分布式数据实现跨设备数据同步的N个秘密 | 分布式数据管理解析(二)
上期我们给大家带来分布式数据管理如何完成数据存储,数据同步,数据跨端访问,并保证整个过程中跨设备数据安全的解读。
这都得益于分布式数据管理平台抽象出的三大关键技术——分布式数据库,分布式文件系统和融合搜索。
那么这三大技术究竟如何具体实现全场景多设备上的数据保存,数据同步,数据访问,让我们一一来详细解读。今天我们率先进入分布式数据库的原理解析和接口介绍。
分布式数据库
分布式数据库主要应用在跨设备的数据库数据同步上,例如实现手机和手表,手机和大屏,手机跟手机等设备间的联系人、日历、媒体等源数据同步。
这么说可能有点抽象,我们来看一个具体的例子,下图中手机上增加的日历信息,可以通过分布式数据库的技术将新增数据自动同步到手表上。此外,当日历过期后可通过手表删除,删除的动作也会通过分布式数据库的技术,自动同步到手机上,达到一个端端的自动协同。
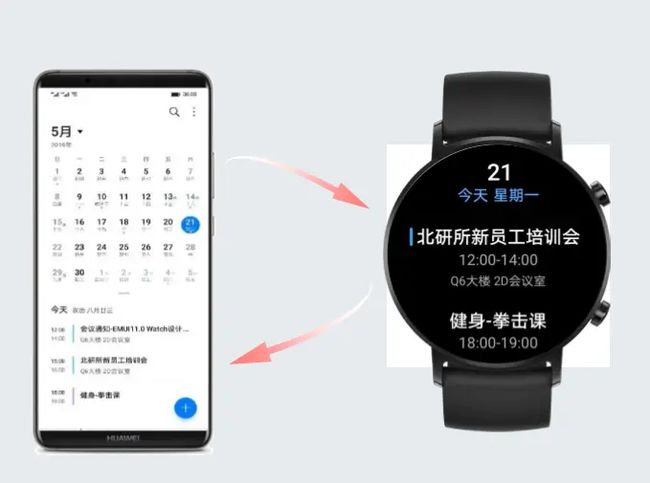
那么分布式数据库内部到底如何构成,又是如何实现端端数据同步的呢?
下面让我们深入分布式数据库的架构视图来窥探一二。
分布式数据库的架构视图
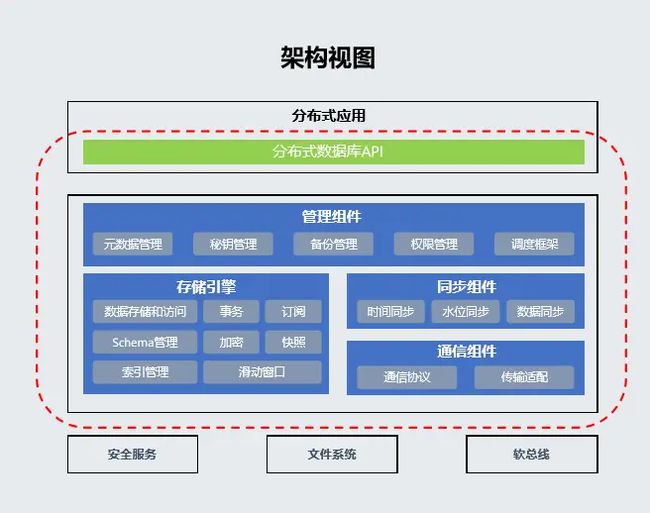
分布式数据库主要包括五个模块:
- 对外接口
分布式数据库API,提供专门的数据库创建、数据访问、数据订阅等接口给应用程序调用,接口支持KV数据模型,支持常用的数据类型。
- 管理组件:
管理组件负责数据库内元数据管理、权限管理、加密管理、备份和恢复管理以及多用户管理等、同时负责初始化底层分布式DB的存储组件、同步组件和通信适配层。
【元数据管理】:管理分布式数据库的信息,包含一些策略数据。【秘钥管理】:分布式数据库支持配置为加密,使用两层的秘钥保证机制,根秘钥会保存在TE硬件环境中,工作秘钥会送到TE中使用根秘钥来加解密,加密之后的工作秘钥保存在文件系统上,并且进行双备份,将解密之后的工作秘钥送到存储引擎中,对分布式数据库做加解密的动作。在数据库访问完成中,秘钥数据会被清理掉。【备份管理】:分布式应用程序在开发的时候,可将创建的分布式数据库设置为支持备份,这样的话在充电熄屏的情况下分布式数据库对所有要备份的数据进行备份。当我们检测到分布式数据库损坏情况下,可以使用备份的数据库来恢复,尽可能的保证分布式数据库的可靠性。【权限管理】:保证分布式数据库里面的数据不会被恶意应用访问或者篡改,保证数据物理上隔离。【调度框架】:调用存储引擎中存储的数据,将数据串联起来,与另外一台设备进行同步。
- 存储引擎
支持分布式数据库的数据存储和访问,提供数据库里面包括事务,订阅,数据库加密的实际实现,以及快照等数据库的高级特性,同时提供了结构化或者说Schema化的分布式数据库和索引管理的能力。
- 同步组件
实现分布式数据库所有的同步逻辑,包括时间同步,水位同步和数据同步。同步组件连结了存储组件与通信组件,其目标是保持在线设备间的数据库数据一致性,包括将本地产生的未同步数据同步给其他设备,接收来自其他设备发送过来的数据,并合并到本地设备中。
那么到底什么是水位同步呢?
由于数据是以记录按时间由旧到新依次同步的,保证旧记录的同步完成在新纪录同步之前,因此同步进度其实是一个单调递增的时刻值,类似水位线,水位线之下的记录就是已经完成同步的数据。
水位同步用于协商确认同步双方的同步进度。当同步一方还原过数据库时,双方记录的同步进度就会存在差异,需要协商以便确认数据同步时记录的起始时刻。
那么为什么又需要时间同步呢?
由于各种原因两个设备上的系统时间其实是没法完全对齐的,因此,在数据库的数据同步时,如果两个设备同时修改了同一条数据,那么系统默认的冲突解决策略是通过时间的先后顺序去解冲突。但当一个设备的时间比当前设备的时间快很多的情况下,可能会导致数据解冲突的正确性,从而产生问题,因此需要进行设备间的时间同步。这样每个设备都会记录与其他设备的时间差,当当前设备把数据发送给其他设备的时候,该设备会在当前的具体时间上加入时间偏移,保存到其他设备上去,完成一个last one win的冲突解决策略,尽可能保证数据同步的正确性和一致性。
- 通信组件
主要负责通信协议的实现,包括数据包数据帧的格式定义,以及数据在网络传输和文件系统存储的一个大小端的转换,以及数据发送和接收的一个拆包和组包的逻辑的实现。通信组件也把下面不同的物理传输通道做了一个适配,让同步组件感知不到具体的物理传输通道。
了解了分布式数据库的架构和运行,大家肯定迫不及待想知道分布式库到底提供了哪些数据模型,它的同步模型又是怎么样的,下面就让我们一起来探索一下。
分布式数据库的数据模型
HarmonyOS上的分布式应用可以创建一到多个分布式数据库,称为KvStore。KvStore通过数据库的名字storeId来标识,分布式数据由一系列的Entry组成。每个Entry由一对KV(KEY&VALUE)。
KV数据模型在数据的访问读写以及同步的时候是非常简单的,包括解冲突。简单来说就是当KEY相同的话,进行覆盖,不相同则执行保存。
分布式数据库中的KvStore主要应对简单的业务场景。针对复杂的业务场景,分布式数据库提供Schema能力。应用程序开发者在创建控件和打开分布式数据库的时候,可以将VALUE的结构信息,也就是Schema定义出来,传递给分布式数据库。
Schema的结构包括版本号,模式,严格匹配还是兼容匹配,VALUE字段的定义(字段、字段层级、类型、是否允许为空、是否有默认值、是否建索引,单个还是联合索引),把信息组合成Schema信息,在创建和打开数据库的时候传递下来,这个时候KV分布式数据库就升级为文档型数据库,针对文档型数据库,我们支持关系型的语义查询。

分布式数据库的同步模型
在数据同步方面,和传统的云数据同步的模型相比,分布式数据库实现的是无中心点对点之间的数据同步,每个设备是一个没有中心的网络,两两设备之间进行数据同步。

每个设备节点只发送自身产生的数据,比如说设备A数据同步到设备B,设备B并不会把数据同步到其他设备上,不能发送从其他设备同步过来的数据,除非自己又做了修改更新。
每个设备按照时间顺序将分布式数据同步给其他设备,同时分别记录与每台设备同步的水位。 为此,分布式数据库提供自动同步和手动同步两种模式。自动同步,即整个同步过程及同步触发的这个动作,不需要应用程序或者开发人员参与,完全由分布式数据库内部进行实现。 手动同步,这种同步模式同步课程不需要应用程序来参与,但触发的动作,我们提供了一个sync接口让应用程序来调用和触发。通过sync接口的调用,应用程序可以决定什么时候同步,是否同步已经同步给哪些设备。数据同步基于KVStore的粒度进行,在建立可信关系的设备只有AppId和StoreId都相同的KVStore之间才能同步数据。我们来看一个例子,设备1中有数据库A, B, C,设备2上有数据库A(与设备1上的数据库A AppId和StoreId相同)和B(与设备1上的数据库B AppId和StoreId相同),设备1和设备2在建立了可信关系之后,进行数据库同步只会A与A,B与B,C由于在设备2上没有,因而不会进行同步。

说了这么多,HarmonyOS分布式数据库到底提供了哪些对外接口给到开发者们呢?
分布式数据库对外接口
分布式数据库对外接口主要包括两部分:支持一般场景数据模型的“轻量级KV接口”和针对复杂业务场景的“支持关系型语义的增强接口”。轻量级的KV接口包括三个部分:KvManager,KvStore和KvStoreResultSet。

-
KvManager提供了分布式数据库的创建、打开、关闭和删除的一些接口,以及一些相关的配置项;
-
KvStore是基于KvManager打开得到的一个分布式数据库对象,基于KvStore这个类,可以实现分布式数据库的数据增删改查,数据订阅,数据同步和创建滑动窗口,主要用于做数据访问;
-
KvStoreResultSet是一个查询的结果集。当我们创建结果集之后可以在这个结果集里面查询数据满足数据结果的总数,以及通过移动的方式循环的方式查询每一条数据。
支持关系型语义的增强接口包括两层,上面一层为“设置分布式数据库Schema接口”,下面一层为“设置关系型语义查询算子接口”。
其中,分布式数据库Schema接口包括Schema和FieldNode,Schema信息包括Value内部的结构,包含了哪些字段,以及其要建立哪些字段的索引,而FieldNode针对不同字段可以指定名字,类型,默认值,是否允许为空等这些属性。
Query,关系型语义查询算子接口,应用于在创建完Schema或者说结构化的分布式数据库之后,在后续进行数据库查询。使用Query查询算子可以实现关系型语义的查询,当前分布式数据库查询算子支持大小比较,范围比较,是否为空,多条件的组合,模糊匹配,排序以及limit+offset复杂条件式的查询。

由此,我们可以总结分布式数据库的特点:
-
不依赖云
和传统的云数据同步的模型相比,分布式数据库实现的是无中心点对点之间的数据同步。 -
接口简单
备份、加密特性简单可配,不需要业务实现复杂的逻辑。 -
同步逻辑透明
分布式数据库同步逻辑完全透明,同步过程应用程序完全不需要参与,完全由分布式数据库自己实现。 -
提供时间同步、水位同步和冲突解决
分布式数据库提供时间同步、水位同步和冲突解决的关键技术,保证数据在数据同步过程中的正确性和一致性。 -
屏蔽不同的物理传输通道
我们都知道,底层的物理传输通道有很多种(比如基于蓝牙的BR/BRE传输,如基于WiFi的局域网/P2P纯属),通过分布式数据库的技术,让业务不用感知这一层,降低开发学习成本。
为了能让大家更好的学习鸿蒙 (OpenHarmony) 开发技术,这边特意整理了《鸿蒙 (OpenHarmony)开发学习手册》(共计890页),希望对大家有所帮助:https://qr21.cn/FV7h05
《鸿蒙 (OpenHarmony)开发学习手册》
入门必看:https://qr21.cn/FV7h05
- 应用开发导读(ArkTS)
- ……

HarmonyOS 概念:https://qr21.cn/FV7h05
- 系统定义
- 技术架构
- 技术特性
- 系统安全

如何快速入门?:https://qr21.cn/FV7h05
- 基本概念
- 构建第一个ArkTS应用
- 构建第一个JS应用
- ……

开发基础知识:https://qr21.cn/FV7h05
- 应用基础知识
- 配置文件
- 应用数据管理
- 应用安全管理
- 应用隐私保护
- 三方应用调用管控机制
- 资源分类与访问
- 学习ArkTS语言
- ……

基于ArkTS 开发:https://qr21.cn/FV7h05
1.Ability开发
2.UI开发
3.公共事件与通知
4.窗口管理
5.媒体
6.安全
7.网络与链接
8.电话服务
9.数据管理
10.后台任务(Background Task)管理
11.设备管理
12.设备使用信息统计
13.DFX
14.国际化开发
15.折叠屏系列
16.……
