趣味科普|可解释性人工智能
可解释性人工智能

PART.01
概述

1
可解释性人工智能(XAI)定义
![]()
随着机器学习和人工智能技术在各个领域中的迅速发展和应用,向用户解释算法输出的结果变得至关重要。人工智能的可解释性是指人能够理解人工智能模型在其决策过程中所做出的选择,包括做出决策的原因,方法,以及决策的内容[1]。简单的说,可解释性就是把人工智能从黑盒变成了白盒。
2
研究的作用
![]()
可解释性是现在人工智能在实际应用方面面临的最主要的障碍之一。人们无法理解或者解释为何人工智能算法能取得这么好的表现。可解释性人工智能模型的作用主要有:
1. 可解释性人工智能可以打破研究和应用之间的差距,加速先进的人工智能技术在商业上的应用:出于安全,法律,道德伦理等方面的原因,在一些管制较多的领域场景例如医疗,金融等,会限制无法解释的人工智能技术的使用。
2. 通过可解释性理解模型做出的决策,找出偏差出现的原因,从而提升模型的性能。
3. 有助于人工智能模型的使用:可解释性可以帮助用户理解人工智能所做出的决策,使得用户能更有效地使用模型,也能纠正用户在使用模型时因为不清楚算法所做的事情而产生错误的操作;
4. 可解释性人工智能能增加用户的信任度:用户知道了人工智能决策的依据之后,会更加信任人工智能所做出的政策。
3
应用领域
![]()
1. 学术研究:可解释性人工智能可以更好的帮助研究人员有效的理解模型做出的决策,从而发现模型做出的决策偏差并且针对性的纠正错误,提升模型的性能;可解释性算法可以找出算法的薄弱点,并针对性的加入噪音来促进算法的鲁棒性,例如对抗性学习;可解释性可以确保只有有意义的变量才能推断出输出,来使得决策过程中因果关系更加真实。
2. 医疗领域:可解释性人工智能可以根据输入的数据症状或者CT图,给出一个可解释性的预测结果,来辅助医生进行诊断。假如模型是不可解释的,无法确定模型是怎么进行决策的,医生也不敢轻易使用人工智能提供的结果进行诊断。
![]()

图 1| 医疗领域中使用人工智能进行辅助诊断
3. 金融领域:金融领域也是极度依赖可解释性的行业领域。人工智能做出的投资决策需要有很强的解释性,否则金融从业人员不会放心使用模型得出的决策结果;金融领域中可解释性人工智能另一个常用的应用方向是检测金融欺诈行为,模型找出欺诈行为并提供决策的解释,帮助监管人员打击犯罪。
4. 信息安全:通过XAI技术获取的模型可解释性信息,可以加入到对抗性环境中,对模型进行更有效的攻击,找出模型安全性较差的环节并进行修复,利用XAI技术来提升系统安全性。
5. 专家系统:专家系统是一类具有专门知识和经验的计算机智能程序系统,采用知识表示和知识推理技术模拟通常由领域专家才能解决的复杂问题。专家系统也需要很强的解释性。
4
XAI的目标
![]()
可解释性人工智能拥有众多的解释性目标。但是由于可解释性的范围太过于广泛,不同的应用场景下所需要解释的内容不一样,甚至针对不同的用户受众所要解释的内容也不同,因此目前XAI领域没有一个统一的评判标准体系。但是文献[2]中对XAI相关工作中用到的评判指标做了总结统计,按使用频率排名较前的有:
1. 信息性:信息性是最常用也是用户受众最广的解释性目标,几乎所有受众都能使用这个解释性目标。使用人工智能模型的最终目的是支持决策[3],因此需要人工智能需要提供大量有关决策目标的信息,来将用户的决定与模型给出的解决方案联系起来,使得用户理解模型内部的作用,从而更好的使用模型。
2. 可移植性:这是使用第二常用的目标,一般应用受众为领域专家和从事数据科学的人员。可移植性表示了人工智能方法能否在不同的场景和数据下很好的应用,可移植性高的算法拥有更广泛的应用场景。可解释人工智能可以提升算法的可移植性,因为它可以清楚的表示出算法的决策过程,以及可能影响模型应用的边界值,这有助于用户在不同的场景中应用算法[4]。
3. 可访问性:应用频率第三的目标是可访问性,主要受众是产品开发团队以及用户。可访问性表示的是能否用非专业的解释方式来进行算法的解释,,保证非专业人员也能明白算法的决策过程,降低了用户在对算法提供改进意见时的技术准入门槛,保证用户能参与改进或者开发人工智能模型的过程中[5],让用户能更加专注于提升自己的体验。
除此之外,可解释性人工智能的目标还有:可信度,因果关系,置信度,公平性,隐私保护等等。

PART.02
主要实现方法

目前可解释性人工智能的实现方法主要分为两种:一种是可解释模型,即设计出来的机器学习模型本来就具备可解释的能力;另一种是模型可解释技术,利用模型可解释技术来解释本来没有可解释性的机器学习模型。
1
可解释模型
![]()
可解释模型的可解释性可以分为三个层次:可模拟性、可分解性和算法透明。可模拟性指整体模型可以直接被人类进行模拟以及评估;可分解性表示模型的各个部分(输入、参数和计算)都可以被解释;而算法透明表示用户能够理解模型从其任意输入数据中产生任何给定输出的过程,通常需要使用数学分析来获得算法透明。
比较典型的可解释模型有线性回归,决策树,KNN,以及基于规则的学习等等。
1. 线性回归:线性回归假设自变量和因变量之间存在线性关系,并且通过计算得出他们之间的线性关系。该方法能很好的做到可解释模型的3个层次,但是也需要模型可解释技术辅助进行更好的解释。线性回归模型被提出的时间较早,已经被应用了很长一段时间,因此其解释模型结果的方法也较为成熟,包括统计学方法[6]以及可视化方法等等。当然线性回归的解释性也有一些潜在的问题[7],例如未观察到的异质性,不同模型之间比率可能会无效等等。另外想要线性回归模型保持可模拟性和可分解性,模型不能过大,而且变量必须被用户理解。
![]()
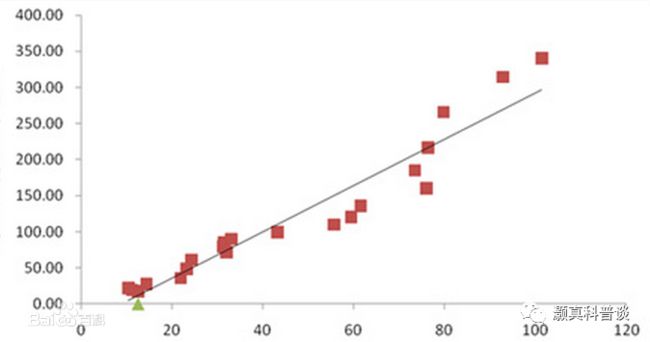
图2 |线性回归
2. 决策树:决策树是用于回归和分类问题的分层决策结构[8],能满足可解释模型的各个层次。虽然决策树能拟合各个层次,但是决策树的个体特征会使其倾向于某个层次,这和决策环境密切相关的。决策树拥有较高的可解释性,因此长期应用于非计算机和人工智能领域,因此决策树在其他领域的解释性已经有很多成熟的工作可以参考[9][10]。但是,决策树泛化能力较差,不适用于需要平衡预测准确度的场景。
![]()

图3 |决策树算法
3. KNN:即K最近邻算法,选择测试样本的K个最近邻的类别中最多的类别作为样本类别的预测结果。KNN的模型可解释性取决于特征数量、邻居数量(即K值)和用于度量样本之间相似性的距离函数。如果K值特别大则会降低KNN的可模拟性,而如果特征或者距离函数较为复杂,会限制KNN模型的可分解性。
![]()
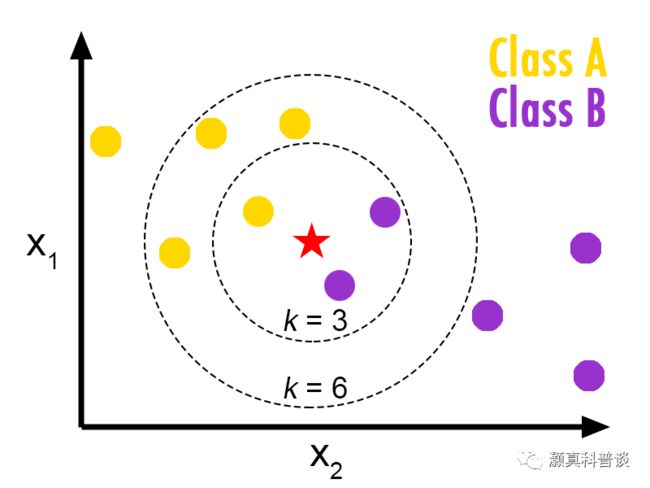
图4 |KNN算法
4. 基于规则的学习:基于规则的学习会使用数据集进行训练,生成规则来表示模型。规则常用简单的if-then形式或者简单形式的排列组合来表示,具体表示方法如图5所示。基于规则的学习是可解释性模型,常通过生成解释规则来解释复杂模型[11],在可解释性上表现非常好,因为它和人类平时思考模式相近,易于理解和解释。相对应的规则学习的泛化能力就较差了。基于规则的学习广泛应用于专家系统的知识表示[12]。但是需要注意,模型规则数量会提升模型的性能,但是同时也会降低解释性。规则的长度也不利于可解释性。需要增加可解释性,只需要放宽规则约束。
![]()

图5 |基于规则的学习
2
模型可解释技术
![]()
当机器学习模型本身不属于可解释模型时,就需要使用模型可解释技术来解释其决策。模型可解释技术的目的是表示已有的模型如何从给定的输入生成出预测的可理解信息。现在比较常用的模型可解释方法主要有特征重要性方法和基于实例的方法。
1、特征重要性方法
特征重要性方法主要分为基于扰动的方法和基于梯度的方法。
(1)基于扰动的方法
通过一个或者一组输入特征来对输入进行扰动,从而观察其与原始输出的差异,来得到特征重要性。基于扰动的方法可以直接估计特征的重要性,使用简单,通用性强。但是每次只能扰动一个或一组特征,导致算法速度缓慢。另外,一些复杂的机器学习模型是非线性的,解释受选择的特征的影响很大。较为经典的基于扰动的方法有LIME[13]和SHAP[14]。
LIME,全称Local Interpretable Model-agnostic Explanations,局部可解释模型不可知解释。其原理是以需要解释的模型为基础上来设计一个全新的简化的可解释模型,然后使用这个简单的模型,搭配可解释的特征进行适配,来接近复杂模型的效果,从而起到解释复杂模型的作用。
作者在LIME的基础上提出了Anchors算法[15]。和LIME相比,LIME是在局部建立一个可理解的线性可分模型,而Anchors的目的是建立一套更精细的规则系统。
![]()
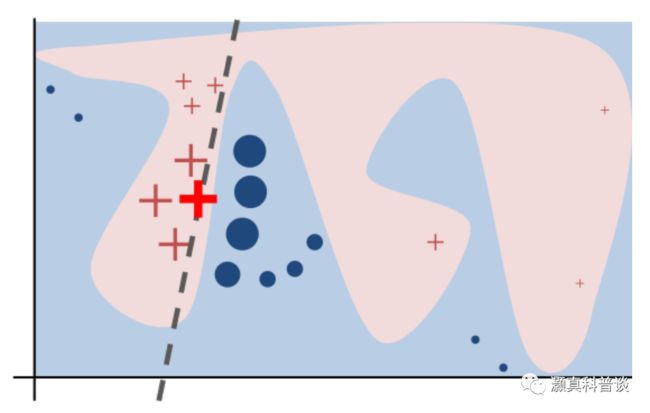
图 6|LIME算法的例子[13]
SHAP的全称是SHapley Additive exPlanation,是由Shapley value启发的可加性解释模型。它的核心思想是计算特征对模型输出的贡献,然后从全局和局部两个层面对“黑盒模型”进行解释。SHAP是在实际使用中最常用的方法,易于操作。由于该方法可以得出各特征对模型的影响,主要被用于进行特征工程或者辅助数据采集。
![]()

图 7| SHAP算法
(2)基于梯度的算法
基于梯度的基本方法只是计算输出相对于输入的梯度,相比扰动方法更有效率。例如DeepLIFT(Deep Learning Important FeaTures)方法[16]将每个神经元的激活与它的"参考激活"进行比较,并根据差异给每个输入分配分数。
2、基于实例的方法
基于实例的方法会使用特定的实例作为输入来解释机器学习模型,因此它们通常只提供局部解释。基于实例的方法是模仿人类的推理方式而提出的,人类通常在推理时会使用类似的情况举例来提供解释。较常用的方法有反事实解释[17]和对抗性攻击[18]。
反事实解释可以理解为从想要的结果来倒推输入,从而获得模型的解释。该方法使用类似的情况,对机器学习模型的当前输入实例进行不同的预测。
对抗性攻击是特意使用能做出错误预测的例子来对模型进行解释。一个较为经典的用法是在识别图片中物体时,通过在照片中加入噪音来让机器学习模型无法正确识别。如图8所示,在猫的图片中加入了噪音后模型会将其识别为柠檬。但是对于人类来说图片是没有变化的。当发现了这种问题后便可以对其进行改进,从而提升模型的鲁棒性。
![]()

图 8|对抗性攻击
3
可解释性深度学习
![]()
深度学习模型一直被认为是黑箱模型,模型本身没有可解释性,因此必须使用模型可解释技术进行解释。解释性差已经成为了现在深度学习发展的最大的阻力之一。解释深度学习的常用方法有事后局部解释和特征相关性技术。下面按照不同的深度学习方法类型,分为多层神经网络、卷积神经网络(CNN)和循环神经网络(RNN)来分别介绍它们的可解释性方法。
1)多层神经网络:在推断变量间复杂关系下效果极佳,但是可解释性非常差。常用的可解释方法包括模型简化方法、特征相关性估计、文本解释、局部解释和模型可视化[19][20][21]。
2)卷积神经网络:卷积神经网络主要应用于图像分类,对象检测和实例分割。虽然其复杂的内部关系使得模型难以解释,但是对于人类来说,图形会更好理解,因此CNN会比其他的深度学习模型更好解释。一般的可解释方法有两种:一是把输出映射到输入空间上,查看哪些输入会影响输出,从而理解模型的决策过程;二是深入网络内部,以中间层的视角来解释外部[22][23][24]。
3)循环神经网络:RNN广泛应用于固有序列数据的预测问题,如自然语言处理和时间序列分析。RNN的可解释方法较少,主要分为两类:一是使用特征相关性解释方法,理解RNN模型所学习的内容;二是使用局部解释,修改RNN架构来对决策进行解释[25][26]。

PART.03
未来研究方向

下面对XAI未来需要解决的问题和可能的研究方向进行一个简要的介绍。
1
模型可解释性和性能之间的权衡
![]()
在提升模型性能的同时往往会降低模型的可解释性,因为性能往往会便是和算法复杂度绑定的,而越复杂的模型可解释性就越差。准确性和可解释性的关系如图9所示。虽然性能和可解释性这种负相关的趋势无法逆转,我们还是可以通过升级可解释性的方法,使其更加精密,从而减缓这种负相关的趋势[27]。
![]()

图 9|可解释性和准确性之间的关系
2
统一可解释性的指标
![]()
在1.3节中已经提到过,目前可解释性人工智能领域并没有一个统一的评判指标。而这将会是可解释性人工智能发展路上的一个重大阻碍。XAI领域需要持续发展,就必须先统一评判指标。值得高兴的是,已经有学者开始注意到这个问题并开始研究如何用统一的标准来评判可解释性[2]。
3
深度学习模型的可解释性
![]()
在2.2节的深度学习的模型可解释性技术中有提到,深度学习一直被认为是黑箱模型,在实际应用中一个较大的阻力就是相当于传统的机器学习方法,深度学习可解释性较差。这不仅限制了深度学习在管制较多的领域上的应用,而且也会影响到模型的优化。在无法知晓深度学习模型进行决策的原因的情况下是很难做出好的改进的。如果能对深度学习模型进行一个好的解释,将会使得深度学习发展速度更快。
4
XAI在信息安全上的应用
![]()
目前XAI在信息安全上的应用较少,但是在未来这可能会是一个重要的应用场景。XAI可以通过模型的输入和输出来推理模型的数据和作用,从而被用于盗窃模型数据和功能[28]。当然从另一个角度来看,通过XAI技术获取的信息可以加入到对抗性环境中,对模型进行更有效的攻击,找出模型安全性较差的环节并进行修复,来利用XAI技术来提升系统安全性。
5
XAI可以支持跨学科信息交流
![]()
XAI能对无专业背景的用户有效的进行模型决策的解释,即1.3节中提到的可访问性。XAI也可以进行关键数据研究,即进行多学科融合,并针对不同的受众给出他们需要知道的解释[29]。XAI可以促进不同受众和学科之间的信息交流。

PART.04
总结

可解释性人工智能的目标是使人能够理解人工智能模型决策的过程,从而更好的对模型进行使用以及改进,并且增加用户的信任度,扩展人工智能技术的应用场景。深度学习算法的不可解释性是现在限制深度学习的发展的一个重要问题,因此可解释性的研究将会是深度学习未来重要的研究方向。另外,可解释性人工智能还能应用于信息安全领域,还能促进跨学科知识交流。可解释性人工智能才刚处于起步阶段,拥有非常广阔的研究前景。相信在不远的未来,可解释性人工智能会引领人工智能技术进行一次新的突破。
参考文献:
[1] Confalonieri R, Coba L, Wagner B, et al. A historical perspective of explainable Artificial Intelligence[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2021, 11(1): e1391.
[2] Arrieta A B, Díaz-Rodríguez N, Del Ser J, et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI[J]. Information Fusion, 2020, 58: 82-115.
[3] Huysmans J, Dejaeger K, Mues C, et al. An empirical evaluation of the comprehensibility of decision table, tree and rule based predictive models[J]. Decision Support Systems, 2011, 51(1): 141-154.
[4] Caruana R, Lou Y, Gehrke J, et al. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission[C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 1721-1730.
[5] Miller T, Howe P, Sonenberg L. Explainable AI: Beware of inmates running the asylum[C]// Proceedings of the International Joint Conference on Artificial Intelligence: Vol. 36. Menlo Park: AAAI Press, 2017: 36-40.
[6] Hosmer Jr D W, Lemeshow S, Sturdivant R X. Applied logistic regression: Vol. 398[M]. New York: John Wiley & Sons, 2013.
[7] Mood C. Logistic regression: Why we cannot do what we think we can do, and what we can do about it[J]. European Sociological Review, 2010, 26(1): 67-82.
[8] Quinlan J R. Simplifying decision trees[J]. International Journal of Man-Machine Studies, 1987, 27(3): 221-234.
[9] Maimon O Z, Rokach L. Data mining with decision trees: Theory and applications: Vol. 69[M]. Singapore: World Scientific, 2014.
[10] Rovnyak S, Kretsinger S, Thorp J, et al. Decision trees for real-time transient stability prediction[J]. IEEE Transactions on Power Systems, 1994, 9(3): 1417-1426.
[11] Nunez H, Angulo C, Catala A. Rule-based learning systems for support vector machines[J]. Neural Processing Letters, 2006, 24(1): 1-18.
[12] Langley P, Simon H A. Applications of machine learning and rule induction[J]. Communications of the ACM, 1995, 38(11): 54-64.
[13] Ribeiro M T, Singh S, Guestrin C. "Why should I trust you?" Explaining the predictions of any classifier[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1135-1144.
[14] Lundberg S M, Lee S I. A unified approach to interpreting model predictions[C]// Proceedings of the Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2017: 4765-4774.
[15] Ribeiro M T, Singh S, Guestrin C. Nothing else matters: model-agnostic explanations by identifying prediction invariance[C]// Proceedings of the 30th Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2016.
[16] Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences[C]// Proceedings of the 34th International Conference on Machine Learning. New York: PMLR, 2017: 3145-3153.
[17] Sharma S, Henderson J, Ghosh J. Certifai: Counterfactual explanations for robustness, transparency, interpretability, and fairness of artificial intelligence models[J]. arXiv preprint arXiv:1905.07857, 2019.
[18] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[C]// Proceedings of the 2th International Conference on Learning Representations. New York: Curran Associates, Inc., 2013.
[19] Che Z, Purushotham S, Khemani R, et al. Interpretable deep models for ICU outcome prediction[C]// American Medical Informatics Association (AMIA) Annual Symposium: Vol. 2016. New York: AMIA, 2016, 371-380.
[20] Montavon G, Lapuschkin S, Binder A, et al. Explaining nonlinear classification decisions with deep taylor decomposition[J]. Pattern Recognition, 2017, 65: 211-222.
[21] Kindermans P J, Schütt K T, Alber M, et al. Learning how to explain neural networks: Patternnet and patternattribution[C]// Proceedings of the International Conference on Learning Representations. New York: Curran Associates, Inc., 2017.
[22] Bach S, Binder A, Montavon G, et al. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation[J]. PloS One, 2015, 10(7): e0130140.
[23] Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2921-2929.
[24] Zeiler M D, Taylor G W, Fergus R. Adaptive deconvolutional networks for mid and high level feature learning[C]// Proceedings of the 2011 International Conference on Computer Vision. New York: IEEE, 2011: 2018-2025.
[25] Arras L, Montavon G, Müller K R, et al. Explaining recurrent neural network predictions in sentiment analysis[C]// Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysi. New York: Association for Computational Linguistics, 2017: 159-168.
[26] Choi E, Bahadori M T, Sun J, et al. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism[C]// Proceedings of the Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2016: 3504-3512.
[27] Gunning D. Explainable artificial intelligence (xAI)[R]. Arlington: Defense Advanced Research Projects Agency (DARPA), 2017.
[28] Orekondy T, Schiele B, Fritz M. Knockoff nets: Stealing functionality of black-box models[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 4954-4963.
[29] Iliadis A, Russo F. Critical data studies: An introduction[J]. Big Data & Society, 2016, 3(2): 2053951716674238.
【END】
图文/ 张明睿 杜秉航 刘子琪 王宇洋 黄易平
排版/ 张明睿
审核/ 郝治翰 安栩瑶 赵润泽 杜秉航
文章仅代表作者观点,本文首发于瀚创科普谈,转载请注明公众号出处

您的点赞,就是对我们最大的支持

分享

收藏

点赞

在看