go sync.Map 设计与实现
本文基于 Go 1.19
在上一篇文章中(《深入理解 go sync.Map - 基本原理》),我们探讨了 go 中 sync.Map 的一些基本内容,如 map 并发使用下存在的问题,如何解决这些问题等。
我们也知道了 sync.Map 的一些基本操作,但是我们还是不知道 sync.Map 是如何实现的,以及为什么在特定场景下,sync.Map 比 map + Mutex/RWMutex 快。
本篇文章就来继续深入探讨 sync.Map,对 sync.Map 的设计与实现进行更加详尽的讲解。
sync.Map 概览
开始之前,我们先来了解一下 sync.Map 的数据结构,以及其一个大概的模型。这对于我们了解 sync.Map 的设计非常有好处。
本文用到的一些名词解析
read和read map:都是指sync.Map中的只读 map,即sync.Map中的m.read。dirty和dirty map:都是指sync.Map中的可写 map,即sync.Map中的m.dirty。entry:sync.Map中的entry,这是保存值的结构体,它是一个原子类型的指针。其中的指针指向key对应的值。
sync.Map 的数据结构
sync.Map 的数据结构如下:
read和dirty是sync.Map中最关键的两个数据结构,它们之间可以相互转化。
// 在 sync.Map 中的作用是一个特殊的标记
var expunged = new(any)
// sync.Map
type Map struct {
// 互斥锁
mu sync.Mutex
// 只读 map,用于读操作
read atomic.Pointer[readOnly]
// dirty map,写入操作会先写入 dirty map
dirty map[any]*entry
// 记录需要从 dirty map 中读取 key 的次数。
// 也就是没有在 read map 中找到 key 的次数。
misses int
}
// readOnly 是一个只读的 map
type readOnly struct {
m map[any]*entry // dirty map 中的 key 的一份快照
amended bool // 记录是否在 dirty map 中有部分 read map 中不存在的 key
}
// 实际存储值的结构体。
// p 有三种状态:nil, expunged, 正常状态。
type entry struct {
p atomic.Pointer[any]
}
说明:
expunged是一个特殊的标记,用于表示entry中的值已经被删除。并且那个key在dirty map中已经不存在了。Map也就是我们使用的sync.Map,它有一个mu互斥锁,用于保护dirty map。Map中有两个map,一个是read map,一个是dirty map。read map是一个只读的map,但不是我们在其他地方说的只读。它的只读的含义是,它的key是不能增加或者删除的。但是value是可以修改的。dirty map是一个可读写的map,新增key的时候会写入dirty map。
misses是一个int类型的变量,用于记录read map中没有找到key的次数。当misses达到一定的值的时候,会将dirty map中的key同步到read map中。readOnly是一个只读的map,它的m字段是一个map,用于保存dirty map中的key的一份快照。readOnly中的amended字段用于记录dirty map中是否有read map中不存在的key。entry是一个结构体,它有一个p字段,用于保存key对应的值。p字段有三种状态:nil、expunged、正常状态。expunged是一个特殊的标记,用于表示key对应的值已经被删除,并且那个key在dirty map中已经不存在了。
因为在
sync.Map中是使用了特殊的标记来表示删除的,也就是不需要使用delete函数来删除key。这样就可以利用到了原子操作了,而不需要加锁。这样就能获得更好的性能了。
sync.Map 的整体模型
上一小节我们已经介绍了 sync.Map 的数据结构,现在让我们来看一下 sync.Map 的整体模型。
它的整体模型如下:

关键说明:
read map是一个只读的map,不能往里面添加key。而dirty map是一个可读写的map,可以往里面添加key。sync.Map实现中,基本都是会先从read map中查找key,如果没有找到,再从dirty map中查找key。然后根据查找结果来进行后续的操作。- 如果
read map中没有找到key,需要加锁才能从dirty map中查找key。因为dirty map是一个可读写的map,所以需要加锁来保证并发安全。
这实际上是一种读写分离的理念。
sync.Map 的工作流程
通过看它的数据结构和整体模型,想必我们依然对 sync.Map 感到很陌生。现在再来看看 sync.Map 的工作流程,这样我们就能知道其中一些字段或者结构体的实际作用了。
下面,我们通过一些 map 的常规操作来看一下 sync.Map 的工作流程:
- 添加
key:如果是第一次写入key的话(假设其值为value),会先写入dirty map,在dirty map中的value是一个指向entry结构体的指针。entry结构体中的p字段也是一个指针,它指向了value的内存地址。 - 读取
key:先从read中读取(无锁,原子操作),read中找不到的时候再去dirty中查找(有锁)。 - 修改
key:如果key在read map中存在的话,会直接修改key对应的value。如果key在read map中不存在的话,会去dirty map中查找(有锁),如果在dirty map中也不存在的话,则修改失败。 - 删除
key:如果key在read map中存在的话,会将key对应的entry指针设置为nil(实际上是打标记而已,并没有删除底层map的key)。如果在read中找不到,并且dirty有部分read中不存在的key的话,会去dirty map中查找(有锁),如果在dirty map中也不存在的话,则删除失败。
可能我们看完这一大段说明还是不会太懂,但是没关系,下面对每一个操作都有图,结合我画的图应该可以更好地理解。
深入之前需要了解的一些背景知识
在 sync.Map 中有一些我们需要有基本了解的背景知识,这里简单说一下。
锁
在 sync.Map 中,需要读写 dirty map 的时候,都需要加锁,加的锁是 sync.Mutex。对于这把锁,我们需要知道的是:
sync.Mutex 是一个互斥锁。当一个 goroutine 获得了 sync.Mutex 的使用权之后(Lock 调用成功),其他的 goroutine 就只能等待,直到该 goroutine 释放了 sync.Mutex(持有锁的 goroutine 使用了 Unlock 释放锁)。
所以,我们在源码中看到 m.mu.Lock() 这行代码的时候,就应该知道,从这一行代码直到 m.mu.Unlock() 调用之前,其他 goroutine 调用 m.mu.Lock() 的时候都会被阻塞。
在
sync.Map中,dirty map的读写都需要加锁,而读read map的时候不需要锁的。
原子操作
go 语言中的原子操作是指,不会被打断的操作。也就是说,当一个 goroutine 执行了一个原子操作之后,其他的 goroutine 就不能打断它,直到它执行完毕。
这可以保证我们的一些操作是完整的,比如给一个整数加上一个增量,如果不使用原子操作,而是先取出来再进行加法运算,再写回去这样操作的话,
就会出现问题,因为这个过程有可能被打断,如果另外一个 goroutine 也在进行这个操作的话,就有可能会出现数据错乱的问题。
而原子操作的 Add(比如 atomic.Int32 的 Add 方法)可以在加法过程中不被打断,所以我们可以保证数据的完整性。
这里说的不被打断说的是:这个原子操作完成之前,其他 goroutine 不能操作这个原子类型。
除了 Add 方法,atomic 包中还有 Load、Store、Swap 等方法,这些方法都是原子操作,可以保证数据的完整性。
在
sync.Map中,对entry状态的修改都是通过原子操作实现的。
CAS
CAS 是 Compare And Swap 的缩写,意思是比较并交换。CAS 操作是一种原子操作,它的原理是:当且仅当 内存值 == 预期值 时,才会将 内存值 修改为 新值。
使用代码表示的话,大概如下:
if *addr == old {
*addr = new
return true
}
return false
也就是说:
- CAS 原子操作会先进行比较,如果
内存值 == 预期值,则执行交换操作,将内存值修改为新值,并返回true。 - 否则,不执行交换操作,直接返回
false。
CAS 如果比较发现相同就会交换,如果不相同就不交换,这个过程是原子的,不会被打断。在
sync.Map中,修改entry的状态的时候,有可能会使用到 CAS。
double-checking(双重检测)
这是一种尽量减少锁占用的策略,在单例模式中可能会用到:
// 第一次检查不使用锁
if instance == nil {
mu.Lock()
defer mu.Unlock()
// 获取到锁后,还要再次检查,
// 因为有可能在等待锁的时候 instance 已经被初始化了
if instance == nil {
instance = new()
}
}
return instance
上面这个例子中,在获取到锁之后,还进行了一次检查,这是因为 mu.Lock() 如果获取不到锁,那么当前 goroutine 就会被挂起,等待锁被释放。
如果在等待锁的过程中,另外一个 goroutine 已经初始化了 instance,那么当前 goroutine 就不需要再初始化了,所以需要再次检查。
如果第二次检查发现 instance 已经被初始化了,那么就不需要再初始化了,直接返回 instance 即可。
在
sync.Map中,也有类似的双重检测,比如在Load方法中,会先从read中获取entry,如果没有,就会加锁,获取到锁后,再去检查一下read中是否有entry,如果没有,才会从dirty中获取entry。这是因为在等待锁的时候可能有其他goroutine已经将key放入read中了(比如做了Range遍历)。
dirty map 和 read map 之间的转换
上面我们说了,写入新的 key 的时候,其实是写入到 dirty 中的,那什么时候会将 key 写入到 read 中呢?
准确来说,sync.Map 是不会往 read map 中写入 key 的,但是可以使用 dirty map 来覆盖 read map。
dirty map 转换为 read map
dirty map 转换为 read map 的时机是:
missess的次数达到了len(dirty)的时候。这意味着,很多次在read map中都找不到key,这种情况下是需要加锁才能再从dirty map中查找的。这种情况下,就会将dirty map转换为read map,这样后续在read map中能找到key的话就不需要加锁了。- 使用
Range遍历的时候,如果发现dirty map中有些key在read map中没有,那么就会将dirty map转换为read map。然后遍历的时候就遍历一下read map就可以了。(如果read map中的key和dirty map中的key完全一致,那直接遍历read map就足够了。)
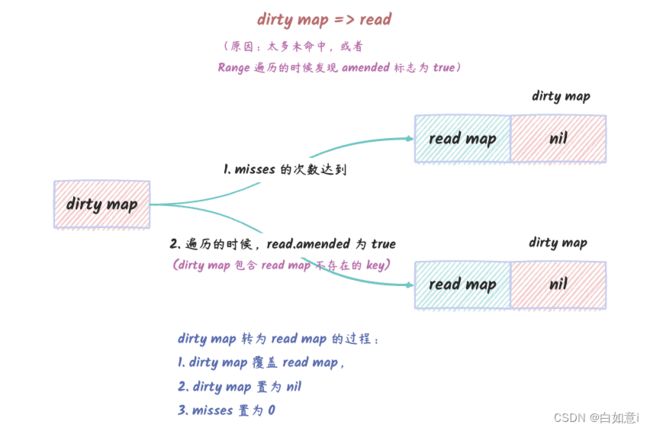
dirty map 转换为 read map 的操作其实是很简单的,就是使用 dirty map 直接覆盖掉 read map,然后将 dirty map 置为 nil,同时 misses 重置为 0。
简单来说,如果因为新增了
key需要频繁加锁的时候,就会将dirty map转换为read map。
read map 转换为 dirty map
read map 转换为 dirty map 的时机是:
dirty map为nil的情况下,需要往dirty map中增加新的key。

read map 转换为 dirty map 的时候,会将 read map 中正常的 key 复制到 dirty map 中。
但是这个操作完了之后,read map 中的那些被删除的 key 占用的空间是还没有被释放的。
那什么时候释放呢?那就是上面说的 dirty map 转换为 read map 的时候。
sync.Map 中 entry 的状态
在 sync.Map 中,read map 和 dirty map 中相同 key 的 entry 都指向了相同的内容(共享的)。
这样一来,我们就不需要维护两份相同的 value 了,这一方面减少了内存使用的同时,也可以保证同一个 key 的数据在 read 和 dirty 中看到都是一致的。
因为我们可以通过原子操作来保证对 entry 的修改是安全的(但是增加 key 依然是需要加锁的)。
entry 的状态有三种:
nil:被删除了,read map和dirty map都有这个key。expunged:被删除了,但是dirty map中没有这个key。- 正常状态:可以被正常读取。
它们的转换关系如下:

说明:
key被删除dirty map为nil的时候,需要写入新的key,read中被删除的key状态会由nil修改为expunged- 被删除的
key,重新写入 read中被删除的key(dirty map中不存在的),在再次写入的时候会发生
注意:expunged 和正常状态之间不能直接转换,expunged 的 key 需要写入的话,需要先修改其状态为 nil。正常状态被删除之后先转换为 nil,然后在创建新的 map 的时候才会转换为正常状态。也就是 1->2 和 4->3 这两种转换)
不存在由正常状态转换为
expunged或者由expunged转换为正常状态的情况。
entry 状态存在的意义
entry 的状态存在的意义是什么呢?我们去翻阅源码的时候会发现,其实 sync.Map 在删除的时候,
如果在 read map 中找到了 key,那么删除操作只是将 entry 的状态修改为 nil(通过原子操作修改),并没有真正的删除 key。
也就是并不像我们使用普通 map 的时候那种 delete 操作,会将 key 从 map 中删除。
这样带来的一个好处就是,删除操作我们也不需要加锁了,因为我们只是修改了 entry 的状态,而不是真正的删除 key。
这样就可以获得更好的性能了。
就算转换为了
nil状态,也依然可以转换为expunged或者正常状态,具体看上一个图。
read.amended 的含义
我们往 sync.Map 中写入新的 key 的时候,会先写入 dirty map,但是不会写入 read map。
这样一来,我们在读取的时候就需要注意了,因为我们要查找的 key 是有可能只存在于 dirty map 中的,
那么我们是不是每次在 read map 中找不到的时候都需要先去 dirty map 中查找呢?
答案是否定的。我们从 dirty map 中进行查找是有代价的,因为要加锁。如果不加锁,遇到其他 goroutine 写入 dirty map 的时候就报错了。
针对这种情况,一种比较简单的解决方法是,增加一个标志,记录一下 read map 跟 dirty map 中的 key 是否是完全一致的。
如果是一致的,那么我们就不需要再加锁,然后去 dirty map 中查找了。否则,我们就需要加锁,然后去 dirty map 中查找。
sync.Map 中的 amended 字段就是这里说的标志字段。单单说文字可能有点抽象,我们可以结合下图理解一下:

read.amended 的含义就是
read map跟dirty map中的key是否是完全一致的。如果为true,说明有些 key 只存在于dirty map中。
sync.Map 源码剖析
sync.Map 提供的方法并不多,它能做的操作跟普通的 map 差不多,只是在并发的情况下,它能保证线程安全。
下面是 sync.Map 所能提供的方法:
Store/Swap(增/改): 往sync.Map中写入新的key。(Store实际调用了Swap方法)Load(查): 从sync.Map中读取key。LoadOrStore(查/增/改): 从sync.Map中读取key,如果不存在,就写入新的key。Delete/LoadAndDelete(删): 从sync.Map中删除key。(Delete实际调用了LoadAndDelete方法)Range: 遍历sync.Map中的所有key。
还有两个可能比较少用到的方法:
CompareAndDelete: 从sync.Map中删除key,但是只有在key的值跟old相等的时候才会删除。CompareAndSwap: 从sync.Map中写入新的key,但是只有在key的值跟old相等的时候才会写入。
接下来我们会从源码的角度来分析一下 sync.Map 的实现。
Store/Swap 源码剖析
Store 实际上是对 Swap 方法的调用,所以我们看 Swap 方法的源码就够了:
Swap 方法的作用是:交换一个 key 的值,并返回之前的值(如果有的话)。
返回值中的 prev 就是之前的值,loaded 表示 key 是否存在。
下面是 Swap 方法的源码:
func (m *Map) Swap(key, value any) (previous any, loaded bool) {
// 读取 read map
read := m.loadReadOnly()
// 先从 read map 中读取 key
if e, ok := read.m[key]; ok {
// 在 read map 中读取到了 key
if v, ok := e.trySwap(&value); ok { // ok 表示是否成功交换
// swap 成功
if v == nil { // 之前的值为 nil,表示 key 之前已经被删除的了
return nil, false
} // 之前的值不为 nil,表示存在
return *v, true
}
// 执行到这里表示:
// read map 中存在 key,但是已经被删除。(为 expunged 状态)
}
// read map 中找不到 key,加锁,从 dirty map 中继续找
m.mu.Lock()
// double checking,二次检查,因为有可能等待锁的时候 read map 已经发生了变化
read = m.loadReadOnly()
if e, ok := read.m[key]; ok { // read map 中存在 key
if e.unexpungeLocked() { // 将 entry 由 expunged 状态改为 nil 状态
// key 之前已经被删除了,并且之前 dirty map 中不存在 key,
// 所以这里需要将 key 添加到 dirty map 中。
m.dirty[key] = e
}
// 写入新的值,v 是旧的值
if v := e.swapLocked(&value); v != nil {
// v 不为 nil,表示之前存在
loaded = true
previous = *v
}
} else if e, ok := m.dirty[key]; ok { // read map 中不存在 key,但是 dirty map 中存在 key
// 写入新的值,v 是旧的值
if v := e.swapLocked(&value); v != nil {
// v 不为 nil,表示之前存在
loaded = true
previous = *v
}
} else { // read map 中不存在 key,dirty map 中也不存在 key(需要写入新的 key)
if !read.amended { // dirty map 和 read map 的 key 完全一致)
// 现在要写入新的 key 了,所以这个 amended 状态得修改了。
// 我们正在将第一个新键添加到 dirty map 中。
// 确保它已分配并将 read map 的 amended 标记设置为 true。
m.dirtyLocked()
// amended 设置为 true,因为下面要写入一个在 read map 中不存在的 key
m.read.Store(&readOnly{m: read.m, amended: true})
}
// 新增的 key,dirty map 中不存在,所以直接写入
m.dirty[key] = newEntry(value)
}
// 解锁
m.mu.Unlock()
return previous, loaded
}
Swap/Store 图示

注意:这里的
read map和dirty map中都没有包含entry,我们知道它们中相同的key都指向相同的entry就可以了。
Swap 的操作流程
- 从
read map中读取key,如果存在,就直接交换value,并返回之前的value。 - 如果
read map中不存在key,就加锁,加锁后,再从read map中读取key,如果存在,就直接交换value,并返回之前的value。(double checking) - 加锁后,如果在
read map中依然找不到key,再从dirty map中读取key,如果存在,就直接交换value,并返回之前的value。 - 如果
read map和dirty map都不存在key,就将key添加到dirty map中,并返回nil。在这一步中,如果read map和dirty map的key完全一致,就将read map的amended状态设置为true。
在第 4 步中,还有一个关键操作就是
dirtyLocked(),这个操作的作用是保证dirty map初始化,如果dirty map已经初始化,就不会做任何操作。
如果dirty map是nil,那么会初始化,然后将read map中未被删除的key添加到dirty map中。
dirtyLocked() 源码剖析
dirtyLocked() 的作用是保证 dirty map 初始化,如果 dirty map 已经初始化,就不会做任何操作。
之所以 dirty map 需要初始化,是因为在 dirty map 转换为 read map 的时候,dirty map 会被设置为 nil,
但是新增 key 的时候是要写入到 dirty map 的,所以需要重新初始化。
具体可以看上面的 dirty map 和 read map 的之间的转换 这一节。
dirtyLocked() 的实现如下:
// 1. 如果 m.dirty 为 nil,则创建一个新的 dirty map。
// 2. 否则,不做任何操作
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read := m.loadReadOnly()
// dirty map 初始化
m.dirty = make(map[any]*entry, len(read.m))
// 对于 read map 中的 key,如果不是 expunged,则将其复制到 dirty map 中。
// read map 中 nil 的 key 会被转换为 expunged 状态。
for k, e := range read.m {
// 不是 expunged 的 entry,才会被复制到 dirty map 中。
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
dirtyLocked() 图示:

dirtyLocked()里有个需要注意的地方就是,它会将read map中的nil的key转换为expunged状态。
expunged状态表明这个key只是在read map中,而不在dirty map中。
做完迁移之后,dirty map其实就不包含那些被删除的key了。
Swap/Store 关键说明
Swap 方法里面其实基本已经包含了 sync.Map 主要设计理念了,下文讲解其他方法的时候,其中一些细节不再做过多的解释了:
sync.Map在做很多操作的时候,都会先从read map中读取,如果read map中不存在,再从dirty map中读取。- 如果需要从
dirty map中读取,那么会先加锁,然后再从dirty map中读取。 sync.Map在对entry进行操作的时候,都是通过原子操作进行的。(这是因为有些写操作是没有mu.Lock()保护的)
而对于
dirty map和read map的转换等只是一些实现细节的上的问题,我们如果了解了它的设计理念,那么就可以很容易的理解它的实现了。
Swap/Store 里的原子操作
这里面用了很多原子操作:
m.loadReadOnly(): 读取read map。e.trySwap(&value): 交换key的值。key存在的时候,直接通过原子操作使用新的值覆盖旧的。(如果key只存在于read map中的话,这个操作会失败。)e.unexpungeLocked(): 将entry由expunged状态改为nil状态。e.swapLocked(&value): 交换key的值。key存在的时候,直接通过原子操作使用新的值覆盖旧的。m.read.Store(&readOnly{m: read.m, amended: true}): 将read map的amended状态设置为true。
为什么使用原子操作
为什么要使用原子操作呢?这是因为 sync.Map 中有一些写操作是没有加锁的,比如删除的时候,
删除的时候只是将 entry 的状态通过原子操作改成了 nil 状态。
如果不使用原子操作,那么就会出现并发问题。
比如:在 m.mu.Lock() 保护的临界区内先读取了 entry 的状态,我们还没来得及对其做任何操作,
在另外一个 goroutine 中 entry 的状态被修改了,那么我们临界区内的 entry 状态已经成为它的历史状态了,
如果这个时候再基于这个状态做任何操作都会导致并发问题。
Load 源码剖析
Load 方法的作用是从 sync.Map 中读取 key 对应的值。
在 sync.Map 的实现中,key 的查找都遵循以下的查找流程:

注意:从
read map查找不需要加锁,从dirty map中查找需要加锁。
下面是 Load 方法的源码:
// Load 返回存储在 map 中的键值,如果不存在值则返回 nil。
// ok 结果表明是否在 map 中找到了值。
func (m *Map) Load(key any) (value any, ok bool) {
// 通过原子操作获取只读 map
read := m.loadReadOnly()
e, ok := read.m[key]
// 不在只读 map 中,并且 dirty map 包含一些 key 不在 read.m 中。
if !ok && read.amended {
m.mu.Lock()
// double checking
read = m.loadReadOnly()
e, ok = read.m[key]
if !ok && read.amended { // 仍然不在只读 map 中,并且 dirty map 包含一些 key 不在 read.m 中。
e, ok = m.dirty[key] // 从 dirty map 中获取
// 不管条目是否存在,记录一个未命中:这个键将走慢路径,直到脏映射被提升为读映射。
m.missLocked() // read 中读不到
}
m.mu.Unlock()
}
// key 不存在
if !ok {
return nil, false
}
// key 存在,通过原子操作获取值
return e.load()
}
Load 图示

其实 Load 的过程大概就是前一个图的查找 key 的过程,只不过其中有一步 missLocked(),
这个操作是用来记录 key 未命中的次数的。在达到一定次数之后,会将 dirty map 提升为 read map。
missLocked 源码剖析
missLocked 的实现是很简单的,就是将 misses 加 1,如果 misses 达到了 dirty map 的大小,
就会将 dirty map 提升为 read map。
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// 未命中的次数达到 len(m.dirty),将 dirty map 提升为 read map
m.read.Store(&readOnly{m: m.dirty})
// 重置 dirty map
m.dirty = nil
// 重置 misses
m.misses = 0
}
这个过程可以用下图表示:

Load 工作流程
Load 方法的工作流程如下:
- 通过原子操作获取
read map。如果read map中存在key,则直接返回key对应的值。 - 如果
dirty map中包含了一些read map中不存在的key,则需要加锁,再次获取read map。 - 如果
read map中不存在key,则从dirty map中获取key对应的值(同时调用missLocked())。否则返回从read map中获取到的key对应的值。
LoadOrStore 源码剖析
LoadOrStore 方法的作用是从 sync.Map 中读取 key 对应的值,如果不存在则将 key 和 value 存入 sync.Map 中。
其实它跟 Load 方法整体流程上也是差不多的,只不过它在找到 key 的时候,会将 key 和 value 存入 sync.Map 中。
如果没有找到 key,则新增 key 到 dirty map 中。
下面是 LoadOrStore 方法的源码:
// LoadOrStore 返回键的现有值(如果存在)。
// 否则,它存储并返回给定的值。
// 返回值:loaded 表明是否是加载的值,而不是存储的值。actual 是当前存储的值。
func (m *Map) LoadOrStore(key, value any) (actual any, loaded bool) {
// 如果从 read map 中获取到了 key,则不需要加锁。
read := m.loadReadOnly()
if e, ok := read.m[key]; ok { // key 是 expunged 状态的时候,ok 为 false
actual, loaded, ok := e.tryLoadOrStore(value)
if ok { // Load 或者 Store 成功
return actual, loaded
}
}
// 加锁
m.mu.Lock()
// double checking
read = m.loadReadOnly()
if e, ok := read.m[key]; ok {
// key 存在于 read map 中
if e.unexpungeLocked() { // 状态:expunged => nil
// 之前是 expunged 状态,现在变成了 nil 状态。需要在 dirty map 中写入 e。
m.dirty[key] = e
}
// 再次对 entry 执行尝试 Load 或者 Store 新的值的操作
actual, loaded, _ = e.tryLoadOrStore(value)
} else if e, ok := m.dirty[key]; ok {
// key 存在于 dirty map 中
actual, loaded, _ = e.tryLoadOrStore(value)
m.missLocked() // misses++,表示 read map 中没有该 key
} else {
// key 不存在于 read map 和 dirty map 中。
if !read.amended {
// 下面需要往 dirty map 中写入新的 key,所以需要确保 dirty map 被初始化。
m.dirtyLocked()
// dirty map 中现在有一些 read map 中不存在的 key,所以需要将 read map 的 amended 置为 true。
m.read.Store(&readOnly{m: read.m, amended: true})
}
// 写入 dirty map
m.dirty[key] = newEntry(value)
actual, loaded = value, false
}
m.mu.Unlock()
return actual, loaded
}
LoadOrStore 图示

LoadOrStore 工作流程
key在read map中找到,尝试在read map中Load或Store,操作成功则返回。找不到则加锁,然后二次检查(double checking)。- 在
read map中依然找不到,但是key在dirty map中找到,尝试在dirty map中Load或Store,操作成功则返回。(missLocked) key不存在,往dirty map中写入key和value。(如果dirty map为nil,则先进行初始化),然后read map的amended修改为true。
tryLoadOrStore 源码剖析
我们发现,在 LoadOrStore 方法中,找到 key 之后,都是调用 tryLoadOrStore 方法来进行 Load 或 Store 操作的。
它的作用就是在 entry 上尝试 Load 或 Store 操作,简单来说就是,如果 key 已经存在则 Load,否则 Store(当然,实际上没有这么简单)。
我们先来看看它的源码:
// 如果 entry 未被删除,tryLoadOrStore 会自动加载或存储一个值。
// 如果 entry 被删除,tryLoadOrStore 将保持条目不变并返回 ok==false。
//
// 返回值:
// ok:操作是否成功(Load 成功、Store 成功)
// loaded:表示是否是 Load 出来的
// actual:Load 到的值
func (e *entry) tryLoadOrStore(i any) (actual any, loaded, ok bool) {
// 获取 entry 的状态
p := e.p.Load()
// 这个 key 只存在于 read map 中,并且它已经被删除了
if p == expunged {
return nil, false, false
}
// key 是正常状态,Load 成功,返回
if p != nil {
return *p, true, true
}
// p 是 nil,说明 key 不存在,需要 Store
ic := i
for { // 循环直到 Load 或者 Store 成功(类似自旋锁)
// Store 成功
if e.p.CompareAndSwap(nil, &ic) {
return i, false, true
}
// Store 失败,重新获取 entry 的状态
p = e.p.Load()
// 被删除了
if p == expunged {
return nil, false, false
}
// 还没被删除,说明 key 存在
if p != nil {
return *p, true, true
}
}
}
tryLoadOrStore 的逻辑可以用下图表示:
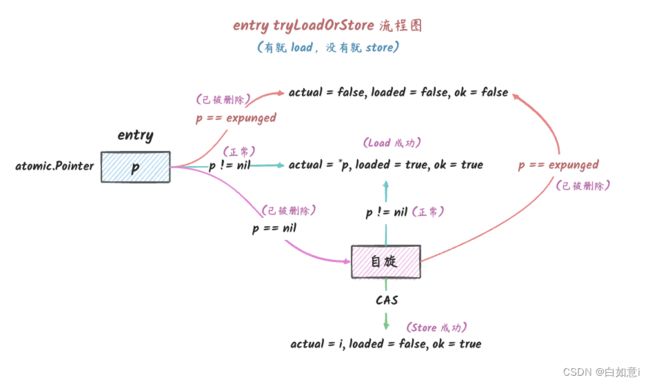
在 p 是 nil 的情况下,会有一个 for 循环一直尝试 Load 或者 Store,一旦成功就会返回。
unexpungeLocked 的作用
在 LoadOrStore 方法中,我们发现,如果 key 在 read map 中找到,会先调用 unexpungeLocked 方法。
读到这里,可能很多读者对 expunge 和 unexpunge 有点懵逼,不知道它们是干什么的。
简单来说,expunge 就是表明 key 已经被删除了,并且这个 key 只存在于 read map 中(在 dirty map 中不存在)。
而 unexpunge 的作用就是取消 expunge 的效果(因为要往这个 key 写入新的值了),紧接着我们会往 dirty map 中写入这个 key。
我们可以结合下图来思考一下:

注意:实际中
entry并不是连续存储的。
expunged 状态说明:
p == expunged,key已被删除,并且dirty map不为nil,并且dirty中没有这个key。p == nil,key已被删除,并且dirty map为nil,或dirty[k]指向该entry。(Store)p != nil,key正常,返回其值。(Load)
Delete 源码剖析
Delete 方法实际上只是 LoadAndDelete 的 wrapper 函数,所以我们看 LoadAndDelete 就够了。
删除操作在 sync.Map 中是一个很简单的操作,如果在 read map 中找到了要删除的 key,
那么我们只需要将其设置为 nil 就可以了。虽然它是一个写操作,但是依然不需要加锁。
如果在
read map中找到了key,则可以不加锁也把它删除。因为sync.Map中的删除只是一个标记。
例外的情况是,它在 read map 中找不到,然后就需要加锁,然后做 double checking,然后再去 dirty map 中查找了。
LoadAndDelete 的源码如下:
// LoadAndDelete 删除键的值,返回以前的值(如果有)。
// loaded 报告 key 是否存在。
func (m *Map) LoadAndDelete(key any) (value any, loaded bool) {
// 获取 read map
read := m.loadReadOnly()
// 从 read map 查找 key
e, ok := read.m[key]
if !ok && read.amended { // read map 找不到那个 key,需要继续从 dirty map 中查找
m.mu.Lock() // 加锁
read = m.loadReadOnly() // double checking
e, ok = read.m[key]
if !ok && read.amended { // 需要继续从 dirty map 中查找
e, ok = m.dirty[key] // 从 dirty map 中删除 key
delete(m.dirty, key) // 直接做删除 key 的操作
// 累加未命中 read map 的次数
m.missLocked()
}
m.mu.Unlock()
}
if ok { // key 存在,做删除操作(设置 entry 为 nil 状态)
return e.delete()
}
// key 找不到,不需要做删除操作
return nil, false
}
删除的操作会有两种情况:
- 存在于
read map中,则直接删除。(设置entry指针为nil,但是不会删除read map中的key) - 只存在于
dirty map中,则直接删除。这种情况下,会删除dirty map中的key。
LoadAndDelete 图示

LoadAndDelete 工作流程
- 从
read map中查找key,如果找到了,那么直接删除key(将entry的指针设置为nil),并返回value。 - 如果
read map中没有找到key,并且read.amended为true,那么就需要加锁,然后做double checking。 - 加锁后在
read map依然找不到,并且read.amended为true,那么就需要从dirty map中查找key。 - 同时在临界区内直接执行
delete操作,将key从dirty map中删除。同时累加misses次数。 - 最后,如果找到了
key对应的entry,则将其删除(设置entry指针为nil),并返回value。
Range 源码剖析
Range 方法的作用是遍历 sync.Map 中的所有 key 和 value,它接受一个函数作为参数,如果这个函数返回 false,那么就会停止遍历。
Range 的源码如下:
// Range 依次为映射中存在的每个键和值调用 f。 如果 f 返回 false,则 range 停止迭代。
func (m *Map) Range(f func(key, value any) bool) {
// 我们需要能够遍历在调用 Range 开始时已经存在的所有键。
read := m.loadReadOnly()
if read.amended {
// dirty map 中包含了 read map 中没有的 key
m.mu.Lock()
read = m.loadReadOnly()
if read.amended {
// 使用 m.dirty 中的数据覆盖 m.read 中的数据
read = readOnly{m: m.dirty}
m.read.Store(&read)
// 重置 dirty map
m.dirty = nil
// 重置 misses
m.misses = 0
}
m.mu.Unlock()
}
// 所有的 key 都在 read map 中了,遍历 read map 即可
for k, e := range read.m {
v, ok := e.load()
if !ok { // 已经被删除
continue
}
if !f(k, v) { // f 可以返回一个 bool 值,如果返回 false,那么就停止遍历
break
}
}
}
Range 图示
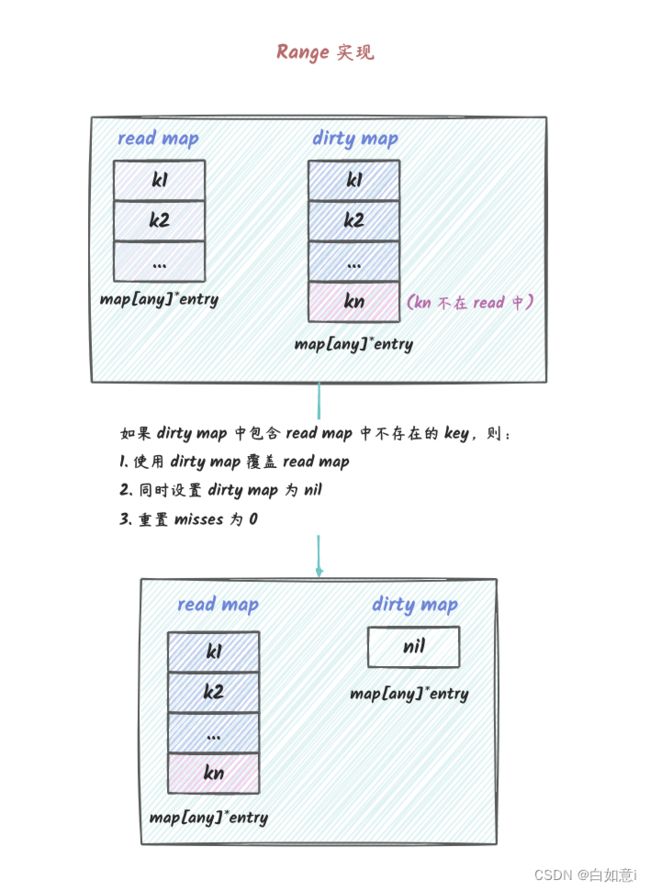
Range 遍历的时候,只会遍历 read map 中的 key。如果 read.amended 为 true,那么就需要加锁,然后做 double checking,
如果二次检查 read.amended 还是 true,那么就需要将 dirty map 中的数据覆盖到 read map 中。
Range 工作流程
- 为了保证能遍历
sync.Map中所有的key,需要判断read.amended是否为true。 - 如果为
true,说明只有dirty map中包含了所有的key,那么就需要将dirty map转换为read map。(这样的好处是,可以在遍历过程中,不需要加锁) - 然后开始遍历,遍历的时候只需要遍历
read map即可,因为这个时候read map中包含了所有的key。 - 遍历过程中,如果发现
key已经被删除,则直接跳过。否则将key和value传递给f函数,如果f函数返回false,那么就停止遍历。
CompareAndSwap 源码剖析
CompareAndSwap 方法的作用是比较 key 对应的 value 是否为 old,如果是,则将 key 对应的 value 设置为 new。
CompareAndSwap 的源码如下:
// 如果映射中存储的值等于旧值,则 CompareAndSwap 会交换 key 的旧值和新值
// 旧值必须是可比较的类型。
func (m *Map) CompareAndSwap(key, old, new any) bool {
// 获取 read map
read := m.loadReadOnly()
// 从 read map 读取 key 对应的 value
if e, ok := read.m[key]; ok {
// 在 read map 中找到了,进行 CAS 操作
return e.tryCompareAndSwap(old, new)
} else if !read.amended {
// 在 dirty map 也没有,返回 false
return false
}
// 加锁
m.mu.Lock()
defer m.mu.Unlock()
read = m.loadReadOnly()
swapped := false
if e, ok := read.m[key]; ok { // double checking
// 在 read map 中找到了,进行 CAS 操作
swapped = e.tryCompareAndSwap(old, new)
} else if e, ok := m.dirty[key]; ok {
// 在 dirty map 中找到了,进行 CAS 操作
swapped = e.tryCompareAndSwap(old, new)
// 累加 misses 次数
m.missLocked()
}
return swapped
}
CompareAndSwap 图示

其实到这里,我们应该发现了,其实 sync.Map 的大多数方法的实现都是先从 read map 中读取,如果没有找到,那么就从 dirty map 中读取。
只是从 read map 中读取的时候,需要加锁,然后做 double checking。
CompareAndSwap 工作流程
- 首先从
read map中读取key对应的value。如果找到则进行CAS操作,如果没有找到,那么就需要加锁,然后做double checking。 - 如果还是没找到。则从
dirty map中查找,找到则做 CAS 操作,然后累加misses次数。 - 如果还是没找到,那么就返回
false。
CompareAndDelete 源码剖析
CompareAndDelete 方法的作用是比较 key 对应的 value 是否为 old,如果是,则将 key 对应的 value 删除。
CompareAndDelete 的源码如下:
// 如果 key 的值等于 old,CompareAndDelete 会删除它的条目。
// 旧值必须是可比较的类型。
//
// 如果 map 中的 key 的值不等于 old,则 CompareAndDelete 返回 false(即使旧值是 nil 接口值)。
func (m *Map) CompareAndDelete(key, old any) (deleted bool) {
// 获取 read map
read := m.loadReadOnly()
e, ok := read.m[key]
// read map 中不存在这个 key,并且 dirty map 中包含了一些 read map 中没有的 key
if !ok && read.amended {
// 加锁
m.mu.Lock()
read = m.loadReadOnly()
e, ok = read.m[key]
// double checking
if !ok && read.amended { // dirty map 中包含 read map 中不存在的 key
e, ok = m.dirty[key]
// 累加 misses 次数
m.missLocked()
}
m.mu.Unlock()
}
// 如果 key 存在,并且其值等于 old,则将其删除。
for ok {
p := e.p.Load()
// 已经被删除,或者值不等于 old,返回 false,表示删除失败
if p == nil || p == expunged || *p != old {
return false
}
// 将其删除(本质上是一个 CAS 操作,将其状态修改为了 nil)
if e.p.CompareAndSwap(p, nil) {
return true
}
}
// key 找不到,返回 false
return false
}
CompareAndDelete 图示

CompareAndDelete 工作流程
- 首先从
read map中读取key对应的value。如果找到则进行CAS操作,如果没有找到,那么就需要加锁,然后做double checking。 - 如果还是没找到。并且
dirty map中包含了部分read map中不存在的key,则从dirty map中查找,找到则做 CAS 操作,然后累加misses次数。 - 如果找到了
key,会通过原子操作读取其之前的值。如果发现它已经被删除或者旧值不等于old,则返回false。否则通过CAS操作将其删除,然后返回true。 - 如果没有找到
key,则返回false。
entry 的一些说明
entry 这个结构体是 sync.Map 中实际保存值的结构体,它保存了指向了 key 对应值的指针。
在上面阅读代码的过程中,我们发现,entry 中有很多方法使用了 try 前缀,比如 trySwap, tryLoadOrStore 等。对于这类方法,我们需要知道的是:
- 它并不保证操作一定成功,因为一些写操作是不需要持有互斥锁就可以进行的(比如删除操作,只是一个原子操作,将
entry指向了nil)。 - 这类方法里面,有一个
for循环,来进行多次尝试,直到操作成功,又或者发现entry已经被删除的时候就返回。类似自旋锁。 - 这类方法里面对
entry状态的修改是通过CAS操作来实现的。
sync.Map 源码总结
一顿源码看下来,我们不难发现,sync.Map 的大部分方法整体处理流程上是非常相似的,都是先从 read map 中读取,如果没有找到,那么就需要加锁,然后做 double checking。如果还是没找到,那么就从 dirty map 中查找,如果还是没找到,那么就返回 false。
这样做的目的都是在尽量地减少锁的占用,从而获得更好的性能。
同时,如果在 dirty map 中查找的次数多了,会触发 dirty map 转换为 read map 的操作流程,这样一来,下一次搜索同样的 key 就不再需要加锁了。
最后一个关键的点是,在 sync.Map 中没有被锁保护的地方,都是通过原子操作来实现的,这样一来,就可以保证在多核 CPU 上的并发安全。
总结
sync.Map中的key有两份,一份在read map中,一份在dirty map中。read map中的key是不可变的,而dirty map中的key是可变的。sync.Map中的大多数操作的操作流程如下:- 首先从
read map中读取key对应的value。找到则做相应操作。 - 如果没找到,则加锁,再做一次
double checking。找到则做相应操作。 - 如果还是没找到,那么就从
dirty map中查找,找到则做相应操作。 - 从
dirty map找到的时候,需要累加misses次数,如果misses次数超过了dirty map的大小,那么就会触发dirty map转换为read map的操作流程。
- 首先从
sync.Map中的read map和dirty map中相同的key指向了同一个value(是一个entry结构体实例)。entry有三种状态:nil: 表示key已被删除。expunged: 表示key已被删除,并且dirty map中没有这个key,这个key只存在于read map中。*v: 表示一个指向具体值的指针,是正常状态。
sync.Map中的大部分方法都是通过原子操作来实现的,这样一来,就可以保证在多核 CPU 上的并发安全。就算没有在锁保护的临界区内,这种操作依然可以保证对map的操作不会出现错乱的情况。read map中有一个字段标识了是否dirty map中存在部分read map中不存在的key。这样一来,如果在read map中找不到key的时候,就可以先判断一下read.amended是否为true,如果是true,才需要进行加锁,然后再去dirty map中查找。这样一来,就可以减少加锁的次数,从而获得更好的性能。dirty map和read map之间是会相互转换:- 在
dirty map中查找key的次数超过了dirty map的大小,就会触发dirty map转换为read map的操作流程。 - 需要写入新的
key的时候,如果dirty map为nil,那么会将read map中未删除的key写入到一个新创建的dirty map中。
- 在
sync.Map性能更好的原因:尽量减少了加锁的次数,很多地方使用原子操作来保证并发安全。(如果我们的业务场景是写多读少,那么这一点可能就不成立了。)