Go 知识for-range
Go 知识for-range
- 1. for-range 的用法
-
- 1.1 数组
- 1.2 切片
- 1.3 字符串
- 1.4 map
- 1.5 chan
- 2. 原理
-
- 2.1 数组
- 2.2 切片
- 2.3 字符串
- 2.4 map
- 2.5 chan
- 3. 总结
https://a18792721831.github.io/
1. for-range 的用法
for-range 表达式用于遍历集合元素,比传统的for更加简单直观。
for-range 的表达式一般格式:
for index, value := range data {
//....
}
for-range 一般可以返回两个值,对于不同类型的data有不同的返回值。
对于数组,返回下标和值。
对于切片,返回下标和值。
对于string,返回下标和值。
对于map,返回key和value。
对于chan,返回值,只会返回一个元素。
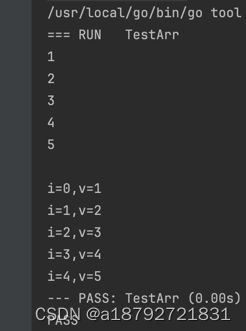
1.1 数组
arr := [5]int{1, 2, 3, 4, 5}
for i := range arr {
fmt.Println(arr[i])
}
fmt.Println()
for i, v := range arr {
fmt.Printf("i=%d,v=%d\n", i, v)
}
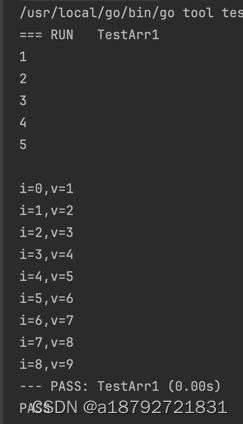
1.2 切片
arr := []int{1, 2, 3, 4, 5}
for i := range arr {
fmt.Println(arr[i])
}
fmt.Println()
arr = append(arr, 6, 7, 8, 9)
for i, v := range arr {
fmt.Printf("i=%d,v=%d\n", i, v)
}
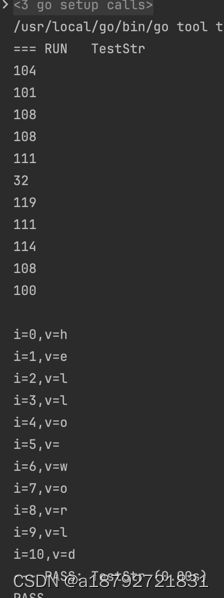
1.3 字符串
str := "hello world"
for i := range str {
fmt.Println(str[i])
}
fmt.Println()
for i, v := range str {
fmt.Printf("i=%d,v=%c\n", i, v)
}
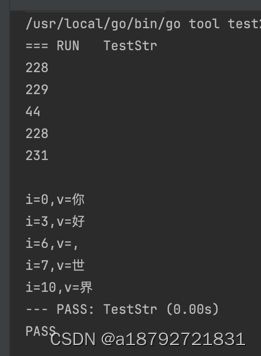
需要注意的是,对于中英文,因为编码的方式不同,每个字符的占用空间不同,就会出现下标不连续的问题。
str := "你好,世界"
for i := range str {
fmt.Println(str[i])
}
fmt.Println()
for i, v := range str {
fmt.Printf("i=%d,v=%c\n", i, v)
}
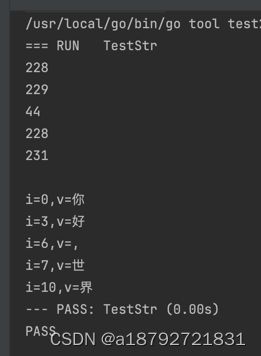
1.4 map
str := map[string]int{
"one": 1,
"two": 2,
"three": 3,
"four": 4,
"five": 5,
}
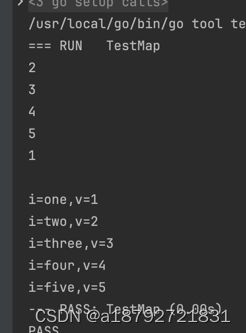
for i := range str {
fmt.Println(str[i])
}
fmt.Println()
for k, v := range str {
fmt.Printf("i=%s,v=%d\n", k, v)
}
1.5 chan
ch := make(chan string, 10)
ch <- "h"
ch <- "e"
ch <- "l"
ch <- "l"
ch <- "o"
for i := range ch {
fmt.Println(i)
}
//fmt.Println()
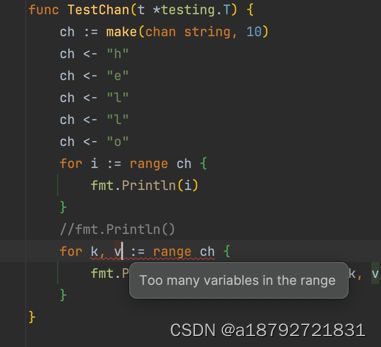
//for k, v := range ch {
// fmt.Printf("i=%s,v=%d\n", k, v)
//}
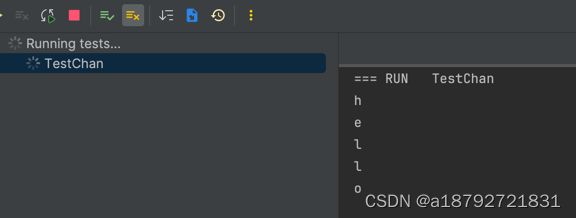
因为chan里面没有数据了,所以就阻塞了,并不会自动结束哦。
当你视图用两个变量接收返回值的时候,就会编译失败
2. 原理
for-range是在编译的时候,转换为传统的for语句。
需要注意,下面都是伪代码,使用常见的语法规则进行描述。
因为在for-range中使用了 := 短定义并赋值的方式,所以使用for-range的时候,第二个值会进行变量拷贝,对于大数据的for-range,可能会导致性能变差。
2.1 数组
len_temp := len(arr)
data := arr
for index_temp = 0; index_temp < len_temp; index_temp++ {
value_temp = data[index_temp]
index = index_temp
value = value_temp
// 执行 for-range 里面的代码
// .....
}
需要注意的一个,在数组中,len和cap是两个值,如果len=5,cap=10,在遍历过程中,对于第6个元素进行赋值,那么是无法遍历到的。因为在遍历开始的时候,就已经使用len获取到了遍历范围了。
2.2 切片
len_temp := len(sli)
data := sli
for index_temp = 0; index_temp < len_temp; index_temp++ {
value_temp = data[index_temp]
index = index_temp
value = value_temp
// 执行 for-range 里面的代码
// .....
}
切片与数组基本上相同。
2.3 字符串
len_temp := len(str)
var next_index_temp int
for index_temp = 0; index_temp < len_temp; index_temp = nex_index_temp {
value_temp = rune(str[index_temp])
if value_temp < utf8.RuneSize {
next_index_temp = index_temp + 1
} else {
value_temp, next_index_temp = decoderune(str, index_temp)
}
index = index_temp
value = value_temp
// 执行 for-range 里面的代码
// .....
}
因为不同的字符集,占用的长度不同,所以这里会对是否是utf8字符集字符进行判断,并进行不同的处理。
比如:
2.4 map
var temp *map
init_map(type, data, &temp)
for ; temp != nil; temp = iter_next() {
index_temp = *temp.key
value_temp = *temp.value
index = index_temp
value = value_temp
// 执行 for-range 里面的代码
// .....
}
map的遍历是无序的,同时不会指定次数,但是同样需要避免在遍历过程中,操作map。
2.5 chan
for {
index_temp, ok = <- ch
if !ok {
break
}
index = index_temp
// 执行 for-range 里面的代码
// .....
}
可以看到遍历chan,最终依然是使用操作符<-读取数据的,但是会对第二个值进行判断,所以可以保证for-range返回的值都是成功读取的值,当没有数据读取的时候,依然会因为操作符<-阻塞。
3. 总结
总的来说,for-range和java里面的for-each是类似的,原理都可以理解为语法糖,在编译的时候再进行替换。