综述|如何利用LLM做多模态任务?
作者|胡安文(知乎同名)
进NLP群—>加入NLP交流群
大型语言模型LLM(Large Language Model)具有很强的通用知识理解以及较强的逻辑推理能力,但其只能处理文本数据。虽然已经发布的GPT4具备图片理解能力,但目前还未开放多模态输入接口并且不会透露任何模型上技术细节。因此,现阶段,如何利用LLM做一些多模态任务还是有一定的研究价值的。
本文整理了近两年来基于LLM做vision-lanuage任务的一些工作,并将其划分为4个类别:
冻住LLM,训练视觉编码器等额外结构以适配LLM,例如mPLUG-Owl,LLaVA,Mini-GPT4,Frozen,BLIP2,Flamingo,PaLM-E[1]
将视觉转化为文本,作为LLM的输入,例如PICA(2022),PromptCap(2022)[2],ScienceQA(2022)[3]
利用视觉模态影响LLM的解码,例如ZeroCap[4],MAGIC
利用LLM作为理解中枢调用多模态模型,例如VisualChatGPT(2023), MM-REACT(2023)
接下来每个类别会挑选代表性的工作进行简单介绍:
训练视觉编码器等额外结构以适配LLM
这部分工作是目前关注度最高的工作,因为它具有潜力来以远低于多模态通用模型训练的代价将LLM拓展为多模态模型。
随着GPT4的火热,近期涌现了大量的工作,如LLaVA, Mini-GPT4和mPLUG-Owl。这三个工作的主要区别如下图所示,总体而言,模型结构和训练策略方面大同小异,主要体现在LLaVA和MiniGPT4都冻住基础视觉编码器,mPLUG-Owl将其放开,得到了更好的视觉文本跨模态理解效果;在实验方面mPLUG-Owl首次构建并开源视觉相关的指令理解测试集OwlEval,通过人工评测对比了已有的模型,包括BLIP2、LLaVA、MiniGPT4以及系统类工作MM-REACT。
 mPLUG-Owl vs MiniGPT4 vs LLaVA
mPLUG-Owl vs MiniGPT4 vs LLaVA
mPLUG-Owl
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl是阿里巴巴达摩院mPLUG系列的最新工作,继续延续mPLUG系列的模块化训练思想,将LLM迁移为一个多模态大模型。此外,Owl第一次针对视觉相关的指令评测提出一个全面的测试集OwlEval,通过人工评测对比了已有工作,包括LLaVA和MIniGPT4。该评测集以及人工打分的结果都进行了开源,助力后续多模态开放式回答的公平对比。
模型结构:采用CLIP ViT-L/14作为"视觉基础模块",采用LLaMA初始化的结构作为文本解码器,采用类似Flamingo的Perceiver Resampler结构对视觉特征进行重组(名为"视觉摘要模块"),如图。
 mPLUG-Owl模型结构
mPLUG-Owl模型结构
模型训练
第一阶段: 主要目的也是先学习视觉和语言模态间的对齐。不同于前两个工作,Owl提出冻住视觉基础模块会限制模型关联视觉知识和文本知识的能力。因此Owl在第一阶段只冻住LLM的参数,采用LAION-400M,COYO-700M,CC以及MSCOCO训练视觉基础模块和视觉摘要模块。
第二阶段: 延续mPLUG和mPLUG-2中不同模态混合训练对彼此有收益的发现,Owl在第二阶段的指令微调训练中也同时采用了纯文本的指令数据(102k from Alpaca+90k from Vicuna+50k from Baize)和多模态的指令数据(150k from LLaVA)。作者通过详细的消融实验验证了引入纯文本指令微调在指令理解等方面带来的收益。第二阶段中视觉基础模块、视觉摘要模块和原始LLM的参数都被冻住,参考LoRA,只在LLM引入少量参数的adapter结构用于指令微调。
实验分析
除了训练策略,mPLUG-Owl另一个重要的贡献在于通过构建OwlEval评测集,对比了目前将LLM用于多模态指令回答的SOTA模型的效果。和NLP领域一样,在指令理解场景中,模型的回答由于开放性很难进行评估。
SOTA对比:本文初次尝试构建了一个基于50张图片(21张来自MiniGPT-4, 13张来自MM-REACT, 9张来自BLIP-2, 3来自GPT-4以及4张自收集)的82个视觉相关的指令回答评测集OwlEval。由于目前并没有合适的自动化指标,本文参考Self-Intruct对模型的回复进行人工评测,打分规则为:A="正确且令人满意";B="有一些不完美,但可以接受";C="理解了指令但是回复存在明显错误";D="完全不相关或不正确的回复"。实验证明Owl在视觉相关的指令回复任务上优于已有的OpenFlamingo、BLIP2、LLaVA、MiniGPT4以及集成了Microsoft 多个API的MM-REACT。作者对这些人工评测的打分同样进行了开源以方便其他研究人员检验人工评测的客观性。
多维度能力对比:多模态指令回复任务中牵扯到多种能力,例如指令理解、视觉理解、图片上文字理解以及推理等。为了细粒度地探究模型在不同能力上的水平,本文进一步定义了多模态场景中的6种主要的能力,并对OwlEval每个测试指令人工标注了相关的能力要求以及模型的回复中体现了哪些能力。在该部分实验,作者既进行了Owl的消融实验,验证了训练策略和多模态指令微调数据的有效性,也和上一个实验中表现最佳的baseline——MiniGPT4进行了对比,结果显示Owl在各个能力方面都优于MiniGPT4。
LLaVA
Visual instruction tuning
自然语言处理领域的instruction tuning可以帮助LLM理解多样化的指令并生成比较详细的回答。LLaVA首次尝试构建图文相关的instruction tuning数据集来将LLM拓展到多模态领域。具体来说,基于MSCOCO数据集,每张图有5个较简短的ground truth描述和object bbox(包括类别和位置)序列,将这些作为text-only GPT4的输入,通过prompt的形式让GPT4生成3种类型的文本:1)关于图像中对象的对话;2)针对图片的详细描述;3)和图片相关的复杂的推理过程。注意,这三种类型都是GPT4在不看到图片的情况下根据输入的文本生成的,为了让GPT4理解这些意图,作者额外人工标注了一些样例用于in-context learning。
模型结构:采用CLIP的ViT-L/14作为视觉编码器,采用LLaMA作为文本解码器,通过一个简单的线性映射层将视觉编码器的输出映射到文本解码器的词嵌入空间,如图。
 LLaVA模型结构
LLaVA模型结构
模型训练1/ 第一阶段:跨模态对齐预训练,从CC3M中通过限制caption中名词词组的最小频率过滤出595k图文数据,冻住视觉编码器和文本解码器,只训练线性映射层;2. 第二阶段:指令微调,一版针对多模态聊天机器人场景,采用自己构建的158k多模态指令数据集进行微调;另一版针对Science QA数据集进行微调。微调阶段,线性层和文本解码器(LLaMA)都会进行优化。
实验分析
消融实验: 在30个MSCOCO val的图片上,每张图片设计3个问题(对话、详细描述、推理),参考 Vicuna[8],用GPT4对LLaVA和text-only GPT4的回复进行对比打分,报告相对text-only GPT4的相对值。
SOTA对比: 在Science QA上微调的版本实现了该评测集上的SOTA效果。
Mini-GPT4
Minigpt-4: Enhancing vision-language under- standing with advanced large language models
Mini-GPT4和LLaVA类似,也发现了多模态指令数据对于模型在多模态开放式场景中表现的重要性。
模型结构:采用BLIP2的ViT和Q-Former作为视觉编码器,采用LLaMA经过自然语言指令微调后的版本Vicuna作为文本解码器,也通过一个线性映射层将视觉特征映射到文本表示空间,如图:
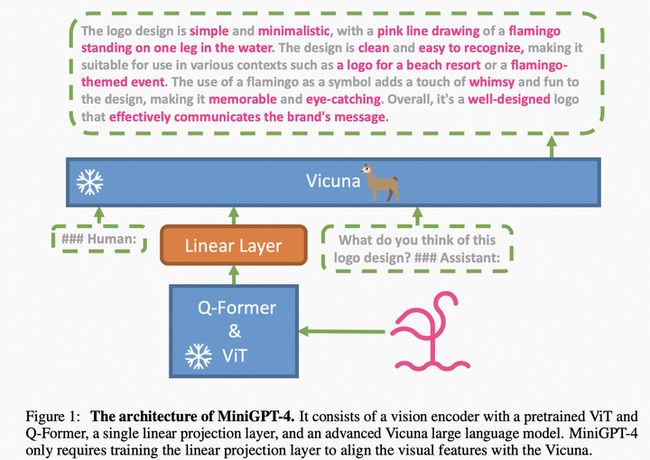 MiniGPT4模型结构
MiniGPT4模型结构
模型训练
第一阶段:目标通过大量图文对数据学习视觉和语言的关系以及知识,采用CC+SBU+LAION数据集,冻住视觉编码器和文本解码器,只训练线性映射层;
第二阶段:作者发现只有第一阶段的预训练并不能让模型生成流畅且丰富的符合用户需求的文本,为了缓解这个问题,本文也额外利用ChatGPT构建一个多模态微调数据集。具体来说,1)其首先用阶段1的模型对5k个CC的图片进行描述,如果长度小于80,通过prompt让模型继续描述,将多步生成的结果合并为一个描述;2)通过ChatGPT对于构建的长描述进行改写,移除重复等问题;3)人工验证以及优化描述质量。最后得到3.5k图文对,用于第二阶段的微调。第二阶段同样只训练线性映射层。
DeepMind于2021年发表的Frozen,2022年的Flamingo以及Saleforce 2023年的BLIP2也都是这条路线,如图所示。

Frozen
Multimodal Few-Shot Learning with Frozen Language Models.
Frozen训练时将图片编码成2个vision token,作为LLM的前缀,目标为生成后续文本,采用Conceptual Caption作为训练语料。Frozen通过few-shot learning/in-context learning做下游VQA以及image classification的效果还没有很强,但是已经能观察到一些多模态in-context learning的能力。
Flamingo
Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo为了解决视觉feature map大小可能不一致(尤其对于多帧的视频)的问题,用Perceiver Resampler (类似DETR的解码器)生成固定长度的特征序列(64个token),并且在LLM的每一层之前额外增加了一层对视觉特征进行注意力计算的cross-attention layer,以实现更强的视觉相关性生成。Flamingo的训练参数远高于Frozen,因此采用了大量的数据:1)MultiModal MassiveWeb(M3W) dataset:从43million的网页上收集的图文混合数据,转化为图文交叉排列的序列(根据网页上图片相对位置,决定在转化为序列后,token 在文本token系列中的位置);2)ALIGN (alt-text & image Pairs): 1.8 million图文对;3)LTIP (LongText & Image Pairs):312 million图文对;4)VTP (Video & Text Pairs) :27 million视频文本对(平均一个视频22s,帧采样率为1FPS)。类似LLM,Flamingo的训练目标也为文本生成,但其对于不同的数据集赋予不同的权重,上面四部分权重分别为1.0、0.2、0.2、0.03,可见图文交叉排列的M3W数据集的训练重要性是最高的,作者也强调这类数据是具备多模态in-context learning能力的重要因素。Flamingo在多个任务上实现了很不错的zero-shot以及few-shot的表现。
BLIP2
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP2采用了类似于Flamingo的视觉编码结构,但是采用了更复杂的训练策略。其包含两阶段训练,第一阶段主要想让视觉编码器学会提取最关键的视觉信息,训练任务包括image-Text Contrastive Learning, Image-grounded Text Generation以及Image-Text Matching;第二阶段则主要是将视觉编码结构的输出适配LLM,训练任务也是language modeling。BLIP2的训练数据包括MSCOCO,Visual Genome,CC15M,SBU,115M来自于LAION400M的图片以及BLIP在web images上生成的描述。BLIP2实现了很强的zero-shot capitoning以及VQA的能力,但是作者提到未观察到其in-context learning的能力,即输入样例并不能提升它的性能。作者分析是因为训练数据里不存在Flamingo使用的图文交错排布的数据。不过Frozen也是没有用这类数据,但是也观察到了一定的in-context learning能力。因此多模态的in-context learning能力可能和训练数据、训练任务以及位置编码方法等都存在相关性。
将视觉转化为文本,作为LLM的输入
PICA
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
以PICA为例,它的目标是充分利用LLM中的海量知识来做Knowledge-based QA。给定一张图和问题,以往的工作主要从外部来源,例如维基百科等来检索出相关的背景知识以辅助答案的生成。但PICA尝试将图片用文本的形式描述出来后,直接和问题拼在一起作为LLM的输入,让LLM通过in-context learning的方式直接生成回答,如图所示。
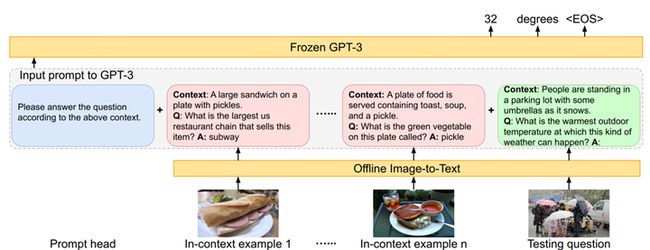 PICA
PICA
In-context learning的效果比较依赖example/demonstration的质量,为此PICA的作者利用CLIP挑选了和当前测试样例在问题和图片上最接近的16个训练样例作为examples。
利用视觉模态影响LLM的解码
MAGIC
Language Models Can See: Plugging Visual Controls in Text Generation
以MAGIC为例,它的目标是让LLM做image captioning的任务,它的核心思路是生成每一个词时,提高视觉相关的词的生成概率,公式如图所示。
 MAGIC解码公式
MAGIC解码公式
该公式主要由三部分组成:
LLM预测词的概率
退化惩罚(橙色)
视觉相关性(红色)
退化惩罚主要是希望生成的词能带来新的信息量。视觉相关性部分为基于CLIP计算了所有候选词和图片的相关性,取softmax之后的概率作为预测概率。
利用LLM作为理解中枢调用多模态模型
Visual ChatGPT
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
以微软Visual ChatGPT为例,它的目标是使得一个系统既能和人进行视觉内容相关的对话,又能进行画图以及图片修改的工作。为此,Visual ChatGPT采用ChatGPT作为和用户交流的理解中枢,整合了多个视觉基础模型(Visual Foundation Models),通过prompt engineering (即Prompt Manager)告诉ChatGPT各个基础模型的用法以及输入输出格式,让ChatGPT决定为了满足用户的需求,应该如何调用这些模型,如图所示。
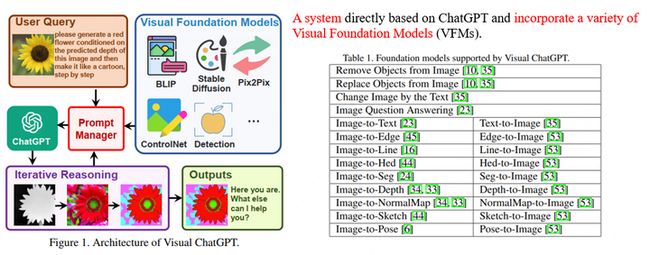
微软另一个小组稍晚一段时间提出的MM-REACT[5]也是同样的思路,区别主要在于prompt engineering的设计以及MM-REACT更侧重于视觉的通用理解和解释,包含了很多Microsoft Azure API,例如名人识别、票据识别以及Bing搜索等。
总结
对比几种融入方式:
“训练视觉编码器等额外结构以适配LLM”具有更高的研究价值,因为其具备将任意模态融入LLM,实现真正意义多模态模型的潜力,其难点在于如何实现较强的in-context learning的能力。
“将视觉转化为文本,作为LLM的输入”和“利用视觉模态影响LLM的解码”可以直接利用LLM做一些多模态任务,但是可能上限较低,其表现依赖于外部多模态模型的能力。
“利用LLM作为理解中枢调用多模态模型”可以方便快捷地基于LLM部署一个多模态理解和生成系统,难点主要在于prompt engineering的设计来调度不同的多模态模型。
参考资料
[1]
PaLM-E: https://arxiv.org/abs/2303.03378
[2]PromptCap: https://arxiv.org/abs/2211.09699
[3]ScienceQA: https://arxiv.org/abs/2209.09513
[4]例如ZeroCap: https://arxiv.org/abs/2111.14447
[5]MM-REACT: https://arxiv.org/abs/2303.11381
进NLP群—>加入NLP交流群