脑电整合器:用于脑电解码和可视化的卷积转换器
脑电整合器:用于脑电解码和可视化的卷积转换器
EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization
来源
期刊: IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING
作者: Yonghao Song, Graduate Student Member, IEEE, Qingqing Zheng , Member, IEEE, Bingchuan Liu , Student Member, IEEE, and Xiaorong Gao, Member, IEEE
网址: https://ieeexplore.ieee.org/document/9991178
摘要
方法: EEG Conformer ,将局部和全局特征封装在一个统一的EEG分类框架中。卷积模块在整个一维时间和空间卷积层中学习低级的局部特征;自注意力模块直接连接,以提取局部时间特征内的全局相关性;基于全连接层的简单分类器模块被用于预测EEG信号的类别
评估: 在基于EEG的运动想象和情绪识别范式的三个公开数据集上进行了广泛的实验
结果: 达到了最先进的性能,有很大的潜力成为通用EEG解码的新基线
代码: https://github.com/eeyhsong/EEG-Conformer.
方法

图1. Conformer的架构
Conformer由卷积模块、自注意力模块和全连接分类器组成。
卷积模块: 输入是经过预处理的EEG数据,分别在时间维度和电极通道维度上应用时间和空间卷积层。空间滤波器学习不同电极通道之间的相互作用表示;批归一化加速训练,缓解过拟合;平均池化平滑时间特征避免过拟合,降低复杂度。
自注意力模块: 输入是卷积模块的时空表示,通过度量特征图中不同时间位置之间的全局相关性,进一步提取长期时间特征。采用交叉熵作为损失函数。
分类器: 若干个全连接层组成
预处理
- 用6阶切比雪夫滤波器来带通滤波:滤除高、低频噪声
- Z - score标准化:减少波动和非平稳性
数据集
BCI竞赛IV数据集2a: 9名被试的EEG数据组成。运动想象任务共4个,涵盖了移动左手、右手、双脚、舌头的想象。
BCI 竞赛IV数据集2b: 9名受试者的EEG数据组成。有两个运动想象任务,涵盖左右手运动想象。
SEED3: 15名被试的基于情绪的脑电信号组成。通过十五个电影片段刺激被试产生三种情绪,包括积极、中性和消极。
基线比较
BCI竞赛IV数据集2a(多分类)

Conformer比FBCSP的准确率显著提高了10.91%。其他深度学习方法,如ConvNet和EEGNet,其性能优于FBCSP,表明基于CNN的方法具有较强的特征表示能力。然而,由于感知域有限,这些基于CNN的方法只关注局部特征,而忽略了全局相关性,这可能会降低对相干EEG序列的解码精度。不同的是,本文方法在原始CNN的基础上,通过集成Transformer架构来封装局部和全局依赖关系。因此,Conformer在大多数受试者上获得了较好的结果,在平均准确率( p < 0.05)和kappa上获得了显著的提升。
BCI 竞赛IV数据集2b(二分类)

二分类结果表现出与数据集I中相似的趋势。与FBCSP ( p < 0.05)相比,Conformer显著提升了整体性能,在被试1上甚至提高了12.5 %的准确率。与仅使用CNN架构的其他端到端方法相比,有明显的提升,其中ConvNet ( p < 0.05)和EEGNet ( p < 0.01)分别提升了5.25 %和4.15 %。本文方法的平均准确率和kappa值在几乎所有受试者上仍然领先于DRDA,进一步验证了本文方法的有效性。
SEED3(多类别脑电情感数据集)
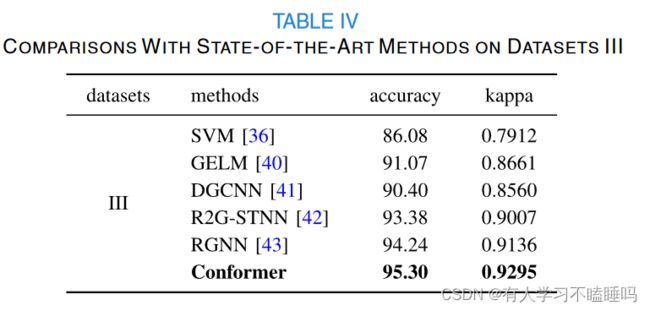
本文与SVM等机器学习方法进行了比较,该方法首先在该数据集上取得了显著的效果;图正则极限学习机( Graph regularized extreme learning machine,GELM )采用单前馈层学习具有判别性的特征,而区域全局时空神经网络( Regions to global spatial-temporal neural network,R2G-STNN ) 采用双向长短期记忆网络学习情绪脑电信号的时空特征。此外,基于图学习不同脑电通道之间内在关系的神经网络,如动态图卷积神经网络( DGCNN ) 和正则化图神经网络( RGNN ) 也被纳入比较。
与其他最先进的方法相比,Conformer在Dataset III上仍然具有竞争力。通过这种方式,我们的方法在运动想象和情绪识别范式上都取得了令人印象深刻的表现,说明我们的方法具有良好的泛化性。
训练过程
在图像处理中,Transformer模型往往需要大量的数据进行预训练,才能在下游任务中取得较好的效果。然而,由于用于校准的数据有限,在EEG构象异构体中没有使用预训练。
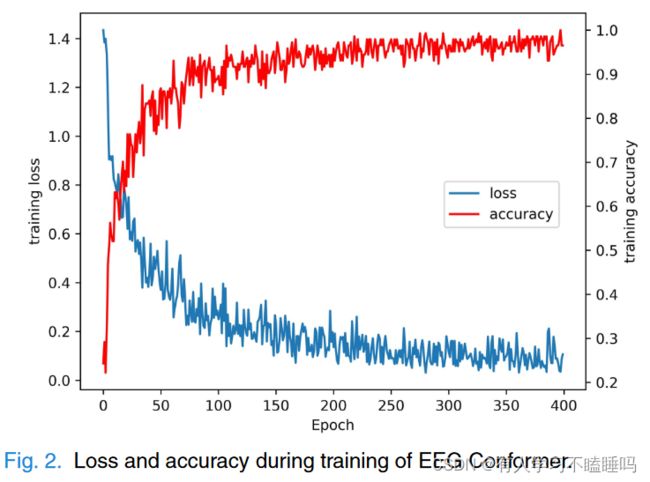
图2中展示了训练过程中损失和准确率的变化趋势。在自注意力模块的轻量级使用下,该过程是稳定的。可以看出,模型在第250历元左右收敛较快。
消融实验
EEG Conformer相对于基于CNN的方法的关键改进是增加了基于注意力的Transformer模块用于学习全局表示。同时,数据增广也可能对最终结果有所贡献。数据集I上的消融研究。
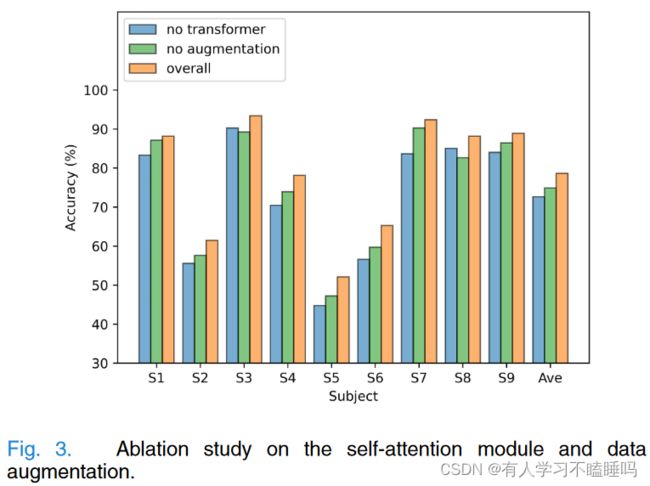
当去除Transformer部分后,在每个主题上的结果都有大幅度的下降。被试6降低幅度最大,为8.68 %,被试3降低幅度最小,为3.12 %。平均精度显著下降了6.02 % ( p < 0 . 01)。数据增强策略有助于提高模型的性能。与未进行数据增强的方法相比,整体性能提升了3.75 % ( p < 0.01)的平均准确率。有趣的是,区分度较好的被试1的提升幅度仅为1.04 %,而原本表现较差的被试5和6的提升幅度更为显著,分别达到了4.86 %和5.56 %。因此,在训练过程中引入数据增强,增强了构象异构体的鲁棒性。
参数敏感性
本文评估了自注意力模块中自注意力层的深度N,注意力头的数量h,以及池化核的设计对模块的影响。

图4探究深度对EEG Conformer的影响
对于数据集I,当深度从0增加到1 ( p < 0.01)时,准确率有明显的提升。Transformer的引入确实有助于EEG解码。随着深度的增加,参数数量成比例增加,这使得模型的性价比降低。
同样在数据集 II上的评估也显示了Conformer对自注意力深度的不敏感性。

图5探究了注意力头的数量对EEG Conformer的影响
从盒型图看,不同头数对结果的影响没有明显的规律。不同受试者的分布无明显差异。平均准确率保持小幅波动,在数据集I上极差仅为1.43 %,在数据集II上极差仅为1.02 %。随着头部数量的增加,性能有轻微的上升趋势,但随后下降。当头数取10时比头数取1时在数据集I和数据集II ( p > 0.05)上的平均准确率分别高出0.82 %和0.50 %。总体而言,头部数量的变化尚未表现出对特征学习的显著促进作用。

图6比较了不同池化核选择对模型性能影响
当核尺寸开始增长时,平均精度有了大幅度的提升。通过将内核从15增加到45,在数据集I上获得了13.08 % ( p < 0 . 01)的增益。之后,结果趋于平缓,并没有显著上升。
模型的可解释性
特征分布: t分布随机近邻嵌入( t-SNE )是一种流行的统计降维与可视化方法。
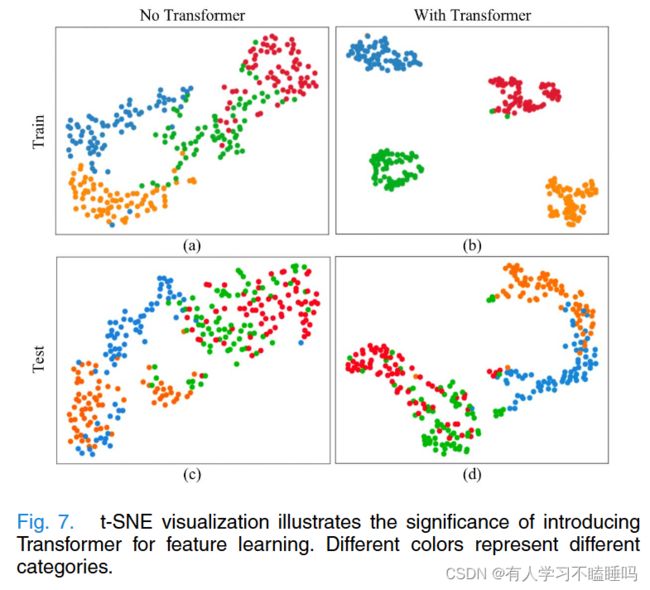
图7为经过充分训练后的数据集I中被试1在有无Transformer情况下的特征分布
对于训练数据,在没有Transformer的帮助下,不同类别的特征比较接近。加入Transformer后,类间距离变大,类内距离变小,如图7 ( b )所示。另一方面,在没有Transformer的情况下,类别之间的混叠现象明显,使得图7 ( d )中的类别边界更加尖锐。
全局表示: 引入Transformer来学习EEG数据中的全局时间依赖关系,即从时间序列中定位对解码任务更重要的信息。

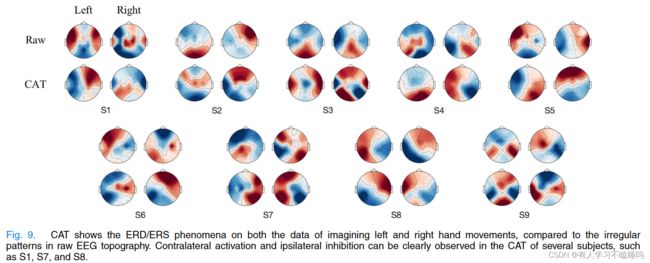
图8为数据集1的地形图和梯度加权类激活映射
图中的第一行表示每个受试者的所有训练试验都是对地形的平均。不同被试之间没有明显的活动脑区线索。第二行采用CAM来监控自注意力模块在脑电特征上关注的时间段
在运动想象过程中,EEG数据被绘制成一个圆,从上往下顺时针旋转。不同的激活在不同的时间呈现。正如预期的那样,所有受试者的数据在试验开始时都是衰减的,这可能预示着运动意图的延迟。
本文进一步提出了一种新的应用于EEG的可视化方法-类激活拓扑( CAT )。脑电地形图绘制在归一化数据乘以归一化CAM上。从图8的第三行开始,CAM加权的EEG数据大部分集中在运动皮层的区域,与运动想象的范式一致。进一步,将想象左手运动和右手运动的原始EEG和CAT绘制在图9中。我们惊讶地发现了事件相关去同步( ERD )和事件相关同步( ERS )现象。与不规则的原始脑电地形图相比,在一些被试的CAT中观察到明显的对侧激活和同侧抑制,如第一名和第八名。