iou的cpu和gpu源码实现
本专栏主要是深度学习/自动驾驶相关的源码实现,获取全套代码请参考
简介
IoU(Intersection over Union)是一种测量在特定数据集中检测相应物体准确度的一个标准,通常用于目标检测中预测框(bounding box)之间准确度的一个度量(预测框和实际目标框)。
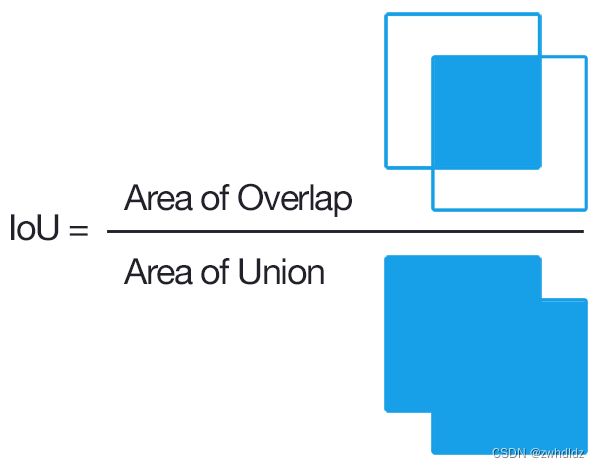
IoU计算的是“预测的边框”和“真实的边框”的交叠率,即它们的交集和并集的比值。最理想情况是完全重叠,即比值为1。
IoU的计算方法如下:
计算两个框的交集面积,即两个框的左、上、右、下四个点的交集。
计算两个框的并集面积,即两个框的左、上、右、下四个点的并集。
计算交集面积和并集面积的比值,即为 IoU 值。
IoU的优点是可以反映预测检测框与真实检测框的检测效果,并且具有尺度不变性,即对尺度不敏感。但是,IoU也存在一些缺点,例如无法反映两个框之间的距离大小(重合度),如果两个框没有相交,则 IoU 值为 0,无法进行学习训练。
源码实现:
cpu版源码实现:
def iou_core(box1: Tensor, box2: Tensor, area_sum: Tensor):
overlap_w = torch.min(box1[2],box2[2]) - torch.max(box1[0],box2[0])
overlap_h = torch.min(box1[3],box2[3]) - torch.max(box1[1],box2[1])
if overlap_w <= 0 or overlap_h <= 0:
return 0
overlap_area = overlap_h * overlap_w
return overlap_area / (area_sum - overlap_area)
def iou_cpu(box1: Tensor, box2: Tensor):
box1_num = box1.size(0)
box2_num = box2.size(0)
box1_dim = box1.size(1)
box2_dim = box2.size(1)
if box1_dim != 4 or box2_dim != 4:
return -1
box1_area = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1])
box2_area = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1])
result = torch.zeros(size=(box1_num, box2_num))
for i in range(box1_num):
for j in range(box2_num):
if box1_area[i] >= 0 and box2_area[j] >= 0:
result[i, j] = iou_core(box1[i], box2[j], box1_area[i] + box2_area[j])
else:
result[i, j] = 9999
return result
gpu版源码实现:
__device__ float iou_core(const float* box1 ,const float* box2){
float box1_x0 = *(box1 + 0);
float box1_y0 = *(box1 + 1);
float box1_x1 = *(box1 + 2);
float box1_y1 = *(box1 + 3);
float box2_x0 = *(box2 + 0);
float box2_y0 = *(box2 + 1);
float box2_x1 = *(box2 + 2);
float box2_y1 = *(box2 + 3);
if(!(box1_x0 < box1_x1 && box1_y0 < box1_y1 && box2_x0 < box2_x1 && box2_y0 < box2_y1)){
return 9999;
}
float inter_x0 = std::max(box1_x0, box2_x0);
float inter_x1 = std::min(box1_x1, box2_x1);
float inter_y0 = std::max(box1_y0, box2_y0);
float inter_y1 = std::min(box1_y1, box2_y1);
float inter_area = (inter_x1 - inter_x0)*(inter_y1-inter_y0);
inter_area = std::max(inter_area, 0.0f);
float box1_area = (box1_x1 - box1_x0)*(box1_y1-box1_y0);
float box2_area = (box2_x1 - box2_x0)*(box2_y1-box2_y0);
float iou = inter_area / (box1_area + box2_area - inter_area);
printf("iou =%f\n",iou);
return iou;
}
__global__ void iou_gpu_kernel(const int box1_num,
const float* box1_ptr,
const int box2_num,
const float* box2_ptr,
float* result_ptr){
const int box1_idx = blockIdx.x * THREADS_PER_BLOCK + threadIdx.x;
const int box2_idx = blockIdx.y * THREADS_PER_BLOCK + threadIdx.y;
printf("gpu: box1_idx = %d, box2_idy= %d\n",box1_idx,box2_idx);
if(box1_idx>=box1_num || box2_idx>=box2_num){
return;
}
printf("gpu: box1_idx = %d, box2_idy= %d, result_id= %d\n",box1_idx,box2_idx,box1_idx * box2_num + box2_idx);
const float* box1 = box1_ptr + box1_idx * 4;
const float* box2 = box2_ptr + box2_idx * 4;
float iou = iou_core(box1, box2);
*(result_ptr + box1_idx * box2_num + box2_idx) = iou;
}
void iou_gpu_launch(const int box1_num,
const float* box1_ptr,
const int box2_num,
const float* box2_ptr,
float* result_ptr){
dim3 blocks(DIVUP(box1_num, THREADS_PER_BLOCK),DIVUP(box2_num, THREADS_PER_BLOCK));//每个grid的blocks
dim3 threads(THREADS_PER_BLOCK,THREADS_PER_BLOCK);//每个block里面的thread
printf("blocks=(%d %d), threads=(%d %d)\n",
DIVUP(box1_num, THREADS_PER_BLOCK),DIVUP(box2_num, THREADS_PER_BLOCK),
THREADS_PER_BLOCK,THREADS_PER_BLOCK);
iou_gpu_kernel<<<blocks,threads>>>(box1_num,box1_ptr,box2_num,box2_ptr,result_ptr);
cudaDeviceSynchronize();// waiting for gpu work
printf("gpu done\n");
}
耗时测试:
import torch
from iou import iou_gpu, iou_cpu
from utils import TicToc
device = torch.device('cuda:0')
input1 = torch.Tensor([[0, 0, 1, 1],
[0, 2, 1, 3],
[0.2, 0, 1, 1],
[0.1, 2, 1, 3],
[0.11, 0, 1, 1],
[0, 2.4, 1, 3],
[0.2, 0.1, 1, 1],
[0.7, 2.5, 1, 3],
[0, 0, 6, 1],
[1.5, 2, 1, 3]]).to(device)
input2 = torch.Tensor([[0.5, 0, 1.5, 1],
[0, 0.5, 1, 1.5],
[0.5, 0.5, 1.5, 1.5],
[0, 0.5, 1, 2.5]]).to(device)
tictic = TicToc('iou fun')
for i in range(1000):
result = iou_gpu(input1, input2)
tictic.toc()
tictic.tic()
for i in range(1000):
result2 = iou_cpu(input1.to('cpu'), input2.to('cpu'))
tictic.toc()
pass
具体流程说明:
IoU的计算方法如下:
计算两个框的交集面积,即两个框的左、上、右、下四个点的交集。
计算两个框的并集面积,即两个框的左、上、右、下四个点的并集。
计算交集面积和并集面积的比值,即为 IoU 值。
在实际应用中,通常设定 IoU 的阈值,例如 0.5 或 0.7 等,当 IoU 值大于阈值时,认为预测成功。通过调整阈值,可以得到不同的模型,再通过不同的评价指标(如 ROC 曲线、F1 值等)来确定最优模型。
如需获取全套代码请参考