LLM(1): Exa,基于 LLM 的搜索
LLM(1): Exa,基于 LLM 的搜索
1. Exa 是什么
Exa 指的是网站 https://exa.ai, 是一个基于 LLM 的搜索网站:

exa 以前叫 Metaphor:

results = exa.search('hottest AI agent startups', use_autoprompt=True)
print(results)
输出内容:
Title: AgentOps
URL: https://www.agentops.ai/
ID: tz-F56tReaJJZ9g13dB3eA
Score: 0.18857020139694214
Published Date: 2000-01-01
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: HiOperator | Generative AI-Enhanced Customer Service
URL: https://www.hioperator.com/
ID: MIXJhTDGLrn9VmqKh6UOTA
Score: 0.1851872056722641
Published Date: 2000-01-01
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: imbue
URL: https://imbue.com/
ID: kOYHjR-2wEIOZc9Nv4bUHQ
Score: 0.18357500433921814
Published Date: 2023-09-07
Author: None
Text: None
Highlights: None
Highlight Scores: None
...
Exa API 的进一步使用
Exa 希望用户以搜索 API 的方式使用它, 因此围绕搜索功能, 提供了细分的功能:
(https://docs.exa.ai/reference/cheat-sheet)
from exa_py import Exa
# 初始化 Exa 客户端
# instantiate the Exa client
exa = Exa("YOUR API KEY")
# 基本的查询:只输入搜索关键字
# basic search
results = exa.search("This is a Exa query:")
# 稍微高级一点: 设置 use_autoprompt 为 True, 意思是输入查询的文本不用非得是 prompt 文本, Exa API 会自动帮你转为 prompt 文本
# autoprompted search
results = exa.search("autopromptable query", use_autoprompt=True)
# 带有时间过滤的查询
# search with date filters
results = exa.search("This is a Exa query:", start_published_date="2019-01-01", end_published_date="2019-01-31")
# 带有指定网站范围的查询
# search with domain filters
results = exa.search("This is a Exa query:", include_domains=["www.cnn.com", "www.nytimes.com"])
# 搜索bing获取文本内容
# search and get text contents
results = exa.search_and_contents("This is a Exa query:")
# 搜索并且高亮结果
# search and get highlights
results = exa.search_and_contents("This is a Exa query:", highlights=True)
# 搜索,并且给出如何加工搜索结果,例如:包含html的tag,1000字以内
# search and get contents with contents options
results = exa.search_and_contents("This is a Exa query:",
text={"include_html_tags": True, "max_characters": 1000},
highlights={"highlights_per_url": 2, "num_sentences": 1, "query": "This is the highlight query:"})
# 查询相似的文档
# find similar documents
results = exa.find_similar("https://example.com")
# 查找相似的内容
# find similar excluding source domain
results = exa.find_similar("https://example.com", exclude_source_domain=True)
# 根据内容查询相似的
# find similar with contents
results = exa.find_similar_and_contents("https://example.com", text=True, highlights=True)
# 获取文本
# get text contents
results = exa.get_contents(["ids"])
# 获取高亮
# get highlights
results = exa.get_contents(["ids"], highlights=True)
# get contents with contents options
results = exa.get_contents(["ids"],
text={"include_html_tags": True, "max_characters": 1000},
highlights={"highlights_per_url": 2, "num_sentences": 1, "query": "This is the highlight query:"})
Exa 的检索范围
Exa 专门建立了索引, 每个被索引的“方向”/“关键词”, 预期是能得到还不错的搜索结果:
类别1: 公司
比如输入 “Here is the homepage of a company working on making space travel cheaper:”
from exa_py import Exa
import os
MY_EXA_API = os.environ["MY_EXA_API"]
exa = Exa(MY_EXA_API)
q = "Here is the homepage of a company working on making space travel cheaper:"
result = exa.search(q, use_autoprompt=True)
print(result)
Title: Venus Aerospace :: A New Approach to Hypersonic Transportation
URL: https://www.venusaero.com/
ID: aU6USG9MOjAjE-__6sKoWw
Score: 0.18922962248325348
Published Date: 2020-09-29
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: Manufacturing in Microgravity
URL: https://varda.com/
ID: EurzS7kqWK4C1rPz3yFFOQ
Score: 0.18556879460811615
Published Date: 2022-05-20
Author: None
Text: None
Highlights: None
Highlight Scores: None
类别2: Research papers
from exa_py import Exa
import os
MY_EXA_API = os.environ["MY_EXA_API"]
exa = Exa(MY_EXA_API)
q = "If you're looking for the most helpful academic paper on \"embeddings for document retrieval\", check this out (pdf:"
result = exa.search(q, use_autoprompt=True)
print(result)
结果:
Title: Structure with Semantics: Exploiting Document Relations for Retrieval
URL: https://arxiv.org/pdf/2201.03720v2.pdf
ID: t5QlAL4osVjsgk0lWpiLVw
Score: 0.1772574484348297
Published Date: None
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: Dense Passage Retrieval for Open-Domain Question Answering
URL: https://arxiv.org/pdf/2004.04906.pdf
ID: k6cwFCTzELLqYSt-cbnXow
Score: 0.17709843814373016
Published Date: None
Author: None
Text: None
Highlights: None
Highlight Scores: None
类别3: Github repos
比如搜索如何用 pnnx 转换 pytorch 模型到 ncnn
from exa_py import Exa
import os
MY_EXA_API = os.environ["MY_EXA_API"]
exa = Exa(MY_EXA_API)
q = "Here's a Github repo if you want to convert pytorch to ncnn by using pnnx"
result = exa.search(q, use_autoprompt=True)
print(result)
Title: GitHub - pnnx/pnnx: PyTorch Neural Network eXchange
URL: https://github.com/pnnx/pnnx
ID: ClKdd0rQsP3TOCqrGvaVdA
Score: 0.2674873471260071
Published Date: 2023-02-17
Author: Pnnx
Text: None
Highlights: None
Highlight Scores: None
Title: GitHub - kouxichao/pytorch2ncnn: pytorch_converter
URL: https://github.com/kouxichao/pytorch2ncnn
ID: rOd-b0MCXckVuvCxKLwstQ
Score: 0.25793394446372986
Published Date: 2023-01-01
Author: Kouxichao
Text: None
Highlights: None
Highlight Scores: None
类别4: 个人主页
结果不太行,和宣传的相差较大
类别5: News 新闻
类别6: 维基百科
类别7: Events
Events 意思是活动, 其实和 News 新闻有点像, 个人感觉传统的搜索引擎不体会记录 Event。
类别8: 博客
个人觉得博客 和 个人主页 没必要分开。博客的结果好挺多的。
比如我直接在 exa.ai 搜 “If you’re a huge fan of opencv, checkout these blogs”
竟然找到了年头特别久的一篇: https://opencv.blogspot.com/ , 标题是 “I Hate (Love) OpenCV”
类别9: Jobs 找工作
其实 Exa 已经支持中文了。我输入的是:
如果你在寻找一份在创业公司做基于LLM的健身产品的研发的工作,请点击这里
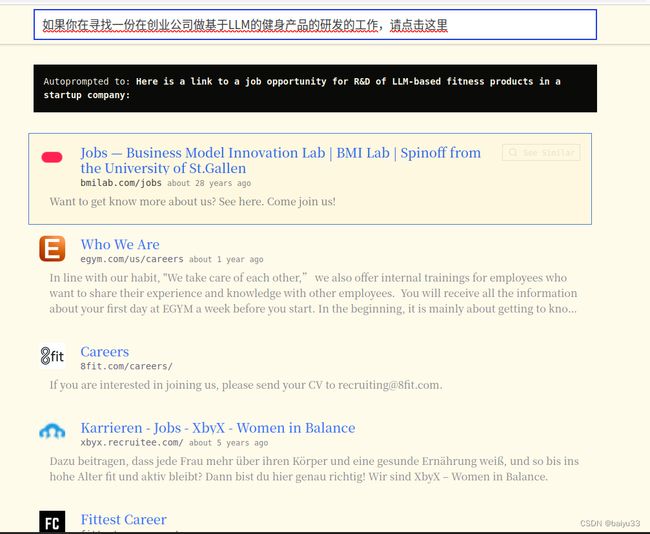
试试通过 API 调用:
from exa_py import Exa
import os
MY_EXA_API = os.environ["MY_EXA_API"]
exa = Exa(MY_EXA_API)
q = "如果你在寻找一份在创业公司做基于LLM的健身产品的研发的工作,请点击这里"
result = exa.search(q, use_autoprompt=True)
print(result)
Title: Jobs — Business Model Innovation Lab | BMI Lab | Spinoff from the University of St.Gallen
URL: https://bmilab.com/jobs
ID: DwraeSmD6ibOwaLbEIP6RQ
Score: 0.1805850863456726
Published Date: 1996-01-01
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: Who We Are
URL: https://egym.com/us/careers
ID: NqYMN7Cnv-Lt68z1jOEsBQ
Score: 0.17937926948070526
Published Date: 2023-01-01
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: Careers
URL: https://8fit.com/careers/
ID: vWS1mya-1-fzkAtjhjMRpQ
Score: 0.17652249336242676
Published Date: None
Author: None
Text: None
Highlights: None
Highlight Scores: None
类别10: Places and things
感觉是 “周末去哪玩” 的另一种叫法。比如我输入:
在1月份的时候,在杭州去哪里玩比较有意思?


我从 python API 搜索,结果的前3个:
- 西湖
- 灵隐寺
- 六和塔
from exa_py import Exa
import os
MY_EXA_API = os.environ["MY_EXA_API"]
exa = Exa(MY_EXA_API)
q = "在1月份的时候,在杭州去哪里玩比较有意思?"
result = exa.search(q, use_autoprompt=True)
print(result)
Title: West Lake
URL: https://www.visitourchina.com/hangzhou/attraction/west-lake.html
ID: e8i-QT_gISqP7iwC4_wVsA
Score: 0.19630639255046844
Published Date: 2023-01-01
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: Scan to follow SHINE's official Wechat account.
URL: http://www.shine.cn/tags/lingyintemple/
ID: rq0v4ubX4uwyM1TdnRmNEg
Score: 0.19139492511749268
Published Date: 2020-09-12
Author: None
Text: None
Highlights: None
Highlight Scores: None
Title: Hangzhou Attractions: Hangzhou Liuhe Pagoda, Six Harmonies Pagoda
URL: https://www.hangzhouprivatetour.com/attractions/show/six_harmonies_pagoda.htm
ID: 7glcxF2Xx8-aDYEqu7RYzw
Score: 0.18733161687850952
Published Date: 2017-12-22
Author: None
Text: None
Highlights: None
Highlight Scores: None
总结
这篇简要介绍了 Exa 的使用, 是 LLM 应用到搜索引擎上的案例。
Exa 的输入可以是英文, 也可以是中文, 估计内部执行了翻译。
Exa 的输出是中文, 需要自行翻译。
Exa 相当于是在10个细分领域提升了搜索效率和质量。不过具体的类别应该是 API 内部自行判断的。
Exa 最初是需要输入 prompt 形式的查询文本, 现在则是支持任意关键词, 自动补充为 prompt。
大致流程是:
用于输入文本 -> 转换为英语 -> 自动补充为 prompt -> 判断检索内容属于哪个类别 -> 在这个类别里进行生成。
10个类别,那就是10个领域模型。
其他
Metaphor 的介绍视频: https://www.bilibili.com/video/BV1om4y1M7XM