CUDA基础教程文档记录
目录
-
- 前言
- 0. CUDA基础语法
- 1. CUDA共享内存
- 2. GPU架构简介
- 3. CUDA内存子系统
- 4. 原子/规约操作和warp shuffle
- 5. CUDA统一内存(Managed Memory)
- 6. CUDA流和并发
- 7. Profiler驱动的优化
前言
学习手写 AI 中 HY 大佬的《CUDA基础教程》八讲视频,由于没有文档,所以手动记录下,仅供自己参考
部分实战代码讲解部分并没有记录,建议大家观看原视频,视频链接
文档配合视频,食用更佳
感谢 HY 大佬的分享
0. CUDA基础语法
CUDA 语言版本:cuda c++/cuda Fortran/cuda Python/cuda Matlab,本文档 cuda 讲解 cuda c++,遵守 c++ 标准
GPU 和 CPU 异构计算:计算密集型 -> GPU,逻辑流控制 -> CPU
Typical workflow:
- a. 先把数据从 CPU 内存拷到 GPU 显存上
- b. 执行 GPU 程序计算,以多个线程 (gridDim * blockDim) 一起计算 SIMT 的方式
- c. 把结果从 GPU 显存中拷回 CPU 内存里
host 和 device 内存物理上是隔离的,设备指针(device pointer/gpu pointer)指向 GPU 显存地址,无法在 CPU 端解引用。主机指针(host pointer/cpu pointer)指向 CPU 内存地址,无法在 GPU 端解引用。需要用 cudaMalloc(),cudaFree()。cudaMemcpy()… 这些 CUDA API 来实现对设备显存的操作。
// nvcc simplekernel.cu -o simplekernel
#include threadIdx.x threadIdx.x threadIdx.x threadIdx.x
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
|0|1|2|3|4|5|6|7 |0|1|2|3|4|5|6|7 |0|1|2|3|4|5|6|7 |0|1|2|3|4|5|6|7
blockIdx.x = 0 blockIdx.x = 1 blockIdx.x = 2 blockIdx.x = 3
data:
|0|1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24|25|26|27|28|29|30|31
4 blocks in total, each of them contain 8 threads
data[20] = 2(blockIdx.x) * 8(blockDim.x) + 4(threadIdx.x)
// nvcc add.cu -o add && ./add
#include "cuda_runtime.h"
#include d_ap(d_a);
// std::unique_ptr d_bp(d_b);
// std::unique_ptr d_cp(d_c);
// printf("d_ap.get(): %p, d_bp.get(): %p, d_cp.get(): %p\n", d_ap.get(), d_bp.get(), d_cp.get());
// addkernel<<>>(d_ap.get(), d_bp.get(), d_cp.get(), N);
Obj obj(100);
addkernel<<<m, n>>>(d_a, d_b, d_c, N, obj);
CHECK(cudaGetLastError());
CHECK(cudaDeviceSynchronize());
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
for(int i = 0; i < 5; i++)
{
printf("gpu result %d, cpu result %d\n", c[i], 3 * i);
}
// printf("after addkernel called, obj._a: %d\n", obj._a);
free(a);
free(b);
free(c);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}
几点注意事项:
1. \space kernel 函数可以是模板函数,在实现插件不同精度计算流程时有用,但由于计算逻辑不一致,需要模板特化
2. \space 除了指针之外,传递给 kernel 函数的可以是 c++ 的对象,此时只能是 pass by value semantics,否则会报 an illegal memory access was encountered 的错误
3. \space .cu 文件里面可以可以使用智能指针,编译没问题。但是 host 和 device 之间传递数据的指针需要是原始指针。符合 c++ 语言标准并不意味着支持 c++ 的标准库里所有特征,智能指针是标准库里的东西(std::shared_ptr
4. \space c++ 语言标准并没有强制规定类型的大小。sizeof(long) 的值由编译器决定,不同操作系统和体系结构使用不同的数据模型(Data Models and Word Size,数据模型(LP32 LP64 LLP64 ILP64)-Isgxeva-博客园)。在这类问题上,nvcc 负责和 host 编译器(比如 gcc 和 g++)保持一致
5. \space 同一个 block 里面的 threads 可以通信和同步,简单的例子比如向量相加可能用不到这种机制
1. CUDA共享内存
上节课提到 CUDA 编程模型设计 grid 和 block 两个层级的概念是因为一个 block 里的线程可以使用共享内存通信(一个线程写,另外一个线程读)。共享内存(Shared memory)是一种片上高速缓存。当要解决的问题可以 data 复用的时候,每次都从 global(在 DRAM 上,*d_a,*d_b,*d_c 这些都是)读取的话比较损失性能,可以考虑用 shared memory 作为缓存来加速(这个思想对于所有有内存层级结构的硬件都适用,不止 GPU/CUDA)
Shared memory 的特性:
1. Shared memory 是在芯片上(on-chip)的内存。数量少,速度快(higher bandwidth,lower latency)
2. 只对一个 block 里面的所有线程可见,其他 block 有它们自己的 shared memory 副本
3. 相比于 L1 缓存(同样 on-chip),它可以由程序员管理,用 __shared__ 来分配
4. 有动态和静态分配方式,两种分配方式没有性能差异:
- a. 静态:__shared__temp[size];
- b. 动态:__shared__temp[];kernel<<
1D stencil 问题的定义:每个元素的 output 是其周围(包括它自己)2r+1 个元素的和(类似一维卷积)。例子:
|x|x|x| input |x|x|x|
|x|x|x| output|x|x|x|
当 r 是 3 的时候,每个元素计算其周围 7 个元素的和。注意:输入输出的数量规模是一样的(有别于数据规约求和)
在一个线程块 block 里面的每个线程计算一个 output,输入数据存在重复读取的情况:
input: |x|x|x|X|Y|x|x|output|x|x|x|x|x|x|x|…(总体数据量很大,这边只考虑一个 block 里的情况)
^ ^
计算 X 时候,需读取周围 7 个元素。计算 Y 的时候,也需要读取周围 7 个元素。平均下来,当 r 是 3 的时候,每个输入数据需要被读取 7 次,它在 7 个输出数据的计算过程中被用到
思路:把数据缓存在 shared memory 里:
1. 设置一个 block 里要处理的数据量正好是 blockDim.x 个
2. 从 global memory 里面读取 blockDim.x + 2 * r(原因见下)这么多输入数据到 shared memory 里
3. 计算 blockDim.x 个输出数据,每个线程用自己的寄存器保存求和的结果(res)
4. 把 blockDim.x 个输出数据写回 global memory 里
5. 每个 block 需要在左右边界分别填补 r 个元素,r = 3 的例子
|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|
|x|x|x|^ ^|x|x|x|
Example:
#define r 3
__global__ stencil_1d(int* in, int* out){
__shared__ int temp[BLOCK_SIZE + 2 * r]; // per-block, static allocation
int gindex = threadIdx.x + blockIdx.x * blockDim.x; // 用来索引 global memory
int lindex = threadIdx.x + r; // 用来索引 shared memory
// 把数据从 global memory 读到 shared memory 里。没有 for 循环,SIMT 模式,一个 block 里所有线程合作完成
temp[lindex] = in[gindex];
if(threadIdx.x < r){
temp[lindex - r] = in[gindex - r];
temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE];
}
__syncthreads(); // 确保所有数据已经读到 shared memory 里,注意不能写在 if 条件语句里
int res = 0;
// 此时需要 for 循环,因为一次线程要负责计算 2*r+1 个元素的和
for(int offset = -r; offset <= r; offset++)
res += temp[lindex + offset];
out[gindex] = res;
}
2. GPU架构简介
前面两节课讲了如何写语法正确的 CUDA。人们使用 CUDA 的原因是提高性能,而这需要了解 GPU 的硬件架构知识教程里的提高并行度,增加 GPU 使用率 -> 使用足够多的线程,但是什么是“足够多”?
GPU 的 core 和 CPU 的 ALU 类似,CPU 的 core 和 GPU 的 sm 类似
Dual-issue:warp schedule 能够在同一个时钟周期内调度两条在一个指令队列里的相邻的指令
一般而言,SM 数量越多,性能越好。程序可以在不用重新编译的情况下自动适配有更多的 SM 的架构
Warp scheduler: 决定了什么时候哪条指令得到执行,warp-by-warp 的,永远是一个 warp(32 个线程一起执行)
同一架构里,Compute compability(CC)的第一个数字是一样的(Turing 除外,它和 Volta 一样,也是 7.x)
cc5.2 和 cc6.1 硬件架构类似,cc6.0 和 cc7.0 硬件架构类似
Tesla GPU 的显存有 ecc 内存(内存ECC 机制),Geforce 系列则没有
一个线程块里的线程不会跨越 SM 驻留,从始至终(from 指令 issue to retire)它们总是驻留在一个 SM 里




NVIDIA GPU 架构梳理 NVIDIA Ampere 架构深度解析
一个线程块 block 可以进一步分为多个 warp,一个 warp 由 32 个线程组成。指令的执行总是以 warp(32 个线程)为单位 GPU 没有 CPU 那样预取和分支预测之类的机制,它能提高性能的方式只有一个:延迟隐藏(latency hiding)。这一点需要有足够的 warp 来实现,也就是足够多的线程。回答”设置几个线程(gridDim.x * blockDim.x)合适“这个问题?
Latency:你要一个东西和你得到一个东西之间的时间间隔,通常用 clock cycle 来衡量
全局内存访问的 latency:>100(or hundreds)计算的 latency:<100(typical 5)cycles
假设你是 warp 调度器,你的目标是使得机器不要有闲置的时刻,这样就能取得高性能

注意在真实的场景中,访问全局内存的 latency 要远大于 18 个 cycle。如果你的 warp 数量是无限大,那么你的机器永远不会闲置,但这是不可能的。Volta:64 warps per SM 是上限值,80(SMs)* 64 * 32(threads/warp)= 163840,gridDim.x * blockDim.x 的值如果小于 163840,那么对于 Volta 架构,是没有完全利用处理器性能的。
注意事项:
1. 以上讨论没有考虑 cache 的存在,初代 GPU 是没有 cache 的,说明 latency hiding 任何时候都有用
2. 当然,如果指令之间没有依赖性时也可以做到 latency hiding
3. 如果你的 kernel 是带宽(计算 or 访存)受限,那么增加一个 SM 里线程数量也不会提高性能
4. 同一个时钟周期内,10 指令可以有不同的 warp 由不同的 warp scheduler 来调度,在计算资源充足的情况下
5. 上图里的 warp 可以来自不同的 block,一个 SM 里可以同时驻留多个 block,但是有上限。见下面的代码:
6. 在第 5 点没达到上限的情况下,把一个 block 里的 warp 数减半同时增加一倍的 blocks 和之前版本没有性能差异
// 演示 block schedule 的示例代码
// 一个 SM 里能同时驻留的 block 数量是有限制的,(Maxwell/Pascal/Volta:32)
#include 3. CUDA内存子系统
上节课我们结合 GPU 的硬件架构学到了 CUDA 性能优化的一大准则:开启足够多的线程,这节课我们学习另一大准则:高效利用内存子系统,我们主要讨论对 global 和 shared memory 的访问。
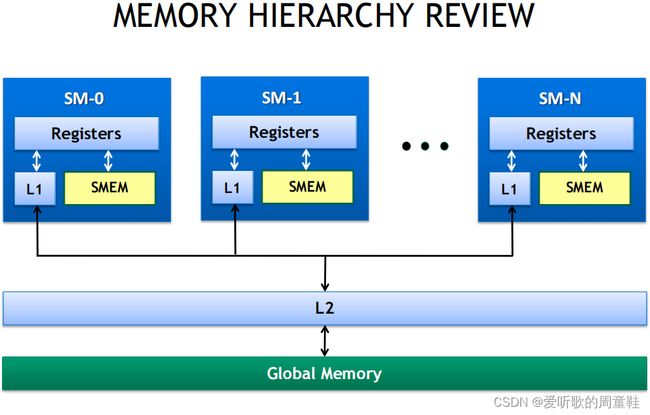
GPU 内存层级结构:
1. 本地存储(local storage),每个线程独有,通常是指寄存器,stencil 问题里保存求和结果的变量 res
2. 共享内存/L1 缓存,通常是 48(6496)KB 这个级别。可以由程序员管理,对于一个 block 里所以的线程可见,访问速度很快,带宽很高,通常大于 1TB/s,L1 没有 cache 一致性协议
3. L2 缓存,device 级别的资源,对于所有线程可见,用来缓存对于 global 内存的访问。L2 缓存有 cache 一致性协议。
4. Global 内存,对于所有线程可见,CPU 也可以。latency 比较高(几百个 cycles),带宽通常是 900GB/s(Volta V100),768GB/s(a5000)这个级别。用 cudaMalloc 和 cudaFree 来管理。

Global memory 的访问特性:
1. 读取:有 Caching,是默认的行为,当读取一个数据时,先从 L1 中找,找不到的话从 L2 中找,再找不到的话才从 global memory,一次读取的粒度是 128 个 bytes,称为一个缓存行。也可以说没有缓存的,通过给 nvcc 传递 -Xptxas -dlcm=cg 这个参数。这个时候读取的粒度是 32 个 bytes。什么时候有用?程序正确性角度:想要两个在不同 SM 里的线程通信时有用。性能角度:缓解全局内存访问不合并时候有用(见下文)。
2. 写入:使 L1 中某个缓存行失效,也就是如果将来有对这个数据的读取,L1 Cache 会 miss,对于 L2 是回写式(write-back),也就是先更新 L2 里内存,在将来某个时刻再写回到 global 内存里。
注意:访存操作也是一个 warp 里的 32 个线程一起执行的,不同线程可以访问不同内容的数据(通常是 32 个不同的地址)。内存控制器(memory controller)决定了需要访问哪一个缓存行(不是一个字节)。
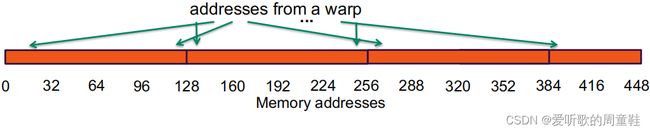
下图中,一个 warp 里要访问的地址正好落在一个 32 位对齐的缓存行(128 bytes)里,它们是相邻且连续的。128 bytes 通过 bus 传输从 global memory 传输到寄存器中。它们也是计算时用到的,bus 带宽的利用率是 100%。int c = a[idx]; 这样的访存模式称为合并访存(coalesced)

下图中,虽然每个线程要访问的地址是不连续的,但它们同样落在一个 32 位对齐的缓存行里。这样的访存模式也是合并的,带宽的利用率也是 100%。int c = a[rand()%warpSize];。

下图中,一个 warp 里的线程要访问的地址是没有 32 位对齐的连续的 128 bytes,此时这些地址落在了 2 个缓存行里。这导致实际在 bus 上传输的数据量是 256 bytes,但是计算有用的才 128 bytes。bus 利用率是 50%,传输的 256 bytes 里有一半没有用到,此时的访存模式不是合并的。int c = a[idx-2];。从这个角度看,如果 kernel 是带宽受限(memory bound),那么性能直接下降一半。但是当其他 warp 的线程访存的时候,会发现数据已经在缓存中了,所以均摊下来,平均一个 warp 需要访问一个缓存行,性能和合并访存几乎没有差异。

下图中,一个 warp 里 32 个线程要访问的是同一个地址,此时还是需要传输一个缓冲行的数据量,也就是 128 bytes。用到的只是其中的 4 bytes,bus 的利用率是 4/128=3.125%,int c = a[30]。

下图中,一个 warp 里 32 个线程访问的地址是随机的,最差的情况是每个地址都落在了一个缓冲行里面。bus 利用率:128/(128*N),N=32 时,最差 3.125%。int c = a[rand()]。通常间接寻址会导致这种访存模式(index 本身是随机数产生的),scatterND 操作为什么性能低?
下图中,如果通过 Xptxas -dlcm=cg 把 L1 缓存关掉,则没有缓存行的存在,每次可以只读 32 个 bytes。此时最差情况当 N=32 时的 bus 利用率是 128/(32*N)=12.5%。有助于改善全局内存访问不合并的问题。

优化策略:想办法做到合并访存,有时候可考虑 padding。一个 warp 里的线程尽可能访问连续的内存区域。对于 memory bound 的核函数,努力提升 bus 的利用率。如何做到?在保证线程数量足够多的情况下,可以考虑让一个线程处理多个数据 -> 向量化访存(vector-load)
共享内存(shared memory)的组织/性能和使用场景:
1. 32 个 bank,每个 bank 宽度为 4 个字节。两个相差为 4 个 bytes 的地址属于相邻的不同 bank,两个相差 128 bytes 的地址属于相同的 bank。
2. 用共享内存来实现块(block)内线程间的通信以及缓存重复的对全局访存的访问,改善全局内存访问模式(矩阵转置)
3. Shared memory 的带宽很高,通常大于 1TB/s,它没有合并访问的问题,但是需要注意 bank 冲突,一个 SM 可以在 1 到 2 个时钟周期里来处理访问来自不同 bank 里地址的访存请求。相反地,如果要访问地地址来自相同的 bank,则需要更多的时钟周期来序列化访问(bank0,bank1…),此时称为 bank 冲突。但如果要访问的是同一个 bank 里相同的地址(multicast),则此时也不会有 bank 冲突。


以下两种情况没有 bank 冲突。注意 bank 不代表是地址,线程 0 访问 bank0 说明线程 0 访问的内存地址在第一列
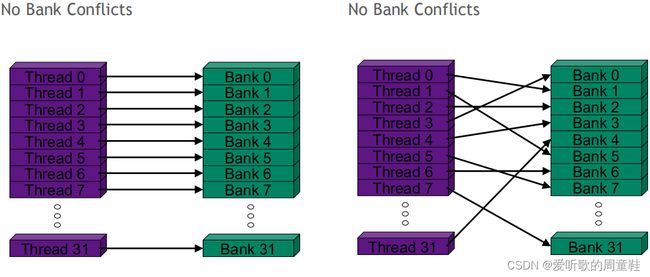
以下分别是 2 路和 16 路 bank 冲突的情况:

假设 shared memory 是 32x32 大小,一个 warp 的 32 线程访问同一个 bank(颜色相同的一列),此时发生了 32 路 bank 冲突,该怎么解决这个问题呢?把 shared memory 添加一列变成 32x33 大小,则此时每一列的地址属于不同的 bank(颜色不一致),此时是没有 bank 冲突的。padding 的元素永远不会被访问。


4. 原子/规约操作和warp shuffle
之前的课程我们学习了 transform 类型的问题(数目输出规模大体一致),这节课我们学习原子/规约操作和 warp shuffle。什么是规约操作?求一个数组的和/最大值/最小值。输入是 N 个数据,输出是 1 个数据。我们需要回答这样一个问题:每个线程该干一件什么事情(thread strategy)?transform 类型的问题很直观,每个线程独立做一些计算(比如,out = in * scale)。规约类问题(reduction)则没有那么的直观。
开启和输入数据规模一样大规模的线程,每个线程在一个全局变量上进行累加,伪代码和汇编如下:
c += a[i];
LD R2,a[i]
LD R1,c
ADD R3,R1,R2
ST c,R3
每个线程独立地执行上面的指令,cuda 编程模型并不保证线程执行的顺序,最后的结果可能是错误的。需要用 atomicAdd(&c, a[i]) 来确保正确性,上面 4~6 行的指令会变成一条不可分割的指令:
RED.E.ADD.F32.FTZ.RN[c],R2;
原子操作的实现需要用到 L2 缓存,因为此时线程之间不再并发,而是等一个线程先执行三条指令完了之后其他线程才会开始执行相同的三条指令,所以会对性能有影响。原子操作有很多,有 atomicMax/Min/Sub/Inc… 所有的原子操作都可以用 atomicCAS 这个原子操作来实现。在 Pascal 架构以前,atomicAdd 函数不支持 double 精度的浮点数,可以用 atomicCAS 函数来实现支持 double 精度的 atomicAdd 函数。但是这个版本的函数要比 Pascal 以及更高架构原生提供的 atomicAdd 函数慢很多,有兴趣的话可以改下这份(https://github.com/HaohaoNJU/CenterPoint/blob/master/src/preprocess.cu#L94)代码看快了多少。
atomicAdd 函数的返回值是其第一参数里的加之前的值,这一点可以用来并行地决定要处理的数据在队列的位置:
int index = atomicAdd(order, 1);
在临时 buffer 里预留一定的空间:每个线程独自产生一定量的数据,如何并行地将它们收集在一个 buffer 里?
buffer_ptr: ->| | | | | |
buffer_idx: ---^
int size = var;
float local_buffer[size] = {...}; // 产生一批大小是 size 数据
int offset = atomicAdd(buffer_index, size); // 之前数据存在 buffer_index 这个位置处
memcpy(buffer_ptr + offset, local_buffer, size * sizeof(float));
这个是经典的流压缩问题(stream compaction):CUDA流压缩算法 | 码农家园,atomicAdd 可能不是最高效的实现
原子操作不能完全利用内存带宽,有损性能。我们需要一个更高效的算法来求解规约问题,尽可能用到所有的线程。parallel reduction 是一种常见的规约的方式,它采取了一种树状的方式:

下层的节点在运算之前需要保证上层的节点已经计算完毕,需要全局的同步。可以通过开启不同的核函数来实现这点,一层开启一个核函数,不同的核函数天然地可以作为一个全局地同步点,但是开启核函数也有 overhead。也可以在每个 block 层级 reduction 计算的结尾处使用原子操作来确保同步。或者关于CUDA中__threadfence的理解-CSDN博客和协作组(cooperative groups,cudaLaunchCooperativeKernel)
Sweep reduction:
for(unsigned int s = blockDim.x/2; s>0; s>>=1)
{
if(tid < s){
sdata[tid] += sdata[tid+s]; // 右半部分加到左半部分
}
__syncthreads(); // 在 if 条件语句的外面
}

最终得到的是一个 block 里面所有元素的局部和。也可以相邻元素相加求和的方式,但是 sweep 的访问方式可以避免 bank 冲突的问题,也可以规避浮点数相加没有交换律的问题(大数吃小数)。
希望设计的核函数可以处理任何规模的输入数据,一个 block 里开启的线程数目不受输入数据的影响->grid-stride loop
// gdata[0...N-1] | | | | | | | | | | | | | | | | | | | | | | | | | | | |...
// |grid-width stride|grid-width stride|grid-width stride|...
int idx = threadIdx.x + blockDim.x * blockIdx.x;
while(idx < N){
sdata[tid] += gdata[idx]; // 一个 warp 里所有的线程都加上
idx += gridDim.x * blockDim.x; // grid width, 可以小于,等于或大于输入数据的规模 N
}
一个完整的 kernel 函数:
__global__ void reduce(float* gdata, float* out){
__shared__ float sdata[BLOCK_SIZE];
int tid = threadIdx.x;
sdata[tid] = 0.0f;
size_t idx = threadIdx.x + blockDim.x * blockIdx.x;
while(idx < N){ // grid stride loop to load data
sdata[tid] += gdata[idx];
idx += gridDim.x * blockDim.x;
}
for(unsigned int s = blockDim.x/2; s>0; s>=1){
__syncthreads();
if(tid < s) sdata[tid] += sdata[tid+s]; // parallel sweep reduction
}
if(tid == 0) out[blockIdx.x] = sdata[0]; // 这里只是一个 block 里面的局部和
// if(tid == 0) atomicAdd(out, sdata[0]); // 这样可以避免再开启一个 kernel
}
Warp shuffle:
利用共享内存 shared memory 可以实现 block 内的线程之间的通信,CUDA 9.0 之后可以使用另外一种不用到 shared memory 更高效的通信机制:warp shuffle。是一个 warp 里的线程束之间的通信机制,比如 shared memory 更细粒度:
1. __shfl_sync():拷贝来自任意 lane id(0~31) 线程里的值
2. __shfl_xor_sync():拷贝来自一个计算出来的 lane id(0~31) 线程里的值
3. __shfl_up_sync():拷贝来自有一定偏移量 lane id 更小的线程里的值
4. __sync_down_sync():拷贝来自有一定偏移量 lane id 更大的线程里的值
源线程和目标线程必须参与计算(不能有一个在 if 条件语句里),参数 mask 同来代表哪些线程需要参与计算。
__global__ void reduce_ws(float* gdata, float* out){
__shared__ float sdata[2];
int tid = threadIdx.x;
int idx = threadIdx.x + blockDim.x + blockIdx.x;
float val = 0.0f; // 用来保存累加结果的是一个临时变量,而不是 shared memory
unsigned mask = 0xFFFFFFFFU; // 32 个 1 代表一个 warp 里的 32 个线程全都参与计算
int lane = threadIdx.x % warpSize; // 当前线程是 warp 内部的哪个线程
int warpId = threadIdx.x / warpSize; // 当前线程是属于哪一个 warp
while(idx < N){ // grid stride loop to load gdata
val += gdata[idx];
idx += gridDim.x * blockDim.x;
}
// 1st warp-shuffle reduction,每个 warp 内部求和
for(int offset = warpSize/2; offset>2; offset>>=1)
val += __shfl_down_sync(mask, val, offset);
// 第一轮迭代
// 把线程号为 16 的 val 值加到线程号为 0 的 val 值上,结果记录在线程号是 0 的 val 值里
// 把线程号为 17 的 val 值加到线程号为 1 的 val 值上,结果记录在线程号是 1 的 val 值里
// 第二轮迭代
// 把线程号为 8 的 val 值加到线程号为 0 的 val 值上,结果记录在线程号是 0 的 val 值里
// 把线程号为 9 的 val 值加到线程号为 1 的 val 值上,结果记录在线程号是 1 的 val 值里
if(lane == 0) sdata[warpId] = val; // 每个 warp 有一个求和的结果,最多 32 个 warp
// 内部求和的结果累加到线程号是 0 的线程的 val 值里,这步是把放到 shared memory 里
__syncthreads();
// 之后只在第一个 warp 里进行求和即可
if(warpId == 0){
// 如果 warp 存在,则把数据从 shared memory 里再读取出来
// 比如 blockDim.x = 1024,tid(0~1023),一共有 32 个 warp
val = (tid < blockDim.x / warpSize) ? sdata[lane] : 0;
// 最后再 warp 之间再做一次求和操作
for(int offset = warpSize / 2; offset > 0; offset >>= 1)
val += __shfl_down_sync(mask, val, offset);
if(tid == 0) atomicAdd(out, val);
}
}
Warp shuffle 的优点:
1. 可以减轻或者消除对 shared memory 的使用,让核函数的 occupancy 不再受到 shared memory 的限制
2. 从机器执行的指令角度看,把之前对 shared memory 的读写的 2 条指令变成了一条指令
3. 减少了显式同步的次数,也就是对 __syncthreads() 语句的调用次数,提升了性能
其它使用场景:
1. Warp shuffle 还可以用来求 warp 级别的前缀和(prefix-sum)以及排序(sort),CUDA高性能计算经典问题(二)—— 前缀和(Prefix Sum)
2. 减轻 atomicAdd 之类的原子操作对 L2 缓存系统的压力。一个 warp 里的 32 个线程都调用一次 atomicAdd 来进行求和操作。warp shuffle 先在一个 warp 里面求和,然后调用一次 atomicAdd(atomic aggregation)
对于 for 循环,gcc 里的 #pragma unroll N 语句对于 nvcc 编译器同样有优化效果,本质是循环展开之后可以对指令进行重新排序,降低对访存指令的依赖性。具体讨论可见循环展开。为了方便编译器做这件事情,循环的次数最好是在编译期间就确定下来。
Mask 参数和 if 条件语句的区别:Pascal 以及之前的架构中,if 条件语句之后,divergent 的 warp 需要重新 reconverge,但这有点有损性能。从 Volta 架构开始,如果有性能的原因且不影响程序的正确性,那么即使 if 条件语句结束, warp 仍然可以保持 divergent 的状态,虽然看起来应该是 reconverge 了。但是编译器没有义务保证这一点。注意是可以,具体是不是 divergent 的状态是个灰色地带。但有时候需要 convergence 来确保程序的正确性,比如 warp shuffle 操作。新的 CUDA(cuda 9.0+) 编程模型有了 mask 参数。它告诉编译器,不管 warp 的状态是不是 convergent 的,如果 warp 是 divergent 的,并且代码不在任何阻止 convergent 的 if 条件语句里面,那么必须回到 convergent 的状态来确保将要执行的指令是有效且能产生正确的结果。注意只是 mask 参数指定的线程(比如 16)需要 reconvergent,其他未指定的线程是什么状(convergent 还是 divergent)还是未知的。
What does mask mean in warp shuffle functions(__shfl_sync)
CUDA C++ Programming Guide
supported by devices of compute capability 5.0 or higher.
Deprecation Notice: __shfl, __shfl_up, __shfl_down, and __shfl_xor have been deprecated in CUDA 9.0 for all devices.
Removal Notice: When targeting devices with compute capability 7.x or higher, __shfl, __shfl_up, __shfl_down, and __shfl_xor are no longer available and their sync variants should be used instead.
5. CUDA统一内存(Managed Memory)
这节课我们学习 cuda 的统一内存(managed memory):目的是为了简化编程,不一定能提高性能。
cuda 编程模型需要三步走策略:1. 从 cpu 拷数据到 gpu 2. 在 gpu 上执行计算 3. 把结果从 gpu 拷回 cpu。利用 managed memory,程序员可以不用显式地做 1 和 3,cudaruntime 自动完成这件事。Managed Memory 不是一开始就有的特性,是从 2012-2013/cuda 6.0/kepler 架构开始才有的特性。
只有一个指针,数据只有一份,通过 data migration 机制来实现统一内存。哪个处理器需要数据,就把数据搬到哪边,天然地保证了数据一致性。没有 data race 的情况,同一个时钟周期内数据只能被一个处理器访问。
从 pascal 架构/cuda 8 开始,统一内存有了 oversubscription/demand paging 的机制,可以用 cudaMallocManaged 分配超过 GPU 显存大小的数据量(比如如果显存是 16G,那 cudaMalloc 最多只能分配 16 G 的数据量),但是也不能超过 system memory 的大小。之前学习的原子操作对于统一内存也适用,提供了跨处理器的能力(atomicAdd_system)。
// cpu 代码
void sortfile(FILE* fp, int N){
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, compare);
use_data(data);
free(data);
}
// 不使用统一内存的 cuda 代码
void sortfile(FILE* fp, int N){
char* data, *d_data;
data = (char*)malloc(N);
cudaMalloc(&d_data, N);
fread(data, 1, N, fp);
cudaMemcpy(d_data, data, N, cudaMemcpyHostToDevice); // 1
qsort<<<...>>>(d_data, N, 1); // 2
cudaMemcpy(data, d_data, N, cudaMemcpyDeviceToHost); // 3, 同步操作
use_data(data);
cudaFree(d_data);
free(data);
}
// 使用统一内存的 cuda 代码
void sortfile(FILE* fp, int N){
char* data;
cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort<<<...>>>(data, N, 1);
cudaDeviceSynchronize(); // 比起 cpu 代码就多了这么一行,因为 gpu 和 gpu 是异步执行的
use_data(data);
cudaFree(data);
}
和 malloc 一样,cudaMalloc,cudaMallocManaged 只负责申请,不负责初始化:
__global__ void setValue(int* ptr, int index, int val)
{
ptr[index] = val;
}
void foo(int size){
char* data;
cudaMallocManaged(&data, size); // 申请统一内存
memset(data, 0, size); // 在 CPU 端访问所有的数据
setValue<<<...>>>(data, size/2, 5); // 在 GPU 端访问某一个数据
cudaDeviceSynchronize();
useData(data);
cudaFree(data);
}
下图展示统一内存的工作机制,通过缺页中断(page fault)来实现,page fault 在 cpu 和 gpu 上都可以触发
1. cudaMallocManaged() 预留了一些内存,但此时还没有页分配的操作(bring allocation into existence)
2. 调用 memset 的时候会发生缺页中断([page fault]),此时数据都在 CPU 的 system memory 里,已经初始化
3. setValue 会同样出发 page fault,这个中断会把用到的数据所在的 page 通过 bus 搬到 GPU 里(data migration)
4. 也可以先在 GPU 上分配好所有的页,然后在 CPU 端用到的时候触发 page fault

注意和 pinned memory 的区别:pinned memory 一直是 host memory,只不过有时候可以被 gpu 访问到。
cudaMallocManaged 分配的内存,如果一会儿在 gpu 端访问,一会儿在 cpu 端访问,性能会很差(频繁触发 page fault)
如果用 cudaMallocManaged 分配一段内存,但是从来不在 gpu 端去访问它。这段内存第一次在 cpu 上访问的时候,和直接用 malloc 分配的内存相比,还是会有略微性能上的差距,这点和 cpu 的缓存机制有关。
和 GPUDirect RDMA 的区别:GPUDirect RDMA 和统一内存没有关系,它本质上是在 cpu 里分配一段 buffer,这段 buffer 可以被一些第三方设备(比如网卡)直接访问,而不需要经过 system memory。这段 buffer 不是由程序员手动分配的。
在 Pascal 架构以前,或者在 windows 操作系统上,没有按需搬移(on-demand migration),认购超额(oversubscription),并发访问(concurrent access)这些机制。cudaMallocManaged 分配的内存会在 kernel 启动的时候全部搬到 GPU 上(即使 kernel 用不到)。然后在 kernel 函数结束的时候,再通过调用 cudaDeviceSynchronize() 来使得数据又可以在 CPU 端访问,如果没有会报 segmentation fault。在 Pascal 架构之后不再调用 cudaDeviceSynchronize() 的话不会 segmentation fault,虽然程序结果不一定正确。
__global__ void mykernel(char* data){
data[1] = 'g';
}
void foo(){
char* data;
cudaMallocManaged(&data, 2);
mykernel<<<...>>>(data);
// 注意这里没有调用 cudaDeviceSynchronize()
data[0] = 'c'; // pascal 架构之前会报 segmentation fault,pascal 架构之后不会,但不确保访问顺序
cudaFree(data); // data[0] 和 data[1] 的访问顺序不确定
}
__global__ void mykernel(int* addr){
atomicAdd_system(addr, 10); // 实现多个 gpu 之间的原子操作,pascal 架构开始才支持
}
void foo(){
int* addr;
cudaMallocManaged(addr, 4);
*addr = 0;
mykernel<<<...>>>(addr);
// cpu atomic
__sync_fetch_and_add(addr, 10);
}
以下代码验证了 Pascal 架构之后的 oversubscription 的特性:
void foo(){
// 假设 GPU 显存一共 16G
// 利用 cudaMallocManaged 可以分配 64G 的内存
char* data;
size_t size = 64ULL * 1024 * 1024 * 1024; // 注意 size 的类型是 size_t
cudaMallocManaged(&data, size);
}
注意以上讨论不适用于 jetson 系统的 SoC 上,在 jetson 系统上,host 和 device memory 在物理上是一个东西。所有如果程序员是使用 cudaMallocManaged 分配的内存,访问的时候是不会触发缺页中断(数据搬移)的,所以也不会有任何的性能损失,不管在 CPU 端还是 GPU 端。如果在 jetson 上使用普通的 malloc 和 cudaMalloc/cudaMemcpy 来操作的话,那么在整个 dram 里有两块区域保持着相同的数据,它们分别由各自的指针(device pointer/host pointer)才能访问到,这时候就没有高效利用内存。
统一内存使用的场景
1. 深拷贝(deep copy)
struct dataElem{
int key;
int len;
char* name; // 指向一个 buffer,char buffer[len]
}
// 不用统一内存的代码
void launch(dataElem* elem, int N){ // 一个数组,数据里面的元素类型是 dataElem
dataElem* d_elem;
cudaMalloc(&d_elem, N * sizeof(dataElem));
cudaMemcpy(d_elem, elem, N * sizeof(dataElem), cudaMemcpyHostToDevice);
for(int i = 0; i < N; i++){
char* d_name;
cudaMalloc(&d_name, elem[i].len);
cudaMemcpy(d_name, elem[i].name, elem[i].len, cudaMemcpyHostToDevice);
cudaMemcpy(&(d_elem[i].name), &d_name, sizeof(char*), cudaMemcpyHostToDevice);
}
kernel<<<...>>>(d_elem); // 传递给核函数的可以是结构体或者对象
}
2. 如果算法操作的数据结构是链表,和深拷贝的情况类似,使用 cudaMallocManaged 时可以规避复制,简化编程
3. C++ 对象,可以重载 new 和 delete 运算符,在重载的实现里使用统一内存,其他类继承它,用户无感
class Managed{
public:
void* operator new(size_t len){
void* ptr;
cudaMallocManaged(&ptr, len);
cudaDeviceSynchronize();
return ptr;
}
void operator delete(void* ptr){
cudaDevicesynchronize();
cudaFree(ptr);
}
};
class umString : public Managed{
int length;
char* data;
public:
// 用拷贝构造器来实现按值传递
umString(const umString& s){
length = s.length;
cudaMallocManaged(&data, length);
memcpy(data, s.data, length);
}
};
class dataElem : public Managed{
public:
int key;
umString name;
};
dataElem* data = new dataElem[N]; // new 的操作是重载的实现,但是对于用户是无感的
kernel<<<...>>>(data);
4. 假设数据结构很大且访问模式事先不能知道(比如一张很大的 graph,图遍历的时候下一个要访问的节点不能像数组那样预先知道),超过了 gpu 的显存。这时候用统一内存可以利用 oversubscription 的特性,虽然性能有所下降。
统一内存对性能有影响,有时候还很严重,需要手动调优,见下面代码:
__global__ void kernel(float* data){
int index = threadIdx.x + blockIdx.x * blockDim.x;
data[index] = va; // 这样的访问模式导致数据是用到了才会搬移
}
int n = 256 * 256;
float* data;
cudaMallocManaged(&data, n * sizeof(float));
kernel<<<256, 256>>>(data);
这段代码要比不使用统一内存(或者使用 pascal 架构之前的统一内存)的版本慢很多。究其原因,依赖于缺页中断来搬移数据的机制,当要搬移的数据量很大的时候,每页都有一定的 overhead。是不高效的。对于大数据量的搬移,高效的做法是像 memcpy 那样一整块的搬移。
利用 cudaMemPrefetchAsync(ptr, length, destDevice, stream) 可以恢复性能:
__global__ void kernel(float* data){
int index = threadIdx.x + blockIdx.x * blockDim.x;
data[index] = va; // 这样的访问模式导致数据是用到了才会搬移
}
int n = 256 * 256;
int ds = n * sizeof(float);
float* data;
cudaMallocManaged(&data, n * sizeof(float));
cudaMemPrefetchAsync(data, ds, 0); // 把数据拷到设备号是 0 号的设备上
kernel<<<256, 256>>>(data);
cudaMemPrefetchAsync(data, ds, cudaCpuDeviceId); // 把数据拷回去
这个 API 和 cudaMemcpy(Async) 非常相似,它接收一个指针,长度,和设备号这些参数。注意设备号可以是 cpu。
如果已知对数据的使用方式,还可以用 cudaMemAdvise(ptr, count, hint, device) 这个 API 来给 cudaruntime 一些提示,这边的 hint 参数可以是以下几个:
- a. cudaMemAdviseSetReadMostly:建议的大部分操作是只读。cudaruntime 会给每一个要访问它的处理器创建一个独立的副本,这样数据 overhead 只在每一个处理器第一次访问的时候才有,之后没有。当然这边只是建议,写操作还是有效的。当有处理器对这块数据进行写操作的时候,所有处理器的副本都失效,除了执行写操作的这个处理器自己的副本,所以要想获取高性能,还是得遵守它得建议,device 这个给参数被忽略。
- b. cudaMemAdviseSetPreferredLocation:建议这块数据最多被哪个处理器访问。不会自动触发数据搬移,当建议得处理器真的访问(或者 prefetch)的时候才会有数据搬移。当有其他处理器也要访问这块数据的时候,如果条件允许,会建立映射。不满足条件,则会引起数据搬移。从 Volta 架构开始,cudaruntime 可以自动统计每个处理器访问这块数据的次数,不需要程序员去建议。
- c. cudaMemAdviseSetAccessedBy:建议要访问的处理器在访问的时候通过映射而不是数据搬移的方式去访问。如果数据被搬移了,映射也会被更新。目的是为了在不引起缺页中断的情况下访问数据。
注意,cudaMemeAdvise 做的事情只是对 cudaruntime 的建议,这个 API 自己本身不会搬运数据。
总结:统一内存只是简化编程,不会提升性能,它的性能上限是普通的不使用统一内存的性能。在大多数情况下,它比写得好的手动搬运数据的代码性能更低。滥用统一内存会使得代码性能急剧下降。统一内存有助于实现在复杂数据结构上的算法,以及特定的设计模式。对于使用很多第三方库的代码,每个第三方库自己会使用一定量的 GPU 显存,但是对于其它第三方库使用的 GPU 显存量无感的情况下,统一内存的 oversubscription 机制有助于解决这个问题,而不需要重构代码,减轻移植代码时候的工作量。
6. CUDA流和并发
之前我们讨论了如何写好一个高性能的核函数,这节课我们学习核函数之间的并发,更好地利用处理器资源,提升整个系统的性能。回顾下三步走策略:1. 把数据从 cpu 上拷到 gpu 上; 2. 在 gpu 上进行计算; 3. 把结果从 gpu 上拷回到 cpu 里。我们还学到即使利用了统一内存的技术,还是得遵守这样的三步走策略,只不过 cudaruntime 帮程序员做了数据拷贝的操作。cuda 并发技术的初衷是想办法把数据搬运和计算的步骤在时间线上重叠(overlap)起来,如下图所示:

这样就能减少总体耗时,符合人们使用 GPU 的最初目的,可以成为 CUDA 优化的第三大准则。
要想实现 CUDA 并发,就需要使用 pinned memory,pinned memory 也是属于 system dram 的一部分,它可以实现异步的拷贝数据,从而实现在时间上的重叠。cudaHostAlloc/cudaFreeHost/cudaHostRegister/cudaHostUnregister 这些 API 可以对 pinned memory 的操作。pinned memory 实质上是在物理内存里分配的,没有虚拟内存的参与,不会被操作系统交换到磁盘上。逻辑上也说得通,因为 gpu 端要想访问某个地址时它没办法知道这个地址所在的页是在虚拟内存里,还是被操作系统交换到磁盘上,所以干脆不要虚拟内存那套机制。也因此,不能分配大于系统物理内存的 pinned memory(out of memory 报错)。滥用 pinned memory 会降低系统整体的性能,因为操作系统也需要一定的物理内存来干它应该干的事情。
实现 cuda 并发的另一机制是 stream。cuda 编程模型的默认行为是:核函数调用是异步的,cudaMemcpy 是同步的。如果使用默认流(legacy default stream)的话,所有对 CUDA API 的调用都是由 cuda 驱动序列化的(等前一个调用返回之后再调用后一个 CUDA API)。我们需要一个新的 API:cudaMemcpyAsync(),这个 API 需要接受一个额外的 stream 参数,而且它参数里的地址需要是属于 pinned memory 的。两个方向的并发地数据拷贝(HostToDevice,DeviceToHost)也可以通过这个 API 来实现。什么是 stream?一系列按照代码编写顺序执行的操作。来自不同 stream 的操作可以在时间上重叠,比如来自不同 stream 的核函数调用和数据拷贝操作。同一个 stream 里操作无法在时间上重叠。
stream 的语义:两个在同一个 stream 里的操作永远以代码编写的顺序执行。代码上后面的操作永远无法在前面的操作执行完毕之前就开始执行,无论它们是否靠在一起或者由其他的操作夹杂在其中。在不同 stream 里的两个操作没有执行顺序上的约定,一个在 stream1 里的操作可以在另一个 stream2 里的操作的执行之前,执行过程中,或者执行之后执行。CUDA 编程模型对于这一点没有任何规定。通常核函数,cuda api 调用(cudaMemcpyAsync),包括 stream callback(见下文),都会接受一个 stream 参数。
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaMemcpyAsync(dst, src, size, direction, stream1); // 这两个操作可以在时间上重叠,pinned memory
kernel<<<grid, block, 0, stream2>>>(...); // 注意第三个参数是动态共享内存的大小,这里给 0
// 从代码层面看,虽然核函数在数据拷贝的后面,但由于在两个 stream 里,执行顺序未知
cudaStreamQuery(stream1); // 测试 stream1 是否空闲
cudaStreamSynchronize(stream2); // 强制 cpu 线程等待所有在 stream2 里的 cuda 操作执行完毕,和 cudaDeviceSynchronize() 区分
cudaStreamDestroy(stream2);
第一张图左边黑色的是代码层面的顺序,中间橘黄色的是时间线上的执行顺序:
第二张图是一个更加具体的例子,展示了有无 stream 情况下时间线上的执行顺序(把整个要处理的输入数据拆分成和 stream 数量大小一致的分组,每个分组在一个 stream 里执行,可以实现时间上重叠,需要算法可以拆分。核函数开启的开销也可以被覆盖掉,这比序列化的操作好很多):


这个是一种”深度优先“的代码编写顺序:在一个 for 循环里做数据拷贝,kernel 计算,数据拷回三个操作。其实也可以用一个”宽度优先“的方式:一个 for 循环里只做数据拷贝,一个 for 循环里只做 kernel 计算,一个 for 循环里只做数据拷回。两种模式在性能上(并发度)没有差异,但是”深度优先“的方式会有一个问题:stream 的本质是一个队列,当输入数据非常大的时候,拷贝操作的数量会超过队列长度的上限值。
注意:
1. stream 的创建和销毁也是有成本的,但是它们通常不会被在测量性能时统计进去。比如 cudaMalloc,它当然也没有 stream 参数。
2. 在一个 stream 里执行的核函数可以访问同一设备里的任何地址,包括在其他 stream 里执行的拷贝操作的数据/被其他核函数修改的数据,这时候就有 data race 的问题,程序员需要手动做好同步。
3. 可以创建的 stream 的数量上是有上限值的,通常来说 2~3 个 stream 已经满足实际需求。>10 个 stream 说明代码没写好
4. 核函数访问一个还没有从 host 端拷到 GPU 里的数据的地址是未定义行为。cudaruntime 的 API 是线程安全的。
5. 由于核函数执行时间通常较数据拷贝要小很多,性能提升主要在于两个方向的数据拷贝操作在时间上的重叠。
6. 如果一个核函数用完了某种硬件计算单元,其他 stream 里用到同样计算单元的核函数则不会并发执行。
还有一个默认流(legacy default steam)的概念,如果开启核函数时不传 stream 参数,以及 cudaMemcpy 这个 API,它们用到的是默认流。默认流是一个全局的同步点:如果把自己创建的 stream 和默认流一起使用,那么在默认流里的操作必须等待其他 stream 里在它前面的操作执行完毕才开始执行,其他 stream 里后面的操作也必须等待默认流里操作执行完毕才开始执行,简而言之会破坏并发性。主机端的线程共享一个默认流(也可以改变这个行为,给 nvcc 传递 --default-stream per-thread 这个参数)。这个特性只在和别人合作时有用,自己从头写代码的话,在追求高度并发的场景下,应该避免使用默认流。
用 cudaLaunchHostFunc() 这个函数可以实现 “stream callback”。主机端的函数也可以在 stream 里完成,它的行为符合之前的 stream 语义。需要在 CPU 端开启新的线程,新的线程里不能调用 cuda 运行时 api/核函数调用,只能做一些常规的在 CPU 上的操作。需要 CPU 端等待 GPU 的结果出来才能继续执行的场景下有用(比如用到了 cuda 统一内存,以前只能通过调用 cudaDeviceSynchronize 来确保 gpu 的改动对 cpu 可见,高并发的场景下可以用 stream callback 来替换)。cudaStreamAddCallback 是旧的 API
对于统一内存,调用 cudaMemPrefetchAsync 而不是 cudaMemcpy 来实现数据的拷贝。流语义会保证之前提到的数据搬移(data migration)的操作会以正确的顺序执行。但是,cudaMemPrefetchAsync 做的工作要比 cudaMemcpy 多,因为需要更新 GPU 和 CPU 上的页表,相应地,耗时比平常地异步调用会更多,可能会在时间线上造成空隙。为了确保高吞吐量,DeviceToHost 需要在一个 busy 的 stream 里而 HostToDevice 需要在一个 idle 的 stream 里完成。详细讨论可以参考(Maximizing Unified Memory Performance in CUDA | NVIDIA Technical Blog)
cudaEvent 是一个放在 stream 里的标记。当代码里写下 cudaEvent 时称为被记录下,当 stream 的执行到达之前记录的点的时候称为完成。常用场景是用来测试一段核函数的耗时:
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start); // 记录一个开始的未知
kernel<<<...>>>(); // 可以是其他任何设备上的 cuda 操作
cudaEventRecord(stop); // 记录一个结束的位置
cudaEventSynchronize(stop); // 等待 stream 执行到 stop 这个标记的位置
cudaEventElapsedTime(&float_val, start, stop);
cudaEvent 和 NVTX marker 的区别:cudaEvent 主要是对 cudaruntime api 可见,而 NVTX marker 主要对 profile 可见。
也可以用 cudaStreamWaitEvent 这个函数来实现高并发场景下,可以使一个 stream 等待另一个 stream 里的 event,一定程度上打破了之前提到的 stream 语义。stream 也可以在多设备的场景下使用,见代码:
cudaSetDevice(0);
cudaStreamCreate(&stream0);
cudaSetDevice(1);
cudaStreamCreate(&stream1);
kernel1<<<b,t,0,stream1>>>(...); // kernel1 和 kernel2 可以并发执行
cudaSetDevice(0);
kernel2<<<b, t, 0, stream0>>>(...);
核心函数和 CPU 端的函数的异步行为可以轻易被见证,但是核函数之间的并发性很难被见证。需要参与并发的核函数使用相对少的资源的同时又有相对较长的执行时间。不如在一个核函数里尽可能充分利用设备的资源。可以支持的并发核函数的数量是由硬件限制的,当一个 kernel 使用了所有的 SM 里的所有 block 时,这时候 CWD(cuda work distributor)不能同时调度其他核函数的 block 进行执行。即使其他并发的条件都满足,也就是两个核函数在不同 stream 里。注意这不是硬性规定,但 cuda 通常来说都是这么做的,因为没道理在一个核函数还没干完的时候让它停下来去调度其他的核函数。
stream 之间还可以设置不同的优先级,如果两个在不同优先级 stream 里的核函数都有机会被 CWD 调度,那么 CWD 会优先调度在优先级比较高的那个 stream 里的核函数。注意这是调度时候就有的行为,而不是高优先级 kernel 抢占了低优先级 kernel 的执行。代码如下:
int priority_high, priority_low;
cudaDeviceGetStreamPriorityRange(&priority_low, $priority_high);
cudaStream_t st_high, st_low;
cudaStreamCreateWithPriority(&st_high, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_low, cudaStreamNonBlocking, priority_low);
和 stream 有关的话题是 cuda graph,这个是在 cuda 10 开始的特性。允许一个 stream 里所有操作(核函数,内存拷贝,stream 回调,甚至是其他 cuda graph)组织成图的形式。每项操作都是图里的一个节点,这样就可以自定义操作(节点)之间的依赖性。一旦创建成图,后面可以多次调用,不需要 cpu 的参与。主要是用来减少 cpu 端开启这些工作项的开销。cuda graph 可以手动建图,也可以捕获一个图。注意捕获的时候只是捕获,并没有实际地去调用这些函数。
7. Profiler驱动的优化
这节课程更偏向实战,建议大家观看视频
NVIDIA 官方关于 Nsight Compute 工具进行核函数性能优化的三篇系列博客:
-
Analysis-Driven Optimization: Preparing for Analysis with NVIDIA Nsight Compute, Part 1
-
Analysis-Driven Optimization: Analyzing and Improving Performance with NVIDIA Nsight Compute, Part 2
-
Analysis-Driven Optimization: Finishing the Analysis with NVIDIA Nsight Compute, Part 3