Python asyncio的基本使用
Asyncio在python3.6、3.7的基本使用方式
- 什么是事件循环(event loop):
一方面,它类似于 CPU ,顺序执行协程的代码;另一方面,它相当于操作系统,完成协程的调度,即一个协程“暂停”时,决定接下来执行哪个协程。
- 可等待对象(Future、协程、Task):
把可等待对象注册进事件循环里,事件循环会安排他们执行并返回结果
import asyncio
# 用async定义一个协程
async def wait_and_print(wait_time, name):
# 这是一个模拟io阻塞的定时器,在sleep(或者io)的时候,
# 协程会把控制权交还给event_loop,让他去执行别的协程
await asyncio.sleep(wait_time)
print(f'wait_time:{wait_time}, name:{name}')
# 直接 wait_and_print(2, 'a') 这样不能运行一个协程,要将它注册入事件循环中
# 在python3.7
# asyncio.run(wait_and_print(2, 'a'))
# 在python3.6
loop = asyncio.get_event_loop()
# run_until_complete 这个函数会阻塞运行直到里面的协程运行完毕返回结果
loop.run_until_complete(wait_and_print(2, 'a'))
结果输出:wait_time:2, name:a
常用到的对象和函数及其使用场景
协程对象:要运行一个协程对象,必须把他注册到事件循环里,那么有三种方法
-
直接注册到event_loop中
-
在别的协程中await它,间接的注册到事件循环里
-
把它包装成一个Task对象,此时会直接注册入’下一轮’的事件循环中
import asyncio
async def wait_and_print(wait_time, name):
# await会阻塞直到后面跟的协程运行完毕返回结果
await asyncio.sleep(wait_time)
print(f'wait_time:{wait_time}, name:{name}')
# # 1.直接注册入事件循环
# loop = asyncio.get_event_loop()
# loop.run_until_complete(wait_and_print(2, 'a'))
#
#
# # 2.间接注册入事件循环
# # 在其他协程中await它,再把那个协程注册入事件循环
# async def run():
# await wait_and_print(2, 'a')
#
#
# loop = asyncio.get_event_loop()
# loop.run_until_complete(run())
# # 3.打包成Task对象
#
async def run():
# 关于下面两个函数的区别后面会在说完Task和Future对象后进行讨论
# python3.6
# asyncio.ensure_future(wait_and_print(2, 'a'))
# python3.7
print(asyncio.create_task(wait_and_print(2, 'a')))
await asyncio.sleep(3)
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
结果输出:
<Task pending coro=<wait_and_print() running at /Users/frostw/Documents/share_new/share/第二部分/1.py:4>>
wait_time:2, name:a
Task
把协程对象打包成一个Task,这个过程会直接注册这个协程进入事件循环中
它的主要作用是帮助event_loop进行调度,如果Task发现它打包的协程在await一个对象(执行一个io操作),则该Task会挂起该协程的执行,把控制权交回event_loop,让他去运行其他Task,当该对象运行完毕,Task会将打包的协程恢复运行
Future
Task的父类,一个比较底层的对象,用于支持底层回调式代码与高层异步/等待式代码交互,它有一些方法,例如result(),set_result(),done(),cancelled(),cancel()等,但是一般不会使用Future对象,如果要使用也是在Task对象使用
enture_future()和create_task()
一般的使用就是传入一个协程对象,然后打包成一个task对象后返回,但是enture_future()还有别的用法,下面是python作者相关的讨论
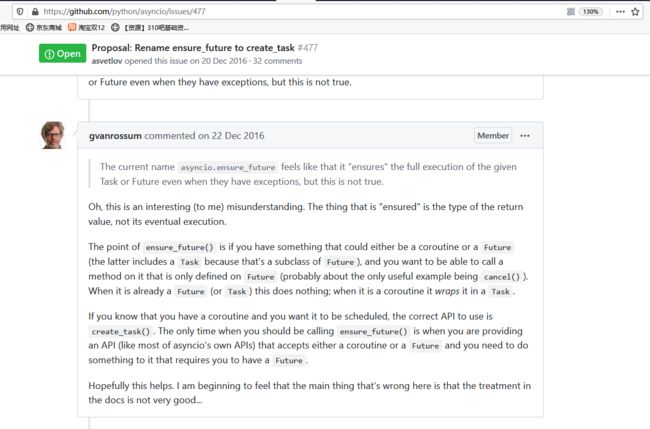
大概的翻译如下:
- 如果有个可能是协程或者future或者task的对象,你希望能对它使用仅在Future类中定义过的方法(这里或许唯一能举出的有用的函数的例子就是cancel()),就对它使用entrue_future。这个函数会在当传入的对象已经是一个Future或者Task,就啥也不干,原封不动返回它,当它是一个协程则把他打包成一个Task并返回。
- 现版本来说(python3.7)如果你就是想把一个协程注册入事件循环运行,那就该用create_task(),如果是想提供一个底层些的API(类似asyncio自带的api)时候要用到Future对象,那就用enture_future()
asyncio.wait_for()
-
wait_for会检查传进去的对象,如果是协程则会打包成task
-
等待可等待对象完成,并可以设置超时
-
这里涉及到一个取消task/future的概念,也就是之前提到的future.cancel(),如果超时则把future取消
import asyncio
async def wait_and_print(wait_time, name):
await asyncio.sleep(wait_time)
print(f'wait_time:{wait_time}, name:{name}')
async def run():
# 为了我们方便查看这个任务的后续状态,先打包成一个task_
task_ = asyncio.create_task(wait_and_print(1000, 'a'))
try:
await asyncio.wait_for(task_, timeout=3)
except asyncio.TimeoutError:
print('发现任务超时,已被取消')
# 查看被取消后的状态
print(task_)
print(task_.cancelled())
asyncio.run(run())
结果输出:
发现任务超时,已被取消
>
True
asyncio.gather()
-
并发的运行协程,或者task,并把他们的结果按照顺序放在列表中返回
-
gather会检查传进去的对象,如果是协程则会打包成task
import asyncio
async def wait_and_print(wait_time, name):
await asyncio.sleep(wait_time)
print(f'wait_time:{wait_time}, name:{name}')
# 添加一个return
return f'wait_time:{wait_time}, name:{name}'
# loop = asyncio.get_event_loop()
# # 会把三个协程打包成任务task加入循环
# gather_result = loop.run_until_complete(asyncio.gather(wait_and_print(1, 'a'),
# wait_and_print(2, 'b'),
# wait_and_print(1, 'c')))
# print(gather_result)
async def wait_and_cancel_task(wait_time, task):
await asyncio.sleep(wait_time)
task.cancel()
print(f'{task} 被取消了')
return f'{task} 被取消了'
async def run():
# 封装一个b_task
b_task = asyncio.create_task(wait_and_print(5, 'b'))
print(b_task)
gather_ = asyncio.gather(wait_and_print(1, 'a'),
b_task,
wait_and_print(3, 'c'),
# 在这里把他给取消了
wait_and_cancel_task(4, b_task), return_exceptions=True)
print(await gather_)
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
结果输出:
>
wait_time:1, name:a
wait_time:3, name:c
wait_for= cb=[gather.._done_callback() at /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/asyncio/tasks.py:691]> 被取消了
['wait_time:1, name:a', CancelledError(), 'wait_time:3, name:c', ' wait_for= cb=[gather.._done_callback() at /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/asyncio/tasks.py:691]> 被取消了']
- 协程并不一定按顺序执行,但结果是按顺序返回
- 关于被取消:
- return_exceptions 参数为False(默认):所有协程任务所引发的首个异常会立刻作为gather的结果返回,但其他任务不会被取消
- return_exceptions 参数为True:所有协程任务所引发的异常不会立刻返回,会聚合在列表中当作普通结果返回
- 如果gather本身被取消,那它所有的协程任务都会被取消
结合例子讨论loop的调度过程
官网示例1
import asyncio
async def compute(x, y):
print("Compute %s + %s ..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()
示例2
import asyncio
async def wait_and_print(wait_time, name):
await asyncio.sleep(wait_time)
print(f'wait_time:{wait_time}, name:{name}')
async def run():
asyncio.create_task(wait_and_print(1, 'a'))
await wait_and_print(1, 'b')
if __name__ == '__main__':
asyncio.run(run())
# 原因:create_task会把任务自动安排到下一轮事件循环
结果输出:
wait_time:1, name:b
wait_time:1, name:a
示例3
import asyncio
async def wait_and_print(wait_time, name):
await asyncio.sleep(wait_time)
print(f'wait_time:{wait_time}, name:{name}')
async def run():
asyncio.create_task(wait_and_print(1, 'a'))
await asyncio.sleep(0)
await wait_and_print(1, 'b')
if __name__ == '__main__':
asyncio.run(run())
# 原因:await asyncio.sleep(0)会使得task将控制权交还给loop进行下一个任务
结果输出:
wait_time:1, name:a
wait_time:1, name:b
示例4
import asyncio
async def wait_and_print(wait_times, name):
await asyncio.sleep(wait_times)
print(f'wait_times:{wait_times} name:{name}')
async def run():
asyncio.ensure_future(asyncio.ensure_future(wait_and_print(1, 'f')))
asyncio.ensure_future(wait_and_print(1, 'b'))
asyncio.ensure_future(asyncio.gather(wait_and_print(1, 'd')))
asyncio.create_task(wait_and_print(1, 'a'))
await wait_and_print(1, 'c')
asyncio.ensure_future(asyncio.gather(wait_and_print(2, 'g'), wait_and_print(0, 'h')))
await wait_and_print(1, 'e')
# c>f>b>d>a>h>e>
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
wait_times:1 name:c
wait_times:1 name:f
wait_times:1 name:b
wait_times:1 name:d
wait_times:1 name:a
wait_times:0 name:h
wait_times:1 name:e
基于Asyncio的发布订阅程序
import asyncio
import random
async def mama(zhuo_zi):
while True:
zheng_bao_zi = random.randint(1, 10)
await asyncio.sleep(zheng_bao_zi)
pan_zi = random.randint(1, 10)
[await zhuo_zi.put(bao_zi) for bao_zi in range(pan_zi)]
print(f'妈妈花了{zheng_bao_zi}秒,上桌了{pan_zi}个包子')
print(f'现在桌子上的包子总数:{zhuo_zi.qsize()}')
async def xiao_ming(zhuo_zi):
while True:
if zhuo_zi.qsize() == 0:
print(f'小明发现没包子了,等一会')
await asyncio.sleep(1)
else:
await zhuo_zi.get()
chi_bao_zi = random.randint(1, 3)
await asyncio.sleep(chi_bao_zi)
print(f'小明花了{chi_bao_zi}秒吃了个包子')
async def run(mama_number, xiao_ming_number):
zhuo_zi = asyncio.Queue()
mama_tasks = [asyncio.create_task(mama(zhuo_zi)) for number in range(mama_number)]
xiao_ming_tasks = [asyncio.create_task(xiao_ming(zhuo_zi)) for number in range(xiao_ming_number)]
return mama_tasks, xiao_ming_tasks
if __name__ == '__main__':
loop = asyncio.get_event_loop()
mama_tasks, xiao_ming_tasks = loop.run_until_complete(run(mama_number=3, xiao_ming_number=8))
loop.run_forever()
简易的通过协程池发送请求的爬虫
import asyncio
import logging
import time
import json
log = logging
def parsed_response(response):
"""
解析 response
:param : response byte
:return: status_code int
headers dict
str body
"""
r = response.decode()
header, body = r.split('\r\n\r\n', 1)
h = header.split('\r\n')
status_code = int(h[0].split()[1])
headers = {}
for line in h[1:]:
k, v = line.split(': ')
headers[k] = v
return status_code, headers, body
def parse_url(url):
"""
对 url 进行字符串拆分
:param url: http://httpbin.org/headers
:return: (protocol, host, port, path)
"""
# 检查协议
protocol = 'http'
if url[:7] == 'http://':
u = url.split('://')[1]
elif url[:8] == 'https://':
protocol = 'https'
u = url.split('://')[1]
else:
u = url
# https://g.cn:1234/hello
# g.cn:1234/hello
# 检查默认 path
i = u.find('/')
if i == -1:
host = u
path = '/'
else:
host = u[:i]
path = u[i:]
# 检查端口
port_dict = {
'http': 80,
'https': 443,
}
# 默认端口
port = port_dict[protocol]
if ':' in host:
h = host.split(':')
host = h[0]
port = int(h[1])
return protocol, host, port, path
def save_response(queue, save_name='data'):
"""
将一个队列里的数据保存到json文本
:param queue: asyncio.Queue
:param save_name: str json文本的name
:return:
"""
data = []
for i in range(queue.qsize()):
status_code, headers, body = queue.get_nowait()
save_dict = dict(id=i,
status_code=status_code,
headers=headers,
body=body)
data.append(save_dict)
s = json.dumps(data, indent=2, ensure_ascii=False)
with open(save_name, 'w', encoding='utf-8') as f:
f.write(s)
async def connect(host, port, path='headers', tls=False):
"""
:param host: str: httpbin.org
:param port: int: 80/443
:param tls: bool
:param path: str: headers/
:return: response content (bytes)
"""
log.debug(f'connect to {host}:{port}, tls:{tls}')
if tls is True:
protocol = 'https'
reader, writer = await asyncio.open_connection(
host,
port,
ssl=True)
else:
protocol = 'http'
reader, writer = await asyncio.open_connection(
host,
port)
log.debug(f'{host}:{port}, tls:{tls} connected')
request = f'GET {protocol}://{host}:{port}/{path} HTTP/1.1\r\nHost:{host}\r\n\r\n'
# 由于设置了timeout, 在以下操作任意阶段皆有可能超时导致协程任务被丢弃
# 所以必须添加finally字段用来正确关闭连接
try:
log.debug(f'request send--{request}')
writer.write(request.encode('utf-8'))
await writer.drain()
log.debug(f'request send done--{request}')
log.debug(f'response recv start')
response = b''
# 接收response
while True:
line = await reader.readline()
response += line
if line == b'}\n':
break
log.debug(f'response recv done')
log.debug(f'close connect')
writer.close()
return response
finally:
writer.close()
async def http_request(url):
"""
返回请求后的状态码,页面内容
:param url: http://httpbin.org/headers
:return: state_code, header, body
"""
protocol, host, port, path = parse_url(url)
if port == 443:
response = await connect(host, port, tls=True)
else:
response = await connect(host, port, tls=False)
status_code, headers, body = parsed_response(response)
return status_code, headers, body
async def create_one_coroutine(url_queue, coros_queue, response_queue, task_timeout=1):
"""
:param url_queue:
:param coros_queue:
:param response_queue:
:param task_timeout:
:return:
"""
# 用当前协程池队列大小给予协程id
thread_id = coros_queue.qsize()
log.info(f'添加一个协程{thread_id}')
# 将协程放入协程池队列
await coros_queue.put(thread_id)
while True:
# 如果urls任务队列空了,则从协程池队列中去掉一个协程
if url_queue.empty() is True:
await coros_queue.get()
log.info(f'协程{thread_id}关闭')
break
url = await url_queue.get()
log.info(f'协程{thread_id}从队列中拿取一个url, 还剩{url_queue.qsize()}个url')
try:
# 将http_request(url)返回的response装入response队列中
await response_queue.put(
await asyncio.wait_for(http_request(url), timeout=task_timeout))
# asyncio.wait_for()超时会引发一个TimeoutError
except asyncio.TimeoutError:
log.info(f'协程{thread_id}请求超时,丢弃这次请求')
else:
log.info(f'协程{thread_id}成功获取一次响应')
async def if_threads_done(threads_queue, response_queue):
"""
监视urls协程的管理协程,
每1秒对urls协程队列进行一次判定,
如果urls协程队列已空则关闭loop
:param response_queue: asyncio.Queue
:param threads_queue: asyncio.Queue
:return:
"""
start_time = time.time()
while True:
# 每隔一秒检查一次协程池队列是否为空
await asyncio.sleep(1)
if threads_queue.empty() is True:
log.info(f'所有协程已经关闭,关闭loop')
break
# 如果协程池队列已经没有协程在运行,则统计时间->保存responses->关闭loop
log.info(f'获取成功的响应数量:{response_queue.qsize()}')
save_response(response_queue, save_name='response.txt')
use_time = time.time() - start_time
log.info(f'总耗时:{str(use_time)}')
log.info(f'响应已存入response.txt')
loop = asyncio.get_running_loop()
loop.stop()
async def run_with_pool(urls, threads=5, task_timeout=5):
"""
:param urls: list
:param threads: int
:param task_timeout: int
:return: loop
"""
# 创建一个url队列,用于协程提取url
url_queue = asyncio.Queue()
# 创建一个coroutines队列,用于管理协程
coros_queue = asyncio.Queue()
# 创建一个response队列,用于保存response
response_queue = asyncio.Queue()
# 将urls列表加入队列
[url_queue.put_nowait(url) for url in urls]
# 创建协程池
coros = [create_one_coroutine(url_queue, coros_queue, response_queue, task_timeout)
for i in range(0, threads)]
[asyncio.create_task(coro) for coro in coros]
# 创建一个监视urls协程的管理协程, 每1秒对urls协程队列进行一次判定,如果urls协程队列已空则关闭loop
asyncio.create_task(if_threads_done(coros_queue, response_queue))
def main():
tasks = [
'http://httpbin.org'
] * 50
tasks += [
'https://httpbin.org'
] * 50
loop = asyncio.get_event_loop()
loop.create_task(run_with_pool(tasks, threads=15, task_timeout=3))
try:
loop.run_forever()
finally:
loop.close()
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
main()