使用webots进行强化学习
之前学习强化学习使用的环境是gym,但这毕竟不是长久之计,最后是需要使用机器人仿真的环境进行仿真,这里选择了webots。
首先是建立模型。
之前使用gym进行过通过控制车体运动来保持杆不倒的训练。

那么webots也从这开始。
首先在soildworks中建模,导入模型到webots中。
之前有写过方法:将solidworks装配体模型导入webots并进行控制

也是一车一杆。
随后模仿gym的写法编写环境的控制代码
主要包括__init__、step、reset三个函数
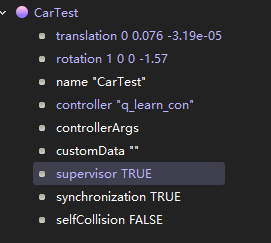
而为了使webots中机器人复位,需要使用Supervisor,而不是Robot
为了使用Supervisor,必需将机器人上supervisor设为true
from controller import Robot,Motor,DistanceSensor,Supervisor,GPS
class Env:
def __init__(self):
# create the Robot instance.
self.robot = Supervisor() #使用Supervisor需要将机器人上supervisor设为true
# robot = Robot()
self.wheel_r = 35 #mm 轮子半径
self.wheel_dis = 145 # 左右轮子距离
# get the time step of the current world.
self.timestep = int(self.robot.getBasicTimeStep()) #ms
self.motor_fl = self.robot.getMotor('jointfl')
self.motor_fr = self.robot.getMotor('jointfr')
self.motor_bl = self.robot.getMotor('jointbl')
self.motor_br = self.robot.getMotor('jointbr')
self.ds = self.robot.getPositionSensor('jointlink_sensor')
self.ds.enable(self.timestep)
self.gps = self.robot.getGPS('gps_body')
self.gps.enable(self.timestep)
self.pos_l=self.pos_r = 0
self.vel = 0 #最大为0.35
self.rad = 0
self.link_speed = 0 #rad/s
self.link_ang = self.link_ang_pre = 0 #rad
self.pos = 0
self.action_sapce=[0,1,2] # 0 不动 1左 2右
def step(self,action):
self.robot.step(self.timestep) #延时
self.link_ang_pre = self.link_ang
self.link_ang = self.ds.getValue() #rad
self.link_speed = (self.link_ang - self.link_ang_pre)*1000 / self.timestep
self.pos = self.gps.getValues()[2]
if action == 0 : self.vel = 0
if action == 1 : self.vel = -0.3
if action == 2 : self.vel = 0.3
vr = self.vel + self.rad*self.wheel_dis/2
vl = self.vel - self.rad*self.wheel_dis/2
self.pos_r += vr/self.wheel_r * self.timestep
self.pos_l += vl/self.wheel_r * self.timestep
self.motor_fl.setPosition(-self.pos_l)
self.motor_bl.setPosition(-self.pos_l)
self.motor_fr.setPosition(self.pos_r)
self.motor_br.setPosition(self.pos_r)
self.state = [self.pos,self.vel,self.link_ang,self.link_speed]
if self.pos>0.5 or self.pos<-0.5 or self.link_ang >0.5 or self.link_ang <-0.5: self.done = True #超出范围
else : self.done = False
if self.link_ang <0.1 and self.link_ang >-0.1 : self.reward=1 #保持在一定角度
else: self.reward= -50
if self.done: self.reward=-100
return [self.state,self.reward,self.done,[]]
def reset(self):
self.robot.simulationReset()
self.robot.step(self.timestep)
print('reset')
self.pos_l=self.pos_r = 0
self.vel = 0
self.rad = 0
self.link_speed = 0 #rad/s
self.link_ang = self.link_ang_pre = 0 #rad
self.pos = 0
self.state = [self.pos,self.vel,self.link_ang,self.link_speed]
self.done = False
return self.state
后面将之前的Qlearning代码改改,再整合一下。
"""python_con_test controller."""
# You may need to import some classes of the controller module. Ex:
# from controller import Robot, Motor, DistanceSensor
from controller import Robot,Motor,DistanceSensor,Supervisor,GPS
import numpy as np
import time
import os
import pickle
class Env:
def __init__(self):
# create the Robot instance.
self.robot = Supervisor() #使用Supervisor需要将机器人上supervisor设为true
# robot = Robot()
self.wheel_r = 35 #mm 轮子半径
self.wheel_dis = 145 # 左右轮子距离
# get the time step of the current world.
self.timestep = int(self.robot.getBasicTimeStep()) #ms
self.motor_fl = self.robot.getMotor('jointfl')
self.motor_fr = self.robot.getMotor('jointfr')
self.motor_bl = self.robot.getMotor('jointbl')
self.motor_br = self.robot.getMotor('jointbr')
self.ds = self.robot.getPositionSensor('jointlink_sensor')
self.ds.enable(self.timestep)
self.gps = self.robot.getGPS('gps_body')
self.gps.enable(self.timestep)
self.pos_l=self.pos_r = 0
self.vel = 0 #最大为0.35
self.rad = 0
self.link_speed = 0 #rad/s
self.link_ang = self.link_ang_pre = 0 #rad
self.pos = 0
self.action_sapce=[0,1,2] # 0 不动 1左 2右
def step(self,action):
self.robot.step(self.timestep) #延时
self.link_ang_pre = self.link_ang
self.link_ang = self.ds.getValue() #rad
self.link_speed = (self.link_ang - self.link_ang_pre)*1000 / self.timestep
self.pos = self.gps.getValues()[2]
if action == 0 : self.vel = 0
if action == 1 : self.vel = -0.3
if action == 2 : self.vel = 0.3
vr = self.vel + self.rad*self.wheel_dis/2
vl = self.vel - self.rad*self.wheel_dis/2
self.pos_r += vr/self.wheel_r * self.timestep
self.pos_l += vl/self.wheel_r * self.timestep
self.motor_fl.setPosition(-self.pos_l)
self.motor_bl.setPosition(-self.pos_l)
self.motor_fr.setPosition(self.pos_r)
self.motor_br.setPosition(self.pos_r)
self.state = [self.pos,self.vel,self.link_ang,self.link_speed]
if self.pos>0.5 or self.pos<-0.5 or self.link_ang >0.5 or self.link_ang <-0.5: self.done = True #超出范围
else : self.done = False
if self.link_ang <0.1 and self.link_ang >-0.1 : self.reward=1 #保持在一定角度
else: self.reward= -50
if self.done: self.reward=-100
return [self.state,self.reward,self.done,[]]
def reset(self):
self.robot.simulationReset()
self.robot.step(self.timestep)
print('reset')
self.pos_l=self.pos_r = 0
self.vel = 0
self.rad = 0
self.link_speed = 0 #rad/s
self.link_ang = self.link_ang_pre = 0 #rad
self.pos = 0
self.state = [self.pos,self.vel,self.link_ang,self.link_speed]
self.done = False
return self.state
class QLearning:
def __init__(self, learning_rate=0.01, reward_decay=0.99, e_greedy=0.9):
#self.target # 目标状态(终点)
self.lr = learning_rate # 学习率
self.gamma = reward_decay # 回报衰减率
self.epsilon = e_greedy # 探索/利用 贪婪系数
self.num_pos = 4 #分为多少份
self.num_vel = 3
self.num_linkang = 10
self.num_linkvel = 10
self.num_actions = 3
self.actions = [0,1,2] # 可以选择的动作空间 离散化
# q_table是一个二维数组 # 离散化后的状态共有num_pos*num_vel中可能的取值,每种状态会对应一个行动# q_table[s][a]就是当状态为s时作出行动a的有利程度评价值
self.q_table = np.random.uniform(low=-1, high=1, size=(self.num_pos*self.num_vel*self.num_linkang*self.num_linkvel, self.num_actions)) # Q值表
self.pos_bins = self.toBins(-0.5, 0.50, self.num_pos)
self.vel_bins = self.toBins(-4, 4, self.num_vel)
self.linkang_bins = self.toBins(-0.5,0.5, self.num_linkang)
self.linkvel_bins = self.toBins(-5.0, 5.0, self.num_linkvel)
# 根据本次的行动及其反馈(下一个时间步的状态),返回下一次的最佳行动
def choose_action(self,state):
# 假设epsilon=0.9,下面的操作就是有0.9的概率按Q值表选择最优的,有0.1的概率随机选择动作
# 随机选动作的意义就是去探索那些可能存在的之前没有发现但是更好的方案/动作/路径
if np.random.uniform() < self.epsilon:
# 选择最佳动作(Q值最大的动作)
action = np.argmax(self.q_table[state])
else:
# 随机选择一个动作
action = np.random.choice(self.actions)
return action
# 分箱处理函数,把[clip_min,clip_max]区间平均分为num段, 如[1,10]分为5.5
def toBins(self,clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)[1:-1] #第一项到倒数第一项
# 分别对各个连续特征值进行离散化 如[1,10]分为5.5 小于5.5取0 大于取5.5取1
def digit(self,x, bin):
n = np.digitize(x,bins = bin)
return n
# 将观测值observation离散化处理
def digitize_state(self,observation):
# 将矢量打散回4个连续特征值
pos, vel , link_ang, link_vel = observation
# 分别对各个连续特征值进行离散化(分箱处理)
digitized = [self.digit(pos,self.pos_bins),
self.digit(vel,self.vel_bins),
self.digit(link_ang,self.linkang_bins),
self.digit(link_vel,self.linkvel_bins)]
# 将离散值再组合为一个离散值,作为最终结果
return ((digitized[1]*self.num_pos + digitized[0]) * self.num_vel + digitized[2])*self.num_linkang + digitized[3]
# 学习,主要是更新Q值
def learn(self, state, action, r, next_state):
next_action = np.argmax(self.q_table[next_state])
q_predict = self.q_table[state, action]
q_target = r + self.gamma * self.q_table[next_state, next_action] # Q值的迭代更新公式
self.q_table[state, action] += self.lr * (q_target - q_predict) # update
def env_test():
env = Env()
observation = env.reset() #状态包括以下4个因素 小车的位置、速度 木棒的角度、速度
while True: #
action = np.random.choice([0, 1,2]) #动作 0不动 1 左 2右
observation, reward, done, info = env.step(action)
print(observation,action,reward,done)
if(done): break
def train():
env = Env()
agent = QLearning()
# with open(os.getcwd()+'/tmp/test_car.model', 'rb') as f:
# agent = pickle.load(f)
for i in range(520): #训练次数
observation = env.reset() #状态包括以下4个因素 小车的位置、速度 木棒的角度、速度
state = agent.digitize_state(observation) #状态标准化
for t in range(800): #一次训练最大运行次数 一次运行时间为5ms
action = agent.choose_action(state) #动作 0 1向左 2向右
observation, reward, done, info = env.step(action)
next_state = agent.digitize_state(observation)
print(i,' : ',t)
print(observation,action,reward,done,state,next_state)
agent.learn(state,action,reward,next_state)
state = next_state
if done: #done 重新加载环境
print("Episode finished after {} timesteps".format(t+1))
break
# env.render() # 更新并渲染画面
print(agent.q_table)
#保存
with open(os.getcwd()+'/tmp/test_car.model', 'wb') as f:
pickle.dump(agent, f)
def test():
env = Env()
with open(os.getcwd()+'/tmp/test_car.model', 'rb') as f:
agent = pickle.load(f)
agent.epsilon = 1
observation = env.reset() #状态包括以下4个因素 小车的位置、速度 木棒的角度、速度
state = agent.digitize_state(observation) #状态标准化
for t in range(800): #一次训练最大运行次数
action = agent.choose_action(state) #动作
observation, reward, done, info = env.step(action)
next_state = agent.digitize_state(observation)
print(observation,action,reward,done,state,next_state)
state = next_state
# env_test()
train()
# test()
然后就可以开始训练了。
刚开始的时候机器人运动不了几帧杆就超出了允许的范围,然后重置。
大概训练了300次左右,小车就已经可以保持杆好几秒直立了。
webots中还有个好处就是可以使用最大速度运行仿真环境。
点击快速仿真,将不会显示界面,加快速度,如果中途想看看训练进行的如何了,就可以点击中间的正常速度,查看仿真情况。


最终效果: