快速排序详解


.
专栏:数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
- 介绍
- 什么是快速排序
- 基本思想
- 快速排序hoare版本
-
- 动图
- 代码实现
- 代码的详细解释:
- 快速排序挖坑法
-
- 动图
- 代码实现
- 代码的详细解释:
- 快速排序前后指针法
-
- 动图
- 代码实现
- 代码的详细解释:
- 快速排序实现
-
- 代码实现
- 代码的详细解释
- 快速排序非递归实现
-
- 代码实现
- 代码的详细解释
- 三数取中
- 性能和复杂度分析
-
- 时间复杂度:
- 空间复杂度:
- 完整代码
- 总结
介绍
排序算法是一个重要的主题。快速排序是一种经典的基于比较的排序算法,以其高效性而著称。本博客将深入介绍快速排序算法的基本思想,并探讨其三种不同的实现方法:Hoare分区、挖坑法和指针法。我们将逐步解释每一种实现方式,展示其工作原理以及如何选择适当的实现方法。
什么是快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
基本思想
快速排序的基本思想可以通过一个实例来说明。假设我们有一个包含数字3、6、8、10和2的数组。首先,我们选择数字6作为枢轴元素。然后,我们将数组划分为两个子数组:一个包含小于6的元素(即3、2),另一个包含大于6的元素(即8、10)。现在,我们只需要对这两个子数组进行排序,就可以得到最终的排序结果(即2、3、6、8、10)。
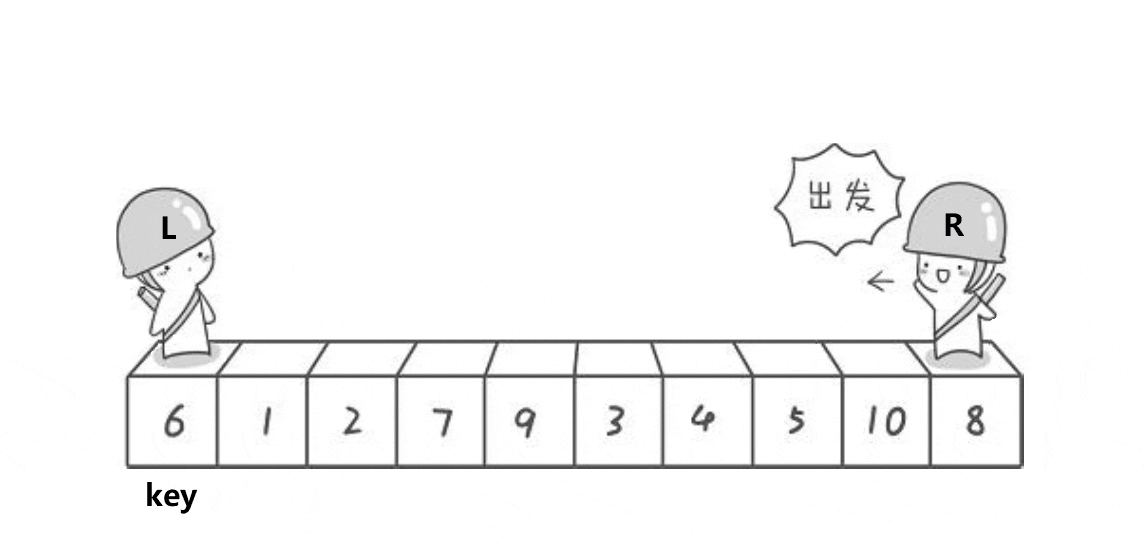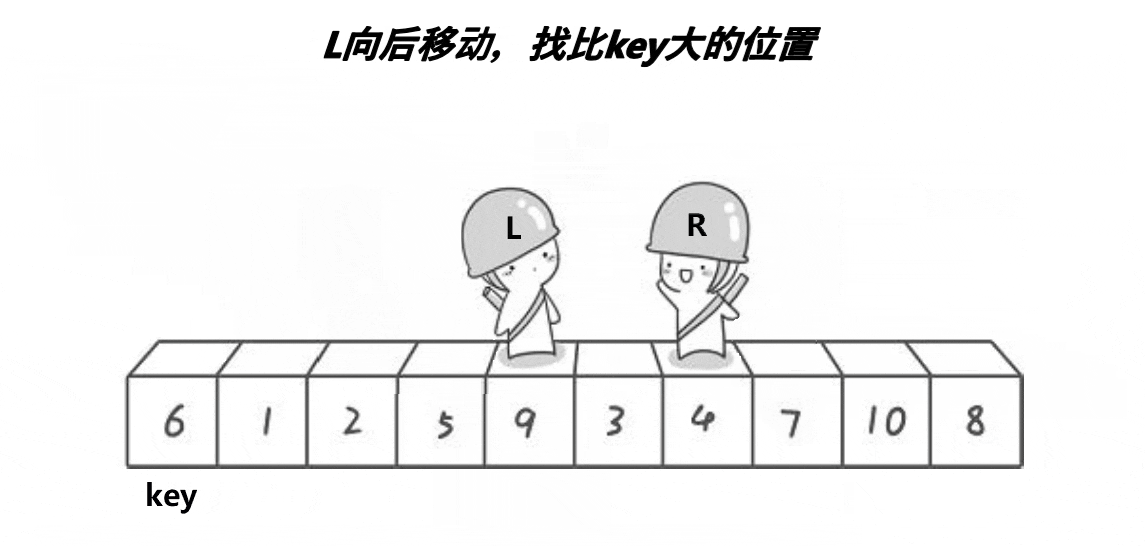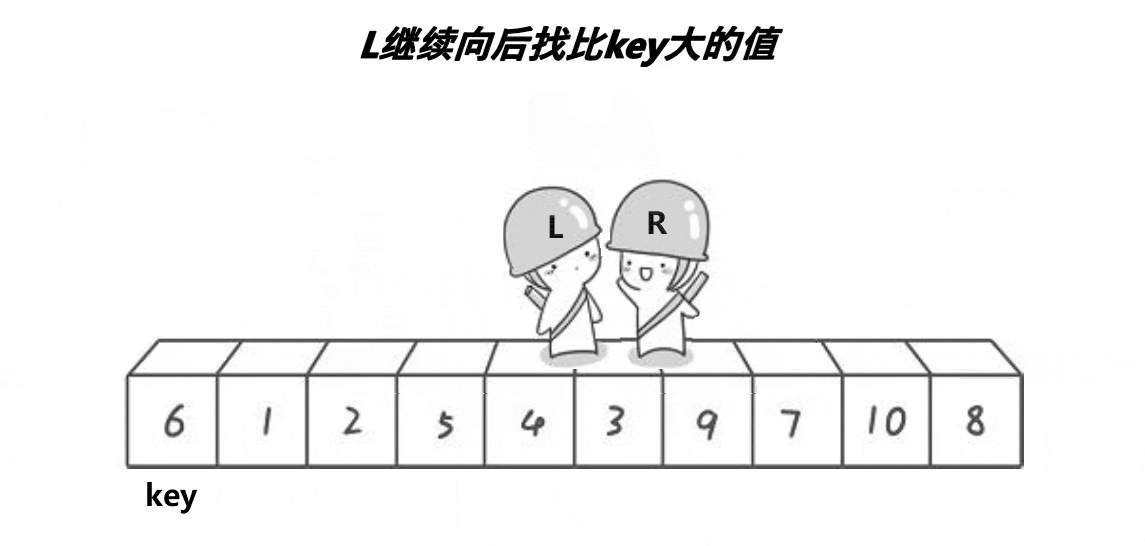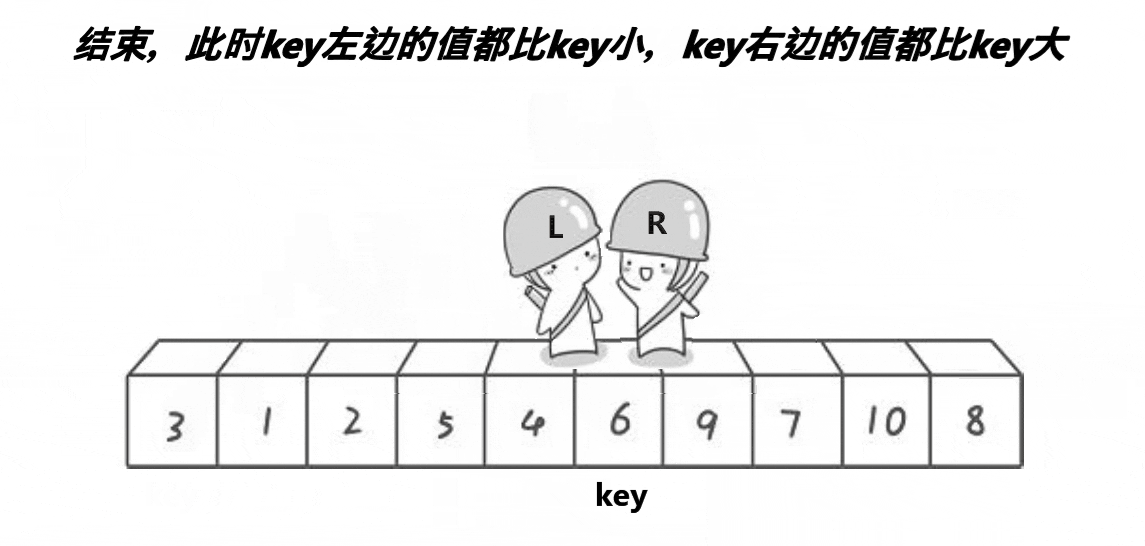
快速排序hoare版本
动图
代码实现
int PartSort1(int* a, int begin, int end)
{
// 选择中间值作为枢轴
int midi = GetMidi(a, begin, end);
// 将枢轴元素交换到数组的起始位置
swap(&a[begin], &a[midi]);
// 初始化关键元素和左右指针
int key = begin;
int left = begin;
int right = end;
// 进行分区
while (left < right)
{
// 从右侧找到第一个小于枢轴的元素
while (left < right && a[right] >= a[key])
{
--right;
}
// 从左侧找到第一个大于枢轴的元素
while (left < right && a[left] <= a[key])
{
++left;
}
// 交换左右两侧找到的元素
swap(&a[left], &a[right]);
}
// 将枢轴元素交换到最终的位置
swap(&a[left], &a[key]);
// 返回枢轴的位置
return left;
}
这段代码是快速排序算法的Hoare分区实现。Hoare分区是一种在数组中划分元素的方法,使得所有比枢轴元素小的元素都在其左侧,所有比枢轴元素大的元素都在其右侧。
代码的详细解释:
选择中间值作为枢轴: 使用
GetMidi函数选择数组的中间值作为枢轴,这是一种常见的选择方式。
将枢轴元素交换到数组的起始位置: 通过
swap函数,将选定的枢轴元素与数组的起始位置进行交换,以便后续分区操作。
初始化关键元素和左右指针: key 变量用于存储枢轴元素最初的位置,
left和right分别是左右指针,用于在数组中移动。
进行分区: 使用
left和right从数组的两端开始向中间移动,找到需要交换的元素对。right指针找到第一个小于枢轴的元素,left指针找到第一个大于枢轴的元素,然后交换它们。
将枢轴元素交换到最终的位置: 在分区结束后,将枢轴元素放置到最终的位置,以确保左侧元素都小于等于枢轴,右侧元素都大于等于枢轴。
返回枢轴的位置: 返回最终放置枢轴的位置,该位置将用于递归调用,将数组分成两个子数组进行排序。
这个函数的核心思想就是通过不断移动左右指针,找到需要交换的元素对,实现数组的分区。这种方法是Hoare分区的经典实现方式。
快速排序挖坑法
动图
代码实现
int PartSort2(int* a, int begin, int end)
{
// 基准情况:当开始位置大于等于结束位置时,表示数组已有序
if (begin >= end)
{
return;
}
// 选择中间值作为枢轴
int midi = GetMidi(a, begin, end);
// 将枢轴元素交换到数组的起始位置
swap(&a[begin], &a[midi]);
// 记录枢轴元素的值
int key = a[begin];
// 初始化坑的位置
int hole = begin;
// 进行分区
while (begin < end)
{
// 从右侧找到第一个小于枢轴的元素
while (begin < end && a[end] >= key)
{
end--;
}
// 将找到的元素填入坑中
a[hole] = a[end];
hole = end;
// 从左侧找到第一个大于枢轴的元素
while (begin < end && a[begin] <= key)
{
begin++;
}
// 将找到的元素填入坑中
a[hole] = a[begin];
hole = begin;
}
// 将枢轴元素放入最终的坑中
a[hole] = key;
// 返回枢轴的位置,用于递归调用
return hole;
}
代码的详细解释:
基准情况: 开始位置
begin大于等于结束位置end时,表示数组已有序,直接返回。
选择中间值作为枢轴: 使用
GetMidi函数选择数组的中间值作为枢轴,这是一种常见的选择方式。
将枢轴元素交换到数组的起始位置: 通过
swap函数,将选定的枢轴元素与数组的起始位置进行交换,以便后续分区操作。
记录枢轴元素的值和初始化坑的位置:
key变量用于存储枢轴元素的值,hole变量初始化为枢轴的位置begin。
进行分区: 使用
begin和end从数组的两端开始向中间移动,找到需要填入坑的元素对。end找到第一个小于枢轴的元素,begin找到第一个大于枢轴的元素,然后将它们填入坑中。
将枢轴元素放入最终的坑中: 分区结束后,将枢轴元素放入最终的坑中,以确保左侧元素都小于等于枢轴,右侧元素都大于等于枢轴。
返回枢轴的位置: 返回最终放置枢轴的位置,该位置将用于递归调用,将数组分成两个子数组进行排序。
这段代码中的挖坑法思想通过标记“坑”位置,巧妙地避免了大量的元素交换操作,提高了效率。
快速排序前后指针法
动图
代码实现
int PartSort3(int* a, int begin, int end)
{
// 选择中间值作为枢轴
int midi = GetMidi(a, begin, end);
// 将枢轴元素交换到数组的起始位置
swap(&a[begin], &a[midi]);
// 初始化关键元素和指针
int key = begin;
int prev = begin;
int cur = prev + 1;
// 进行分区
while (cur <= end)
{
// 如果当前元素小于枢轴,并且prev自增后不等于cur
if (a[cur] < a[key] && prev++ != cur)
{
// 交换当前元素与prev指向的元素
swap(&a[prev], &a[cur]);
}
// 移动当前指针
cur++;
}
// 将枢轴元素交换到最终的位置
swap(&a[key], &a[prev]);
// 更新枢轴的位置
key = prev;
// 返回枢轴的位置,用于递归调用
return key;
}
代码的详细解释:
选择中间值作为枢轴: 使用
GetMidi函数选择数组的中间值作为枢轴,这是一种常见的选择方式。
将枢轴元素交换到数组的起始位置: 通过
swap函数,将选定的枢轴元素与数组的起始位置进行交换,以便后续分区操作。
初始化关键元素和指针:
key变量用于存储枢轴元素最初的位置,prev和cur分别是前一个指针和当前指针,用于在数组中移动。
进行分区: 使用两个指针从数组的左侧向右侧移动,找到需要交换的元素对。当当前元素小于枢轴时,将其与
prev指向的元素进行交换,同时prev自增。
将枢轴元素交换到最终的位置: 在分区结束后,将枢轴元素放入最终的位置,以确保左侧元素都小于等于枢轴,右侧元素都大于等于枢轴。
返回枢轴的位置: 返回最终放置枢轴的位置,该位置将用于递归调用,将数组分成两个子数组进行排序。
这段代码中的指针法通过使用两个指针来遍历数组,避免了大量的元素交换操作,提高了效率。
快速排序实现
代码实现
void QuickSort(int* a, int begin, int end)
{
// 基准情况:当开始位置大于等于结束位置时,表示数组已有序或为空,直接返回
if (begin >= end)
{
return;
}
// 使用 PartSort1 函数进行分区,得到枢轴位置 key
int key = PartSort1(a, begin, end);
// 递归对枢轴左侧的子数组进行排序
QuickSort(a, begin, key - 1);
// 递归对枢轴右侧的子数组进行排序
QuickSort(a, key + 1, end);
}
代码的详细解释
基准情况: 当开始位置
begin大于等于结束位置end时,表示数组已有序或为空,直接返回,作为递归的终止条件。
使用
PartSort1函数进行分区: 调用PartSort函数对当前子数组进行分区,得到枢轴位置key。PartSort1函数用于划分数组,这是快速排序的核心之一。
递归排序左右子数组: 对枢轴左侧的子数组和右侧的子数组分别进行递归排序。递归调用
QuickSort函数。
这段代码实现了快速排序的递归版本。通过不断划分和排序子数组,最终整个数组变得有序。这是一种高效的排序算法,适用于大规模数据。
快速排序非递归实现
代码实现
void QuickSortNonR(int* a, int begin, int end)
{
// 初始化堆栈
Hp s;
HeapInit(&s);
// 将初始的开始位置和结束位置压入堆栈
HeapPush(&s, end);
HeapPush(&s, begin);
// 非递归循环
while (!HeapEmpty(&s))
{
// 弹出堆栈中的左右位置
int left = HeapTop(&s);
HeapPop(&s);
int right = HeapTop(&s);
HeapPop(&s);
// 使用 PartSort3 函数进行分区,得到枢轴位置 key
int key = PartSort3(a, left, right);
// 将枢轴左侧的子数组入栈
if (left < key)
{
HeapPush(&s, key - 1);
HeapPush(&s, left);
}
// 将枢轴右侧的子数组入栈
if (key + 1 < right)
{
HeapPush(&s, right);
HeapPush(&s, key + 1);
}
}
// 销毁堆栈
HeapDestroy(&s);
}
代码的详细解释
初始化堆栈: 使用
HeapInit函数初始化堆栈 s。
将初始的开始位置和结束位置压入堆栈: 将数组的开始位置
begin和结束位置end压入堆栈,表示初始的待排序子数组。
非递归循环: 进入循环,直到堆栈为空。每一次循环弹出左右位置,进行分区,然后将分区后的子数组的左右位置再次压入堆栈,实现对子数组的非递归排序。
使用
PartSort3函数进行分区: 调用PartSort3函数对当前子数组进行分区,得到枢轴位置 key。
将枢轴左侧的子数组和右侧的子数组入栈: 将枢轴左侧的子数组和右侧的子数组的左右位置依次压入堆栈,以便后续对它们的排序。
销毁堆栈: 在算法结束后,销毁堆栈。
这段代码通过堆栈模拟递归调用,实现了快速排序的非递归版本。这样的实现方式避免了递归可能引起的栈溢出问题,提高了算法的鲁棒性。
三数取中
int GetMidi(int* a, int begin, int end)
{
// 计算三个位置的中间位置 midi
int midi = (begin + end) / 2;
// 比较 a[begin] 和 a[midi] 的大小
if (a[begin] < a[midi])
{
// 如果 a[begin] < a[midi],则继续比较 a[midi] 和 a[end] 的大小
if (a[midi] < a[end])
{
// 如果 a[midi] < a[end],则 midi 是中值
return midi;
}
else if (a[begin] > a[end])
{
// 如果 a[begin] > a[end],则 begin 是中值
return begin;
}
else
{
// 否则,end 是中值
return end;
}
}
else // a[begin] > a[midi]
{
// 如果 a[begin] > a[midi],则继续比较 a[midi] 和 a[end] 的大小
if (a[midi] > a[end])
{
// 如果 a[midi] > a[end],则 midi 是中值
return midi;
}
else if (a[begin] < a[end])
{
// 如果 a[begin] < a[end],则 begin 是中值
return begin;
}
else
{
// 否则,end 是中值
return end;
}
}
}
这个函数的目的是在快速排序中选择一个中值,以作为枢轴的索引。中值的选择可以帮助提高快速排序的性能,确保分区相对均衡。
性能和复杂度分析
在选择排序算法时,我们通常关心其性能和复杂度。快速排序在平均情况下表现优异,但也有一些需要注意的地方。让我们深入分析快速排序的平均时间复杂度、最坏时间复杂度和空间复杂度,并将其与其他排序算法进行比较。
时间复杂度:
快速排序是一个典型的比较排序算法,其平均时间复杂度为O(n log n)。在最坏的情况下,它的时间复杂度也是O(n log n)。这是因为快速排序是基于分治策略的,每次递归调用都会将问题规模减半,直到子问题规模足够小(通常为1或2)。
空间复杂度:
快速排序的空间复杂度取决于实现方式。递归版本需要O(log n)的额外空间(用于堆栈)。非递归版本使用一个额外的数据结构(如堆)来模拟递归调用,需要O(1)的空间。
快速排序是一种平均时间复杂度较低的排序算法,但在最坏情况下可能退化为O(n^2)。递归版本和非递归版本的空间复杂度都取决于递归调用的深度,因此为O(log n)。
| 算法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 快速排序 | O(n^2) ~ O(n log n) | O(log n) |
完整代码
可以来我的github参观参观,看完整代码
路径点击这里–>所有排序练习
总结
通过代码片段、图表、图示等元素,以清晰而详细的方式表达了每个概念,使读者能够更好地理解和跟随解释。排序算法,这是一种基于比较的排序算法,以其高效性而著称。我们介绍了快速排序的基本思想,并详细讨论了三种不同的实现方法:Hoare分区、挖坑法和指针法。