大数据——Flink 知识点整理
目录
1. Flink 的特点
2. Flink 和 SparkStreaming 的对比
3. Flink 和 Blink、Alink之间的关系
4. JobManager 和 TaskManager 的职责
5. Flink 集群部署有哪些模式
6. Flink Dataflow 介绍
7. Parallelism 和 Slot 的理解
8. Flink 执行图
9. DatastreamAPI 常见的Transform 算子
10. Flink 中窗口类型
11. Flink 中窗口函数的分类
12. Flink 中 window的功能
13. 谈谈对 Flink 中时间语义的理解
14. 谈谈对 Flink 中 Watermark 的理解
15. 谈谈对 Flink 状态编程的理解
16. 谈谈 Flink 中是如何实现对状态(state)的存储、访问及维护的(状态后端——state backend)
17. Flink 检查点算法
18. Flink 的重启策略
19. Flink 中 TableAPI 和 FlinkSQL 的基本使用,1.9 版本以后引入了 Blink Planner
20. 谈谈对于 Flink 中广播状态(broadcast State)的理解
21. Flink 中如何保证端到端的状态一致性
22. 两阶段提交对 Sink 系统的要求
23. Flink 的监控主要看哪些指标(Mertics)
24. Flink 中如何实现反压
25. Flink 的优化
26. Flink 中 CEP 的应用
1. Flink 的特点
- Flink 具有高吞吐、低延时、高性能的特点
- 支持基于时间语义、窗口及状态编程
- 同时还具备了 checkpoint 和 savepoint 的功能
2. Flink 和 SparkStreaming 的对比
- Flink支持实时流处理,而 SparkStreaming 是通过微批处理的方式来实现实时处理,牺牲了吞吐量
- Flink 支持状态编程,而 SparkStreaming 不支持
- Flink:JobManager、TaskManager SparkStreaming:master、worker
3. Flink 和 Blink、Alink之间的关系
- Blink 是Flink的一个分支版本,由阿里团队开发,在Flink 1.9版本之后,融入了Blink Table API 的Blink Planner
- Alink 是基于 Flink 的通用算法平台,也是由阿里团队开发,更多的是用于机器学习和人工智能。
4. JobManager 和 TaskManager 的职责
JobManager
协调 Flink 应用程序的分布式执行。它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager: 负责 Flink 集群中的资源提供、回收、分配 。 它管理 task
- slots,这是 Flink 集群中资源调度的单位。Flink 为不同的环境和资源提供者(例如
- YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。
- Dispatcher:提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster:负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
TaskManager
执行作业流的 task,并且缓存和交换数据流。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。
5. Flink 集群部署有哪些模式
StandAlone、StandAlone HA、Flink on Yarn(Yarn Session、Pre-Job)
6. Flink Dataflow 介绍
Dataflow:Flink 程序在执行的时候会被映射成一个数据流模型
Operator:数据模型中每一个操作被称为 Operator,Operator 可以被分为 Source、Transform、Sink
Operator Chain:客户端在提交任务的时候会对 Operator 进行优化,如果 Operator 在数据传递过程中保持数据的分区数和数据的排序不变,则会将 Operator 进行合并,合并后被称为 Operator Chain,实际上就是一个执行链,每个执行链会在 TaskManager 上的一个独立的线程中执行,即 SubTask
Partition:数据流模型是分布式的和并行的,执行中会形成1~n个分区
SubTask:多个分区任务可以并行,每一个都是独立运行在一个线程中,也就是一个 Subtask 子任务
Parallelism:并行度,就是可一个同时真正执行的子任务数/分区数
7. Parallelism 和 Slot 的理解
Slot 是静态的概念,是指 TaskManager 具有的并发执行能力
Parallelism 是动态的概念,是指程序运行时实际使用的并发能力
设置合适的 Parallelism 能提高运算效率,太多和太少都不行,正常情况下 Parallelism <= Slot
设置Parallelism有多种方式,优先级为 API > env > p > file
8. Flink 执行图
Flink 中执行图可以分为4层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图,表示程序的拓扑结构
JobGraph:StreamGraph 经过优化后生成了 JobGraph 提交给 JobManager 的数据结构。主要优化是将多个符合条件的节点 chain 在一起作为一个节点(Operator Chain),这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗
ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph,是 JobGraph的并行化版本,是调度层最核心的数据结构
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构
9. Flink 代码实现步骤(以 wordcount 为例)
//1. 创建环境(Execution Environment)
val env = SteamExecutionEnvironment.getExecutionEnvironment
//2. 加载数据源(Source)
val dataStream = env.readTextFile("D:\\study\\wordcount\\input")
//3. 数据转换(Transform)
val result = dataStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
//4. 结果输出(Sink)
result.print()
//5. 执行程序(Execute)
env.execute()10. DatastreamAPI 常见的Transform 算子
单流:
- Map
- FlatMap
- Filter
- KeyBy
- Reduce
- Aggregations
- max/maxBy min/minBy
多流:
- union
- connect
- join
- coMap/coFlatMap
- process
11. Flink 中窗口类型
针对上游数据是keyedStream还是非keyedStream可以分为Keyed Windows 和 Non-Keyed Windows
基于数量的 CountWindow
//滚动窗口
//指的是同一个 key 的数据达到5个才执行,不是总共的数据达到5
streamKeyBy.countWindow(5)
//滑动窗口
//指定步长为2,当单个 key 满足2个时就执行一次,但是计算的窗口是大小为5的值,而这里的窗口大小指的也是同一个 key 达到5条
streamKeyBy.countWindow(5,2)基于时间的 TimeWindow
//滚动窗口
//每5秒一个窗口
streamKeyBy.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
//滑动窗口
//每10秒一个窗口,5秒的滑动,5秒执行一次,计算的是10秒的数据
streamKeyBy.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
//会话窗口
//会话窗口在时间窗口中使用,如果窗口中没数据的话就不触发执行
streamKeyBy.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
12. Flink 中窗口函数的分类
增量聚合函数:
每条数据到来就进行计算,保持一个简单的状态。场景:求和
ReduceFunction(reduce)、AggregateFunction(aggregate)
全窗口函数:
先把窗口所有数据收集起来,等计算的时候遍历所有数据。场景:窗口内排序
相比于增量聚合函数,全窗口函数能够取到更多的上下文信息,例如窗口信息,状态的信息
ProcessWindowFunction(process)、WindowFunction(apply)
案例
13. Flink 中 window的功能
- reduce、aggregate:对窗口内的数据进行聚合计算
- process、apply:可以获得窗口内的上下文信息,如窗口信息和状态信息
- assigner:分配器,将数据流中的元素分配到对应的窗口
- trigger:触发器,定义 window 什么时候触发计算
- evictor:剔除器,定义移除某些数据的逻辑
- allowedLateness:允许处理迟到的数据
- sideOutputLateData:将迟到的数据放入侧输出流
- getSideOutput:获取侧输出流
14. 谈谈对 Flink 中时间语义的理解
三种时间概念:事件时间、接入时间、处理时间
- 事件时间:EventTime,数据产生的时间
- 接入时间:IngestionTime,数据进入 Flink 的时间
- 处理时间:ProcessTime,数据被算子处理的时间
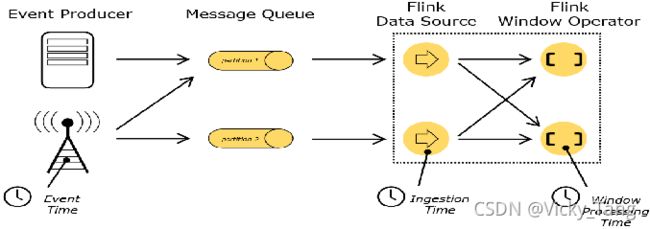
关于窗口起始时间的计算值
左闭右开
timestamp-(timestamp-offset+windowSize)%windowSize
15. 谈谈对 Flink 中 Watermark 的理解
为什么引入 Watermark
由于网络或者系统等外部因素的影响,数据被传输到 Flink 的时间往往不是按照事件产生的顺序传输过来的,因而会造成乱序或者延迟等问题。在此情况下,引入了 Watermark 机制,用于衡量数据到达的进度和完整性
Watermark 的计算
Flink 将最新读取数据的最大的 EventTime 减去固定的时间间隔作为 Watermark。固定的时间间隔其实就是指最大延迟时间。如果有一条数据的 Watermark 大于了某个窗口的 EndTime,就会默认该窗口内的数据已经全部到达并触发执行
package org.example.window
import java.time.Duration
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{EventTimeSessionWindows, SlidingEventTimeWindows, TumblingEventTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
import org.example.bean.TrainAlarm
//设定eventTime 和 watertime 处理乱序时间
object AssignEventTimeAndWm {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputStream= env.socketTextStream("master", 666)
.map(line => {
val ps = line.split(",")
TrainAlarm(ps(0), ps(1).toLong, ps(2).toDouble)
})
.assignTimestampsAndWatermarks(
//Duration 设置延迟时长 watermark = 当前已经到达的最大eventTime - 延时时长
//只要比watermark小的窗口就可以触发
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[TrainAlarm] {
//设置eventTime是哪个字段
override def extractTimestamp(element: TrainAlarm, l: Long): Long = {
element.ts*1000L
}
})
)
inputStream.keyBy(_.id)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.max("temp")
.print()
env.execute()
}
}
案例
16. 谈谈对 Flink 状态编程的理解
状态:可以理解为是数据流在计算处理的中间结果,一般接个富函数或者 ProcessFunction 获取状态
- Flink 会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑
- 在 Flink 中,状态由每一个 Task 维护,状态始终与特定的算子相关联
- 状态的类型
- 算子状态:算子状态的作用范围限定为算子任务
- 列表状态(List state)
- 联合列表状态(Union list state)
- 广播状态(Broadcast state)
- 键控状态:根据输入数据流中定义的键(key)来维护和访问。不同的 key 维护自己的状态,并且不同 key 的状态不同
- 值状态(Value state):将状态表示为单个值
- 列表状态(List state):将状态表示为一组数据的列表
- 映射状态(Map state):将状态表示为一组Key-Value对
- 聚合状态(Reducing state&Aggregate state):将状态表示为一个用于聚合的操作。将一个新到的值直接带入进去做聚合操作
- 算子状态:算子状态的作用范围限定为算子任务
package org.example.state
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import org.example.bean.TrainAlarm
/**
* 10 s 内温度连续上升就报警
* 定义三个状态:温度状态、时间状态、个数状态
* 如果是第一条数据,更新温度状态值、注册10s后触发的定时器并更行时间状态,个数状态设置为1
* 如果不是第一条数据,
* 如果温度比温度状态的值大,更新温度状态值,个数状态设置 +1
* 如果温度比温度状态的值小,删除定时器(从时间状态中取时间)个数状态设置为1,重新注册定时器,更新温度状态值
*/
object TrainTempAlarmWithState2 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val rst = env.socketTextStream("master", 666)
.map(line => {
val ps = line.split(",")
TrainAlarm(ps(0), ps(1).toLong, ps(2).toDouble)
}).assignAscendingTimestamps(_.ts*1000L)
.keyBy(_.id)
.process(new TempRiseWithTime())
.print()
env.execute()
}
}
class TempRiseWithTime extends KeyedProcessFunction[String,TrainAlarm,String]{
//定义三个状态:温度状态、时间状态、个数状态
lazy val tempState = getRuntimeContext.getState[Double](new ValueStateDescriptor[Double]("tempstate",classOf[Double]))
lazy val timeState = getRuntimeContext.getState[Long](new ValueStateDescriptor[Long]("timestate",classOf[Long]))
lazy val countState = getRuntimeContext.getState[Int](new ValueStateDescriptor[Int]("countstate",classOf[Int]))
override def processElement(value: TrainAlarm, ctx: KeyedProcessFunction[String, TrainAlarm, String]#Context, out: Collector[String]): Unit = {
if (tempState.value()==0 || timeState.value() ==0){
tempState.update(value.temp)
ctx.timerService().registerEventTimeTimer(value.ts*1000L+10000L)
timeState.update(value.ts*1000L+10000L)
countState.update(1)
}else{
if (value.temp>= tempState.value()){
tempState.update(value.temp)
countState.update(countState.value()+1)
}else{
ctx.timerService().deleteEventTimeTimer(timeState.value())
countState.update(1)
ctx.timerService().registerEventTimeTimer(value.ts*1000L+10000L)
timeState.update(value.ts*1000L+10000L)
tempState.update(value.temp)
}
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, TrainAlarm, String]#OnTimerContext, out: Collector[String]): Unit = {
if(countState.value()>=2){
out.collect(ctx.getCurrentKey + " is alarming")
tempState.clear()
timeState.clear()
countState.clear()
}
}
}
17. 谈谈 Flink 中是如何实现对状态(state)的存储、访问及维护的(状态后端——state backend)
状态后端主要负责的两件事:
- 本地状态的管理
- 将检查点(checkpoint)状态写入远程存储
Flink 提供的三种状态后端:
- MemoryStateBackend:存储在TaskManager内存中,速度快,已丢失------生产环境基本不用
- FsStateBackend:将checkpoint存储到持久化文件系统(FileSystem),而对于本地状态,也会存到TaskManager内存中,还是会受内存溢出(OOM)影响
- RockDBstateBackend:将所有状态序列化后,存入到本地的RockDB中,而RockDB是基于KV的,可以看作是一个本地数据库(实际使用内存+磁盘)。checkpoint存到持久化文件系统(FileSystem)上。
另外,如果设置的是 RockDBStateBackend,需要先引入依赖
org.apache.flink
flink-statebackend-rocksdb_2.12
${flink.version}
18. Flink 检查点算法
一般检查点实现方式:暂停应用,保存检查点,再重新恢复应用
Flink 实现了基于 Chandy-Lamport 算法的分布式快照。将检查点的保存和数据处理分离开,不暂停整个应用
具体实现方式:
Flink 会在输入数据集上间隔性的生成 Checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到对应的 checkpoint 中
对于 barrier 已经到达的分区,继续到达的数据会被缓冲,暂时不会被处理
19. Flink 的重启策略
作用:可以控制在发生故障是如何重新启动作业
如果未启用检查点,则使用“无重启”策略,如果激活了检查点并且尚未配置重启策略,会采用“固定延迟”策略Integer.MAX_VALUE尝试重启
重启策略分为4种:固定延迟重启策略、故障率重启策略、无重启策略、后备重启策略
固定延迟重启策略:
尝试给定重启作业的次数,如果超过最大尝试次数则作业失败,两次连续重启尝试之间,会有一个固定的延迟等待时间
通过在 flink-conf.yaml 中配置参数:
# fixed-delay:固定延迟策略
restart-strategy: fixed-delay
# 尝试5次,默认Integer.MAX_VALUE
restart-strategy.fixed-delay.attempts: 5
# 设置延迟时间10s,默认为 akka.ask.timeout时间
restart-strategy.fixed-delay.delay: 10s
通过代码中修改:
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置最大尝试次数为5,重启间隔为10秒
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(5,Time.seconds,10))故障率重启策略:
在故障后重新作业,当设置的故障率(failure rate)超过每个时间间隔的故障是,作业最终失败。在两次连续尝试之间,策略延迟等待一段时间
在 flink-conf.yaml 中配置参数:
# 设置重启策略为failure-rate
restart-strategy: failure-rate
# 失败作业之前的给定时间间隔内的最大重启次数,默认1
restart-strategy.failure-rate.max-failures-per-interval: 3
# 测量故障率的时间间隔。默认1min
restart-strategy.failure-rate.failure-rate-interval: 5min
# 两次连续重启尝试之间的延迟,默认akka.ask.timeout时间
restart-strategy.failure-rate.delay: 10s
在代码中设置:
val env = StreamExecutionEnvironment.getExecutionEnvironment();
// 3为最大失败次数;5min为测量的故障时间;10s为2次间的延迟时间
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.minutes(5),Time.seconds(10)));
无重启策略:
作业直接失败,不尝试重启
在 flink-conf.yaml 中配置:
restart-strategy: none
在代码中设置:
val env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
后备重启策略:
使用集群定义的重新启动策略。这对于启用检查点的流式传输程序很有帮助。
20. Flink 中 TableAPI 和 FlinkSQL 的基本使用,1.9 版本以后引入了 Blink Planner
使用 TableAPI 和 FlinkSQL需要导入的依赖
org.apache.flink
flink-table-api-scala-bridge_2.12
${flink.version}
org.apache.flink
flink-table-planner-blink_2.12
${flink.version}
org.apache.flink
flink-table-common
${flink.version}
org.apache.flink
flink-csv
${flink.version}
org.apache.flink
flink-json
${flink.version}
程序结构
创建表环境
val bsEnv = StreamExecutionEnvironment.getExecutionEnvironment
bsEnv.setParallelism(1)
//推荐使用BlinkPlanner
val bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings)
连接外部数据源,创建输入表
tableEnv.executeSql("CREATE TEMPORARY TABLE table1 ... WITH ( 'connector' = ... )")
连接外部数据输出,创建输出表
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )")
TableAPI实现查询操作
val table2 = tableEnv.from("table1").select(...)
FlinkSQL实现查询操作
val table3 = tableEnv.sqlQuery("SELECT ... FROM table1 ...")将查询结果放入输出表中
val tableResult = table2.executeInsert("outputTable") tableResult...
TableAPI 和 FlinkSQL 的使用,官网给出的案例非常详细,在写代码时可以借鉴:Apache Flink Documentation | Apache Flink
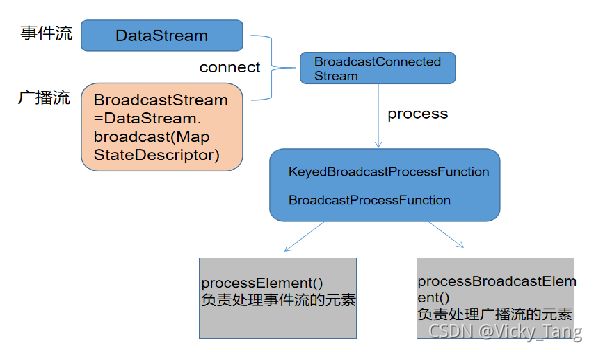
21. 谈谈对于 Flink 中广播状态(broadcast State)的理解
简单理解:一个地吞吐量流包含了一组规则,我们向对来自另一个留的所有元素基于及规则进行评估计算。
场景:动态更新计算规则、大小表关联
与其他操作符状态的区别:
(1)它有一个map格式,用于定义存储结构
(2)它仅对具有广播流和非广播流输入的特定操作符可用
(3)这样的操作符可以具有不同名称的多个广播状态
操作流程
22. Flink 中如何保证端到端的状态一致性
什么是状态一致性:
有状态的流处理,每个算子任务都可以有自己的状态。所谓的状态一致性, 其实就是我们所说的计算结果要保证准确。一条数据不应该被丢失,也不应该被 重复计算。在遇到故障时可以恢复状态,恢复以后得重新计算,结果应该也是完 全正确的。
状态一致性分类:
- At-Most-Once(最多一次):
当任务故障时,最简单的做法就是什么都不干,既不恢复丢失的数据,也不 重复数据。最多处理一次事件。数据可能会丢失。但是处理的速度快。
- At-Least-Once(至少一次) :
在大多数的真实应用场景,我们不希望数据丢失。所有的事件都会被处理, 而且可以被多次处理。
- Exactly-Once(精确一次) :★★★★★
恰好保证每个事件只被处理了一次,既没有数据丢失,也没有数据重复处理 的情况出现
端到端的 Exactly-Once:★★★★★
内部保证:checkpoint
Source 端:可重置数据的读取位置,比如 kafka 的偏移量可以手动维护,提 交。
Sink 端:从故障恢复时,数据不会重复写入外部系统。(幂等写入、事务写 入)
注:
幂等写入:就是说一个操作,可以重复执行很多次,但只导致一次结果更改, 后面再重复执行就不起作用了。
事务写入:原子性,一个事务中的一系列操作,要么全部成功,要么一个不 做。
实现的思想,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时 候,才把所有对应的结果写入 Sink 系统中。 实现方式,预写日志(GenericWriteAheadSink)和两阶段提交(TwoPhaseCommitSinkFunction)。
案例:
Flink 与 Kafka 端到端的 Exactly-Once:
- Flink 内部:利用 checkpoint 机制,把状态存盘,发生故障时可以恢复,保证 内部的状态一致性。
- Source:KafkaConsumer 作为 Source,可以将偏移量作为状态保存下来,如果后续任务发现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据, 保证一致性。
- Sink : KafkaProducer 作 为 Sink , 采 用 两 阶 段 提 交 Sink , 需 要 实 现TwoPhaseCommitSinkFunction。
package cn.jixiang.checkpoint
import java.lang
import java.util.{Properties, Random}
import org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.time.Time
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend
import org.apache.flink.streaming.api._
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.Semantic
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.producer.ProducerRecord
/***
* 从Kafka读取数据,实现WC,写回到Kafka。
* 实现端到端的状态一致性保证。
*/
object End2EndExactlyOnce {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC)
// 设置checkpoint
val hashMapStateBackend = new HashMapStateBackend()
env.setStateBackend(new HashMapStateBackend())
env.getCheckpointConfig.setCheckpointStorage("file:///D:\\Note\\Projects\\02\\Flink\\cha01\\ckp")
env.enableCheckpointing(1000,CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
env.getCheckpointConfig.setCheckpointTimeout(60000)
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(10)
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,Time.milliseconds(600)))
// 从Kafka读取数据
val props1 = new Properties()
props1.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092")
props1.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-1")
props1.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "2000")
props1.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")
props1.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
val kafkaSource = new FlinkKafkaConsumer[String]("test1",new SimpleStringSchema(),props1)
//提交offset到kafka
kafkaSource.setCommitOffsetsOnCheckpoints(true)
val inputData: DataStream[String] = env.addSource(kafkaSource)
// transformation转换
val result = inputData
.flatMap(_.split(" "))
.map(t => {
val random = new Random()
val num = random.nextInt(5)
if (num == 2){
println(num)
throw new Exception("哎呀呀,是异常呀")
}
(t,1)
})
.keyBy(_._1)
.sum(1)
.map(t => t._1 + ":" + t._2)
// 往Kafka写入数据
val props2 = new Properties()
props2.setProperty("bootstrap.servers", "master:9092")
// 默认情况下,Kafka broker 将 transaction.max.timeout.ms 设置为 15 分钟。
// 此属性不允许为大于其值的 producer 设置事务超时时间。
// 默认情况下,FlinkKafkaProducer 将 producer config 中的 transaction.timeout.ms 属性设置为 1 小时
// 因此在使用 Semantic.EXACTLY_ONCE 模式之前应该增加 transaction.max.timeout.ms 的值。
props2.setProperty("transaction.timeout.ms",1000*60*5+"")
val myProducer = new FlinkKafkaProducer[String]("test2",
new KafkaSerializationSchema[String]() {
override def serialize(element: String, timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte], Array[Byte]]("test2",element.getBytes,element.getBytes("utf-8"))
}
},
props2,
Semantic.EXACTLY_ONCE
)
result.print()
result.addSink(myProducer)
env.execute("Flink + Kafka")
}
}
23. 两阶段提交对 Sink 系统的要求
外部系统必须提供事务支持。Kafka、Mysql
原因:
在 checkpoint 隔离期间,必须开启事务并接收数据写入。
在收到 checkpoint 完成的通知之前,事务必须是“等待提交状态”,如果在此状态下 sink 系统关闭了事务(例如超时),则未提交的数据就会丢失
Sink 任务必须能够在进程失败后恢复事务(利用了事务的持久性中的 rollback 机制)
提交事务必须是幂等操作(事务的一致性)
24. Flink 的监控主要看哪些指标(Mertics)
- Counter:对流处理的数据进行累加计数
- Guage:可以反映一个值,比如查看内存使用情况
- Meter:值统计吞吐量和时间单位内发生“事件”的次数。计算方式:事件次数除以使用的时间
- Histogram:用于统计一些数据的分布,如Quantile、Mean、StdDev、Max、Min等
25. Flink 中如何实现反压
什么是反压:
消息处理速度 < 消息的发送速度,消息拥堵,系统运行不畅,通过Consumer 给 Producer 一个反馈,告知所能接受数据的大小,从而使 Producer 减少发送数据的频率
反压的影响:
- checkpoint 的时长:checkpoint barrier 跟随普通数据流动,如果数据处理被阻塞,使得 checkpoint barrier 流经整个数据管道的时长变长,导致 checkpoint 总体时间变长
- state 大小:为保证 Exactly-Once 准确一次,对于有两个以上输入管道的 Operator,checkpoint barrier 需要对齐,即接受到较快的输入管道的 barrier 后, 它后面数据会被缓存起来但不处理,直到较慢的输入管道的 barrier 也到达。这 些被缓存的数据会被放到 state 里面,导致 checkpoint 变大。
反压机制:
Flink1.5 之前是基于 TCP 的反压机制
- 弊端:
- 单个 Task 导致的反压,会阻断整个 TM-TM 的 socket,连checkpoint barrier 也无法发出
- 反压传播路径太长,导致生效延迟较大
Flink1.5 之后采用 Credit-base 反压机制
- 数据写入端将数据写入到buffer中。
- 判断当前的credit值是否大于0。
- 如果credit > 0,则将数据写出,并更新credit值。数据写出的时候会在msg上带上当前生成端的数据量backlog。
- 如果credit <= 0,则不写
26. Flink 的优化
内存管理、数据去重(使用布隆过滤器)、数据倾斜、checkpoint优化、代码重用
参考《大数据—— Flink 的优化》
27. Flink 中 CEP 的应用
什么是CEP:复杂事件处理(Complex Event Processing)
实现方式:将数据流通过一定的规则匹配(模式),然后输出用户想得到的数据
使用场景:
- 风控检测:对用户异常行为模式、数据异常流向实时检测
- 策略营销:向特定行为的用户进行湿湿的精准营销
- 运维监控:监控设备运行参数,灵活配置多指标的发生规则
往期面试题整理:
《大数据——Java 知识点整理》
《大数据——MySQL 知识点整理》
《大数据—— Hadoop 知识点整理》
《大数据—— Hive 知识点整理》
《大数据—— HBase 知识点整理》
《大数据—— Scala 知识点整理》
《大数据—— Spark Core 知识点整理》