【无标题】

论文:chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://arxiv.org/pdf/2401.11631.pdf
我们从跨模态生成的角度回顾了从文本生成视觉数据的研究。这种观点让我们能够在不将分析局限于狭窄的子领域的情况下,对各种旨在处理输入文本并产生视觉输出的方法进行比较。这也导致了在该领域内识别出共同的模板,这些模板随后在类似方法池中以及跨越研究线索进行了比较和对比。我们将文本到图像的生成分解为各种形式的从文本到图像的方法、从文本到视频的方法、图像编辑、自监督学习和基于图的方法。在这次讨论中,我们关注的是2016-2022年间在8个领先的机器学习会议上发表的研究论文,同时也包括了一些不符合概述搜索标准的相关论文。进行的综述表明该领域发表的论文数量显著增加,并强调了研究空白和潜在的研究方向。据我们所知,这是第一次从跨模态生成的视角系统性地审视文本到图像的生成。
1 引言
自2012年ImageNet大规模视觉识别挑战(ILSVRC)以来,当AlexNet [70] 显著超越了所有先前方法后,深度学习成为了图像分类的事实标准,因为它能够比其他方法实现显著更高的准确度。卷积神经网络(CNNs)已成为视觉领域进步的主要动力,首先是使用反向传播 [74] 的基本形式,随后引入了残差连接 [46]。这被自然语言处理(NLP)领域的进步所仿效,后者依赖于循环神经网络(RNNs),其中长短期记忆(LSTM)[53] 架构成为一种特别成功的方法。随后,注意力机制 [7] 的设计导致了基于注意力的架构,如Transformer [148],以及针对Transformers的预训练(BERT)[29]。Transformer架构的进步已进入视觉领域,表现在Vision Transformer(ViT)[33]的设计上。
CNN/ViT在视觉领域和RNN在NLP领域的方法共同依赖于分类任务。这在视觉领域更为明显,其中手头的问题通常本身就是分类任务。NLP架构可能以更隐性的方式使用分类,例如在机器翻译中,问题形式可允许多步骤分类作为可行的任务形式。
然而,必须指出,基于分类的问题并不是深度学习取得显著进步的唯一领域。新技术成功引入的一个广泛研究领域是生成模型领域。使用编码器/解码器架构 [1] 的想法为生成建模找到了新的相关性,随着变分自编码器(VAEs)[67] 和生成对抗网络(GANs)[42] 的出现,以及后来的扩散模型 [134]。这些模型最初有限的能力被扩展,例如通过引入稳定GAN训练的措施,形成了DCGAN模型 [113]。随后进行了更多扩展基本方法的工作。对于VAEs的显著例子包括量化的VAE(VQ-VAE)[147] 及其第二代 [117]。对于GANs,通过像StackGAN [168] 及其扩展 [169] 这样的模型进行了改进。在扩散方面,通过去噪扩散概率模型(DDPMs)[50],[104],[30] 的出现取得了进展。
聚焦于VAEs、GANs和扩散,所有这些方法都依赖于随机输入作为数据生成过程的种子。这种随机性是生成样本多样性的来源。也已经实验性地显示,输入可能还携带了关于生成样本的某种语义信息。对于视觉而言,这可能意味着输入到系统中的随机数据决定了在生成图像中可见的选定特征 [113],而这些特征可能与人类对描述性属性的理解相关联。
这不仅适用于随机输入,还适用于提供给架构的特定定制信息。原则上,VAEs、GANs和扩散模型并不严格要求所有输入数据都是随机的,因此可以向模型展示额外信息。在这种情况下,生成过程取决于输入数据,架构可以被认为是条件生成模型。条件信息的确切形式可能有所不同。在相对简单的设置中,它可能是我们希望生成的实例所属类的标签。然而,情况可能并不那么简单。
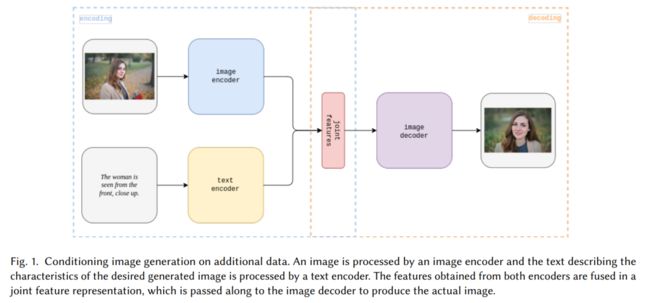
如果我们考虑条件信息编码了所需生成图像的一部分特征,那么就有可能使用由单独训练的模型或联合训练架构的上游部分提取的实际特征。一个相关的例子可能是使用CNN或ViT特征提取器(图像编码器)处理输入图像,并得到这个图像的特征表示。然后,这个表示可以输入到基于VAE、GAN或扩散的模型中。原则上,这个过程可以针对多个数据源重复进行,无论是否包括随机数据。一个具体的例子可能涉及图像编辑任务,其中输入图像由CNN/ViT图像编码器处理,所需最终图像的文本描述由RNN文本编码器处理。然后将这些表示融合为一个,传递给转置卷积(TCNN)[35] 图像解码器、Transformer图像解码器 [148],可能以自回归方式 [146],或扩散图像解码器 [134] 来生成与输入图像特征相符但符合提供描述的图像。这一过程的概述可见于图1。
这个例子展示了条件数据生成的一个重要原则。即,没有明确的假设条件数据来自于与输出数据相同的分布,或实际上是相同的模态。所需图像的描述来自文本模态,而生成的输出来自图像模态。因此,有可能根据另一模态的输入生成一个模态的数据。这个一般过程可以被描述为跨模态生成。可以考虑各种可能的跨模态设置,其中包含一个或多个输入模态,类似地,一个或多个输出模态,每个输入和输出模态都可能不同。例如,可以根据图像生成音频,或相反地,根据音频输入生成图像。
在众多可能的模态中,文本和视觉模态是显著研究努力的对象。这部分可以归因于图像和文本模态都已经分别在视觉和NLP领域进行了相对密集的研究。此外,文本或语言领域由于大多数语言问题依赖于有限的词汇量,从而允许使用多步骤分类方法处理文本,因此具有固有的结构。例如,从输入图像生成文本描述,即图像字幕,可能使用多步骤分类程序来选择字幕中的后续词语。这里的一个重要点是,在这种设置中,图像编码器和文本解码器可以像在视觉和NLP中一样使用,无需显著修改,这使得将这些方法移植到生成设置中变得更容易。由于上述原因,图像字幕,作为图像到文本生成的子领域 [166],可能是跨模态文本和视觉生成中探索最多的领域。
另一方面,从文本领域到视觉领域(例如图像、视频等)在研究产出方面受到的关注明显较少。这背后的一个重要原因可以追溯到数据的固有结构。虽然文本到图像生成可能在输入端获得类似于图像到文本问题的好处,其中可以利用文本的结构化特性,但在输出端的情况完全不同,那里涉及图像。与文本描述不同,图像没有有限的词汇量,至少在传统意义上是这样的,因此,潜在图像的空间显著大于文本生成问题。这是因为对于给定大小的图像,原始像素输出可以在图像的每个点上设置,从而导致可能组合的数量爆炸性增长,问题的维度非常高。如果我们考虑所有有效图像的空间,其中有效图像我们理解为按照某种相似度度量看起来像数据集中的实际图像,那么随机生成有效图像的可能性可能比随机生成有效句子(对于图像字幕问题)要小得多。因此,虽然使用非随机方法生成有效图像高度依赖于方法,但可能仍然比基于图像生成有效句子要求更高。所有这些使得这个问题对多步骤分类方法的适应性大大降低。这些困难导致文本到图像生成的研究领域相对于图像到文本问题明显被低估。尽管研究产出有限,但最近在这个领域取得了显著进展。
图像到文本和文本到图像的问题已经得到了显著的扩展,都处于跨模态生成研究的前沿。它们还吸纳了深度学习其他领域的研究线索。
在这项工作中,我们特别关注文本到图像问题及其派生任务。随着对这一领域的兴趣和研究成果不断增加,有必要对各种研究方向进行全面的回顾。据我们所知,现有的文本到图像生成研究缺乏这样的回顾,这也是本工作的主要贡献所在。我们的目标是建立文本到图像生成内部各个领域以及与深度学习其他领域的联系,将分散的研究线索汇聚起来。我们的意图是从跨模态生成的全局视角统一讨论。
本次回顾的起点是发表在8个机器学习会议上的研究论文:
• 神经信息处理系统会议(NeurIPS)
• 国际机器学习会议(ICML)
• 国际学习表示会议(ICLR)
• AAAI人工智能会议(AAAI)
• 国际人工智能联合大会(IJCAI)
• 计算机视觉国际会议(ICCV)
• 欧洲计算机视觉大会(ECCV)
• 计算机视觉与模式识别会议(CVPR)。
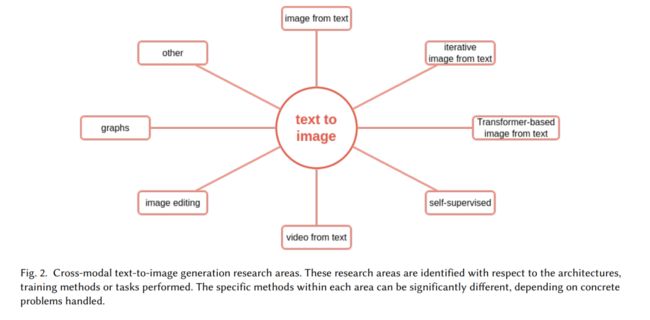
更具体地说,我们考虑了2016年至2022年的时间段内发表的论文 - 在撰写时刻的最新出版年份。我们已经在会议论文集中搜索了以下术语:跨模态,多模态,生成和扩散。根据符合这些标准的论文,我们选择了那些实际涵盖文本到图像生成的论文。我们还添加了一些不符合概述搜索标准但仍然与文本到图像生成相关的论文,特别是关于文本到图像扩散模型的工作。我们努力提供对跨模态文本到图像生成的全面回顾,重点关注各种方法的共同要素以及它们的独特特性。涵盖的主题概述如图2所示。
本次回顾的流程结构如下。在第2节中,描述了文本到图像生成问题,详细讨论了与此任务相关的子领域。特别是,第2.1节涵盖了从文本生成图像,第2.2节讨论了标准方法的迭代扩展,第2.3节聚焦于基于Transformer的变种,第2.4节描述了自监督方法,第2.5节强调了从文本输入生成视频的可能性,第2.6节处理了根据描述编辑图像的任务,第2.7节考虑了图方法,而第2.8节回顾了剩余的特殊方法。在第3节中,讨论了未来研究的潜在方向。第4节总结。
