2 分 31 秒,腾讯云创造 128 卡训练 ImageNet 新记录


来源 | 腾讯云
编辑 | 白峰
转自 | 新智元
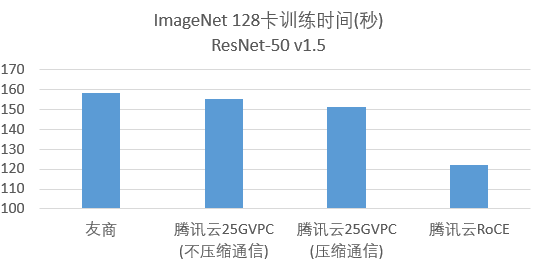
8月21日,腾讯云正式对外宣布成功创造了128卡训练ImageNet业界新记录,以2分31秒的成绩一举刷新了这个领域的世界记录。
刷新世界纪录:2分31秒完成 ImageNet训练
基于腾讯公有云25Gbps的VPC网络环境,使用128块V100,借助Light大规模分布式多机多卡训练框架,在2分31秒内训练 ImageNet 28个epoch,TOP5精度达到93%,创造128卡训练imagenet 业界新记录。
若跨机网络改为RoCE,则训练时间进一步减少到2分2秒。之前业界同样使用128块V100的最好结果是友商的2分38秒。
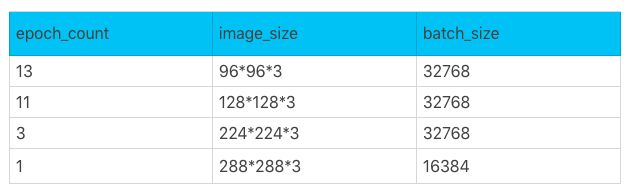
28个epoch分别是:
模型越来越大,算力需求暴涨
在AlexNet[3]网络模型出现后的过去几年中,ResNet[4]、Transformer[5]、BERT[6]等优秀模型相继出现,深度学习有了长足的发展和进步,尤其是在图像、语音、机器翻译、自然语言处理等领域带来了跨越式提升。
在AlphaGo使用深度学习方法战胜世界围棋冠军李世石之后,近期拥有1750亿海量参数,堪称“通用语言智能的希望”——GPT-3[7]的出世,再一次点燃了大家对人工智能未来的期望。但与之相伴的也有很多问题:
数据量大。随着互联网上可使用数据资源愈加丰富,模型训练使用的数据集往往越来越大。GPT-3模型训练则使用了高达45TB的数据量,使得多轮训练时数据读取成为非常耗时的部分。
计算模型复杂。深度网络的一个特点就是结构越深、越复杂,所表达的特征就越丰富,在此思想下,最新的网络结构越来越复杂,从AlexNet的8层,VGG-19的19层,ResNet-50的50层,到Inception-ResNet-V2的467层和ResNet-1000的1202层等。
参数量大。深度神经网络由于层次很多,参数量往往很大。ResNet-50有2500万参数量,AlexNet有6200万的参数量,而VGG-16参数量则达到1.38亿,BERT-Large参数量高达3亿,而GPT-3语言模型的参数量甚至超过1750亿。
超参数范围广泛。随着模型复杂度的提升,模型中可供调节的超参数数量及数值范围也在增多。例如,在CIFAR-10数据集上训练的ResNet模型有16个可调的超参数,当多数超参数的取值为连续域的情况下,如此少量的超参数仍然可能造成组合爆炸。
训练时间长。随着深度学习模型越来越复杂,对算力的需求也越来越高(2012年到2018年,对算力的需求增长2000倍+ )。ResNet-50 训练 ImageNet 128 万张图片 90 个 epoch 可以达到 76.5% 的 Top-1 精度,用一块 V100 的 GPU 需要大概1天多的时间,而各大厂都分别施展了各自的大规模分布式训练大法来缩短该标杆的训练时间。腾讯机智团队在2018年7月在ImageNet数据集上,用4分钟训练好AlexNet,6.6分钟训练好ResNet50,创造了当时AI训练世界新纪录[1]。
如何做高性能AI训练和计算,关乎到AI生产研发效率,对于AI产品的迭代效率和成功至关重要。高效训练的一个baseline是在更短时间内做ImageNet训练。腾讯云希望AI技术能成为普惠的技术帮助人们生活更便捷,通过向客户提供高效的AI生产工具,AI高效训练可以触手可及。
但是要做好高效的AI生产工具,需要做大量的工作,也充满挑战。接下来将从具体挑战,联合团队的解决方案,及最终效果几个方面来陈述,并最终通过2分31秒训练ImageNet这个案例为典型case来呈现成果。
多机多卡难扩展,调参耗时难收敛
数据供给制约计算
深度学习训练数据输入管道包括以下三个部分:从硬盘上读取数据-解析与数据预处理-拷贝到GPU,数据输入管道与计算部分并行执行,为保证GPU能专心来进行模型训练,数据输入部分使用 CPU来进行。但随着GPU性能的提高,计算时间越来越短,CPU,内存,网络带宽开始成为训练时的瓶颈,数据供给也成为训练效率的关键一环。
TCP网络下的多机多卡扩展性差
随着GPU硬件的不断升级,GPU的计算速度一直在提升,加上XLA和混合精度等技术也大大提升了单卡的计算速度。NVLink2使单机内部的AllReduce速度有了大幅提升,超过了120GB/s。但腾讯云的VPC网络只有25Gbps,与单机内的通信带宽有着明显的差异。再加上TCP环境下,跨机通信的数据需要从显存拷到主存,再通过CPU去收发数据,除了实际网络收发数据的延迟,还有很大的额外延迟,所以通信时间更长了。计算时间短加上通信时间长,使得多机多卡的扩展性受到了很大的挑战。
大batch收敛难
为了充分利用大规模集群算力以达到提升训练速度的目的,人们不断的提升训练的batch size,这是因为更大的batch size允许在扩展GPU数量的同时不降低每个GPU的计算负载。
然而,只增大batch size会对精度带来影响和损失。这是因为在大batch size(相对于训练样本数)情况下,样本随机性降低,梯度下降方向趋于稳定,训练就由SGD向GD趋近,这导致模型更容易收敛于初始点附近的某个局部最优解,从而抵消了计算力增加带来的好处。如何既增大batch size,又不降低精度,是另一个重大挑战。
超参数选择多
超参数的选择对模型最终的效果有极大的影响,但由于超参较多,而每一个超参分布范围较广,使得超参调优的耗时较长,特别是针对ImageNet这种大数据集的情况。如何快速寻找到较优解,是另一个重大挑战。
解决方案
联合团队研发了 Light大规模分布式多机多卡训练框架来进行高效训练,并将能力平台化。
单机训练速度优化
1)分布式缓存与数据预取
由于训练数据一般保存在分布式存储,而分布式存储机器和训练机器并不在一个集群。为了加速访问远端存储的数据,团队利用GPU母机的SSD盘/内存,在训练过程中为训练程序提供数据预取和缓存。
2)自动调整最优数据预处理线程数
在预设的运行程序中,每个进程会分配大量线程用于数据预处理。仅仅在数据预处理上,单机8卡就会分配数百个线程。大量的线程的相互抢占导致了cpu运行效率低下,同时也会与tensorflow的OP调度线程争抢而出现OP无法正常并行的问题。
因此团队根据经验和采集运行时信息自动设置最优数据预处理线程数,降低cpu的切换负担,同时也让数据预处理可以和gpu计算并行。
3)本地预解码图片缓存
对于小图片,由于每个迭代步的计算时间少,单位时间需要处理的图片变多,cpu负载仍然过大,导致性能较差。经过分析后发现,JPEG图片解码为制约性能的主要部分。为了解决这个问题,团队预先将数据集中的JPEG图片解码,计算时直接加载解码数据,缓存在内存中,从而直接去除这部分计算压力。
LightCC高效扩展多机训练

1)自适应梯度融合技术优化通信时间
针对小数据块通信问题,通过将小数据块融合成大数据块的方式,减少了通信次数,降低了通信延迟,提升了通信效率。但当应用了XLA技术后,由于TensorFlow中XlaOp的同步性,使得通信需等待编译优化所融合的所有计算完成,导致计算通信无法很好的overlap,为解决这个问题,团队进一步提出了自适应梯度融合技术,根据编译优化的结果自适应的选择梯度融合的阈值,从而达到更好的overlap。

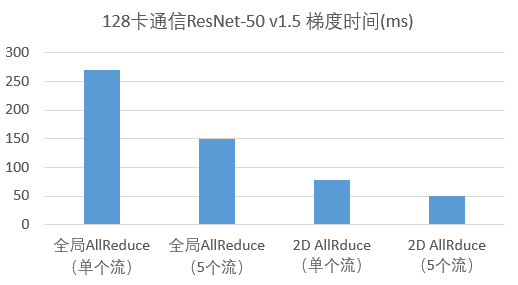
2)层级通信+多流提升带宽利用率
TCP网络下全局AllReduce,除了网络收发包的时间,还有很大的额外延时,导致带宽利用率不高。
针对这个问题,团队使用了2D通信[2]和多流来提升网络收发的并发性,从而提升带宽的利用率。以单机有8块卡的机型为例,2D通信在TCP网络下有不错的效果,主要是因为可以8块卡同时做跨机通信,从而竞争带宽资源,带宽空闲的时间更少,而且跨机通信时建立的环上的节点数只有总节点数的1/8,所以每块卡做跨机通信的次数比全局AllReduce时少得多。多流又使得多个梯度的2D通信可以形成流水线,既某个梯度在做单机内通信时没有利用到网络带宽,这时其它梯度的跨机通信可以填补网络带宽的间隙。
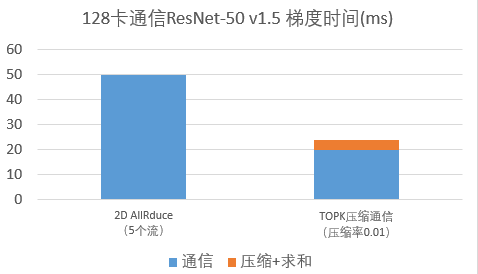
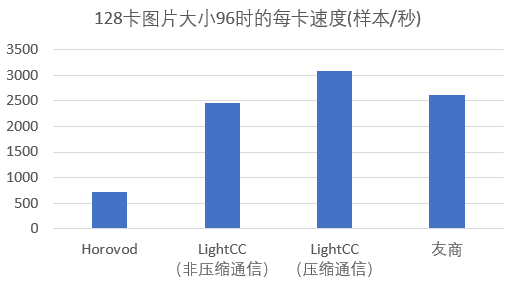
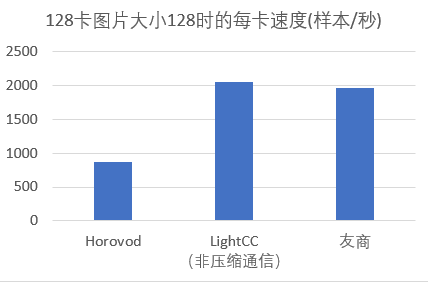
ResNet-50 v1.5的参数量大概是25M个FP32,如果通信时转成FP16,则通信的梯度大小大概是50MB,但因为AllReduce的通信量大概是梯度大小的2倍,所以通信量大概是100MB。通信时间如下图所示。
3)层级topk压缩通信算法减少通信量,突破带宽瓶颈
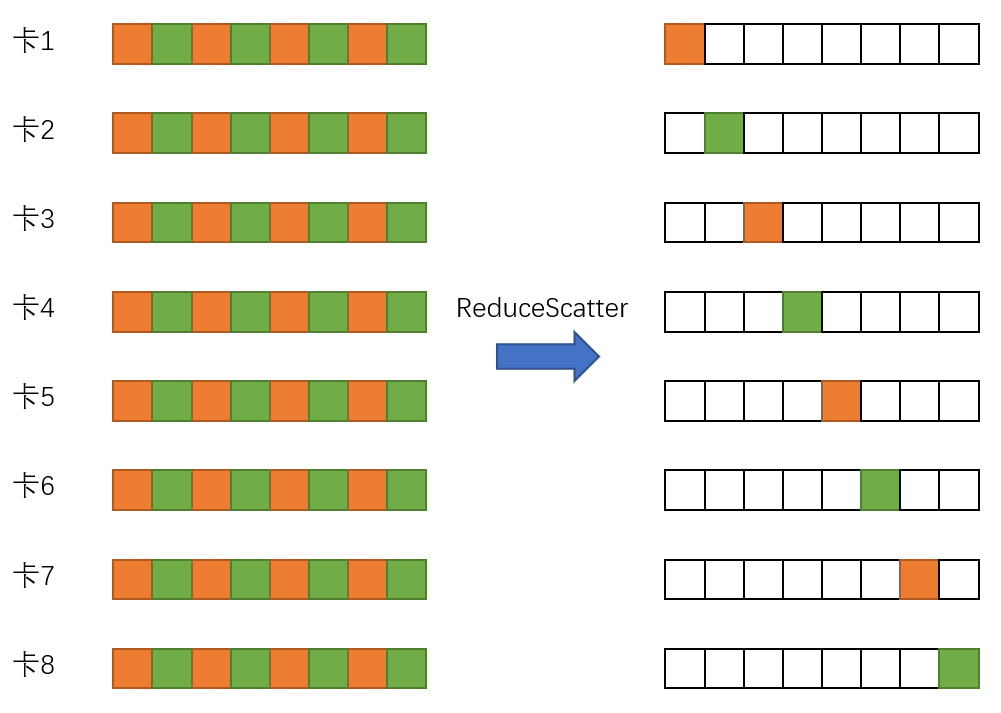
因为网络带宽得到充分利用之后,通信还是瓶颈,为进一步提高扩展性,团队引入了梯度压缩通信技术[8]。梯度压缩通信的做法是每张卡对要通信的梯度做Topk压缩,只剩下绝对值最大的k个value和对应的k个index,然后所有卡的value和index汇总到一起,再计算每个index的总和。通过这种方法,使通信量大大减少。

在此基础上,团队进一步提出了以下几点优化:
1) 首次提出层级Topk压缩通信算法。
还是以单机8卡的机型为例,首先第一步先用ReduceScatter在单机内通信,利用NVLink2的高速带宽,使每块卡快速得到单机内1/8梯度的总和。
第二步的流程与普通的Topk压缩通信一样(如上图),不同的是每块卡只对原梯度1/8大小的数据量做Topk压缩,从而减少Topk压缩的计算时间,而且每块卡在AllGather时的节点数减少到1/8,因为AllGather的通信量与节点数成正比,所以8卡的总通信量也减少到普通Topk压缩通信的1/8。而且单机的8张卡是并行跨机通信的,也提升了带宽利用率.。
第三步再通过单机内的AllGather使每张卡得到整个梯度的通信结果。
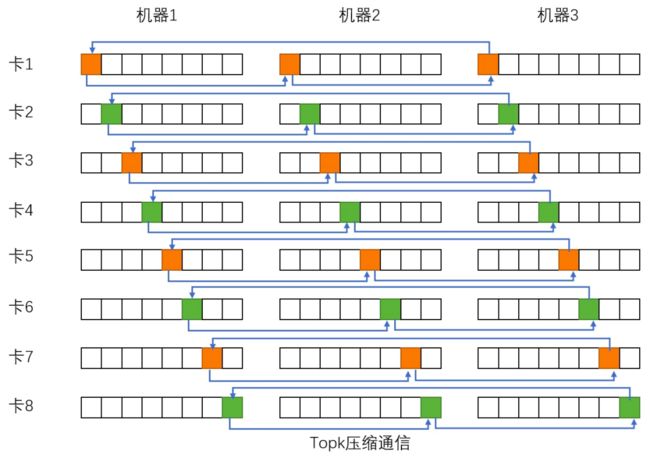

2) Topk压缩性能优化。
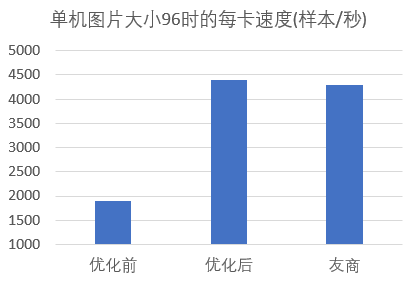
如何高效进行Topk压缩也是提高整体通信效率至关重要的一环,尤其是在GPU上,若使用Tensorflow 自身的 Topk 操作,在8MB数据下选取最大的1%个value需要花费42ms,而图片大小为96*96*3时的前、反向计算的总时间也才几十ms,因此严重影响了整个梯度压缩通信的性能。
为了解决Topk压缩慢的问题,团队调研并借鉴了多种压缩算法,使用了性能较好的阈值二分搜索选择算法[8],并在平衡了效率和精度后做了一些改进,二分搜索过程中记录最大的k'(k' 团队也为算法实现了高性能的CUDA Kernel,首先为了最大化GPU利用率,合理配置Kernel使用的block和thread个数,并保证每个SM上拥有至少16个活动warp,以有效的隐藏访存延迟。其次为了提高内存吞吐量,将多次传输合并为一次传输来减少CPU和GPU之间的内存传输;另外使用带宽更高的共享内存,并通过动态分配的方式,提高共享内存的使用效率;保证block内的各个线程访问连续对齐的内存块,提高缓存命中率。 最后为了提高指令吞吐量,使用效率更高的CUDA接口,并对循环进行展开,减少条件分支。通过以上对CUDA Kernel的深度优化后,在8MB数据下选取前1% 的value只需要2ms,与Tensorflow本身的Topk实现相比,加速比为21。 3) 针对allgather通信进行优化。 当所有卡要通信的数据大小一致时,使用ncclAllGather来通信,不一致时使用ncclBroadCast来模拟allgatherv,这个优化也已经提交到Horovod社区。因为在压缩通信这个场景下,每块卡压缩后的数据大小是一致的,所以使用ncclAllGather通信,比mpi的allgatherv更快。 ResNet-50 v1.5的参数量大概是25M个FP32,以压缩率0.01为例,通信的value用FP16表示的话有0.5MB,而index是int32,所以有1MB。使用层级梯度压缩通信时,跨机AllGather的节点数是16,所以总的跨机通信量大概是24MB。 4) LARS计算并行化 为保证大batch下收敛,团队引入了LARS优化器,但LARS也引入了更多的计算量,每块卡会串行地计算每一层梯度的本地学习率。团队发现,由于该部分时间的消耗,计算时间无法与通信时间完全覆盖,导致整体训练时间的延长。由于LARS的计算是梯度通信之后,每张卡的针对模型计算出的本地学习率都是一致的,也就是每张卡都在做同样的计算,且计算出来的本地学习率对每层梯度为单值。 除了LARS,LAMB也是这种梯度规约后的操作,属于每块做重复计算的操作。针对这类操作,根据操作的计算代价和通信代价进行评估,如果是计算代价比较大的,就会自动将其转换成多卡并行计算再进行汇总,从而使总时间最少。 大batch收敛 1)大batch调参策略 训练样本上,团队在性能和收敛性上做了权衡,使用了变分辨率的多阶训练:训练前期利用多个epoch的低分辨率样本快速收敛,并在训练后期使用少量epoch的高分辨率调高精度。 模型上,使用了业界常用的ResNet50 v1.5,同时在去除了bias及BN层参数正则化项的情况下,对BN层的beta做了一定的初始化调整,在较少迭代步数上取得了较好的收敛效果。 优化器上,选择了业界普遍采用的MomentumSGD结合LARS层级自适应优化器,为了快速收敛,团队对该优化器做了一些改动。对LARS优化器采用了随迭代步变化的置信比约束策略:在Warm up阶段,为了避免由于噪声过大导致发散的问题,将lars优化器的置信比裁剪约束到较小的范围,稳定的收敛;Warm up阶段之后放松对lars优化器置信比的裁剪约束,加速收敛。 对于优化器中的动量值采用了全周期一次完整循环的方式,前期为了收敛的稳定性,动量值会随着训练的迭代不断增大,防止训练发散,后期为了训练的模型适配图片变大的分辨率,动量值随着训练的迭代不断减小,放大后期梯度对模型的贡献,加速收敛。 由于考虑到训练中使用的多分辨率样本,对学习率采用了分段线性变斜率策略,在warmup前后采用不同斜率的线性增长和线性减小,在不同分辨率阶段使用不同的学习率斜率,由AutoML进行端点斜率调节确定最终策略。 实际超参选择中,在确定学习率策略等超参数方案后,团队利用平台大算力结合自研天风AutoML框架,以最后一个epoch的精度作为评估指标,对于各阶段不同大小的样本进行分段分块有针对性的超参微调,并结合AutoML结果对超参方案进行迭代更新。 损失函数上,使用了label smoothing这一正则化手段对训练标签做了平滑处理,以防止过拟合帮助收敛。 2)梯度压缩精度 在整个训练过程当中,只在图片大小为96*96*3时采用梯度压缩通信,因为这种情况下通信的时间占比最大,梯度压缩通信对训练速度的提升最好,而且对精度的影响也最小。 精度补偿采用的是梯度本地累积的方法,也就是没有被选中通信的index的值,会在本地累加,参与下一轮通信。 3)AutoML调参 针对业界开源框架研发 AutoML 算法难、集成自研训练平台工作量大和在大规模长任务训练场景优化效果差的问题,研发了天风 (TianFeng), 是聚焦于大规模训练场景的、轻量的、易扩展的、易使用的 AutoML 框架,通过高度抽象 AutoML 的通用过程,来解决这些业界难题。 为了方便算法工程师做AutoML算法研发和新平台接入,天风内部分为三层,算法层、逻辑层和接入层。 (1)算法层,AutoML算法都在这一层,通过抽象算法逻辑,方便算法工程师实现和接入AutoML算法。 (2)逻辑层,负责对接Client,算法逻辑下发、异常处理和持久化。 (3)接入层,负责训练平台的对接,当前可以很简单的接入自研训练平台,结合AutoML能力和自研训练平台的调度和训练能力。 在ImageNet训练中,存在训练规模大,超参数范围广,人工调参效率低且效果不好的问题。因而引入天风用于超参数空间的探索,将人力较大程度地从繁琐的手工调参中解放出来。 依托智能钛平台的海量弹性算力,天风AutoML利用自研的并行贝叶斯优化算法进行超参数搜索,充分利用智能钛平台资源池中的空闲GPU算力资源并行进行多组弹性任务AutoML实验,做到了高优先级任务占用资源时实验自动终止,资源空闲时自动加载实验终止前的先验数据恢复。 整体上AutoML搜索超参数为大batch size调参指明了方向,在同一模型下,AutoML仅需由工程师指定所需要搜索的超参数及其范围,即可对超参数空间进行探索从而对调参思路进行快速验证。 4.4 高性能机器学习平台——智能钛 智能钛机器学习平台是为 AI 工程师打造的一站式机器学习服务平台,为用户提供从数据预处理、模型构建、模型训练、模型评估到模型服务的全流程开发支持。智能钛机器学习平台内置丰富的算法组件,支持多种算法框架,满足多种AI应用场景的需求。自动化建模(AutoML)的支持与拖拽式任务流设计让 AI 初学者也能轻松上手。 取得的成效 通过以上 Light大规模分布式多机多卡训练框架及平台等一系列完整的解决方案,ImageNet的训练结果取得了新突破。同时,这些方案也广泛应用在腾讯公有云以及腾讯内部的业务,并形成了腾讯云帆(深度学习框架和加速)Oteam、算力Oteam等协同组织,在更广泛的范围内协同共建。以ImageNet的训练结果为例说明下。 单机优化 在单机的速度上,4种不同的图片大小时都超过了友商。例如图片大小为96*96*3时,优化前后的速度对比如下图所示。 多机扩展 在25G的TCP网络上,图片大小为96*96*3时,由于计算时间相对较少,通信时间占比大,所以多机扩展性是最差的。 如果使用Horovod的全局AllReduce,训练速度只有885样本/秒,而使用LightCC多机多卡通信库的话,不使用压缩通信时的训练速度是2450样本/秒(LARS优化前是2360样本/秒),而使用压缩通信的训练速度是3100样本/秒。而友商128卡的速度是2608样本/秒,即不压缩通信时由于带宽限制导致略差于友商,而压缩通信之后超过了友商。 在图片大小为128*128*3时,由于计算时间变长,非压缩通信和压缩通信都只有最后一个梯度的通信没有被计算隐藏,所以压缩通信并没有速度上的优势,不过非压缩通信的速度也已经超过了友商。 收敛 在收敛精度方面,通过手动设置超参与AutoML调参相结合,在28个epoch将top5精度训练到93%。 2分31秒训练ImageNet 在2分36秒内训练 ImageNet 28个epoch,TOP5精度达到93%;使用压缩通信后,在精度达到93%情况下,时间进一步减少到2分31秒,刷新了业界最好成绩,创造了业界新记录。若跨机网络改为RoCE,则训练时间再进一步减少到2分2秒。 构建稳定、易用、好用、高效的平台和服务,将成为算法工程师的重要生产力工具,也会助力游戏AI、计算机视觉AI,广告推荐AI、翻译AI、语音ASR AI等典型AI业务从一个成功走向另一个更大的成功。 本次破纪录的ImageNet训练,由腾讯机智团队、腾讯云智能钛团队、腾讯优图实验室、腾讯大数据团队和香港浸会大学计算机科学系褚晓文教授团队协同优化完成。 参考链接: 1.Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes https://arxiv.org/abs/1807.11205 2.ImageNet/ResNet-50 Training in 224 Seconds https://nnabla.org/paper/imagenet_in_224sec.pdf Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet 3.classification with deep convolutional neural networks." Advances in neural information processing systems. 2012. 4.He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. 5.Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017. 6.Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018). 7.Brown, Tom B., et al. "Language models are few-shot learners." arXiv preprint arXiv:2005.14165 (2020). 8.RedSync : Reducing Synchronization Traffic for Distributed Deep Learning https://arxiv.org/abs/1808.04357 本项目论文《Efficient Distributed Deep Learning Training on Public Cloud Clusters: ImageNet/Resnet-50 Training in Two Minutes》,将首先在arxiv上提交供查阅。 感谢你的分享,点赞,在看三连↓