目录
4.1 从csv和txt文件存取数据
4.1.1 csv文件的存取
4.1.1.1 以前学过的python读取csv文件
4.1.1.2 pandas读取csv
4.1.1.3 csv文件的写入
4.1.1.3.1 原来用python写文件
4.1.1.3.2 pandas写入csv
4.1.2 txt文件的存取
4.1.2.1 以前学过的python文件读取方法
4.1.2.2 pandas读txt文件
4.2 Excel文件的存取
4.2.1 以前学过的python操作excel文件
4.2.1.1 导入库
4.2.1.2 打开工作薄文件
4.2.1.3 获取表单sheet
4.2.1.4 获得每个sheet的汇总数据
4.2.1.5 单元格的操作
4.2.1.5.1 行操作
4.2.1.5.2 单元格操作
4.2.2 用pandas读取excel文件
4.2.3 实例:新冠疫情初期数据分析
4.2.4 excel文件的写入
4.3 从Json文件读写
4.3.1 利用以前的方式
4.3.2 直接利用pandas的方法pd.read_json读取json文件
4.3.3 json文件的写入
4.4 从Html表格中获取数据
4.4.1 从Html表格获得数据的主要注意事项
4.4.2 利用pandas.read_html()爬取天气网页数据
4.5 从数据库获取
4.6 从word文件获取
4.6.1 python-docx的安装
4.6.2 python-docx数据获取的使用
4.6.3 实例:简单可视化分析2022年重庆市免试专升本各个学校数据
4.7 从pdf文件读取数据
4.7.1 安装pdfplumber
4.7.2 使用pdfplumber读取数据
4.7.2.1 读取单页的《集合介绍.pdf》
4.7.2.2 读取多页的《2021jxcg.pdf》
本文涉及到的数据资料文件下载地址 百度网盘
4.1 从csv和txt文件存取数据
4.1.1 csv文件的存取
4.1.1.1 以前学过的python读取csv文件
import csv
f = csv. reader( open ( 'phones.csv' , 'r' , encoding= 'gbk' ) )
for i in f:
print ( i)
['商品名称', '价格', '颜色']
['Apple iPhone X (A1865) 64GB', '6299', '深空灰色']
['Apple iPhone XS Max (A2104) 256GB ', '10999', '深空灰色']
['Apple iPhone XR (A2108) 128GB', '6199', '黑色']
['Apple iPhone 8 (A1863) 64GB', '3999', '深空灰色']
['Apple iPhone 8 Plus (A1864) 64GB', '4799', '深空灰色']
['Apple iPhone XS (A2100) 64GB', '8699', '深空灰色']
['Apple 苹果 iPhone Xs Max 256GB', '9988', '金色']
['Apple 苹果 iPhone Xs 64GB', '8058', '金色']
['Apple 苹果 iPhone XR 128GB', '5788', '黑色']
['Apple iPhone 7 (A1660) 128G', '4139', '玫瑰金色']
f = open ( 'phones.csv' , 'r' , encoding = 'gbk' )
csvReader = csv. reader( f)
for row in csvReader:
print ( row)
f. close( )
['商品名称', '价格', '颜色']
['Apple iPhone X (A1865) 64GB', '6299', '深空灰色']
['Apple iPhone XS Max (A2104) 256GB ', '10999', '深空灰色']
['Apple iPhone XR (A2108) 128GB', '6199', '黑色']
['Apple iPhone 8 (A1863) 64GB', '3999', '深空灰色']
['Apple iPhone 8 Plus (A1864) 64GB', '4799', '深空灰色']
['Apple iPhone XS (A2100) 64GB', '8699', '深空灰色']
['Apple 苹果 iPhone Xs Max 256GB', '9988', '金色']
['Apple 苹果 iPhone Xs 64GB', '8058', '金色']
['Apple 苹果 iPhone XR 128GB', '5788', '黑色']
['Apple iPhone 7 (A1660) 128G', '4139', '玫瑰金色']
with open ( 'phones.csv' , 'r' , encoding = 'gbk' ) as f:
csvReader = csv. reader( f)
for row in csvReader:
print ( row)
['商品名称', '价格', '颜色']
['Apple iPhone X (A1865) 64GB', '6299', '深空灰色']
['Apple iPhone XS Max (A2104) 256GB ', '10999', '深空灰色']
['Apple iPhone XR (A2108) 128GB', '6199', '黑色']
['Apple iPhone 8 (A1863) 64GB', '3999', '深空灰色']
['Apple iPhone 8 Plus (A1864) 64GB', '4799', '深空灰色']
['Apple iPhone XS (A2100) 64GB', '8699', '深空灰色']
['Apple 苹果 iPhone Xs Max 256GB', '9988', '金色']
['Apple 苹果 iPhone Xs 64GB', '8058', '金色']
['Apple 苹果 iPhone XR 128GB', '5788', '黑色']
['Apple iPhone 7 (A1660) 128G', '4139', '玫瑰金色']
row
['Apple iPhone 7 (A1660) 128G', '4139', '玫瑰金色']
list1 = [ ]
with open ( 'phones.csv' , 'r' , encoding = 'gbk' ) as f:
csvReader = csv. reader( f)
for row in csvReader:
list1. append( row)
list1
[['商品名称', '价格', '颜色'],
['Apple iPhone X (A1865) 64GB', '6299', '深空灰色'],
['Apple iPhone XS Max (A2104) 256GB ', '10999', '深空灰色'],
['Apple iPhone XR (A2108) 128GB', '6199', '黑色'],
['Apple iPhone 8 (A1863) 64GB', '3999', '深空灰色'],
['Apple iPhone 8 Plus (A1864) 64GB', '4799', '深空灰色'],
['Apple iPhone XS (A2100) 64GB', '8699', '深空灰色'],
['Apple 苹果 iPhone Xs Max 256GB', '9988', '金色'],
['Apple 苹果 iPhone Xs 64GB', '8058', '金色'],
['Apple 苹果 iPhone XR 128GB', '5788', '黑色'],
['Apple iPhone 7 (A1660) 128G', '4139', '玫瑰金色']]
import pandas as pd
df1 = pd. DataFrame( list1)
df1
0
1
2
0
商品名称
价格
颜色
1
Apple iPhone X (A1865) 64GB
6299
深空灰色
2
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
3
Apple iPhone XR (A2108) 128GB
6199
黑色
4
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
5
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
6
Apple iPhone XS (A2100) 64GB
8699
深空灰色
7
Apple 苹果 iPhone Xs Max 256GB
9988
金色
8
Apple 苹果 iPhone Xs 64GB
8058
金色
9
Apple 苹果 iPhone XR 128GB
5788
黑色
10
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
list1[ 1 : ]
[['Apple iPhone X (A1865) 64GB', '6299', '深空灰色'],
['Apple iPhone XS Max (A2104) 256GB ', '10999', '深空灰色'],
['Apple iPhone XR (A2108) 128GB', '6199', '黑色'],
['Apple iPhone 8 (A1863) 64GB', '3999', '深空灰色'],
['Apple iPhone 8 Plus (A1864) 64GB', '4799', '深空灰色'],
['Apple iPhone XS (A2100) 64GB', '8699', '深空灰色'],
['Apple 苹果 iPhone Xs Max 256GB', '9988', '金色'],
['Apple 苹果 iPhone Xs 64GB', '8058', '金色'],
['Apple 苹果 iPhone XR 128GB', '5788', '黑色'],
['Apple iPhone 7 (A1660) 128G', '4139', '玫瑰金色']]
df1 = pd. DataFrame( list1[ 1 : ] , columns= list1[ 0 ] )
df1
商品名称
价格
颜色
0
Apple iPhone X (A1865) 64GB
6299
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
2
Apple iPhone XR (A2108) 128GB
6199
黑色
3
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
5
Apple iPhone XS (A2100) 64GB
8699
深空灰色
6
Apple 苹果 iPhone Xs Max 256GB
9988
金色
7
Apple 苹果 iPhone Xs 64GB
8058
金色
8
Apple 苹果 iPhone XR 128GB
5788
黑色
9
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
df1. describe( )
商品名称
价格
颜色
count
10
10
10
unique
10
10
4
top
Apple iPhone X (A1865) 64GB
6299
深空灰色
freq
1
1
5
df1. info( )
RangeIndex: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 商品名称 10 non-null object
1 价格 10 non-null object
2 颜色 10 non-null object
dtypes: object(3)
memory usage: 368.0+ bytes
df1[ '价格' ] . astype( 'int64' )
0 6299
1 10999
2 6199
3 3999
4 4799
5 8699
6 9988
7 8058
8 5788
9 4139
Name: 价格, dtype: int64
df1[ '价格' ] = df1[ '价格' ] . astype( 'int64' )
df1. info( )
RangeIndex: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 商品名称 10 non-null object
1 价格 10 non-null int64
2 颜色 10 non-null object
dtypes: int64(1), object(2)
memory usage: 368.0+ bytes
df1. describe( )
价格
count
10.000000
mean
6896.700000
std
2437.144734
min
3999.000000
25%
5046.250000
50%
6249.000000
75%
8538.750000
max
10999.000000
4.1.1.2 pandas读取csv
df2 = pd. read_csv( "phones.csv" , encoding= 'gbk' )
df2
商品名称
价格
颜色
0
Apple iPhone X (A1865) 64GB
6299
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
2
Apple iPhone XR (A2108) 128GB
6199
黑色
3
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
5
Apple iPhone XS (A2100) 64GB
8699
深空灰色
6
Apple 苹果 iPhone Xs Max 256GB
9988
金色
7
Apple 苹果 iPhone Xs 64GB
8058
金色
8
Apple 苹果 iPhone XR 128GB
5788
黑色
9
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
df2. info( )
RangeIndex: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 商品名称 10 non-null object
1 价格 10 non-null int64
2 颜色 10 non-null object
dtypes: int64(1), object(2)
memory usage: 368.0+ bytes
df21 = pd. read_csv( "phones.csv" , encoding= 'gbk' , usecols= [ '商品名称' , '价格' ] )
df21
商品名称
价格
0
Apple iPhone X (A1865) 64GB
6299
1
Apple iPhone XS Max (A2104) 256GB
10999
2
Apple iPhone XR (A2108) 128GB
6199
3
Apple iPhone 8 (A1863) 64GB
3999
4
Apple iPhone 8 Plus (A1864) 64GB
4799
5
Apple iPhone XS (A2100) 64GB
8699
6
Apple 苹果 iPhone Xs Max 256GB
9988
7
Apple 苹果 iPhone Xs 64GB
8058
8
Apple 苹果 iPhone XR 128GB
5788
9
Apple iPhone 7 (A1660) 128G
4139
df22 = pd. read_csv( "phones.csv" , encoding= 'gbk' , usecols= [ 0 , 2 ] )
df22
商品名称
颜色
0
Apple iPhone X (A1865) 64GB
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
深空灰色
2
Apple iPhone XR (A2108) 128GB
黑色
3
Apple iPhone 8 (A1863) 64GB
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
深空灰色
5
Apple iPhone XS (A2100) 64GB
深空灰色
6
Apple 苹果 iPhone Xs Max 256GB
金色
7
Apple 苹果 iPhone Xs 64GB
金色
8
Apple 苹果 iPhone XR 128GB
黑色
9
Apple iPhone 7 (A1660) 128G
玫瑰金色
df23 = pd. read_csv( "phones.csv" , encoding= 'gbk' , nrows= 5 )
df23
商品名称
价格
颜色
0
Apple iPhone X (A1865) 64GB
6299
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
2
Apple iPhone XR (A2108) 128GB
6199
黑色
3
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
4.1.1.3 csv文件的写入
df2
商品名称
价格
颜色
0
Apple iPhone X (A1865) 64GB
6299
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
2
Apple iPhone XR (A2108) 128GB
6199
黑色
3
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
5
Apple iPhone XS (A2100) 64GB
8699
深空灰色
6
Apple 苹果 iPhone Xs Max 256GB
9988
金色
7
Apple 苹果 iPhone Xs 64GB
8058
金色
8
Apple 苹果 iPhone XR 128GB
5788
黑色
9
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
4.1.1.3.1 原来用python写文件
csv.writerow()
csv.writerows()
df2. values
array([['Apple iPhone X (A1865) 64GB', 6299, '深空灰色'],
['Apple iPhone XS Max (A2104) 256GB ', 10999, '深空灰色'],
['Apple iPhone XR (A2108) 128GB', 6199, '黑色'],
['Apple iPhone 8 (A1863) 64GB', 3999, '深空灰色'],
['Apple iPhone 8 Plus (A1864) 64GB', 4799, '深空灰色'],
['Apple iPhone XS (A2100) 64GB', 8699, '深空灰色'],
['Apple 苹果 iPhone Xs Max 256GB', 9988, '金色'],
['Apple 苹果 iPhone Xs 64GB', 8058, '金色'],
['Apple 苹果 iPhone XR 128GB', 5788, '黑色'],
['Apple iPhone 7 (A1660) 128G', 4139, '玫瑰金色']], dtype=object)
import csv
f = open ( "phonesOut0.csv" , 'w' , encoding= 'gbk' )
csvWriter = csv. writer( f)
for row in df2. values:
csvWriter. writerow( row)
f. close( )
df3 = pd. read_csv( "phonesOut0.csv" , encoding= 'gbk' , header= None , names = [ '名称' , '价格' , '颜色' ] )
df3
名称
价格
颜色
0
Apple iPhone X (A1865) 64GB
6299
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
2
Apple iPhone XR (A2108) 128GB
6199
黑色
3
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
5
Apple iPhone XS (A2100) 64GB
8699
深空灰色
6
Apple 苹果 iPhone Xs Max 256GB
9988
金色
7
Apple 苹果 iPhone Xs 64GB
8058
金色
8
Apple 苹果 iPhone XR 128GB
5788
黑色
9
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
df3. shape
(10, 3)
df4 = pd. read_csv( "phonesOut0.csv" , encoding= 'gbk' , index_col= '名称' , header= None , names = [ '名称' , '价格' , '颜色' ] )
df4
价格
颜色
名称
Apple iPhone X (A1865) 64GB
6299
深空灰色
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
Apple iPhone XR (A2108) 128GB
6199
黑色
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
Apple iPhone XS (A2100) 64GB
8699
深空灰色
Apple 苹果 iPhone Xs Max 256GB
9988
金色
Apple 苹果 iPhone Xs 64GB
8058
金色
Apple 苹果 iPhone XR 128GB
5788
黑色
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
df4. shape
(10, 2)
4.1.1.3.2 pandas写入csv
df2
商品名称
价格
颜色
0
Apple iPhone X (A1865) 64GB
6299
深空灰色
1
Apple iPhone XS Max (A2104) 256GB
10999
深空灰色
2
Apple iPhone XR (A2108) 128GB
6199
黑色
3
Apple iPhone 8 (A1863) 64GB
3999
深空灰色
4
Apple iPhone 8 Plus (A1864) 64GB
4799
深空灰色
5
Apple iPhone XS (A2100) 64GB
8699
深空灰色
6
Apple 苹果 iPhone Xs Max 256GB
9988
金色
7
Apple 苹果 iPhone Xs 64GB
8058
金色
8
Apple 苹果 iPhone XR 128GB
5788
黑色
9
Apple iPhone 7 (A1660) 128G
4139
玫瑰金色
df2. to_csv( 'phonseOut1.csv' )
df2. to_csv( 'phonseOut2.csv' , columns= [ '商品名称' , '价格' ] )
df2. to_csv( 'phonseOut3.csv' , index= False )
4.1.2 txt文件的存取
4.1.2.1 以前学过的python文件读取方法
i = 0
with open ( 'itheima_books.txt' , 'r' ) as f:
data = f. read( )
print ( i)
print ( data)
i += 1
0
黑马程序员教程 教程网址
学习线路图 https://book.itheima.net/learnline/1265899443273850881
学习教程 https://book.itheima.net/course/1265899443273850881
面试宝典 https://book.itheima.net/study/1265899443273850881
data
'黑马程序员教程 教程网址\n学习线路图 https://book.itheima.net/learnline/1265899443273850881\n学习教程 https://book.itheima.net/course/1265899443273850881\n面试宝典 https://book.itheima.net/study/1265899443273850881\n'
f.readline()读取一行内容
f.readlines() 读取所有内容,讲每一行作为一个元素,返回列表
i = 0
with open ( 'itheima_books.txt' , 'r' ) as f:
line = f. readline( )
print ( i)
print ( line)
i += 1
0
黑马程序员教程 教程网址
with open ( 'itheima_books.txt' , 'r' ) as f:
line = f. readline( )
print ( line)
line = f. readline( )
print ( line)
黑马程序员教程 教程网址
学习线路图 https://book.itheima.net/learnline/1265899443273850881
with open ( 'itheima_books.txt' , 'r' ) as f:
while True :
line = f. readline( )
if line:
print ( line, end= '' )
else :
break
黑马程序员教程 教程网址
学习线路图 https://book.itheima.net/learnline/1265899443273850881
学习教程 https://book.itheima.net/course/1265899443273850881
面试宝典 https://book.itheima.net/study/1265899443273850881
with open ( 'itheima_books.txt' , 'r' ) as f:
lines = f. readlines( )
lines
['黑马程序员教程 教程网址\n',
'学习线路图 https://book.itheima.net/learnline/1265899443273850881\n',
'学习教程 https://book.itheima.net/course/1265899443273850881\n',
'面试宝典 https://book.itheima.net/study/1265899443273850881\n']
type ( lines)
list
4.1.2.2 pandas读txt文件
import pandas as pd
txtData = pd. read_csv( "itheima_books.txt" )
txtData
黑马程序员教程 教程网址
0
学习线路图 https://book.itheima.net/learnline/12658...
1
学习教程 https://book.itheima.net/course/126589944...
2
面试宝典 https://book.itheima.net/study/1265899443...
type ( txtData)
pandas.core.frame.DataFrame
txtData. shape
(3, 1)
txtData2 = pd. read_csv( "itheima_books.txt" , sep= ' ' )
txtData2
黑马程序员教程
教程网址
0
学习线路图
https://book.itheima.net/learnline/12658994432...
1
学习教程
https://book.itheima.net/course/12658994432738...
2
面试宝典
https://book.itheima.net/study/126589944327385...
txtData2. shape
(3, 2)
练习:读取 cj.txt 文件
txtData3 = pd. read_csv( "cj.txt" , sep= '\t' )
txtData3
学号
班级
姓名
性别
英语
体育
军训
数分
高代
解几
0
2308024241
23080242
成龙
男
76
78
77
40
23
60
1
2308024244
23080242
周怡
女
66
91
75
47
47
44
2
2308024251
23080242
张波
男
85
81
75
45
45
60
3
2308024249
23080242
朱浩
男
65
50
80
72
62
71
4
2308024219
23080242
封印
女
73
88
92
61
47
46
5
2308024201
23080242
迟培
男
60
50
89
71
76
71
6
2308024347
23080243
李华
女
67
61
84
61
65
78
7
2308024307
23080243
陈田
男
76
79
86
69
40
69
8
2308024326
23080243
余皓
男
66
67
85
65
61
71
9
2308024320
23080243
李嘉
女
62
作弊
90
60
67
77
10
2308024342
23080243
李上初
男
76
90
84
60
66
60
11
2308024310
23080243
郭窦
女
79
67
84
64
64
79
12
2308024435
23080244
姜毅涛
男
77
71
缺考
61
73
76
13
2308024432
23080244
赵宇
男
74
74
88
68
70
71
14
2308024446
23080244
周路
女
76
80
77
61
74
80
15
2308024421
23080244
林建祥
男
72
72
81
63
90
75
16
2308024433
23080244
李大强
男
79
76
77
78
70
70
17
2308024428
23080244
李侧通
男
64
96
91
69
60
77
18
2308024402
23080244
王慧
女
73
74
93
70
71
75
19
2308024422
23080244
李晓亮
男
85
60
85
72
72
83
20
2308024201
23080242
迟培
男
60
50
89
71
76
71
txtData3. info( )
RangeIndex: 21 entries, 0 to 20
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 学号 21 non-null int64
1 班级 21 non-null int64
2 姓名 21 non-null object
3 性别 21 non-null object
4 英语 21 non-null int64
5 体育 21 non-null object
6 军训 21 non-null object
7 数分 21 non-null int64
8 高代 21 non-null int64
9 解几 21 non-null int64
dtypes: int64(6), object(4)
memory usage: 1.8+ KB
txtData3 = pd. read_table( "cj.txt" )
txtData3
学号
班级
姓名
性别
英语
体育
军训
数分
高代
解几
0
2308024241
23080242
成龙
男
76
78
77
40
23
60
1
2308024244
23080242
周怡
女
66
91
75
47
47
44
2
2308024251
23080242
张波
男
85
81
75
45
45
60
3
2308024249
23080242
朱浩
男
65
50
80
72
62
71
4
2308024219
23080242
封印
女
73
88
92
61
47
46
5
2308024201
23080242
迟培
男
60
50
89
71
76
71
6
2308024347
23080243
李华
女
67
61
84
61
65
78
7
2308024307
23080243
陈田
男
76
79
86
69
40
69
8
2308024326
23080243
余皓
男
66
67
85
65
61
71
9
2308024320
23080243
李嘉
女
62
作弊
90
60
67
77
10
2308024342
23080243
李上初
男
76
90
84
60
66
60
11
2308024310
23080243
郭窦
女
79
67
84
64
64
79
12
2308024435
23080244
姜毅涛
男
77
71
缺考
61
73
76
13
2308024432
23080244
赵宇
男
74
74
88
68
70
71
14
2308024446
23080244
周路
女
76
80
77
61
74
80
15
2308024421
23080244
林建祥
男
72
72
81
63
90
75
16
2308024433
23080244
李大强
男
79
76
77
78
70
70
17
2308024428
23080244
李侧通
男
64
96
91
69
60
77
18
2308024402
23080244
王慧
女
73
74
93
70
71
75
19
2308024422
23080244
李晓亮
男
85
60
85
72
72
83
20
2308024201
23080242
迟培
男
60
50
89
71
76
71
4.2 Excel文件的存取
4.2.1 以前学过的python操作excel文件
xlrd与xlwt进行excel文件读写
openpyxl进行excel文件读写
4.2.1.1 导入库
import xlrd
4.2.1.2 打开工作薄文件
wb = xlrd. open_workbook( "Athletes_info.xls" )
wb
4.2.1.3 获取表单sheet
获取所有的sheet名字 .sheet_names()
获取表单数量 .nsheets
获得表单所有对象: .sheets()
通过sheet名查找: .sheet_by_name()
通过索引查找: .sheet_by_index()
wb. sheet_names( )
['Sheet1', 'Sheet2', '表单3']
type ( wb. sheet_names( ) [ 0 ] )
str
wb. nsheets
3
wb. sheets( )
[Sheet 0:, Sheet 1:, Sheet 2:<表单3>]
type ( wb. sheets( ) [ 0 ] )
xlrd.sheet.Sheet
wb. sheet_by_name( 'Sheet1' )
Sheet 0:
wb. sheet_by_index( 2 )
Sheet 2:<表单3>
4.2.1.4 获得每个sheet的汇总数据
.name:sheet名
.nrows: 获得总行数
.ncols: 获得总的列
wb = xlrd. open_workbook( "Athletes_info.xls" )
wb. sheet_names( )
['Sheet1', 'Sheet2', '表单3']
sheets = wb. sheets( )
sheets
[Sheet 0:, Sheet 1:, Sheet 2:<表单3>]
type ( sheets)
list
sheets[ 0 ] . nrows
322
sheets[ 0 ] . ncols
9
import xlrd
wb = xlrd. open_workbook( "Athletes_info.xls" )
for i in range ( wb. nsheets) :
sheet = wb. sheet_by_index( i)
print ( sheet. name)
print ( '行数:' , sheet. nrows)
print ( '列数:' , sheet. ncols)
print ( "=" * 50 )
Sheet1
行数: 322
列数: 9
==================================================
Sheet2
行数: 2
列数: 3
==================================================
表单3
行数: 0
列数: 0
==================================================
4.2.1.5 单元格的操作
4.2.1.5.1 行操作
.sheet.row_values(0) #获得第一行的所有内容
.sheet.row(0). #获取单元格值的类型和内容
.sheet.row_types(0)#获得单元格的类型
sheets = wb. sheets( )
sheet0 = sheets[ 0 ]
sheet0
Sheet 0:
sheet0. row_values( 0 )
['name',
'name2',
'gender',
'nation',
'birth',
'height/cm',
'weight',
'event',
'native place']
sheet0. row( 0 )
[text:'name',
text:'name2',
text:'gender',
text:'nation',
text:'birth',
text:'height/cm',
text:'weight',
text:'event',
text:'native place']
sheet0. row_types( 0 )
array('B', [1, 1, 1, 1, 1, 1, 1, 1, 1])
4.2.1.5.2 单元格操作
sheet.row_values(0,3,7) # 获得的是第0行第3到7列(不含最后的第7列)
sheet.col_values(0,0,5) # 获得的是第0列第5到5行(不含最后的第5行)
sheet0. row_values( 0 )
['name',
'name2',
'gender',
'nation',
'birth',
'height/cm',
'weight',
'event',
'native place']
sheet0. row_values( 0 , 3 , 7 )
['nation', 'birth', 'height/cm', 'weight']
sheet0. row_values( 1 , 3 , 7 )
['中国', 32769.0, '', '']
sheet0. col_values( 0 , 0 , 5 )
['name', '毕晓琳 ', '鲍语晴 ', '艾衍含 ', '卞卡 ']
4.2.2 用pandas读取excel文件
import pandas as pd
excelData = pd. read_excel( "Athletes_info.xlsx" , sheet_name= "Sheet1" )
excelData. head( 5 )
name
name2
gender
nation
birth
height/cm
weight
event
native place
0
毕晓琳
Bi Xiaolin
女
中国
1989-09-18 00:00:00
NaN
NaN
足球
辽宁
1
鲍语晴
Bao Yuqing
女
中国
NaN
NaN
NaN
艺术体操
浙江
2
艾衍含
Ai Yanhan
女
中国
2002-02-07 00:00:00
NaN
NaN
游泳
湖北
3
卞卡
BIAN Ka
女
中国
1993-01-05 00:00:00
182.0
113kg
女子铅球
江苏
4
陈楠
Chen Nan
女
中国
1983-12-08 00:00:00
197.0
90kg
篮球
青岛胶南
excelData. info( )
RangeIndex: 321 entries, 0 to 320
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 321 non-null object
1 name2 321 non-null object
2 gender 321 non-null object
3 nation 321 non-null object
4 birth 251 non-null object
5 height/cm 203 non-null float64
6 weight 194 non-null object
7 event 320 non-null object
8 native place 306 non-null object
dtypes: float64(1), object(8)
memory usage: 22.7+ KB
excelData. describe( )
height/cm
count
203.000000
mean
177.911330
std
12.033041
min
140.000000
25%
170.500000
50%
177.000000
75%
184.000000
max
225.000000
phonsedata = pd. read_excel( "phonesdata.xlsx" , sheet_name= 0 , nrows= 5 )
phonsedata
订单号
订单日期
年
月
地区名字
省份名字
城市名字
品牌
型号
运行内存
机身内存
数量
用户名
用户姓名
年龄
性别
手机号
0
20180301004758
2020-01-14
2020
1
中南地区
广西壮族自治区
梧州市
荣耀
荣耀9X
6G
64G
4
RVwhqiwMFc
刘捷
16
1
1379407****
1
20180301004759
2018-01-20
2018
1
华东地区
浙江省
舟山市
三星
Galaxy A50s
6G
128G
7
hICxjenVeM
陈盼妙
37
2
1382084****
2
20180301004760
2019-06-15
2019
6
西北地区
甘肃省
白银市
小米
红米K30 Pro
8G
256G
8
RSXOFBOwki
张浩
36
1
1593116****
3
20180301004761
2019-01-07
2019
1
中南地区
河南省
许昌市
小米
红米Note8
8G
128G
13
OtUMUlCBuK
辛倩
21
2
1308444****
4
20180301004762
2019-05-21
2019
5
直辖市
北京市
北京市
vivo
New 3S
6G
128G
4
eikoQvIyUR
徐旭
31
2
1322687****
phonsedata. info( )
RangeIndex: 5 entries, 0 to 4
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单号 5 non-null int64
1 订单日期 5 non-null datetime64[ns]
2 年 5 non-null int64
3 月 5 non-null int64
4 地区名字 5 non-null object
5 省份名字 5 non-null object
6 城市名字 5 non-null object
7 品牌 5 non-null object
8 型号 5 non-null object
9 运行内存 5 non-null object
10 机身内存 5 non-null object
11 数量 5 non-null int64
12 用户名 5 non-null object
13 用户姓名 5 non-null object
14 年龄 5 non-null int64
15 性别 5 non-null int64
16 手机号 5 non-null object
dtypes: datetime64[ns](1), int64(6), object(10)
memory usage: 808.0+ bytes
4.2.3 实例:新冠疫情初期数据分析
from pyecharts import options as opts
from pyecharts. charts import Map
import pandas as pd
current_prov_covid19 = pd. read_excel( "covid19_data.xls" , sheet_name= 0 )
current_prov_covid19
province
confirm
dead
heal
suspect
0
湖北
65187
2615
20948
0
1
广东
1347
7
851
0
2
河南
1271
19
1032
0
3
浙江
1205
1
860
0
4
湖南
1016
4
783
0
5
安徽
989
6
744
0
6
江西
934
1
719
0
7
山东
756
6
377
0
8
江苏
631
0
478
0
9
重庆
576
6
373
0
10
四川
531
3
307
0
11
黑龙江
480
12
249
0
12
北京
400
4
235
0
13
上海
336
3
272
0
14
河北
312
6
261
0
15
福建
294
1
213
0
16
广西
252
2
147
0
17
陕西
245
1
191
0
18
云南
174
2
144
0
19
海南
168
5
129
0
20
贵州
146
2
104
0
21
天津
135
3
96
0
22
山西
133
0
104
0
23
辽宁
121
1
88
0
24
吉林
93
1
65
0
25
甘肃
91
2
81
0
26
香港
89
2
24
0
27
新疆
76
2
34
0
28
内蒙古
75
0
38
0
29
宁夏
71
0
65
0
30
台湾
32
1
5
0
31
青海
18
0
18
0
32
澳门
10
0
7
0
33
西藏
1
0
1
0
data_history_covid19 = pd. read_excel( "covid19_data.xls" , sheet_name= 1 )
data_history_covid19
date
confirm
dead
heal
suspect
0
2020-01-20
291
6
0
54
1
2020-01-21
440
9
0
37
2
2020-01-22
571
17
28
393
3
2020-01-23
830
25
34
1072
4
2020-01-24
1287
41
38
1965
5
2020-01-25
1975
56
49
2684
6
2020-01-26
2744
80
51
5794
7
2020-01-27
4515
106
60
6973
8
2020-01-28
5974
132
103
9239
9
2020-01-29
7711
170
124
12167
10
2020-01-30
9692
213
171
15238
11
2020-01-31
11791
259
243
17988
12
2020-02-01
14380
304
328
19544
13
2020-02-02
17205
361
475
21558
14
2020-02-03
20438
425
632
23214
15
2020-02-04
24324
490
892
23260
16
2020-02-05
28018
563
1153
24702
17
2020-02-06
31116
636
1540
26359
18
2020-02-07
34546
722
2050
27657
19
2020-02-08
37198
811
2649
28942
20
2020-02-09
40171
908
3281
23589
21
2020-02-10
42638
1016
3996
21675
22
2020-02-11
44653
1113
4640
16067
23
2020-02-12
58761
1259
5642
13435
24
2020-02-13
63851
1380
6723
10109
25
2020-02-14
66492
1523
8096
8969
26
2020-02-15
68500
1665
9419
8228
27
2020-02-16
70548
1770
10844
7264
28
2020-02-17
72436
1868
12552
6242
29
2020-02-18
74185
2004
14376
5248
30
2020-02-19
75002
2118
16157
4922
31
2020-02-20
75891
2236
18266
5206
32
2020-02-21
76288
2345
20659
5365
33
2020-02-22
76741
2442
22888
4148
34
2020-02-23
77150
2592
24734
3434
35
2020-02-24
77658
2663
27323
2824
36
2020-02-25
78064
2715
29745
2491
data_world_covid19 = pd. read_excel( "covid19_data.xls" , sheet_name= "data_world" )
data_world_covid19
country
confirm
dead
heal
suspect
0
中国
78630
2747
32546
2358
1
日本
894
7
23
0
2
泰国
40
0
22
0
3
新加坡
93
0
62
0
4
韩国
1595
13
24
0
5
澳大利亚
23
0
0
0
6
德国
26
0
15
0
7
美国
60
0
0
0
8
马来西亚
22
0
7
0
9
越南
16
0
16
0
10
法国
18
2
11
0
11
阿联酋
13
0
3
0
12
加拿大
12
0
4
0
13
印度
3
0
0
0
14
英国
13
0
8
0
15
意大利
470
12
3
0
16
俄罗斯
2
0
0
0
17
菲律宾
3
1
0
0
18
芬兰
2
0
0
0
19
尼泊尔
1
0
0
0
20
西班牙
13
0
2
0
21
斯里兰卡
1
0
0
0
22
柬埔寨
1
0
0
0
23
瑞典
1
0
0
0
24
比利时
1
0
0
0
25
伊朗
139
19
49
320
26
以色列
6
0
1
0
27
黎巴嫩
1
0
0
0
28
伊拉克
5
0
0
0
29
阿富汗
1
0
0
0
30
科威特
26
0
0
0
31
巴林
26
0
0
0
32
阿曼
4
0
0
0
33
克罗地亚
1
0
0
0
34
奥地利
2
0
0
0
35
瑞士
1
0
0
0
36
阿尔及利亚
1
0
0
0
37
巴西
1
0
0
0
38
希腊
1
0
0
0
39
巴基斯坦
2
0
0
0
40
格鲁吉亚
1
0
0
0
41
挪威
1
0
0
0
42
罗马尼亚
1
0
0
0
df = pd. read_excel( r'covid19_data.xls' , sheet_name= 'current_prov' )
df. head( )
province
confirm
dead
heal
suspect
0
湖北
65187
2615
20948
0
1
广东
1347
7
851
0
2
河南
1271
19
1032
0
3
浙江
1205
1
860
0
4
湖南
1016
4
783
0
province = list ( df[ 'province' ] )
pro_value = list ( df[ 'confirm' ] )
pr_data = [ list ( z) for z in zip ( province, pro_value) ]
pr_data
[['湖北', 65187],
['广东', 1347],
['河南', 1271],
['浙江', 1205],
['湖南', 1016],
['安徽', 989],
['江西', 934],
['山东', 756],
['江苏', 631],
['重庆', 576],
['四川', 531],
['黑龙江', 480],
['北京', 400],
['上海', 336],
['河北', 312],
['福建', 294],
['广西', 252],
['陕西', 245],
['云南', 174],
['海南', 168],
['贵州', 146],
['天津', 135],
['山西', 133],
['辽宁', 121],
['吉林', 93],
['甘肃', 91],
['香港', 89],
['新疆', 76],
['内蒙古', 75],
['宁夏', 71],
['台湾', 32],
['青海', 18],
['澳门', 10],
['西藏', 1]]
用pyecharts里的map_visualmap()函数对上述数据进行疫情地图展示,让大家直观的感受到目前的疫情分布情况,作图如下所示。
epi_map = (
Map( )
. add( "2020年2月26日" , pr_data, "china" )
. set_global_opts( title_opts= opts. TitleOpts( title= "nCov疫情分布" ) ,
visualmap_opts= opts. VisualMapOpts(
pieces= [ { "min" : 10000 , "label" : '>10000人' , "color" : 'red' } ,
{ "min" : 500 , "max" : 9999 , "label" : '500-9999人' , "color" : 'orange' } ,
{ "min" : 100 , "max" : 499 , "label" : '100-499人' , "color" : 'gold' } ,
{ "min" : 10 , "max" : 99 , "label" : '10-100人' , "color" : 'cornsilk' } ,
{ "min" : 0 , "max" : 9 , "label" : '1-9人' , "color" : 'white' } , ] ,
is_piecewise= True ) , )
)
epi_map. render( 'map.html' )
epi_map. render_notebook( )
4.2.4 excel文件的写入
xlwt写入excel文件
df.to_excel()
excelData = pd. read_excel( "Athletes_info.xlsx" , sheet_name= "Sheet1" )
excelData. head( )
name
name2
gender
nation
birth
height/cm
weight
event
native place
0
毕晓琳
Bi Xiaolin
女
中国
1989-09-18 00:00:00
NaN
NaN
足球
辽宁
1
鲍语晴
Bao Yuqing
女
中国
NaN
NaN
NaN
艺术体操
浙江
2
艾衍含
Ai Yanhan
女
中国
2002-02-07 00:00:00
NaN
NaN
游泳
湖北
3
卞卡
BIAN Ka
女
中国
1993-01-05 00:00:00
182.0
113kg
女子铅球
江苏
4
陈楠
Chen Nan
女
中国
1983-12-08 00:00:00
197.0
90kg
篮球
青岛胶南
excelData. to_excel( "Athletes_infoOut2.xls" , sheet_name= "Sheet1" , columns= [ 'name' , 'nation' ] )
D:\ProgramFiles\Anaconda3\lib\site-packages\ipykernel_launcher.py:1: FutureWarning: As the xlwt package is no longer maintained, the xlwt engine will be removed in a future version of pandas. This is the only engine in pandas that supports writing in the xls format. Install openpyxl and write to an xlsx file instead. You can set the option io.excel.xls.writer to 'xlwt' to silence this warning. While this option is deprecated and will also raise a warning, it can be globally set and the warning suppressed.
"""Entry point for launching an IPython kernel.
4.3 从Json文件读写
4.3.1 利用以前的方式
读取json文件为str–> str利用json.loads()转换成字典–>再利用字典使用pd.DataFrame()构建dataframe
import json
with open ( 'Animal_species.json' , encoding= 'utf8' ) as f:
json_str = f. read( )
print ( json_str)
{"哺乳动物":["虎","猴子","狗","猫","鹿"],
"鱼类动物":["龙鱼","鲶鱼","鳟鱼","章鱼","草鱼"],
"飞禽类动物":["丹顶鹤","金雕","白鹭","鸽子","天鹅"],
"昆虫类动物":["蝴蝶","金龟子","蜜蜂","蜻蜓","螳螂"]}
type ( json_str)
str
json_str[ '哺乳动物' ]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/var/folders/gv/w6mdpnf51kncpwpf7x4xvtz80000gn/T/ipykernel_845/249757702.py in
----> 1 json_str['哺乳动物']
TypeError: string indices must be integers
json_dict = json. loads( json_str)
json_dict
{'哺乳动物': ['虎', '猴子', '狗', '猫', '鹿'],
'鱼类动物': ['龙鱼', '鲶鱼', '鳟鱼', '章鱼', '草鱼'],
'飞禽类动物': ['丹顶鹤', '金雕', '白鹭', '鸽子', '天鹅'],
'昆虫类动物': ['蝴蝶', '金龟子', '蜜蜂', '蜻蜓', '螳螂']}
type ( json_dict)
dict
json_dict[ '哺乳动物' ]
['虎', '猴子', '狗', '猫', '鹿']
import pandas as pd
pd. DataFrame( json_dict)
哺乳动物
鱼类动物
飞禽类动物
昆虫类动物
0
虎
龙鱼
丹顶鹤
蝴蝶
1
猴子
鲶鱼
金雕
金龟子
2
狗
鳟鱼
白鹭
蜜蜂
3
猫
章鱼
鸽子
蜻蜓
4
鹿
草鱼
天鹅
螳螂
4.3.2 直接利用pandas的方法pd.read_json读取json文件
json_data = pd. read_json( 'Animal_species.json' , encoding= 'utf8' )
json_data
哺乳动物
鱼类动物
飞禽类动物
昆虫类动物
0
虎
龙鱼
丹顶鹤
蝴蝶
1
猴子
鲶鱼
金雕
金龟子
2
狗
鳟鱼
白鹭
蜜蜂
3
猫
章鱼
鸽子
蜻蜓
4
鹿
草鱼
天鹅
螳螂
4.3.3 json文件的写入
json_dict
{'哺乳动物': ['虎', '猴子', '狗', '猫', '鹿'],
'鱼类动物': ['龙鱼', '鲶鱼', '鳟鱼', '章鱼', '草鱼'],
'飞禽类动物': ['丹顶鹤', '金雕', '白鹭', '鸽子', '天鹅'],
'昆虫类动物': ['蝴蝶', '金龟子', '蜜蜂', '蜻蜓', '螳螂']}
type ( json_dict)
dict
jsonStr = json. dumps( json_dict, ensure_ascii= False )
jsonStr
'{"哺乳动物": ["虎", "猴子", "狗", "猫", "鹿"], "鱼类动物": ["龙鱼", "鲶鱼", "鳟鱼", "章鱼", "草鱼"], "飞禽类动物": ["丹顶鹤", "金雕", "白鹭", "鸽子", "天鹅"], "昆虫类动物": ["蝴蝶", "金龟子", "蜜蜂", "蜻蜓", "螳螂"]}'
type ( jsonStr)
str
with open ( "AnimalOut.json" , "w" ) as f:
f. write( jsonStr)
json_data
哺乳动物
鱼类动物
飞禽类动物
昆虫类动物
0
虎
龙鱼
丹顶鹤
蝴蝶
1
猴子
鲶鱼
金雕
金龟子
2
狗
鳟鱼
白鹭
蜜蜂
3
猫
章鱼
鸽子
蜻蜓
4
鹿
草鱼
天鹅
螳螂
json_data. to_json( "AnimalOut2.json" , force_ascii= False )
4.4 从Html表格中获取数据
4.4.1 从Html表格获得数据的主要注意事项
采用requests.get()获取Html数据
pd.read_html()
直读取网页中的表格数据
返回值是一个列表,列表中每个元素是一个dataframe
pandas. read_html( io, match = '.+' , flavor= None , header= None , index_col= None , skiprows= None , attrs= None , parse_dates= False , tupleize_cols= None , thousands= ', ' , encoding= None , decimal= '.' , converters= None , na_values= None , keep_default_na= True , displayed_only= True )
常用的参数:
io:可以是url、html文本、本地文件等;
flavor:解析器;
header:标题行;
skiprows:跳过的行;
attrs:属性,比如 attrs = {‘id’: ‘table’};
parse_dates:解析日期
注意:返回的结果是DataFrame 组成的list 。
import requests
html_data = requests. get( "https://www.tiobe.com/tiobe-index/" )
html_data
html_data. content
b'\r\n\r\n \r\n index | TIOBE - The Software Quality Company \r\n \r\n
\r\n
\r\n
\r\n
\r\n
\r\n
\r\n \r\n \r\n \r\n \r\n\r\n\r\n
\r\n\r\n \r\nTIOBE Index for March 2022 March Headline: Lua is back in the TIOBE index top 20 \r\n\r\nScripting language Lua is back in the top 20 of the TIOBE index. In its heyday in 2011, Lua briefly touched a top 10 position. Whether this is going to happen again is unknown. But it is clear that Lua is catching up in the game development market: easy to learn, fast to execute, and simple to interface with C. This makes Lua a perfect candidate for this job. One of the drivers behind the recent success of Lua is the very popular gaming platform Roblox, which uses Lua as its main programming language. --Paul Jansen CEO TIOBE Software \r\n
\r\nThe TIOBE Programming Community index is an indicator of the popularity of programming \r\nlanguages. The index is updated once a month. The ratings are based on the number of \r\nskilled engineers world-wide, courses and third party vendors. Popular search engines such as\r\nGoogle, Bing, Yahoo!, Wikipedia, Amazon, YouTube and Baidu are used to calculate the ratings.\r\nIt is important to note that the TIOBE index is not about the best programming language or the language\r\nin which most lines of code have been written.
\r\nThe index can be used to check whether your programming skills are still up to date or to make a \r\nstrategic decision about what programming language should be adopted when starting to build a new \r\nsoftware system. The definition of the TIOBE index can be found here .\r\n
\r\n\r\n\r\nMar 2022 \r\nMar 2021 \r\nChange \r\nProgramming Language \r\nRatings \r\nChange \r\n \r\n1 3 Python 14.26% +3.95% 2 1 C 13.06% -2.27% 3 2 Java 11.19% +0.74% 4 4 C++ 8.66% +2.14% 5 5 C# 5.92% +0.95% 6 6 Visual Basic 5.77% +0.91% 7 7 JavaScript 2.09% -0.03% 8 8 PHP 1.92% -0.15% 9 9 Assembly language 1.90% -0.07% 10 10 SQL 1.85% -0.02% 11 13 R 1.37% +0.12% 12 14 Delphi/Object Pascal 1.12% -0.07% 13 11 Go 0.98% -0.33% 14 19 Swift 0.90% -0.05% 15 18 MATLAB 0.80% -0.23% 16 16 Ruby 0.66% -0.52% 17 12 Classic Visual Basic 0.60% -0.66% 18 20 Objective-C 0.59% -0.31% 19 17 Perl 0.57% -0.58% 20 38 Lua 0.56% +0.23% \r\n
\r\n\r\n\r\n\r\n
\r\n
\r\nOther programming languages \r\nThe complete top 50 of programming languages is listed below. This overview is \r\npublished unofficially, because it could be the case that we missed a language. If\r\nyou have the impression there is a programming language lacking, please notify us \r\nat [email protected] overview of all programming languages that we monitor.
\r\n\r\n\r\nPosition Programming Language Ratings \r\n21 Prolog 0.55% 22 COBOL 0.54% 23 Scratch 0.53% 24 SAS 0.52% 25 Groovy 0.52% 26 Rust 0.51% 27 (Visual) FoxPro 0.50% 28 Ada 0.42% 29 PL/SQL 0.39% 30 Fortran 0.39% 31 Kotlin 0.38% 32 Julia 0.32% 33 Lisp 0.31% 34 VBScript 0.31% 35 Dart 0.26% 36 Scala 0.25% 37 D 0.25% 38 Transact-SQL 0.22% 39 RPG 0.22% 40 TypeScript 0.22% 41 PowerShell 0.21% 42 ABAP 0.20% 43 Awk 0.18% 44 VHDL 0.17% 45 Simulink 0.17% 46 OpenEdge ABL 0.16% 47 Clojure 0.16% 48 Logo 0.16% 49 Haskell 0.15% 50 LabVIEW 0.14% \r\n
\r\nThe Next 50 Programming Languages \r\nThe following list of languages denotes #51 to #100. Since the differences are \r\nrelatively small, the programming languages are only listed (in alphabetical\r\norder).\r\n
\r\n\r\n\t\t\r\nABC, ActionScript, Alice, Apex, ATLAS, Bash, bc, BCPL, Boo, Bourne shell, C shell, CL (OS/400), Clipper, CLIPS, CoffeeScript, DCL, DiBOL, Dylan, ECMAScript, Eiffel, Elm, EXEC, F#, Factor, GML, Hack, Harbour, Haxe, Icon, IDL, Io, J#, Korn shell, Ladder Logic, LiveCode, LPC, ML, Monkey, OCaml, OpenCL, Oz, Processing, Q, Racket, REXX, Ring, S-PLUS, Scheme, SPARK, Tcl\r\n
\r\nThis Month's Changes in the Index \r\nThis month the following changes have been made to the definition of the index:\r\n
\r\n \r\nTzvetelin Katchov observed that "Elisp" has been incorrectly spelled "Elips" for many years in the TIOBE index definition. This has been fixed now. Thanks Tzvetelin! \r\n \r\n \r\nThere are lots of mails that still need to be processed. As soon as there is more time available your mail will be answered. Please be patient. \r\n \r\n \r\nVery Long Term History \r\n\r\nTo see the bigger picture, please find below the positions of the top 10 programming languages of many years back. Please note that these are average positions for a period of 12 months.
\r\n\r\nProgramming Language 2022 2017 2012 2007 2002 1997 1992 1987 C 1 2 2 2 2 1 1 1 Python 2 5 8 7 12 28 - - Java 3 1 1 1 1 14 - - C++ 4 3 3 3 3 2 2 4 C# 5 4 4 8 14 - - - Visual Basic 6 15 - - - - - - JavaScript 7 7 10 9 9 21 - - Assembly language 8 10 - - - - - - PHP 9 6 5 5 8 - - - SQL 10 - - - 34 - - - Fortran 20 27 26 21 24 16 3 7 Prolog 24 34 42 27 25 19 14 3 Lisp 31 31 13 14 10 9 11 2 (Visual) Basic - - 7 4 4 3 7 5
\r\nThere are 2 important remarks here:
\r\nThere is a difference between "Visual Basic" and "(Visual) Basic" in the table above. Until 2010, "(Visual) Basic" referred to all possible dialects of Basic, including Visual Basic. After some discussion, it has been decided to split "(Visual) Basic" into all its dialects such as Visual Basic .NET, Classic Visual Basic, PureBasic, and Small Basic, just to name a few. Since Visual Basic .NET has become the major implementation of Visual Basic, it is now called "Visual Basic". The programming language SQL has not been in the TIOBE index for a long time. In 2018, somebody pointed out that SQL is Turing Complete. From that moment on, SQL is part of the TIOBE index. So although this language is very old, it has only a short history in the index. Programming Language Hall of Fame \r\nThe hall of fame listing all "Programming Language of the Year" award winners is shown below. The award is given to the programming language that has the highest rise in ratings in a year.\r\n
Year Winner 2021 2020 2019 2018 2017 2016 2015 2014 2013 2012 2011 2010 2009 2008 2007 2006 2005 2004 2003
\r\n\r\n\r\nBugs & Change Requests \r\nThis is the top 5 of most requested changes and bugs. If you have any suggestions how to improve the index don't hesitate to send an e-mail to [email protected]
\r\n\r\n\r\nApart from "<language> programming", also other queries such as "programming with <language>", "<language> development" and "<language> coding" should be tried out.\r\n \r\n\r\nAdd queries for other natural languages (apart from English). The idea is to start with the Chinese search engine Baidu. This has been implemented partially and will be completed the next few months.\r\n \r\n\r\nAdd a list of all search term requests that have been rejected. This is to minimize the number of recurring mails about Rails, JQuery, JSP, etc.\r\n \r\n\r\nStart a TIOBE index for databases, software configuration management systems and application frameworks.\r\n \r\n\r\nSome search engines allow to query pages that have been added last year. The TIOBE index should only track those recently added pages.\r\n \r\n \r\n
\r\n\r\n\r\nFrequently Asked Questions (FAQ) \r\n\r\n\r\nQ: Am I allowed to show the TIOBE index in my weblog/presentation/publication? \r\nA: Yes, the only condition is to refer to its original source "www.tiobe.com".
\r\n \r\n\r\nQ: How may I nominate a new language to be added to the TIOBE index? \r\nA: If a language meets the criteria of being listed (i.e. it is Turing complete and has an own Wikipedia entry that indicates that it concerns a programming language) and it is sufficiently popular (more than 5,000 hits for +"<language> programming" for Google), then please write an e-mail to [email protected]
\r\n \r\n\r\nQ: I would like to have the complete data set of the TIOBE index. Is this possible? \r\nA: We spent a lot of effort to obtain all the data and keep the TIOBE index up to date. \r\nIn order to compensate a bit for this, we ask a fee of 5,000 US$ for the complete data set. \r\nThe data set runs from June 2001 till today. It started with 25 languages back in 2001, and \r\nnow measures more than 150 languages once a month. The data are available in comma separated \r\nformat. Please contact [email protected] for more information.
\r\n \r\nQ: Why is the maximum taken to calculate the ranking for a grouping, why not the sum? \r\nA: Well, you can do it either way and both are wrong. If you take the sum, then you get the intersection \r\ntwice. If you take the max, then you miss the difference. Which one to choose? Suppose somebody comes up with a new search term that is 10% of \r\nthe original. If you take the max, nothing changes. If you take the sum then the ratings will rise 10%. So \r\ntaking the sum will be an incentive for some to come up with all kinds of obscure terms for a language. That's \r\nwhy we decided to take the max.
\r\nThe proper way to solve this is is of course to take the sum and subtract the intersection. This will give \r\nrise to an explosion of extra queries that must be performed. Suppose a language has a grouping of 15 terms, \r\nthen you have to perform 32,768 queries (all combinations of intersections). \r\nSo this seems not possible either... If somebody has a solution for this, please let us know.
\r\n \r\n\r\nQ: What happened to Java in April 2004? Did you change your methodology? \r\nA: No, we did not change our methodology at that time. Google changed its methodology. \r\nThey performed a general sweep action to get rid of all kinds of web sites that had been \r\npushed up. As a consequence, there was a huge drop for languages such as Java and C++. In \r\norder to minimize such fluctuations in the future, we added two more search engines (MSN \r\nand Yahoo) a few months after this incident.
\r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n\r\n'
html_tables = pd. read_html( html_data. content, encoding= 'utf-8' )
type ( html_tables)
list
len ( html_tables)
4
html_tables[ 0 ]
Mar 2022
Mar 2021
Change
Programming Language
Programming Language.1
Ratings
Change.1
0
1
3
NaN
NaN
Python
14.26%
+3.95%
1
2
1
NaN
NaN
C
13.06%
-2.27%
2
3
2
NaN
NaN
Java
11.19%
+0.74%
3
4
4
NaN
NaN
C++
8.66%
+2.14%
4
5
5
NaN
NaN
C#
5.92%
+0.95%
5
6
6
NaN
NaN
Visual Basic
5.77%
+0.91%
6
7
7
NaN
NaN
JavaScript
2.09%
-0.03%
7
8
8
NaN
NaN
PHP
1.92%
-0.15%
8
9
9
NaN
NaN
Assembly language
1.90%
-0.07%
9
10
10
NaN
NaN
SQL
1.85%
-0.02%
10
11
13
NaN
NaN
R
1.37%
+0.12%
11
12
14
NaN
NaN
Delphi/Object Pascal
1.12%
-0.07%
12
13
11
NaN
NaN
Go
0.98%
-0.33%
13
14
19
NaN
NaN
Swift
0.90%
-0.05%
14
15
18
NaN
NaN
MATLAB
0.80%
-0.23%
15
16
16
NaN
NaN
Ruby
0.66%
-0.52%
16
17
12
NaN
NaN
Classic Visual Basic
0.60%
-0.66%
17
18
20
NaN
NaN
Objective-C
0.59%
-0.31%
18
19
17
NaN
NaN
Perl
0.57%
-0.58%
19
20
38
NaN
NaN
Lua
0.56%
+0.23%
html_tables[ 1 ] . head( )
Position
Programming Language
Ratings
0
21
Prolog
0.55%
1
22
COBOL
0.54%
2
23
Scratch
0.53%
3
24
SAS
0.52%
4
25
Groovy
0.52%
4.4.2 利用pandas.read_html()爬取天气网页数据
实现上学期所学python爬虫类似功能
import requests
html_data = requests. get( "http://www.weather.com.cn/textFC/hb.shtml" )
html_tables = pd. read_html( html_data. content)
len ( html_tables)
35
html_tables[ 0 ]
0
1
2
3
4
5
6
7
8
0
省/直辖市
城市
周一(4月11日)白天
周一(4月11日)白天
周一(4月11日)白天
周一(4月11日)夜间
周一(4月11日)夜间
周一(4月11日)夜间
NaN
1
省/直辖市
城市
天气现象
风向风力
最高气温
天气现象
风向风力
最低气温
NaN
2
北京
北京
-
- -
-
扬沙
北风 3-4级
14
详情
3
北京
海淀
-
- -
-
扬沙
北风 3-4级
13
详情
4
北京
朝阳
-
- -
-
扬沙
北风 3-4级
14
详情
5
北京
顺义
-
- -
-
扬沙
北风 3-4级
14
详情
6
北京
怀柔
-
- -
-
扬沙
北风 3-4级
13
详情
7
北京
通州
-
- -
-
扬沙
北风 3-4级
12
详情
8
北京
昌平
-
- -
-
扬沙
西北风 <3级
12
详情
9
北京
延庆
-
- -
-
扬沙
北风 <3级
9
详情
10
北京
丰台
-
- -
-
扬沙
北风 3-4级
14
详情
11
北京
石景山
-
- -
-
扬沙
北风 3-4级
12
详情
12
北京
大兴
-
- -
-
扬沙
北风 3-4级
12
详情
13
北京
房山
-
- -
-
扬沙
北风 3-4级
13
详情
14
北京
密云
-
- -
-
扬沙
北风 3-4级
10
详情
15
北京
门头沟
-
- -
-
扬沙
北风 3-4级
13
详情
16
北京
平谷
-
- -
-
扬沙
北风 <3级
11
详情
17
北京
东城
-
- -
-
扬沙
北风 3-4级
14
详情
18
北京
西城
-
- -
-
扬沙
北风 3-4级
13
详情
html_tables[ 1 ]
0
1
2
3
4
5
6
7
8
0
省/直辖市
城市
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)夜间
周四(4月7日)夜间
周四(4月7日)夜间
NaN
1
省/直辖市
城市
天气现象
风向风力
最高气温
天气现象
风向风力
最低气温
NaN
2
天津
天津
晴
南风 <3级
23
晴
南风 <3级
10
详情
3
天津
武清
晴
南风 <3级
23
晴
东南风 <3级
9
详情
4
天津
宝坻
晴
南风 <3级
22
晴
东风 <3级
9
详情
5
天津
东丽
晴
东南风 <3级
22
晴
南风 <3级
10
详情
6
天津
西青
晴
南风 <3级
23
晴
南风 <3级
10
详情
7
天津
北辰
晴
南风 <3级
23
晴
南风 <3级
10
详情
8
天津
宁河
晴
南风 3-4级
20
晴
东南风 3-4级
8
详情
9
天津
和平
晴
南风 <3级
23
晴
南风 <3级
10
详情
10
天津
静海
晴
西南风 <3级
23
晴
南风 <3级
9
详情
11
天津
津南
晴
东南风 <3级
22
晴
南风 <3级
10
详情
12
天津
滨海新区
晴
东南风 4-5级
20
晴
南风 4-5级
10
详情
13
天津
河东
晴
南风 <3级
23
晴
南风 <3级
10
详情
14
天津
河西
晴
南风 <3级
23
晴
南风 <3级
10
详情
15
天津
蓟州
晴
西南风 <3级
22
晴
东北风 <3级
8
详情
16
天津
南开
晴
南风 <3级
23
晴
南风 <3级
10
详情
17
天津
河北
晴
南风 <3级
23
晴
南风 <3级
10
详情
18
天津
红桥
晴
南风 <3级
23
晴
南风 <3级
10
详情
html_tables[ 2 ]
0
1
2
3
4
5
6
7
8
0
省/直辖市
城市
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)夜间
周四(4月7日)夜间
周四(4月7日)夜间
NaN
1
省/直辖市
城市
天气现象
风向风力
最高气温
天气现象
风向风力
最低气温
NaN
2
河北
石家庄
晴
南风 3-4级
24
晴
北风 <3级
10
详情
3
河北
保定
晴
西南风 <3级
25
晴
西南风 <3级
7
详情
4
河北
张家口
晴
东南风 3-4级
24
晴
东南风 <3级
9
详情
5
河北
承德
晴
南风 <3级
22
晴
东南风 <3级
4
详情
6
河北
唐山
晴
西南风 <3级
21
晴
南风 <3级
4
详情
7
河北
廊坊
晴
南风 <3级
24
晴
南风 <3级
9
详情
8
河北
沧州
晴
西南风 3-4级
24
晴
南风 3-4级
6
详情
9
河北
衡水
晴
西南风 <3级
24
晴
南风 <3级
9
详情
10
河北
邢台
晴
东南风 <3级
23
晴
西南风 <3级
11
详情
11
河北
邯郸
晴
南风 <3级
22
晴
南风 <3级
10
详情
12
河北
秦皇岛
晴
西南风 3-4级
18
晴
东风 3-4级
4
详情
13
河北
雄安新区
晴
南风 3-4级
26
晴
南风 3-4级
8
详情
html_tables[ 3 ]
0
1
2
3
4
5
6
7
8
0
省/直辖市
城市
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)夜间
周四(4月7日)夜间
周四(4月7日)夜间
NaN
1
省/直辖市
城市
天气现象
风向风力
最高气温
天气现象
风向风力
最低气温
NaN
2
山西
太原
晴
南风 <3级
24
晴
东南风 <3级
3
详情
3
山西
大同
晴
西风 3-4级
22
晴
西风 <3级
3
详情
4
山西
阳泉
晴
西风 3-4级
25
晴
西风 <3级
8
详情
5
山西
晋中
晴
西南风 <3级
23
晴
东南风 <3级
6
详情
6
山西
长治
晴
南风 3-4级
23
晴
南风 3-4级
9
详情
7
山西
晋城
晴
南风 3-4级
25
晴
东南风 <3级
9
详情
8
山西
临汾
晴
西南风 <3级
29
晴
北风 <3级
11
详情
9
山西
运城
晴
东风 <3级
29
晴
东南风 <3级
13
详情
10
山西
朔州
晴
西风 3-4级
22
晴
西南风 <3级
4
详情
11
山西
忻州
晴
东南风 <3级
24
晴
西南风 <3级
5
详情
12
山西
吕梁
晴
西风 3-4级
25
晴
东风 <3级
8
详情
html_tables[ 4 ]
0
1
2
3
4
5
6
7
8
0
省/直辖市
城市
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)白天
周四(4月7日)夜间
周四(4月7日)夜间
周四(4月7日)夜间
NaN
1
省/直辖市
城市
天气现象
风向风力
最高气温
天气现象
风向风力
最低气温
NaN
2
内蒙古
呼和浩特
晴
西风 3-4级
23
晴
西风 4-5级
5
详情
3
内蒙古
包头
晴
西南风 3-4级
23
晴
西南风 <3级
4
详情
4
内蒙古
乌海
晴
西南风 3-4级
25
晴
西南风 3-4级
8
详情
5
内蒙古
乌兰察布
晴
西风 4-5级
18
晴
西风 4-5级
6
详情
6
内蒙古
通辽
晴
西北风 <3级
12
晴
西南风 4-5级
5
详情
7
内蒙古
赤峰
晴
北风 3-4级
17
晴
西南风 <3级
6
详情
8
内蒙古
鄂尔多斯
晴
西南风 3-4级
21
晴
西南风 3-4级
8
详情
9
内蒙古
巴彦淖尔
晴
西风 <3级
25
晴
西风 <3级
8
详情
10
内蒙古
锡林郭勒
晴
西南风 4-5级
18
晴
西南风 4-5级
4
详情
11
内蒙古
呼伦贝尔
多云
西南风 4-5级
6
多云
西南风 3-4级
-4
详情
12
内蒙古
兴安盟
晴
西北风 3-4级
12
晴
西南风 4-5级
1
详情
13
内蒙古
阿拉善盟
晴
西北风 3-4级
22
晴
西北风 3-4级
9
详情
html_tables[ 5 ]
0
1
2
3
4
5
6
7
8
0
省/直辖市
城市
周五(4月8日)白天
周五(4月8日)白天
周五(4月8日)白天
周五(4月8日)夜间
周五(4月8日)夜间
周五(4月8日)夜间
NaN
1
省/直辖市
城市
天气现象
风向风力
最高气温
天气现象
风向风力
最低气温
NaN
2
北京
北京
晴
西南风 <3级
27
晴
北风 <3级
12
详情
3
北京
海淀
晴
南风 <3级
26
晴
北风 <3级
11
详情
4
北京
朝阳
晴
南风 <3级
26
晴
北风 <3级
13
详情
5
北京
顺义
晴
东南风 <3级
26
晴
东北风 <3级
12
详情
6
北京
怀柔
晴
北风 <3级
24
晴
东北风 <3级
11
详情
7
北京
通州
晴
南风 <3级
26
晴
东风 <3级
13
详情
8
北京
昌平
晴
东南风 <3级
26
晴
西北风 <3级
11
详情
9
北京
延庆
晴
东南风 <3级
23
晴
北风 <3级
10
详情
10
北京
丰台
晴
西南风 <3级
26
晴
北风 <3级
13
详情
11
北京
石景山
晴
南风 <3级
25
晴
北风 <3级
11
详情
12
北京
大兴
晴
西南风 <3级
26
晴
北风 <3级
13
详情
13
北京
房山
晴
西南风 <3级
26
晴
东北风 <3级
11
详情
14
北京
密云
晴
南风 <3级
24
晴
东北风 <3级
9
详情
15
北京
门头沟
晴
南风 <3级
26
晴
北风 <3级
13
详情
16
北京
平谷
晴
南风 <3级
26
晴
东北风 <3级
12
详情
17
北京
东城
晴
南风 <3级
26
晴
北风 <3级
13
详情
18
北京
西城
晴
南风 <3级
26
晴
北风 <3级
11
详情
4.5 从数据库获取
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine( 'mysql+pymysql://root:[email protected] :3306/ttsx' )
category_data = pd. read_sql( 'goodscategory' , engine)
category_data
id
cag_name
cag_css
cag_img
0
1
时令水果
fruit
images/banner01.jpg
1
2
海鲜水产
seafood
images/banner02.jpg
2
3
全品肉类
meet
images/banner03.jpg
3
4
美味蛋品
egg
images/banner04.jpg
4
5
新鲜蔬菜
vegetables
images/banner05.jpg
5
6
低温奶制品
ice
images/banner06.jpg
4.6 从word文件获取
4.6.1 python-docx的安装
pip install python-docx
4.6.2 python-docx数据获取的使用
from docx import Document
myDocx = Document( "集合介绍.docx" )
myDocx
paragraphs = myDocx. paragraphs
paragraphs
[,
,
,
,
,
]
paragraphs[ 0 ] . text
'集合'
paragraphs[ 1 ] . text
'Python的集合(set)本身是可变类型,但Python要求放入集合中的元素必须是不可变类型;集合类型与列表和元组的区别是:集合中的元素无序但必须唯一。下面分创建集合、集合的常见操作和集合推导式三部分对集合进行介绍。'
paragraphs[ 2 ] . text
'集合的常见操作'
from docx import Document
myDocx = Document( "集合介绍.docx" )
paragraphs = myDocx. paragraphs
i = 0
for para in paragraphs:
print ( "第%s个段落:" % i)
print ( para. text)
i = i+ 1
print ( "\n" )
第0个段落:
集合
第1个段落:
Python的集合(set)本身是可变类型,但Python要求放入集合中的元素必须是不可变类型;集合类型与列表和元组的区别是:集合中的元素无序但必须唯一。下面分创建集合、集合的常见操作和集合推导式三部分对集合进行介绍。
第2个段落:
集合的常见操作
第3个段落:
集合是可变的,集合中的元素可以动态增加或删除。Python提供了一些内置方法来操作集合,操作集合的常见方法如下表所示。
第4个段落:
操作集合的常见方法
第5个段落:
from docx import Document
myDocx = Document( "集合介绍.docx" )
tables = myDocx. tables
i = 0
for table in tables:
for row in table. rows:
row_content = [ ]
for cell in row. cells[ : ] :
row_content. append( cell. text)
print ( row_content)
print ( "-" * 20 )
['常见方法', '说明']
--------------------
['add(x)', '向集合中添加元素x,x已存在时不作处理']
--------------------
['remove(x)', '删除集合中的元素x,若x不存在则抛出KeyError异常']
--------------------
['discard(x)', '删除集合中的元素x,若x不存在不作处理']
--------------------
['pop()', '随机返回集合中的一个元素,同时删除该元素。若集合为空,抛出KeyError异常']
--------------------
['clear()', '清空集合 ']
--------------------
['copy()', '拷贝集合,返回值为集合']
--------------------
['isdisjoint(T)', '判断集合与集合T是否没有相同的元素,没有返回True,有则返回False']
--------------------
4.6.3 实例:简单可视化分析2022年重庆市免试专升本各个学校数据
from docx import Document
import pandas as pd
doc = Document( "gs1.docx" )
tables = doc. tables
table_content = [ ]
for table in tables:
for row in table. rows:
row_content = [ ]
for cell in row. cells[ : ] :
row_content. append( cell. text)
table_content. append( row_content)
df = pd. DataFrame( table_content[ 1 : ] , columns= table_content[ 0 ] )
df = df. drop_duplicates( subset= [ '学校名称' , '学生姓名' ] , keep= 'first' )
df_result = df. groupby( '学校名称' ) . count( ) . sort_values( '序号' , ascending= False ) [ '学生姓名' ]
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif' ] = [ 'Arial Unicode MS' ]
type ( df_result)
pandas.core.series.Series
table_content
df = pd. DataFrame( table_content[ 1 : ] , columns= table_content[ 0 ] )
df. head( )
序号
学生姓名
学校名称
专业名称
获奖项目名称
获奖等次
备注
0
1
谭欣
重庆三峡医药高等专科学校
中药学
2021年全国职业院校技能大赛高职组中药传统技能赛项
国赛一等奖
1
2
张茂晴
重庆三峡医药高等专科学校
护理
中华人民共和国第一届职业技能大赛健康和社会照护项目
国赛二等奖
2
3
邓栏栏
重庆三峡医药高等专科学校
护理
2021年“巴渝工匠”杯重庆市第十四届高等职业院校学生职业技能竞赛“护理技能”赛项
市赛一等奖
3
4
秦秀娟
重庆三峡医药高等专科学校
中药学
2021年“巴渝工匠”杯重庆市第十四届高等职业院校学生职业技能竞赛“中药传统技能”赛项
市赛一等奖
4
5
石佳
重庆三峡医药高等专科学校
中药学
2021年“巴渝工匠”杯重庆市第十四届高等职业院校学生职业技能竞赛“中药传统技能”赛项
市赛一等奖
df = df. drop_duplicates( )
df. shape
(313, 7)
df = df. drop_duplicates( subset= [ '学校名称' , '学生姓名' ] , keep= 'first' )
df. shape
(309, 7)
df. groupby( '学校名称' ) . count( )
序号
学生姓名
专业名称
获奖项目名称
获奖等次
备注
学校名称
重庆三峡医药高等专科学校
7
7
7
7
7
7
重庆三峡职业学院
20
20
20
20
20
20
重庆交通职业学院
12
12
12
12
12
12
重庆化工职业学院
3
3
3
3
3
3
重庆医药高等专科学校
5
5
5
5
5
5
重庆商务职业学院
28
28
28
28
28
28
重庆城市管理职业学院
23
23
23
23
23
23
重庆城市职业学院
25
25
25
25
25
25
重庆安全技术职业学院
1
1
1
1
1
1
重庆工业职业技术学院
13
13
13
13
13
13
重庆工商职业学院
15
15
15
15
15
15
重庆工程职业技术学院
28
28
28
28
28
28
重庆工贸职业技术学院
13
13
13
13
13
13
重庆幼儿师范高等专科学校
3
3
3
3
3
3
重庆应用技术职业学院
1
1
1
1
1
1
重庆建筑工程职业学院
1
1
1
1
1
1
重庆建筑科技职业学院
6
6
6
6
6
6
重庆文化艺术职业学院
3
3
3
3
3
3
重庆旅游职业学院
11
11
11
11
11
11
重庆水利电力职业技术学院
18
18
18
18
18
18
重庆电子工程职业学院
31
31
31
31
31
31
重庆科创职业学院
6
6
6
6
6
6
重庆能源职业学院
1
1
1
1
1
1
重庆航天职业技术学院
7
7
7
7
7
7
重庆艺术工程职业学院
1
1
1
1
1
1
重庆财经职业学院
28
28
28
28
28
28
重庆青年职业技术学院
3
3
3
3
3
3
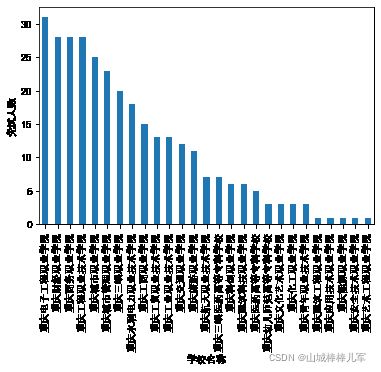
df_result = df. groupby( '学校名称' ) . count( ) . sort_values( '序号' , ascending= False ) [ '学生姓名' ]
df_result
学校名称
重庆电子工程职业学院 31
重庆财经职业学院 28
重庆商务职业学院 28
重庆工程职业技术学院 28
重庆城市职业学院 25
重庆城市管理职业学院 23
重庆三峡职业学院 20
重庆水利电力职业技术学院 18
重庆工商职业学院 15
重庆工贸职业技术学院 13
重庆工业职业技术学院 13
重庆交通职业学院 12
重庆旅游职业学院 11
重庆航天职业技术学院 7
重庆三峡医药高等专科学校 7
重庆科创职业学院 6
重庆建筑科技职业学院 6
重庆医药高等专科学校 5
重庆幼儿师范高等专科学校 3
重庆文化艺术职业学院 3
重庆化工职业学院 3
重庆青年职业技术学院 3
重庆建筑工程职业学院 1
重庆应用技术职业学院 1
重庆能源职业学院 1
重庆安全技术职业学院 1
重庆艺术工程职业学院 1
Name: 学生姓名, dtype: int64
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif' ] = [ 'Arial Unicode MS' ]
df_result. plot. bar( ylabel= '免试人数' )
4.7 从pdf文件读取数据
import pdfplumber
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
/var/folders/gv/w6mdpnf51kncpwpf7x4xvtz80000gn/T/ipykernel_1085/786904664.py in
----> 1 import pdfplumber
ModuleNotFoundError: No module named 'pdfplumber'
4.7.1 安装pdfplumber
pip install pdfplumber
import pdfplumber
4.7.2 使用pdfplumber读取数据
4.7.2.1 读取单页的《集合介绍.pdf》
pdfObj = pdfplumber. open ( "集合介绍.pdf" )
type ( pdfObj)
pdfplumber.pdf.PDF
pdfObj. pages
[]
pdfObj. metadata
{'Author': '孙东',
'Creator': 'Microsoft® Word 2010',
'CreationDate': "D:20200727154403+08'00'",
'ModDate': "D:20200727154403+08'00'",
'Producer': 'Microsoft® Word 2010'}
type ( pdfObj. metadata)
dict
pdfObj. metadata[ 'CreationDate' ]
"D:20200727154403+08'00'"
type ( pdfObj. metadata[ 'CreationDate' ] )
str
pdfObj. pages[ 0 ] . extract_text( )
'集合 \nPython 的集合(set)本身是可变类型,但 Python 要求放入集合中的元素必\n须是不可变类型;集合类型与列表和元组的区别是:集合中的元素无序但必须唯\n一。下面分创建集合、集合的常见操作和集合推导式三部分对集合进行介绍。 \n集合的常见操作 \n集合是可变的,集合中的元素可以动态增加或删除。Python 提供了一些内置\n方法来操作集合,操作集合的常见方法如下表所示。 \n操作集合的常见方法 \n常见方法 说明 \nadd(x) 向集合中添加元素x,x 已存在时不作处理 \nremove(x) 删除集合中的元素x,若x 不存在则抛出KeyError异常 \ndiscard(x) 删除集合中的元素x,若x 不存在不作处理 \n随机返回集合中的一个元素,同时删除该元素。若集合为空,\npop() \n抛出KeyError异常 \nclear() 清空集合 \ncopy() 拷贝集合,返回值为集合 \n判断集合与集合T是否没有相同的元素,没有返回True,\nisdisjoint(T) \n有则返回False \n '
print ( pdfObj. pages[ 0 ] . extract_text( ) )
集合
Python 的集合(set)本身是可变类型,但 Python 要求放入集合中的元素必
须是不可变类型;集合类型与列表和元组的区别是:集合中的元素无序但必须唯
一。下面分创建集合、集合的常见操作和集合推导式三部分对集合进行介绍。
集合的常见操作
集合是可变的,集合中的元素可以动态增加或删除。Python 提供了一些内置
方法来操作集合,操作集合的常见方法如下表所示。
操作集合的常见方法
常见方法 说明
add(x) 向集合中添加元素x,x 已存在时不作处理
remove(x) 删除集合中的元素x,若x 不存在则抛出KeyError异常
discard(x) 删除集合中的元素x,若x 不存在不作处理
随机返回集合中的一个元素,同时删除该元素。若集合为空,
pop()
抛出KeyError异常
clear() 清空集合
copy() 拷贝集合,返回值为集合
判断集合与集合T是否没有相同的元素,没有返回True,
isdisjoint(T)
有则返回False
pdfObj. pages[ 0 ] . extract_words( )
[{'text': '集合',
'x0': 275.57,
'x1': 319.60999999999996,
'top': 93.59635999999989,
'doctop': 93.59635999999989,
'bottom': 115.55635999999993,
'upright': True,
'direction': 1},
{'text': 'Python',
'x0': 114.02,
'x1': 147.824,
'top': 140.61199999999997,
'doctop': 140.61199999999997,
'bottom': 152.61199999999997,
'upright': True,
'direction': 1},
{'text': '的集合(set)本身是可变类型,但',
'x0': 151.22,
'x1': 332.678,
'top': 139.712,
'doctop': 139.712,
'bottom': 152.61199999999997,
'upright': True,
'direction': 1},
{'text': 'Python',
'x0': 336.07,
'x1': 370.006,
'top': 140.61199999999997,
'doctop': 140.61199999999997,
'bottom': 152.61199999999997,
'upright': True,
'direction': 1},
{'text': '要求放入集合中的元素必',
'x0': 373.39,
'x1': 505.39,
'top': 139.712,
'doctop': 139.712,
'bottom': 151.712,
'upright': True,
'direction': 1},
{'text': '须是不可变类型;集合类型与列表和元组的区别是:集合中的元素无序但必须唯',
'x0': 90.024,
'x1': 505.22400000000005,
'top': 157.712,
'doctop': 157.712,
'bottom': 169.712,
'upright': True,
'direction': 1},
{'text': '一。下面分创建集合、集合的常见操作和集合推导式三部分对集合进行介绍。',
'x0': 90.024,
'x1': 498.024,
'top': 175.59199999999998,
'doctop': 175.59199999999998,
'bottom': 187.59199999999998,
'upright': True,
'direction': 1},
{'text': '集合的常见操作',
'x0': 241.49,
'x1': 353.93,
'top': 211.19035999999994,
'doctop': 211.19035999999994,
'bottom': 227.15035999999998,
'upright': True,
'direction': 1},
{'text': '集合是可变的,集合中的元素可以动态增加或删除。Python',
'x0': 114.02,
'x1': 418.234,
'top': 250.74199999999996,
'doctop': 250.74199999999996,
'bottom': 263.64199999999994,
'upright': True,
'direction': 1},
{'text': '提供了一些内置',
'x0': 421.3,
'x1': 505.408,
'top': 250.74199999999996,
'doctop': 250.74199999999996,
'bottom': 262.74199999999996,
'upright': True,
'direction': 1},
{'text': '方法来操作集合,操作集合的常见方法如下表所示。',
'x0': 90.024,
'x1': 366.07,
'top': 268.74199999999996,
'doctop': 268.74199999999996,
'bottom': 280.74199999999996,
'upright': True,
'direction': 1},
{'text': '操作集合的常见方法',
'x0': 266.33,
'x1': 374.35,
'top': 286.62199999999996,
'doctop': 286.62199999999996,
'bottom': 298.62199999999996,
'upright': True,
'direction': 1},
{'text': '常见方法',
'x0': 114.14,
'x1': 162.38,
'top': 306.062,
'doctop': 306.062,
'bottom': 318.062,
'upright': True,
'direction': 1},
{'text': '说明',
'x0': 332.95,
'x1': 357.07,
'top': 306.062,
'doctop': 306.062,
'bottom': 318.062,
'upright': True,
'direction': 1},
{'text': 'add(x)',
'x0': 122.66,
'x1': 154.00400000000002,
'top': 325.322,
'doctop': 325.322,
'bottom': 337.32199999999995,
'upright': True,
'direction': 1},
{'text': '向集合中添加元素x,x',
'x0': 191.09,
'x1': 314.11,
'top': 324.5419999999999,
'doctop': 324.5419999999999,
'bottom': 337.44199999999995,
'upright': True,
'direction': 1},
{'text': '已存在时不作处理',
'x0': 317.23,
'x1': 413.23,
'top': 324.5419999999999,
'doctop': 324.5419999999999,
'bottom': 336.542,
'upright': True,
'direction': 1},
{'text': 'remove(x)',
'x0': 113.3,
'x1': 163.24400000000003,
'top': 343.80199999999996,
'doctop': 343.80199999999996,
'bottom': 355.80199999999996,
'upright': True,
'direction': 1},
{'text': '删除集合中的元素x,若x',
'x0': 191.09,
'x1': 329.11,
'top': 343.022,
'doctop': 343.022,
'bottom': 355.92199999999997,
'upright': True,
'direction': 1},
{'text': '不存在则抛出KeyError异常',
'x0': 332.23,
'x1': 479.38,
'top': 343.022,
'doctop': 343.022,
'bottom': 355.92199999999997,
'upright': True,
'direction': 1},
{'text': 'discard(x)',
'x0': 114.02,
'x1': 162.64400000000003,
'top': 362.1619999999999,
'doctop': 362.1619999999999,
'bottom': 374.1619999999999,
'upright': True,
'direction': 1},
{'text': '删除集合中的元素x,若x',
'x0': 191.09,
'x1': 329.11,
'top': 361.38199999999995,
'doctop': 361.38199999999995,
'bottom': 374.2819999999999,
'upright': True,
'direction': 1},
{'text': '不存在不作处理',
'x0': 332.23,
'x1': 416.23,
'top': 361.38199999999995,
'doctop': 361.38199999999995,
'bottom': 373.38199999999995,
'upright': True,
'direction': 1},
{'text': '随机返回集合中的一个元素,同时删除该元素。若集合为空,',
'x0': 191.09,
'x1': 505.06,
'top': 379.86199999999997,
'doctop': 379.86199999999997,
'bottom': 391.86199999999997,
'upright': True,
'direction': 1},
{'text': 'pop()',
'x0': 125.3,
'x1': 151.292,
'top': 389.64199999999994,
'doctop': 389.64199999999994,
'bottom': 401.64199999999994,
'upright': True,
'direction': 1},
{'text': '抛出KeyError异常',
'x0': 191.09,
'x1': 290.33,
'top': 397.74199999999996,
'doctop': 397.74199999999996,
'bottom': 410.64199999999994,
'upright': True,
'direction': 1},
{'text': 'clear()',
'x0': 122.66,
'x1': 153.92,
'top': 417.02199999999993,
'doctop': 417.02199999999993,
'bottom': 429.02199999999993,
'upright': True,
'direction': 1},
{'text': '清空集合',
'x0': 191.09,
'x1': 239.09,
'top': 416.24199999999996,
'doctop': 416.24199999999996,
'bottom': 428.24199999999996,
'upright': True,
'direction': 1},
{'text': 'copy()',
'x0': 122.66,
'x1': 153.872,
'top': 435.50199999999995,
'doctop': 435.50199999999995,
'bottom': 447.50199999999995,
'upright': True,
'direction': 1},
{'text': '拷贝集合,返回值为集合',
'x0': 191.09,
'x1': 323.09000000000003,
'top': 434.722,
'doctop': 434.722,
'bottom': 446.722,
'upright': True,
'direction': 1},
{'text': '判断集合与集合T是否没有相同的元素,没有返回True,',
'x0': 191.09,
'x1': 493.54,
'top': 453.082,
'doctop': 453.082,
'bottom': 465.98199999999997,
'upright': True,
'direction': 1},
{'text': 'isdisjoint(T)',
'x0': 108.62,
'x1': 168.056,
'top': 462.86199999999997,
'doctop': 462.86199999999997,
'bottom': 474.86199999999997,
'upright': True,
'direction': 1},
{'text': '有则返回False',
'x0': 191.09,
'x1': 267.30199999999996,
'top': 471.082,
'doctop': 471.082,
'bottom': 483.98199999999997,
'upright': True,
'direction': 1}]
pdfObj. pages[ 0 ] . extract_tables( )
[[['', '常见方法', '', '', '说明', ''],
['add(x)', None, None, '向集合中添加元素x,x 已存在时不作处理', None, None],
['remove(x)', None, None, '删除集合中的元素x,若x 不存在则抛出KeyError异常', None, None],
['discard(x)', None, None, '删除集合中的元素x,若x 不存在不作处理', None, None],
['pop()',
None,
None,
'随机返回集合中的一个元素,同时删除该元素。若集合为空,\n抛出KeyError异常',
None,
None],
['clear()', None, None, '清空集合', None, None],
['copy()', None, None, '拷贝集合,返回值为集合', None, None],
['isdisjoint(T)',
None,
None,
'判断集合与集合T是否没有相同的元素,没有返回True,\n有则返回False',
None,
None]]]
pdfObj. close( )
import pdfplumber
i = 0
with pdfplumber. open ( "集合介绍.pdf" ) as pdfObj:
for page in pdfObj. pages:
for table in page. extract_tables( ) :
for row in table:
print ( f"第 { i} 行" )
print ( row)
i = i+ 1
第0行
['', '常见方法', '', '', '说明', '']
第1行
['add(x)', None, None, '向集合中添加元素x,x 已存在时不作处理', None, None]
第2行
['remove(x)', None, None, '删除集合中的元素x,若x 不存在则抛出KeyError异常', None, None]
第3行
['discard(x)', None, None, '删除集合中的元素x,若x 不存在不作处理', None, None]
第4行
['pop()', None, None, '随机返回集合中的一个元素,同时删除该元素。若集合为空,\n抛出KeyError异常', None, None]
第5行
['clear()', None, None, '清空集合', None, None]
第6行
['copy()', None, None, '拷贝集合,返回值为集合', None, None]
第7行
['isdisjoint(T)', None, None, '判断集合与集合T是否没有相同的元素,没有返回True,\n有则返回False', None, None]
import re
i = 0
with pdfplumber. open ( "集合介绍.pdf" ) as pdfObj:
for page in pdfObj. pages:
for table in page. extract_tables( ) :
for row in table:
print ( f"第 { i} 行" )
cleanData = list ( filter ( None , row) )
print ( cleanData)
i = i+ 1
第0行
['常见方法', '说明']
第1行
['add(x)', '向集合中添加元素x,x 已存在时不作处理']
第2行
['remove(x)', '删除集合中的元素x,若x 不存在则抛出KeyError异常']
第3行
['discard(x)', '删除集合中的元素x,若x 不存在不作处理']
第4行
['pop()', '随机返回集合中的一个元素,同时删除该元素。若集合为空,\n抛出KeyError异常']
第5行
['clear()', '清空集合']
第6行
['copy()', '拷贝集合,返回值为集合']
第7行
['isdisjoint(T)', '判断集合与集合T是否没有相同的元素,没有返回True,\n有则返回False']
import pandas as pd
import pdfplumber
with pdfplumber. open ( "集合介绍.pdf" ) as pdfObj:
for page in pdfObj. pages:
for table in page. extract_tables( ) :
tableData = [ ]
for row in table:
cleanData = list ( filter ( None , row) )
tableData. append( cleanData)
pdfTableDf = pd. DataFrame( tableData[ 1 : ] , columns= tableData[ 0 ] )
pdfTableDf
常见方法
说明
0
add(x)
向集合中添加元素x,x 已存在时不作处理
1
remove(x)
删除集合中的元素x,若x 不存在则抛出KeyError异常
2
discard(x)
删除集合中的元素x,若x 不存在不作处理
3
pop()
随机返回集合中的一个元素,同时删除该元素。若集合为空,\n抛出KeyError异常
4
clear()
清空集合
5
copy()
拷贝集合,返回值为集合
6
isdisjoint(T)
判断集合与集合T是否没有相同的元素,没有返回True,\n有则返回False
tableData
[['常见方法', '说明'],
['add(x)', '向集合中添加元素x,x 已存在时不作处理'],
['remove(x)', '删除集合中的元素x,若x 不存在则抛出KeyError异常'],
['discard(x)', '删除集合中的元素x,若x 不存在不作处理'],
['pop()', '随机返回集合中的一个元素,同时删除该元素。若集合为空,\n抛出KeyError异常'],
['clear()', '清空集合'],
['copy()', '拷贝集合,返回值为集合'],
['isdisjoint(T)', '判断集合与集合T是否没有相同的元素,没有返回True,\n有则返回False']]
4.7.2.2 读取多页的《2021jxcg.pdf》
pdfObj2 = pdfplumber. open ( "2021jxcg.pdf" )
type ( pdfObj2)
pdfplumber.pdf.PDF
pdfObj2. pages
[,
,
...
,
]
读取《2021jxcg.pdf》的附件1表格,转换成DataFrame
利用.extract_table()
利用.extract_tables()
import re
import pandas as pd
import pdfplumber
pdfObj2 = pdfplumber. open ( "2021jxcg.pdf" )
table1List = [ ]
for i in range ( 1 , 5 ) :
page = pdfObj2. pages[ i]
table = page. extract_table( )
for row in table:
cleanData = list ( filter ( None , row) )
cleanDataList = [ re. sub( "\n" , '' , value) for value in cleanData[ : ] ]
table1List. append( cleanDataList)
table1Df1 = pd. DataFrame( table1List[ 1 : ] , columns= table1List[ 0 ] )
table1Df1. head( )
申报年度
学院
项目类别
项目名称
成果级别
等级
计分
奖金
人员名单
0
补登记
创新教育学院
质量工程
本/专科英语国家概况(1)(精品课程)
省部级
默认
30
0
曾仲贤、公共账户2、公共账户3、公共账户4、陈显通
1
补登记
城市建设工程学院
教改项目
乡村振兴背景下田园综合体可持续发展研究(脱贫攻坚成果)
省部级
默认
20
0
郭永彦、陈娟娟、江涛、张基斌
2
补登记
会计与金融学院
国家级规划教材
财务会计
国家级
默认
100
0
罗小明、戴锋、张小红
3
补登记
电子信息工程学院
国家级规划教材
C++语言程序设计项目制案例教程
国家级
默认
100
0
陈郑军、蔡茜、龚卫、白小燕、周继萍、胡方霞
4
2021年
党委组织部
质量工程
党建与思想政治教育
省部级
默认
30
3000
王剑华、刘芹、刘玮、黄建、卿竹、周同磊、张基斌
import re
import pandas as pd
import pdfplumber
pdfObj2 = pdfplumber. open ( "2021jxcg.pdf" )
table1List = [ ]
for i in range ( 1 , 5 ) :
page = pdfObj2. pages[ i]
tables = page. extract_tables( )
for table in tables:
for row in table:
cleanData = list ( filter ( None , row) )
cleanDataList = [ re. sub( "\n" , '' , value) for value in cleanData[ : ] ]
table1List. append( cleanDataList)
table1Df2 = pd. DataFrame( table1List[ 1 : ] , columns= table1List[ 0 ] )
table1Df2. head( )
申报年度
学院
项目类别
项目名称
成果级别
等级
计分
奖金
人员名单
0
补登记
创新教育学院
质量工程
本/专科英语国家概况(1)(精品课程)
省部级
默认
30
0
曾仲贤、公共账户2、公共账户3、公共账户4、陈显通
1
补登记
城市建设工程学院
教改项目
乡村振兴背景下田园综合体可持续发展研究(脱贫攻坚成果)
省部级
默认
20
0
郭永彦、陈娟娟、江涛、张基斌
2
补登记
会计与金融学院
国家级规划教材
财务会计
国家级
默认
100
0
罗小明、戴锋、张小红
3
补登记
电子信息工程学院
国家级规划教材
C++语言程序设计项目制案例教程
国家级
默认
100
0
陈郑军、蔡茜、龚卫、白小燕、周继萍、胡方霞
4
2021年
党委组织部
质量工程
党建与思想政治教育
省部级
默认
30
3000
王剑华、刘芹、刘玮、黄建、卿竹、周同磊、张基斌
读取《2021jxcg.pdf》的附件2表格,转换成DataFrame
import pdfplumber
pdfObj2 = pdfplumber. open ( "2021jxcg.pdf" )
table2List = [ ]
for i in range ( 5 , 37 ) :
page = pdfObj2. pages[ i]
tables = page. extract_tables( )
for table in tables:
for row in table:
cleanData = list ( filter ( None , row) )
cleanDataList = [ re. sub( "\n" , '' , value) for value in cleanData[ : ] ]
table2List. append( cleanDataList)
table2Df = pd. DataFrame( table2List[ 1 : ] , columns= table2List[ 0 ] )
table2Df. head( )
申报年度
类别
级别
竞赛名称
认定等次
计分
教师奖金
学生奖金
参与人明细
学生明细
0
补登记
教师比赛
全国一类
全国职业院校技能大赛教学能力比赛
一等奖
120
0
0
蔡茜、胡方霞、陈郑军、周士凯、唐春玲
None
1
补登记
教师比赛
全国三类
全国教育教学信息化大奖赛
三等奖
4
0
0
张弦、许汝才、王传
None
2
补登记
教师比赛
全国三类
国家开放大学学前教育专业学生幼儿集体活动优秀案例评选
三等奖
4
0
0
崔璨
None
3
补登记
教师比赛
全国三类
全国教育教学信息化大奖赛
一等奖
12
0
0
彭翔宇、汪洋、段玭
None
4
补登记
教师比赛
全国三类
全国教育教学信息化大奖赛
三等奖
4
0
0
王嵋、赵娜、尹静
None
table2Df. shape
(578, 10)
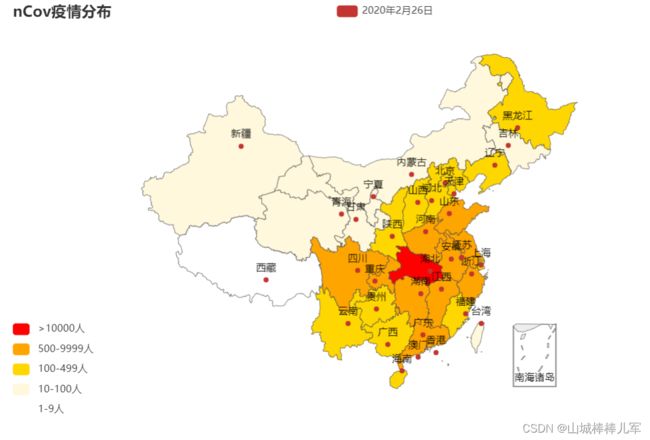
























 Python
Python \r\n
\r\n  \r\n
\r\n  \r\n
\r\n