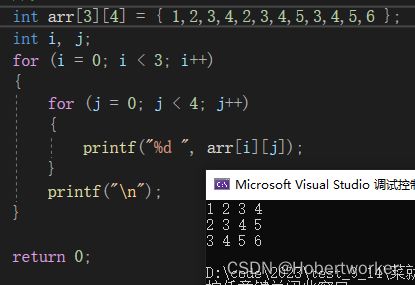
c指针初学
一.指针是什么



内存单元的编号=地址=指针
int a = 10;
&a ---->其实是取出a所占4个字节当中的第一个字节的地址,会自动地根据大小往后找
内存单元的地址是由硬件生成的,这些地址是不需要单独存起来的,只有把地址放在指针变量的时候才需要将其存放起来







指针变量的大小取决于一个地址存放时需要的空间

注:


补充:计算机中的大端存储和小端存储
"大端"和"小端"表示多字节值的哪一端存储在该值的起始地址处;小端存储在起始地址处,即是小端字节序;大端存储在起始地址处,即是大端字节序。
大端存储模式:数据的低位保存在内存中的高地址中,数据的高位保存在内存中的低地址中;
小端存储模式:数据的低位保存在内存中的低地址中,数据的高位保存在内存中的高地址中;
————————————————
版权声明:本文为CSDN博主「托马斯.杨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43886592/article/details/106336154

在内存当中,数据由低位到高位0a 00 00 00,int a =10<=>int a = 0x0000000a
我们常用的X86结构是小端模式,而KEIL C51则为大端模式,很多的ARM,DSP都为小端模式,有些ARM处理器还可以由硬件来选择是大端模式还是小端模式
x86就是32位的环境
x64就是64位的环境
c语言中的%u是输入输出格式说明符,表示按unsigned int格式输入或输出数据。
%d 有符号10进制整数
%i 有符号10进制整数
%o 无符号8进制整数
%u 无符号10进制整数%zu输出size_t型(本身就是为sizeof准备的一种格式)。size_t在库中定义为unsigned int
%x 无符号的16进制数字,并以小写abcdef表示%p 打印地址数据
%X 无符号的16进制数字,并以大写ABCDEF表示
%F/f 浮点数
%E/e 用科学表示格式的浮点数
%g使用%f和%e表示中的总的位数表示最短的来表示浮点数 G 同g格式,但表示为指数
%d 打印整型十进制数据%c 打印字符格式数据
%f 打印float浮点数据
%x 打印十六进制数据
%s 打印字符串
%lf 打印double数据
%e 以指数形式输出数据
%g 根据大小自动选f格式或e格式,且不输出无意义的零
%o 输出八进制数据
%ld 输出长整型
————————————————
版权声明:本文为CSDN博主「枳洛淮南✘」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43520256/article/details/105058248
#include
int main()
{
int* pi = NULL;
double* pa = NULL;
short* pb = NULL;
char* pc = NULL;
printf("%u\n", sizeof(pi));
printf("%u\n", sizeof(pa));
printf("%u\n", sizeof(pb));
printf("%u\n", sizeof(pc));
return 0;}
0x86环境下


下面对*pa进行讨论
int main()
{
int a = 0x11223344;
int* pa = &a;
*pa = 1;
return 0;
} 

强制类型转换后可以存下
int main()
{
int a = 0x11223344;
char* pa = (char*)&a;
return 0;
}
二.指针变量有不同类型的意义
1.类型决定了指针能够访问几个字节权限
int main()
{
int a = 0x11223344;
char* pa = (char*)&a;
*pa = 0;//解引用
return 0;
}
只修改了第一个字节的内容原因是pa作为char指针变量在解引用只能访问一个字节

2.指针加减的步长

指针类型决定了指针加一或减一操作的时候,跳过几个字节
决定了指针的步长
注:那么 int和float类型的指针有什么区别呢?

int

float


虽然这两种指针的访问大小和移位步长是一样的,但浮点数和整数在内存当中的存储方式是有所差异的

三.野指针

原因:
1.指针没有进行初始化
int mian()
{
int* p;//局部变量没有进行初始化(没有明确的指向),放在里面的内容默认为随机值,会在内存里面随机访问一个空间
*p=10;//将该空间进行赋值,就会进行非法访问
return 0;
}
2.指针越界访问
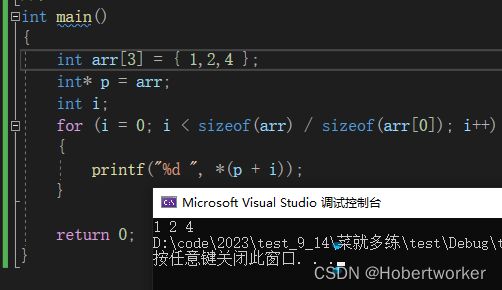
arr数组名是首元素的地址arr[0]

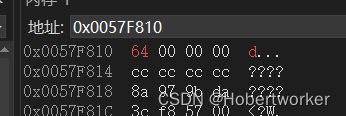
3.指针指向的空间被释放

a是一个局部变量,虽然p里面存放了之前a的地址,但是一旦出了子函数就会将其占用的空间进行销毁(可以理解成a与这块空间的连接被砍断,这块空间就不属于该程序了,但原本存在这块空间的值,如果没有其他数据干扰的话,还是依旧可以被指针进行调用的)


注:
如何去正确使用指针

初始化
(1)
int a = 10;
int* p = &a;
(2)
int* p = NULL; (现在p没有指向有效的空间,所以不能直接对解引用的*p进行赋值,*p=100,是不可以的,由于NULL 是零地址,对于零地址是不能访问的)
解决:
int* p = NULL:
if(p != NULL) //if (p)
{
*p = 100;
}
四.指针运算

1.指针+-整数
注:
(*vp++)等价于先*vp,再vp++
(*vp)++等价于对()中的*vp对象进行++


对于values[N_VALUES]是否越界访问的问题
解答:
不算,理论上来说,由于前面的数组确定了float类型,所以后面的空间也被做好了同样大小的区分
只要对后面的内存不进行直接地使用,将其用于比较是不算越界访问的
数组进行遍历
1.一般
int main()
{
int arr[10]={0};
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
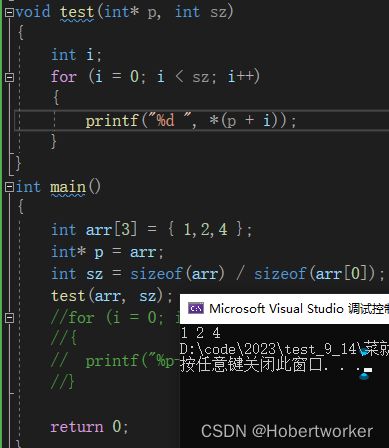
for(i=0;i { arr[i] = 1; } return 0; } 2.指针 指针减去指针的绝对值得到的是指针和指针之间的元素的个数 例:即不能用int arr[ ]的数组地址减去char arr[ ]类型的地址 下面是相关应用: 例:“abcdef”字符串在传参的时候,传过去的是a的地址; 计算字符串的长度 (1) (2) (3)利用指针减指针 可以简化为 for(p=arr[4];p>=arr[0];p--) { *p=1; } 但对于简化后的代码, 最后得到的p指针指向了arr[0]前的一个空间 可以往后越界进行比较,但不允许向前越界进行比较 数组:一组相同类型元素的集合 指针变量:存放的是地址 注:是否加括号是很重要的 *(p+i)于*p+i的区别: 指针的运算是,指针变量的运算,不是解引用指针后进行加减 将(*)代码转化成数组的形式 int arr[]还是拿到的是首元素的地址 arr[i]<--->*(arr+i) 二级指针变量是用来存放一级指针变量的地址的 对于下面的parr+i,实际上是取int* parr数组中首元素的地址,这样就将&a的地址放在了另一个变量中,故进行解引用时,要进行两次解引用 注: 两种写法: 将三个一维数组模拟成二维数组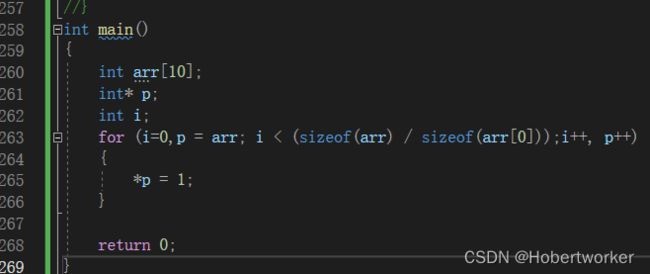

2.指针减去指针






3.指针的关系运算



五.指针和数组





 (*)
(*)
六.二级指针
1.介绍

2.int* *,int**,int*,int *如何进行理解其写法的差异

七.指针数组