sql优化的方法
目录
一、准备数据
1.1、创建表结构
1.2、创建存储过程
二、索引介绍
2.1、类型介绍
2.2、建立索引
2.3、建立复合索引
2.4、查看所有建立的索引
2.5、删除索引
三、EXPLAIN分析参数说明
四、SQL优化案例
4.1、避免使用SELECT *
4.2、慎用UNION关键字
4.4、避免使用or条件(有争议)
4.5、LIKE语句优化
4.6、字符串字段优化
4.7、最左匹配原则(重要)
4.8、COUNT查询数据是否存在优化
4.9、LIMIT关键字优化
4.10、提升GROUP BY的效率
4.11、避免使用!=或<>
4.12、避免NULL值判断
4.13、避免函数运算
4.14、JOIN的表中使用索引字段
4.15、用EXISTS代替IN
一、准备数据
提前准备一张学生表数据和一张特殊学生表数据,用于后面的测试用。
1.1、创建表结构
创建一个学生表:
CREATE TABLE student (
id int(11) unsigned NOT NULL AUTO_INCREMENT,
name varchar(50) DEFAULT NULL,
age tinyint(4) DEFAULT NULL,
id_card varchar(20) DEFAULT NULL,
sex tinyint(1) DEFAULT '0',
address varchar(100) DEFAULT NULL,
phone varchar(20) DEFAULT NULL,
create_time timestamp NULL DEFAULT CURRENT_TIMESTAMP,
remark varchar(200) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;再创建一个特殊学生表:
CREATE TABLE special_student (
id int(11) unsigned NOT NULL AUTO_INCREMENT,
stu_id int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;1.2、创建存储过程
在学生表中插入100w条数据,手动开启和提交事务,每插入1w条记录后,手动COMMIT一次事务,最后再COMMIT一次以提交剩下的记录,这样可以让插入速度更快,因为不需要为每条记录都 COMMIT,从而降低 IO 次数。
CREATE PROCEDURE insert_student_data()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE done INT DEFAULT 0;
DECLARE continue HANDLER FOR NOT FOUND SET done = 1;
START TRANSACTION;
WHILE i < 1000000 DO
INSERT INTO student(name,age,id_card,sex,address,phone,remark)
VALUES(CONCAT('姓名_',i), FLOOR(RAND()*100),
FLOOR(RAND()*10000000000),FLOOR(RAND()*2),
CONCAT('地址_',i), CONCAT('12937742',i),
CONCAT('备注_',i));
SET i = i + 1;
IF MOD(i,10000) = 0 THEN
COMMIT;
START TRANSACTION;
END IF;
END WHILE;
COMMIT;
END执行特殊学生表的存储过程:
CALL insert_special_student();二、索引介绍
2.1、类型介绍
普通索引 最基本的索引,没有任何限制
唯一索引 与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
主索引 即主键索引,关键字PRIMARY
复合索引 为了更多的提高MySQL效率可建立组合索引,遵循“最左前缀”原则
全文索引 可用于MyISAM表,MySQL5.6之后也可用于innodb表,用于在一篇文章中,检索文本信息的, 针对较大的数据,生成全文索引很耗时和空间
2.2、建立索引
CREATE INDEX id_card_index ON student(id_card);2.3、建立复合索引
CREATE INDEX name_address_phone_index ON student(name,address,phone);2.4、查看所有建立的索引
SHOW INDEX FROM student;
2.5、删除索引
ALTER TABLE 表名 DROP INDEX 索引名称;三、EXPLAIN分析参数说明
1、id:SELECT语句的编号。可以通过id来区别多条SELECT语句。
2、select_type:SELECT类型,主要有SIMPLE、PRIMARY、DERIVED等类型。
SIMPLE:简单的SELECT(不含子查询及UNION)。
PRIMARY:查询中最外层的SELECT。
DERIVED:包含的子查询中的SELECT。
3、table:显示这一行的数据是关于哪张表的。
4、partitions:匹配的分区信息。
5、type:显示连接使用了何种类型。
最好到最差的连接类型为 system > const > eq_reg > ref > range > index > ALL.
| system |
表只有一行记录(等于系统表) |
| const | 使用常量进行索引查询 |
| eq_ref | 唯一索引扫描,通常使用主键约束 |
| ref | 非唯一性索引扫描 |
| range | 索引范围扫描 |
| index | 全索引扫描 |
| ALL | 全表扫描 |
6、possible_keys:显示可能应用在这张表中的索引。
7、key:实际使用的索引。
8、key_len:使用的索引的长度。
9、ref:显示索引的哪一列被使用。
10、rows:根据表统计信息及索引条件估算,查询返回的且接近的行数
11、filtered:显示了通过条件过滤出的行数的百分比估计值。
12、Extra:包含不适合在其他列展示但是需要展示的信息。
四、SQL优化案例
4.1、避免使用SELECT *
有的时候,我们为了图方便,会直接使用SELECT * 一次性查出表中所有的数据:
SELECT * FROM student执行结果如图所示:
可以看到,执行时间花了2s左右,耗时很长!
在实际开发中,我们给页面展示的数据可能就只要2-3个字段,如果直接全部查出来了,岂不是白白浪费了字段,同时也损耗了性能,这是因为SELECT * 不会走覆盖索引,会出现大量的回表操作,从而导致SQL性能大幅度降低。
我们上面建立了联合索引,我们就可以只查询索引列,这样会大幅度提升查询效率,优化的SQL如下:
SELECT name,address,phone FROM student执行结果如图所示:
这样执行的速度大大提高!
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT name,address,phone FROM student执行结果如图所示:

确实走了我们建立的复合索引。
4.2、慎用UNION关键字
例如我们根据性别去查询所有学生的信息,虽然这种操作多此一举,直接SELECT *就好了,为了演示这2个关键字的详细区别,使用UNION关键字执行的SQL如下:
SELECT * FROM student WHERE sex = 0
UNION
SELECT * FROM student WHERE sex = 1执行结果如图所示:
我滴妈,查了100w条足足整整等了32s左右,这个速度要是放到系统上,查个数据等到娃娃菜都凉了!
这是因为在使用UNION执行完SQL后,会帮我们获取所有数据并去掉重复的数据,性能的损耗就在这里,而UNION ALL和UNION相反,帮我们获取所有数据但会保留重复的数据。
我们改用UNION ALL关键字,优化的SQL如下:
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE sex = 1执行结果如图所示:
同样查询100w条数据,这边执行速度大大提高了,只用到了3s左右!
4.3、小表驱动大表
言简意赅,意思就是让小表查出来的数据去再查询大表当中的数据。比如我们想查询学生表当中特殊学生的信息,我们就可以使用以special_student这个小表去驱动student这个大表,SQL如下:
SELECT * FROM student WHERE id
IN (SELECT stu_id FROM special_student)执行结果如图所示:

只用了0.02s,速度很可观!因为IN关键字中的子查询语句,子查询语句的数据量很少,所以查询速度会很快!
4.4、避免使用or条件(有争议)
如果我们要查询指定的性别或者指定的身份证号码的学生,执行SQL如下:
SELECT * FROM student WHERE sex = 0 OR id_card = '7121877527789'
执行结果如图所示:

总共查询了近50w条数据,耗时1.4s左右,我们改用UNION ALL关键字查询:
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE id_card = '7121877527789'执行结果如图所示:
和上面查询的数据量一样,好事在1.7s左右,怎么会没什么区别呢?
分析SQL:
使用EXPLAIN关键字分析一下使用OR关键字的这段SQL:
EXPLAIN SELECT * FROM student WHERE SEX = 0 OR id_card = '7121877527789'执行结果如图所示:

很明显,虽然可能会用到建立id_card的索引,正因为sex这个字段没有建立索引,还是走了一次全表扫描。
使用EXPLAIN关键字执行这段SQL:
EXPLAIN
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE id_card = '7121877527789'执行结果如图所示:

很明显条件是sex的走了全表,但是id_card走了索引,所以依旧还是走了一次全表扫描,所以网上说的关于UNION ALL代替OR的,我这边实测感觉还是存在争议的!
4.5、LIKE语句优化
平时我们日常开发用到的LIKE关键字进行模糊匹配会非常多,但是有的情况会使索引失效,导致查询效率变慢,例如:
只要身份证字段包含50就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '%50%'执行结果如图所示:
用了0.8s左右。
只要身份证号码以50结尾就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '%50'执行结果如图所示:

用了0.4s左右。
只要身份证号码以50开头的就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '50%'执行结果如图所示:

这次执行非常快,0.08s左右。
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '%50%'执行结果如图所示:

很明显走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '%50'执行结果如图所示:
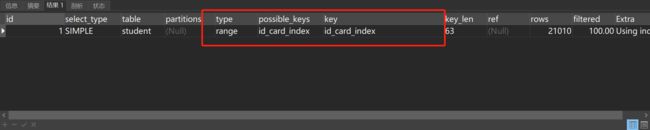
这次便走了索引!
4.6、字符串字段优化
查询指定的身份证号码的学生,如果我们平时疏忽了给身份证号码加上单引号,执行SQL如下:
SELECT * FROM student WHERE id_card = 5040198345执行结果如图所示:

耗时0.4s左右。
给身份证号码加上单引号,优化的SQL如下:
SELECT * FROM student WHERE id_card = '5040198345'执行结果如图所示:

耗时0.02s左右,这次明显快多了!
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card = 5040198345执行结果如图所示:
可能用到了id_card的索引,但是还是走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card = '5040198345'
执行结果如图所示:
这边走了索引。
这边走了索引。
4.7、最左匹配原则(重要)
上面我们按照name,address和phone这个顺序建立了复合索引,相当于建立了(name),(name、address)和(name、address、phone)三个索引,如果我们查询的where条件违背了建立的顺序,则复合索引就失效了,下面直接进行SQL分析:
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE name = '姓名_4' and phone = '7121877527' and address = '地址_4'执行结果如图:
为什么明明违背了最左匹配原则,依旧还是走了复合索引呢?可能是如下原因:

1、通过索引过滤性能足够好,所以还是选择利用索引。
2、联合索引中前几个字段过滤效果较好,所以仍然选择利用索引。
可能的执行计划大概是:
1、优先通过phone字段过滤,将要扫描的记录减少一部分。
2、然后通过address字段继续过滤,再减少一部分记录。
3、最后通过name字段过滤,已经剩下很少的记录需要扫描。
4、尽管违反了最左匹配,解释器可能认为仍然利用索引效率比较高。
所以总的来说,就是解释器会根据实际情况进行权衡,即使是违反最左匹配原则,也可能会选择利用索引。但这并不是一个良好的查询优化,最好还是严格遵守最左匹配原则。
以下是严格遵守最左匹配原则的SQL:
SELECT * FROM student WHERE name = '姓名_4'
SELECT * FROM student WHERE name = '姓名_4' and address = '地址_4'
SELECT * FROM student WHERE name = '姓名_4' and address = '地址_4' and phone = '7121877527' 4.8、COUNT查询数据是否存在优化
比如我想判断年龄为18岁的学生是否存在,我们往往会执行如下SQL:
SELECT COUNT(*) FROM student WHERE age = 18执行结果如图所示:
耗时0.4s左右,虽然知道学生年龄18岁存在,但是没必要查询出这么多数量出来,我们只要知道是否存在即可!
不再使用COUNT,而是改用LIMIT 1,让数据库查询时遇到一条就返回,这样就不要再继续查找还有多少条了,优化的SQL如下:
SELECT 1 FROM student WHERE age = 18 LIMIT 1执行结果如图所示:

耗时0.01s左右,很快就知道了。
4.9、LIMIT关键字优化
平日开发工作中,我们对于分页的处理一般是这样的:
SELECT * FROM student LIMIT 999910,10执行结果如图所示:
耗时0.56s,但是因为我们的ID属于自增长,所以我们可以在此基础上进行一定的优化,优化的SQL如下:
SELECT * FROM student WHERE ID >= 999910 LIMIT 10执行结果如图所示:

仅仅用时0.02s,非常快!
4.10、提升GROUP BY的效率
我们平日写SQL需要多多少少会使用GROUP BY关键字,它主要的功能是去重和分组。 通常它会跟HAVING一起配合使用,表示分组后再根据一定的条件过滤数据,常规执行的SQL如下:
SELECT age,COUNT(1) FROM student GROUP BY age HAVING age > 18执行结果如图所示:
耗时总计0.53s左右,不过还可以进行优化,我们可以在分组之前缩小筛选的范围,然后再进行分组,优化的SQL如下:
SELECT age,COUNT(1) FROM student where age > 18 GROUP BY age
执行结果如图所示:
耗时0.51s左右,虽然不明显,也是一种不错的思路。
4.11、避免使用!=或<>
尽量避免使用!=或<>操作符,下面直接分析SQL:
SQL分析:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card != '5031520645'执行结果如图所示:

虽然我们给了id_card字段建立了索引,但还是走了全表扫描
4.12、避免NULL值判断
为了确保没有NULL值,我们可以设定一个默认值,下面直接分析SQL:
SQL分析:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card IS NOT NULL执行结果如图所示:

依旧还是走了全表扫描。
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card IS NULL执行结果如图所示:

这样是走索引的!
4.13、避免函数运算
在日常SQL撰写中,在WHERE条件上多多少少会用到一些函数,例如截取字符串,执行SQL如下:
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE SUBSTR(id_card,0,9)执行结果如图所示:

索引失效,走了全表扫描。
4.14、JOIN的表中使用索引字段
如果日常开发中,使用JOIN关键字链接表后,使用的ON关键字进行条件链接时,如果条件没有索引,则会进行全表扫描,执行SQL如下:
EXPLAIN SELECT * FROM student a,special_student b WHERE a.id = b.stu_id执行结果如图所示:

正因为special_student表的stu_id没有建立索引,则导致了全表扫描!
为stu_id建立索引后,执行SQL如下:
CREATE INDEX stu_id_index ON special_student(stu_id);
EXPLAIN SELECT * FROM student a,special_student b WHERE a.id = b.stu_id执行结果如图所示:

两张表都走了索引。
4.15、用EXISTS代替IN
IN关键字适合于外表大而内表小的情况,EXISTS适合于外表小而内表大的情
SELECT * FROM special_student
WHERE EXISTS
( SELECT 1 FROM student WHERE special_student.stu_id = student.id)况,执行SQL如下:
运行结果如图所示:

执行效率在0.02s左右,这里special_student是小表,student是大表,速度非常快!