Log->ES、BamaiLog->ES、BamaiLog->CK、Log->HDFS 链路。截止目前,已稳定运行两年有余。
引入 Pulsar 的收益
滴滴大数据 DKafka 集群,基于社区 2.12-0.10.2.0 版本。在运维过程中,遇到了不少痛点,如磁盘 IO 不均、存储容量不均、CPU 利用率不均等负载不均问题,尤其是在高峰期出现瓶颈或故障发生后,想要快速扩容止损成为了一个棘手的问题。尽管团队已经在自动化运维方面做出了不少努力,比如实施了根据磁盘 IO 负载自动调整分区、批量自动迁移计划、以及存储自动负载均衡等措施,但仍需耗费大量的人力来维护这个重度运维的系统。
Pulsar 的出现,为滴滴大数据消息系统带来了新的可能性。特别是对于当前我们所遇到的痛点,Pulsar 提供了一些优雅的解决方案。
解决 SATA HDD 盘的磁盘 IO 瓶颈问题
DKafka 采用分段式 appendlog 顺序写入方式,将分区消息落盘。但是当 Broker 上有成百上千个 topic partition 时,由于需要切换分区消息写入到对应分区 log 文件,从磁盘角度看就变回了随机写入,磁盘读写性能将会随着 Broker 上 topic partition 数量的增加而降低,用户感知现象为生产/拉取耗时增涨。

DKafka 集群运维管理员接不完的 io 热点报警
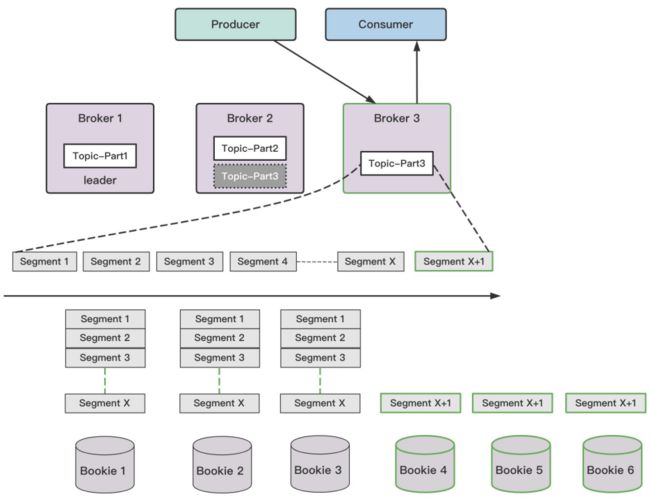
Pulsar 存算分离架构,存储层 Bookie 在存储数据时,通过将不同分区的消息在内存中排序后定期顺序刷盘到同一个entrylog 文件中,再通过 rocksdb 索引组织 entrylog 中的消息与分区 segment 的映射关系,解决随机写入问题。因此 Pulsar 号称可以支持百万分区,不会因为随机写而导致性能急剧下降。
解决集群容量瓶颈问题
针对 DKafka 集群中存在的 IO 瓶颈问题,数据通道团队自2020年至2021年间对线上集群进行了 SSD 机型置换。然而,除部分集群间的数据同步极端场景外,如磁盘故障后拉起服务,仍可能出现大量消息落盘行为集中在一台硬盘上的情况。考虑到 SSD 成本较高,团队决定降低集群存储容量,导致集群不再满足原有的3副本36小时存储周期要求。经过调研用户需求,团队决定将副本数调整为2,并将存储周期改为24小时,以满足大多数用户的需求。对于仍需更长存储周期的用户,可由用户发起申请,SRE 协助单独调整存储周期。尽管如此,仍然存在大量的磁盘热点/单机热点,需要 DKafka 集群运维管理员进行负载均衡。

DKafka 集群中多块盘存储容量达到瓶颈
由于 Pulsar 存储层在存储数据时,一定是顺序存储的,所以 Pulsar 机型在选型时,可以选择大容量 SATA HDD 盘 + NVME 异构机型,NVME 盘主要作为存储层 journal 和存储层 index 即内嵌 rocksdb 的存储介质。参照原 DKafka 的全 SSD 数据盘机型,Pulsar 存储异构机型,在降低成本的情况下,还能延长存储周期,增加副本数。
解决缓存 / IO 未隔离问题
在使用 DKafka 的过程中,重置 topic 的消费组 offset 是常见操作,但这会导致磁盘读取增加,进而加重磁盘 IO 的工作负载。由于 DKafka 的 IO 没有隔离,因此读取操作也会影响写入,从而导致读写耗时显著增长。此外,集群的扩容、缩容以及磁盘故障后屏蔽故障盘数据目录再上线的操作,也会对 pagecache 系统页缓存造成污染,导致更多的读消息 cache miss,进一步加重磁盘 IO 的工作负载。

DKafka 集群在数据迁移期间 p99 生产耗时受到显著影响
Pulsar的多级缓存特性为其无状态的计算层Broker将接收到的消息缓存在堆外内存中,同时这些消息也作为实时读缓存。当Broker中的cache miss发生时,会触发存储层的读取。存储层Bookie设计了多级缓存,包括只读的写缓存和读写的写缓存(后者写满时会触发切换)。如果这两块缓存都miss了,就会到读缓存中读取,如果读缓存也miss了,才会触发磁盘读取。磁盘读取完成后,会触发预读,预读的消息会被缓存在读缓存中。

Pulsar 多级缓存,绿色为命中缓存,黄色虚线为分区连续追赶读的第一次 cache miss 进行磁盘预读
(图片来源 Pulsar 社区)

Pulsar 存储层 IO 隔离
(图片来源 Pulsar 社区)
解决单盘/单机存储热点问题
DKafka 采用存算一体架构,分区与 Broker 紧密绑定,分区存储的分段消息文件在没有外部运维操作的情况下,与磁盘紧密绑定。此外,DKafka 在分配新建分区时,对磁盘相关指标的参考较少,仅排除存储和 IO 热点盘,且集群内部缺乏主动 rebalance 重调度分配分区的能力。这一问题可能导致集群中部分节点/节点中部分磁盘首先达到瓶颈,从而大幅增加运维难度。在容量评估时,也需要考虑这一特点,预留更多的 buffer。当集群中出现热点瓶颈时,需要逐一分区迁移(集群级机器存储热点)或切分区分段消息文件的存储目录(机器级磁盘存储热点),甚至可能需要根据所有消费组的延迟临时缩短 topic 存储周期来解决,这需要投入大量人力进行负载均衡工作,降低出现热点瓶颈的概率,提升集群利用率。如果集群中出现大面积消费延迟的情况,根据延迟进行缩短存储周期的自愈工作将无法开展,还需要联系用户确认丢失的数据或进行生产限流,以避免磁盘写满。

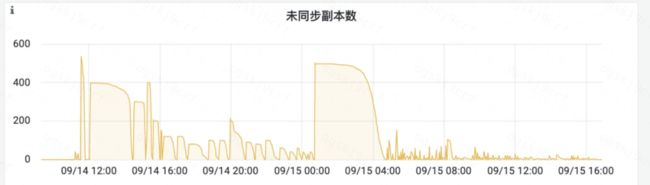
DKafka 集群存在存储热点,部分数据盘达到报警阈值,触发自愈,自动缩短占盘最大分区的 topic 存储周期
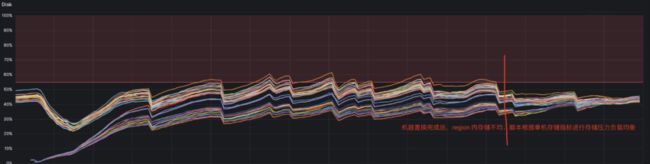
使用现有迁移工具进行机器置换&扩容完成后存储不均,需要再进行 region 内机器级存储均衡

DKafka 集群各块盘存储压力严重不均
Pulsar 的存算组件都是节点对等的,计算层的 topic 分区 segment 轮转切 ensemble 的 ledger rollover 特性使得可以从集群中重新选择存储节点;存储层则根据 ledger id 放置 entrylog 的特性来重新选择存储盘。Pulsar 从架构上进行改善,天然地将数据分散到不同存储节点中的不同数据目录下,这使得存储层 Bookie 集群基本上不需要人工干预存储相关的数据均衡工作,集群中所有数据盘的存储容量利用率差异基本控制在10%以内。值得一提的是,存储层的 ensemble 机制还可以让多副本的分区消息存储在比副本数更多的机器上,例如(5,3,2)配置,这意味着计算层将从存储层集群中选择5个 Bookie 节点进行分段消息的存储,每批 entry 会写到3个 Bookie 中,只要等待2个 Bookie 返回 ack,计算层 Broker 就完成了消息写入流程。
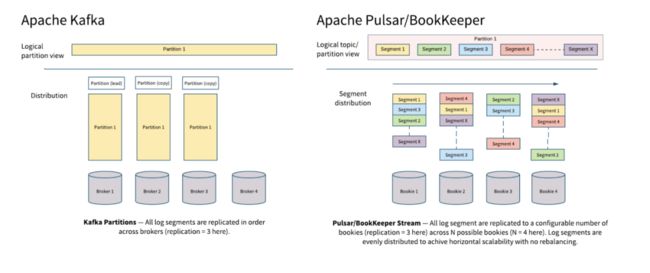
Pulsar 存算分离架构可实现将分段消息再进行分片存储,打散到不同 Bookie 节点
(图片来源 Pulsar 社区)
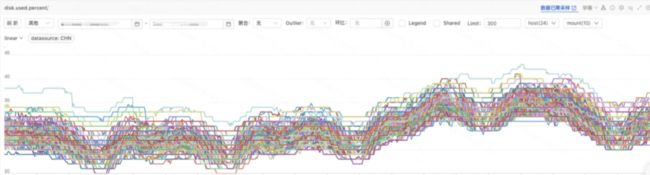
Pulsar 集群各块盘存储压力相对均衡
解决 topic 分区元数据多,rebalance 压力大问题
DKafka 集群分区数据多时,分区 leader rebalance 压力大,线上因此发生过分区无 leader 的故障,需要重启异常 Broker 和 controller 解决,对集群稳定性是非常大的挑战。
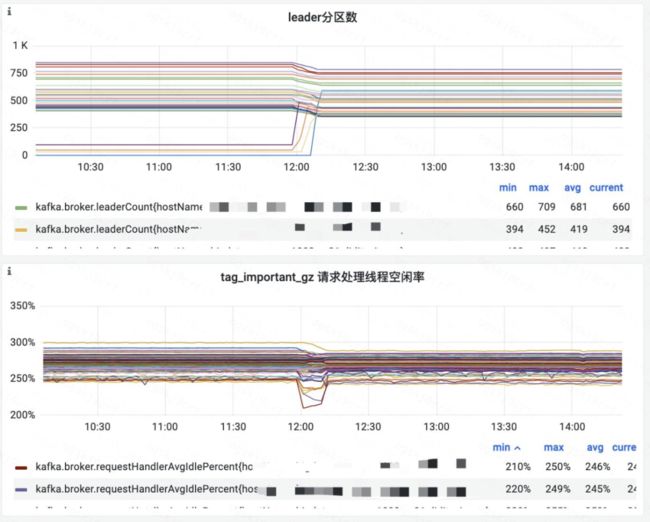
大量分区 leader rebalance 对集群的影响
Pulsar 计算层 Broker 无状态设计,可卸式的 topic 全集以哈希环的方式组成 bundle 集合;让每个 namespace 中的百万分区,通过有限个 bundle 提供服务(bundle 初始化数可控制,支持对半分裂),计算层 Broker 元数据大幅降低。
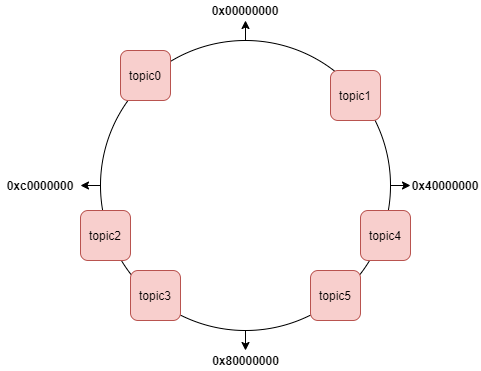
Pulsar 的每个 namespace 仅需要维护 hash 环上有限 个 bundle,大幅减少计算层元数据
(图片来源 Pulsar 社区)
解决负载均衡复杂度高,需要投入较多人力运维问题
目前,线上规模最大的 DKafka 广州 common 公共集群拥有 57485 个分区,但在有次护堤时出现了机器热点,表现为部分机器 CPU 空闲率低、机器负载高和网卡打满的情况。在这种情况下,集群并不会通过分区迁移来实现负载均衡和消除热点机器,而是通过调整分区 AR 顺序,然后执行分区优选副本切换 Leader 的操作,将热点机器上的分区 Leader 切换到低负载的其他机器上,以此来缓解集群热点对集群稳定性的影响。然而,如何选择热点机器上的哪些分区 Leader 进行切换是一项相对复杂的工作,需要根据导致热点的指标,综合考虑选择流量高、消费组多、QPS 高、存储周期长的 topic 分区列表,同时还需要考虑这些分区的 ISR 列表是否未同步,以及 ISR 列表中的其他 Broker 是否也是热点机器;只有在这些条件都不满足的情况下,才能进行分区 Leader 切换操作。
相比之下,Pulsar 的 bundle 机制大大降低了负载均衡的复杂度。由于计算层 Broker 节点对等,Broker 之间无需主从同步,计算层 Broker 可以向存储层 Bookie 进行条带化多副本写入。因此,计算层 Broker 的负载均衡只需要简单地 unload 热点机器上的 bundle,LeaderBroker 将会感知到没有 owner 的 bundle,然后根据集群指标挑选最优 Broker 进行分配,即可完成将落在哈希环中由此 bundle 提供服务的大量分区,一键漂移到其他 Broker 上提供服务,从而大幅提升运维效率。

Pulsar 通过 Bundle 漂移,高效均衡计算层负载
(图片来源 Pulsar 社区)
解决集群扩缩容复杂度高和对集群影响大的问题,以及确保高峰期和故障时能够进行扩容。
DKafka 的扩缩容流程较为复杂,需要进行分区迁移工作。在重大节假日活动期间,还需要根据预估的容量提前进行扩容和分区迁移均衡工作,这个过程耗时较长,耗费人力较多;并且在完成迁移后,还需要进行大量的负载均衡以解决热点瓶颈问题。在遇到突发事件导致流量突增时,DKafka 只能通知上游降级并对 topic 的生产者进行限流,等到突增流量或高峰期过后,再在低峰期进行分区迁移或扩容。此外,之前提到的缓存/IO未隔离问题中的 pagecache 污染问题也表明,扩缩容对集群的影响较大。
缩容操作需要对下线 Broker 上的所有分区进行迁移
相比之下,Pulsar 的无痛扩容功能通过卸载集群中相对热点的 Broker 上的 bundle,并让其自动重分配到集群中的其他 Broker 上,从而实现计算层的负载均衡;对于存储层的 Bookie 扩容,只需启动服务,待集群运行一段时间后,计算层的 topic 分区的 segment 轮转切 ensemble,将存储层低负载节点逐渐利用起来,实现新老节点负载的双向奔赴。基于 Pulsar 的这些特点,它彻底解决了 DKafka 集群在高峰期/故障期间无法进行扩容的问题,这对于集群大面积故障后的快速恢复是一个重大提升。对于缩容场景,只需要在保证集群容量充足的情况下,将 Broker 节点逐台停止,并将预下线的 Bookie 节点设置为 Readonly 状态。待 Bookie 上的 Ledger 都过期后,即可下线这些 Bookie 节点。在提前 Readonly 并完成 Ledger 过期的情况下,每个 Bookie 节点的缩容过程可以在1分钟内完成。

Pulsar 计算层 Broker 将 Bundle 漂移到新扩容到 Broker 上,让扩容的机器立刻能够提供计算能力
(图片来源 Pulsar 社区)
Pulsar 存储层 Bookie 扩容后不需要做任何操作,当计算层分片写满后轮转,写入新的分片时,将会选一批负载低的 Bookie 集合来存储新的分段消息
(图片来源 Pulsar 社区)

Pulsar 存储层 Bookie 扩容后,随着时间推移,新老节点间的负载均衡变化
故障模拟,具体分析 Pulsar 带来的收益
根据上述分析,让我们进行一次故障模拟,以了解Pulsar 如何解决 DKafka 的痛点以及在 Pulsar 出现故障时的处理方式:目前,线上 DKafka 的大部分集群使用的是 SSD 数据盘机型,为控制成本,日常存在机器级磁盘存储热点问题。当 odin 监控出现故障时,由于无法感知故障发生,自愈系统无法进行存储周期缩短工作,可能导致集群的多台 Broker 数据盘存储打满,进而引发多台 Broker 挂掉的故障。由于未能及时感知故障的发生,故障时间可能会持续数十分钟。即使在此情况下拉起故障的 Broker,还可能面临以下问题:
Q1:剩余的这些 Broker 将有更多分区以 leader 角色对客户端提供生产/消费以及故障节点启动后的副本数据同步,加重机器热点情况。而解决机器热点的切分区 leader 操作流程复杂,粒度过小且没有自动化。
A1:Pulsar 通过快速扩容或计算层的 bundle unload / split_unload 解决热点,粒度大且负载均衡的自动化程度高。
Q2:一大波生产流量积压,将对剩余 Broker cpu/网络带宽/磁盘 io 造成冲击,出现集群容量严重不足的情况,并且 DKafka 无法在集群存在瓶颈时进行分区迁移,意味着无法进行集群扩容变更。
A2:Pulsar 节点对等特点,无状态特点,计算层可以快速完成负载均衡,存储层通常不存在热点,即使有热点也可以通过临时 readonly 节点或者快速扩容解决。
Q3:挂掉的 Broker 上的分区 follower 需要从分区 leader 同步数据,将对分区 leader Broker 的 pagecache 进行污染,除了同步数据的读盘操作,还将因 pagecache 污染,造成更多的消费消息读盘操作,用户感知现象为生产/消费耗时增涨。由于上述提及的网卡流出瓶颈,部分分区可能永远无法完成同步(内部优化策略,优先保生产,在大面积故障场景下是负优化),这又加剧了 pagecache 污染持续时间。
A3: Pulsar 存算组件节点对等无需同步数据,计算层条带化写入存储层,并且有多级缓存;另参照上述【缓存 / IO 未隔离问题】
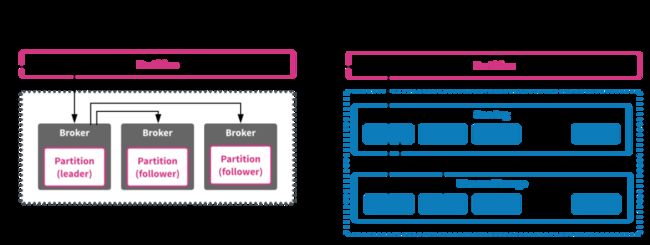
DKafka 主从架构,分区 follower 需要从分区 leader 同步数据;Pulsar 存算分离架构,由 Broker 进行条带化写入 Bookie
(图片来源 Pulsar 社区)
Q4:由于 DKafka 存算一体的架构,无法通过扩容快速进行负载均衡,只能进行生产限流。用户感知现象为数据不及时。在数据通道场景中,极端情况下,限流可能导致数据不完整,如日志在宿主机上保留时间短或程序未 catch 这类异常情况而直接丢弃,用户感知现象为丢失一段时间数据,如看板指标某段时间跌 0,查不到某段时间订单,查不到某段时间日志等。
A4:Pulsar 通过快速扩容解决,计算层负载均衡手段通过 unload bundle,存储层 Bookie 扩容后不需进行任何操作。
Q5:集群中部分分区 ar 都分配在磁盘打满的故障节点上,部分分区无法提供消息生产能力,导致磁盘上数据过期丢失
A5:Pulsar 计算层无状态的设计,计算层自动进行 bundle 故障转移,让剩余 Broker 继续为故障 Broker 上的分区提供服务;计算层还能够通过对 topic 分区 segment 切 ensemble 列表进行存储层故障转移,可以做到服务生产不中断;需要注意的是存储层故障节点容忍数为 ensemble ack quorum -1,副本数为 0 的 segment 可能导致 Broker 无法加载部分分区。最后存储层 Bookie 还支持配置存储高水位拒绝写入和 readonly 方式启动,即便是存储容量不足的情况下,也是可以通过快速扩容写入新数据 + readonly 读取老数据的方式,平稳渡过这次故障。

Pulsar 计算层故障,节点对等特性支持无痛转移故障节点上的计算负载,集群能够持续提供消息生产能力
(图片来源 Pulsar 社区)

Pulsar 存储层,节点对等特性,从架构层面优化,做到更高的可用性
(图片来源 Pulsar 社区)
总结
从上述问题和故障案例中,我们可以看出 Pulsar 在存算分离架构方面的改进,结合缓存/IO隔离、节点对等、计算节点的无状态设计、Bundle 机制以及 Ensemble 机制,有效地解决了 DKafka 集群在日常运维过程中遇到的问题,显著提升了消息系统集群运维管理员的运维体验。然而,Pulsar 在架构上的复杂性以及引擎监控指标的数量级关系上,与 DKafka 相比也有显著的增长。这对引擎研发和运维人员来说,无疑是一个更大的挑战。
数据夜谈
聊聊看,你们在大数据消息系统运维有遇到哪些问题,是如何解决的?如需与我们进一步交流探讨,也可直接私信后台。
作者将选取1则最有意义的留言,送出暖暖保温杯一个。1月16日晚9点开奖。
