Linux grep命令
目录
- 一. 前期准备
- 二. 配置项
-
- 2.1 -e 配置项
- 2.2 -h 配置项
- 2.3 显示上下文的配置项
-
- 2.3.1 -C配置项
- 2.3.2 -A配置项
- 2.3.3 -B配置项
- 三. zgrep
- 四. 案例
-
- 4.1 查询两个文件第一列的数据并去重
- 4.2 {} 或查询
- 4.3 文件路径和查询关键词中均包含正则表达式
- 4.4 查询指定内容开头 + 或 + 以指定内容结尾
- 4.5 抽取日志中指定的字段
- 4.6 `[^ ]*`和`\S*`
一. 前期准备
TEST-2023-07-11.txt
MPLE0130 Exception 123 ExecTime=
MPLE0190 ExecTime=123
MPLE0150 TST 1234 ExecTime=454
MPLE0160 Exception 123 ExecTime=
MPLE0170 TST 1234 ExecTime=999
TEST-2023-09-11.txt
CCCE0130 Exception 123
MPLE0150 TST 1234
MPLE0160 Exception 123
CCCE0170 TST 1234
TEST-2023-10-11.txt
MPLE0130 Exception 123 ExecTime=
MPLE0190 ExecTime=123
MPLE0150 TST 1234 ExecTime=454
MPLE0160 Exception 123 ExecTime=
MPLE0170 TST 1234 ExecTime=999
二. 配置项
2.1 -e 配置项
⏹下面两种写法相同,查询的都是MPLE0130或CCCE0130
grep -a -e MPLE0130 -e CCCE0130 /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt
grep -aE 'MPLE0130|CCCE0130' /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt
[2023-11-12 18:27:49.427] grep -a -e MPLE0130 -e CCCE0130 /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt
[2023-11-12 18:27:51.967] MPLE0130 Exception 123 ExecTime=
⏹查询TEST-2023-*-11.txt文件夹中包含Exception 关键字的
grep -a -e Exception /home/fengyehong/jmw_work_space/TEST-2023-*-11.txt
[2023-11-12 18:27:51.970] fengyehong@ubuntu:~$ grep -a -e Exception /home/fengyehong/jmw_work_space/TEST-2023-*-11.txt
[2023-11-12 18:31:47.356] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0130 Exception 123 ExecTime=
[2023-11-12 18:31:47.363] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0160 Exception 123 ExecTime=
[2023-11-12 18:31:47.371] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:CCCE0130 Exception 123
[2023-11-12 18:31:47.378] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:MPLE0160 Exception 123
[2023-11-12 18:31:47.387] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0130 Exception 123 ExecTime=
[2023-11-12 18:31:47.394] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0160 Exception 123 ExecTime=
2.2 -h 配置项
- 先查询ExecTime的值不为空白的数据,
-h可以只匹配结果不匹配文件所在路径 - 然后使用
grep -e "^\S"过滤掉开头为空白的数据 - 然后使用
awk '{print $1}'打印第一列
grep -a -h -e "ExecTime=\S*" /home/fengyehong/jmw_work_space/TEST-2023-{0[6-9],10}-11.txt | grep -e "^\S" | awk '{print $1}'
[2023-11-12 18:54:27.074] fengyehong@ubuntu:~$ grep -a -h -e "ExecTime=\S*" /home/fengyehong/jmw_work_space/TEST-2023-{0[6-9],10}-11.txt | grep -e "^\S" | awk '{print $1}'
[2023-11-12 18:55:41.989] MPLE0130
[2023-11-12 18:55:41.990] MPLE0150
[2023-11-12 18:55:41.990] MPLE0160
[2023-11-12 18:55:41.990] MPLE0170
[2023-11-12 18:55:41.990] MPLE0130
[2023-11-12 18:55:41.990] MPLE0150
[2023-11-12 18:55:41.990] MPLE0160
[2023-11-12 18:55:41.990] MPLE0170
2.3 显示上下文的配置项
⏹如下图所示的文本,我们想要匹配红框中的内容。
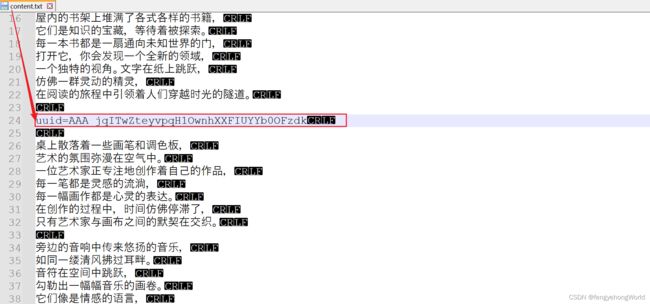
2.3.1 -C配置项
--context配置项的缩写,在匹配行的上方和下方显示额外的文本行。-C 3:显示匹配行的上下方的3行
grep -a -C 3 -e "uuid=\S*" ./content.txt
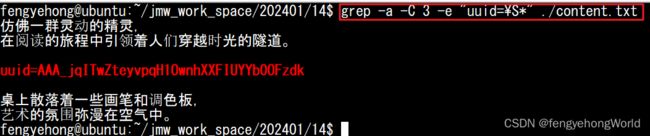
2.3.2 -A配置项
--after-context配置项的缩写,在匹配行的下方显示额外的文本行。-A 3:显示匹配行的下方的3行。
grep -a -A 3 -e "uuid=\S*" ./content.txt

2.3.3 -B配置项
--before-context配置项的缩写,在匹配行的下方显示额外的文本行。-B 3:显示匹配行的下方的3行。
grep -a -B 3 -e "uuid=\S*" ./content.txt

三. zgrep
⏹主要用来查询压缩包中的信息
# 统计 Desktop.zip 压缩包中 fengyehong 这个单词出现的次数
zgrep -a -e fengyehong /home/fengyehong/jmw_work_space/Desktop.zip | wc -l
四. 案例
4.1 查询两个文件第一列的数据并去重
file1.log
123 aaa 你好
345 bbb 我好
345 ccc 大家好
124 ddd 世界好
111 rrr 哈哈哈
file2.log
123 mmm 你好mmm
366 nnn 我好nnn
377 fff 大家好fff
124 uuu 世界好uuu
111 iii 哈哈哈iii
分析
两个文本文件格式相同,都是3列,第一例都是数字编号。可以通过打开这两个文件然后获取出开头列,然后排序之后再去重。
转换为linux命令之后就是
- 通过cat命令同时打开两个文本文件
-o配置项只输出匹配到的内容^\S*匹配开头不为空的内容sort用来排序uniq用来去重
cat file1.log file2.log | egrep -o -a "^\S*" | sort | uniq
111
123
124
345
366
377
如果我们想查看每个数字编码出现的次数的话,给uniq命令加上-c配置项即可。
其中第一列是数字编码出现的次数。
cat file1.log file2.log | egrep -o -a "^\S*" | sort | uniq -c
2 111
1 123
2 124
2 345
1 366
1 377
4.2 {} 或查询
⏹{}表示或,{0[6-9],10}表示从06月到10月。
grep -a -e Exception /home/fengyehong/jmw_work_space/TEST-2023-{0[6-9],10}-11.txt
[2023-11-12 18:33:28.388] fengyehong@ubuntu:~$ grep -a -e Exception /home/fengyehong/jmw_work_space/TEST-2023-{0[6-9],10}-11.txt
[2023-11-12 18:33:30.750] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0130 Exception 123 ExecTime=
[2023-11-12 18:33:30.757] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0160 Exception 123 ExecTime=
[2023-11-12 18:33:30.765] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:CCCE0130 Exception 123
[2023-11-12 18:33:30.772] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:MPLE0160 Exception 123
[2023-11-12 18:33:30.780] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0130 Exception 123 ExecTime=
[2023-11-12 18:33:30.787] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0160 Exception 123 ExecTime=
⏹从两个文件名类似的文件中查询
# 从 20231104bvspl.log 或 20231104bvapp.log 中进行查询
grep -a Error ./log/.20231104bv{spl,app}.log*
4.3 文件路径和查询关键词中均包含正则表达式
⏹路径和查询关键词中均包含正则表达式
^\S表示匹配非空白字符开头的部分。ExecTime=\S*匹配以 ExecTime= 开头后跟非空白字符的部分。
# "^\S" 表示匹配非空白字符开头的部分
# "ExecTime=\S*" 匹配以 ExecTime= 开头后跟非空白字符的部分
grep -a -e "^\S" -e "ExecTime=\S*" /home/fengyehong/jmw_work_space/TEST-2023-{0[6-9],10}-11.txt
[2023-11-12 18:36:15.874] fengyehong@ubuntu:~$ grep -a -e "^\S" -e "ExecTime=\S*" /home/fengyehong/jmw_work_space/TEST-2023-{0[6-9],10}-11.txt
[2023-11-12 18:37:14.504] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0130 Exception 123 ExecTime=
[2023-11-12 18:37:14.521] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt: MPLE0190 ExecTime=123
[2023-11-12 18:37:14.535] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0150 TST 1234 ExecTime=454
[2023-11-12 18:37:14.553] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0160 Exception 123 ExecTime=
[2023-11-12 18:37:14.570] /home/fengyehong/jmw_work_space/TEST-2023-07-11.txt:MPLE0170 TST 1234 ExecTime=999
[2023-11-12 18:37:14.587] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:CCCE0130 Exception 123
[2023-11-12 18:37:14.600] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:MPLE0150 TST 1234
[2023-11-12 18:37:14.615] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:MPLE0160 Exception 123
[2023-11-12 18:37:14.647] /home/fengyehong/jmw_work_space/TEST-2023-09-11.txt:CCCE0170 TST 1234
[2023-11-12 18:37:14.662] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0130 Exception 123 ExecTime=
[2023-11-12 18:37:14.679] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt: MPLE0190 ExecTime=123
[2023-11-12 18:37:14.694] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0150 TST 1234 ExecTime=454
[2023-11-12 18:37:14.712] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0160 Exception 123 ExecTime=
[2023-11-12 18:37:14.727] /home/fengyehong/jmw_work_space/TEST-2023-10-11.txt:MPLE0170 TST 1234 ExecTime=999
4.4 查询指定内容开头 + 或 + 以指定内容结尾
file3.log
110_A6 你好
120_A7 世界
110_G3 hello
110_G4 world
120_A7 こんにちは
140_G3 この世界
150_G4 uuuuuu
110_A6
120_A7
110_G3
110_G4
120_A7
140_G3
150_G4
⏹查询以110_开头,内容包括A6,G3,G4的内容
egrep -a "^110_(A6|G3|G4)" file3.log
110_A6 你好
110_G3 hello
110_G4 world
110_G3
110_G4
⏹查询以110_开头,内容包括A6,G3,G4的内容,并以此为结尾的内容
egrep -a "^110_(A6|G3|G4)$" file3.log
110_G3
110_G4
⏹查询以非空开头,内容包括A6,G3,G4的内容,并以此为结尾的内容
egrep -a "^\S*_(A6|G3|G4)$" file3.log
110_G3
110_G4
140_G3
150_G4
⏹查询以非空开头,内容包括A6,G3,G4的内容
egrep -a "^\S*_(A6|G3|G4)" file3.log
110_A6 你好
110_G3 hello
110_G4 world
140_G3 この世界
150_G4 uuuuuu
110_G3
110_G4
140_G3
150_G4
4.5 抽取日志中指定的字段
有如下日志file4.log
- 日志分内容分为2类,SEQIN 和 SEQOUT
- SEQIN 类中存在若干字段内容,isuuePayId,uuid,jmw_state,method等等
2323 SEQIN mmm isuuePayId=5768awe uuid=woenoo; jmw_state=success method=paypay info=ppp
2323 SEQOUT COST=45726
2345 SEQIN mmm isuuePayId=34895ry uuid=;ljkler jmw_state=faile method=alipay info=ddd
2345 SEQOUT COST=34855
需求,抽取出SEQIN类日志中的第一个字段,isuuePayId 和 jmw_state 字段,让其在一行显示
⏹第一步,抽取SEQIN类日志,去除掉 SEQOUT 日志
grep -a "SEQIN" file4.log
2323 SEQIN mmm isuuePayId=5768awe uuid=woenoo; jmw_state=success method=paypay info=ppp
2345 SEQIN mmm isuuePayId=34895ry uuid=;ljkler jmw_state=faile method=alipay info=ddd
⏹第二步,获取出SEQIN类日志中的第一个字段,isuuePayId 和 jmw_state 字段
grep -a "SEQIN" file4.log | egrep -o -a -e "^\S*" -e "isuuePayId=\S*" -e "jmw_state=\S*"
2323
isuuePayId=5768awe
jmw_state=success
2345
isuuePayId=34895ry
jmw_state=faile
⏹第三步,让isuuePayId和jmw_state到一行上显示
grep -a "SEQIN" file4.log
# 进一步过滤
| egrep -o -a -e "^\S*" -e "isuuePayId=\S*" -e "jmw_state=\S*"
# 替换指定字段的换行符
| sed ':loop; N; $!b loop; ;s/\n\([ij]\)/ \1/g'
2323 isuuePayId=5768awe jmw_state=success
2345 isuuePayId=34895ry jmw_state=faile
4.6 [^ ]*和\S*
20240109_xx.txt
123 name=jiafeitian transactionId=110120 resultCode=0
456 name=zhangsan transactionId= resultCode=1
789 name=lisi transactionId=
111 name=wangwu transactionId=890657 resultCode=0
需求:获取出所有的transactionId字段
⏹使用[^ ]*来获取
grep -o "transactionId=[^ ]*" ./20240109_xx.txt
transactionId=110120
transactionId=
transactionId=
transactionId=890657
⏹使用\S*来获取
grep -o "transactionId=\S*" ./20240109_xx.txt
transactionId=110120
transactionId=
transactionId=
transactionId=890657