GPT-2 开源模型本地搭建(一)
GPT-2 开源模型本地搭建
- 1、GPT使用心得
- 2、py环境准备
-
- 2.1 安装Microsoft Visual C++ 14.0运行库
- 2.2 环境安装
-
- 1. 安装python 3.6或3.7
- 2. 安装pip
- 3 安装tensorflow
- 4. 安装NumPy、regex
- 5. 安装其他插件(pip freeze | grep tensorflow)
- 3、GPT-2 开源模型本地搭建(基于Hugging Face)
-
- 3.1 模型介绍
- 3.2 插件安装
- 3.3 模型运行
- 3.4 模型测试
- 4、GPT-2本地模型搭建(GitHub,坑未踩完)
-
- 4.1 模型介绍
- 4.2 模型下载
- 4.3 为什么Hugging Face下载的模型能加载,而GitHub上下载的不能用的?(要转换格式)
- 5、调试demo源码
1、GPT使用心得
ChatGPT (gpt-35-turbo) 和 GPT-4 模型是针对对话接口进行了优化的语言模型,都是输入对话和输出消息模式。
以上模型的行为与旧的 GPT-3、GPT-2 模型不同,旧的模型是文本输入和文本输出,这意味着它们接受了提示字符串并返回了一个会追加到提示的补全,旧的模型属于文本补全类模型。(本文验证了GPT-2的模型、本主另外还验证了GPT2-ML的中文模型,确实属于文本补全)
这两种模型需要以类似聊天的具体脚本形式提供输入,然后通过聊天返回补全信息,以展示模型编写的消息。 虽然这种形式专为多回合对话而设计,但你会发现它也适用于非聊天场景。
GPT-2 :4年以前就已经开源,没多少研究价值,无法投入使用;
GPT2-ML:苏剑林大佬玩的一套模型,训练了1.5B参数的体量,但能力还是一般,源码。
ChatGPT :github上有不少已经对接了OpenAI官网接口的web版,可以拿来用,比如这款。
GPT-4 :OpenAI就是微软公司的,目前微软云已经出了3.5与4系列的接口,比如预览版;
2、py环境准备
2.1 安装Microsoft Visual C++ 14.0运行库
1)下载vs_BuildTools.exe
百度网盘 ,提取码: 9ut7
2)安装c++插件
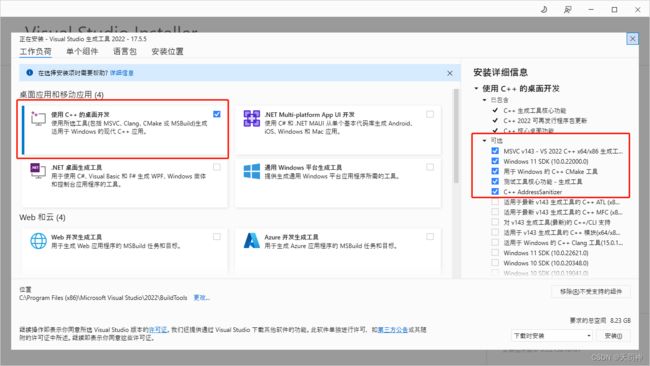
2.2 环境安装
TensorFlow 2.4.0 支持 Python 版本为 3.5-3.8,GPT-2是用TensorFlow实现的,因此需要安装TensorFlow库。
本次验证选用基于Python 3.7、TensorFlow 2.4.0。
供参考的国内镜像源
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
阿里云:https://mirrors.aliyun.com/pypi/simple/
清华:https://pypi.tuna.tsinghua.edu.cn/simple
豆瓣:http://pypi.douban.com/simple/
1. 安装python 3.6或3.7
下载对应的操作系统版本,window下载,官网、百度网盘提取码: mhkq
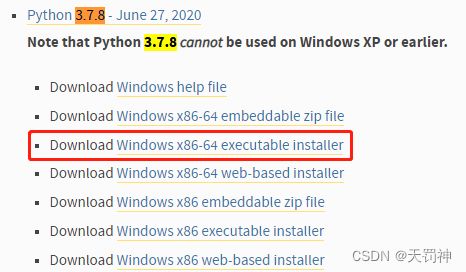
Windows选择“Add Python 3.x to PATH”选项,这样可以将Python添加到系统环境变量中,方便后续操作。
Linux上传源代码包,解压后执行:
./configure
make -j4 && make install
py -V
2. 安装pip
py -m ensurepip --default-pip
pip --version
3 安装tensorflow
pip install tensorflow==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow-gpu==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
查看已安装的 TensorFlow 版本:
pip list | grep tensorflow
pip freeze | grep tensorflow
4. 安装NumPy、regex
pip install numpy==1.19.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install regex==2020.11.13 -i https://pypi.tuna.tsinghua.edu.cn/simple
NumPy是一个用于数值计算的Python库,也是TensorFlow的依赖库之一,因此需要安装。
regex是一个正则表达式库,GPT-2使用了regex库来处理文本数据。
5. 安装其他插件(pip freeze | grep tensorflow)
pip install tensorflow-addons==0.12.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow-estimator==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow-hub==0.11.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip p install tensorflow-io-gcs-filesystem==0.20.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow-text==2.4.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install typing-extensions==3.10.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade Tokenizers -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install transformers==4.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install ctypes -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install flask -i https://pypi.tuna.tsinghua.edu.cn/simple
3、GPT-2 开源模型本地搭建(基于Hugging Face)
Hugging Face是机器学习的圣地,有非常多的模型,类似于代码界的GitHub。
3.1 模型介绍
OpenAI 已将模型开源至 Hugging Face 上,在上面可以找到以下的GPT-2预训练模型:
gpt2
gpt2-medium
gpt2-large
gpt2-xl
其中,gpt2是最小的模型,参数量为124M;gpt2-medium, gpt2-large和gpt2-xl依次是参数量增大的模型。
3.2 插件安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3.3 模型运行
1)下载模型:download.py
from transformers import GPT2Tokenizer, TFGPT2LMHeadModel
model_name = 'gpt2' # 模型名称,可以是 gpt2, gpt2-medium, gpt2-large, gpt2-xl 中的任意一个
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = TFGPT2LMHeadModel.from_pretrained(model_name)
model.save_pretrained(f"./{model_name}") # 将模型保存到本地
tokenizer.save_pretrained(f"./{model_name}") # 将 tokenizer 保存到本地
#Windows执行(py C:\01.project\gitee\gpt-2\src\download.py)
#Linux执行(python3 /root/python/gpt-2/download.py)
2)调用模型:
import tensorflow as tf
import datetime
from transformers import GPT2Tokenizer, TFGPT2LMHeadModel
from flask import Flask, jsonify, request, render_template
model_dir = "C:/01.project/chatgpt/gpt-2/models/gpt2"
# 加载 GPT-2 tokenizer
tokenizer = GPT2Tokenizer.from_pretrained(model_dir)
# 加载 GPT-2 模型
model = TFGPT2LMHeadModel.from_pretrained(model_dir)
# 创建 Flask 实例
app = Flask(__name__)
# 定义 API 接口
@app.route('/generate', methods=['POST'])
def generate_text():
# 从请求中获取文本
input_text = request.get_json()['text']
# 使用 tokenizer 对文本进行编码
input_ids = tokenizer.encode(input_text, return_tensors='tf')
# 使用模型生成文本
output_ids = model.generate(input_ids, max_length=100, num_return_sequences=1)
# 使用 tokenizer 对生成的文本进行解码
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
# 返回生成的文本
return jsonify({'generated_text': output_text})
# 启动应用
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
3)启动模型, 执行:py C:\01.project\gitee\gpt-2\src\app_huggingface_gpt2.py
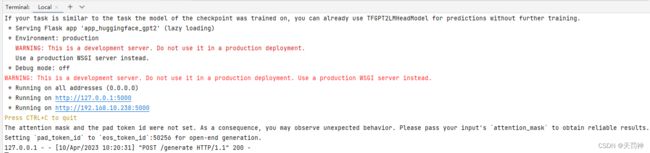
3.4 模型测试
根据测试的结果,我们知道了,这是一个文本补全模型,而不是文本对话模型。
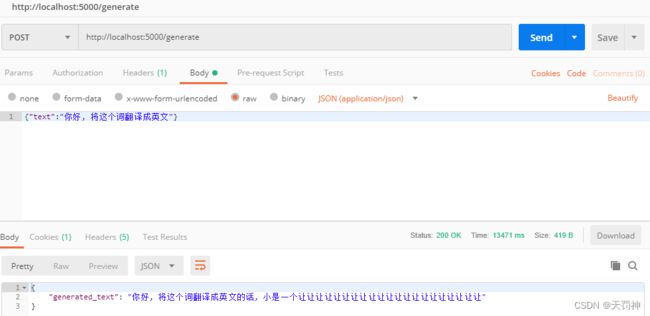
模型效果为什么这么差?
GPT-2模型在训练时是从大规模的文本语料库中学习到的语言模型,但它的训练目标是生成自然流畅的单向文本,而不是与人进行对话。因此,即使它被输入了一些问题或对话,它也只会反映出之前学习到的文本知识,并没有明确的答案或响应。而且,尽管GPT-2可以生成出一些有趣或合理的回复,但也会生成一些无意义或不连贯的回复,这可能会导致对话不友好。如果需要建立一个友好的对话模型,需要用到适合于对话的模型,如Seq2Seq、Transformer等,并在相应的数据集上进行训练和微调。
所以,这玩意不训练就根本没法用,训练的成本不低,可以找大牛训练好的模型直接用。
4、GPT-2本地模型搭建(GitHub,坑未踩完)
4.1 模型介绍
在GitHub,可以下载到开源的模型,这里的模型得用TensorFlow 1.x去跑,本文没有踩这里的坑,主要介绍Hugging Face上的模型,模型大致如下:
GPT-2 117M:117 million parameters
GPT-2 345M:345 million parameters
GPT-2 762M:762 million parameters
GPT-2 1.5B:1.5 billion parameters
GitHub上是居于TensorFlow 1.15.2,但使用TensorFlow 2.x环境也可以使用,
4.2 模型下载
1. 下载源代码
https://github.com/openai/gpt-2
2. 下载模型数据
1)进入到源码路径:cd C:\01.project\gitee\gpt-2
2)pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3)下载过程中会缺少插件:ModuleNotFoundError: No module named 'tqdm'
执行:pip3 install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple
4)下载对应模型
py download_model.py 124M
py download_model.py 355M
py download_model.py 774M
py download_model.py 1558M
5)下载后的模型文件:(124M版本)
4.3 为什么Hugging Face下载的模型能加载,而GitHub上下载的不能用的?(要转换格式)
两个下载的模型分别为tf_model.h5 和 model.ckpt.data-00000-of-00001,都是深度学习模型在不同框架下的存储格式,但它们的区别在于:
- 存储方式:tf_model.h5 是基于 HDF5 格式存储的 Keras/TensorFlow模型文件,而model.ckpt.data-00000-of-00001 则是 TensorFlow 的 checkpoint文件格式。
- 框架兼容性:tf_model.h5 主要用于 Keras 和 TensorFlow框架之间的模型转换和共享,而model.ckpt.data-00000-of-00001是TensorFloW框架保存模型权重和参数的默认格式。因此,在使用其他深度学习框架加载模型时,需要先将 TensorFlow模型转换为其他框架所支持的格式。
- 存储内容:tf_model.h5 中包括了Keras/TensorFlow模型的结构、权重和优化器参数等信息;而 model.ckpt.data-00000-of-00001只包括了 TensorFlow模型的权重数据,其模型图和其他相关参数需要通过其他文件进行保存。
但是,如果使用TensorFlow 加载model.ckpt.data-00000-of-00001模型,需要先将其转换为 TensorFlow 能够识别的格式,如 TensorFlow checkpoint 文件或 SavedModel 等。转换方式取决于你想要的最终格式。
以下是一些可能有用的转换方式:
- 从 TensorFlow checkpoint 文件中加载:可以利用 TensorFlow 官方提供的加载 checkpoint 文件的
API,例如 tf.train.load_checkpoint 函数读取模型权重,并将其转换为 TensorFlow 张量,再利用
TensorFlow 的 API 生成新的 TensorFlow 模型。import tensorflow as tf checkpoint_path = 'path/to/model.ckpt' # 创建一个空白的 TensorFlow 模型 model = YourModel() # 加载原始的 TensorFlow checkpoint 文件 checkpoint = tf.train.load_checkpoint(checkpoint_path) # 将 TensorFlow checkpoint 文件中的权重数据加载到新模型中 for var_name, tensor_value in checkpoint.items(): var_name = var_name.replace('module.', '') model_weights[var_name].assign(tensor_value) - 从 PyTorch 模型中加载:可以利用 PyTorch 和 TensorFlow 提供的模型转换工具,将 PyTorch 模型转换为
TensorFlow checkpoint 文件或 SavedModel,然后在 TensorFlow 中加载。import torch import tensorflow as tf from transformers import TFGPT2LMHeadModel # 加载 PyTorch 模型 pytorch_model = TFGPT2LMHeadModel.from_pretrained('path/to/pytorch/model') # 将 PyTorch 模型转换为 TensorFlow checkpoint 文件 pytorch_weights = pytorch_model.state_dict() tf_checkpoint_path = 'path/to/tf/checkpoint' tf.train.save_checkpoint(tf_checkpoint_path, pytorch_weights) # 加载新的 TensorFlow checkpoint 文件 new_model = YourModel() new_model.load_weights(tf_checkpoint_path) - 从 ONNX 模型中加载:如果原始模型是使用 ONNX 格式保存的,可以使用 TensorFlow 提供的
tf.experimental.tensorrt.Converter 将 ONNX 模型转换为 TensorFlow 格式,然后在
TensorFlow 中加载。import onnx import tensorflow as tf import tf2onnx # 加载 ONNX 模型 onnx_model = onnx.load('path/to/onnx/model') # 将 ONNX 模型转换为 TensorFlow 格式 tf_model_path = 'path/to/tf/model' tf2onnx.convert.from_onnx(onnx_model).save_model(tf_model_path) # 加载新的 TensorFlow 模型 new_model = YourModel() new_model.load_weights(tf_model_path)
5、调试demo源码
demo源代码请见:Gitee