ShardingSphere之ShardingJDBC客户端分库分表上
目录
什么是ShardingSphere?
客户端分库分表与服务端分库分表
ShardingJDBC客户端分库分表
ShardingProxy服务端分库分表
ShardingSphere实现分库分表的核心概念
ShardingJDBC实战
什么是ShardingSphere?
ShardingSphere是一款起源于当当网内部的应用框架。2015年在当当网内部诞生,最初就叫ShardingJDBC。 ShardingSphere这个词可以分为两个部分,其中Sharding就是指的数据分片。从官网介绍上就能看到,他的核心功能就是可以将任意数据库组合,转换成为一个分布式的数据库,提供整体的数据库集群服务。后面的Sphere是生态的意思。这意味着ShardingSphere不是一个单独的框架或者产品,而是一个由多个框架以及产品构成的一个完整的技术生态。目前ShardingSphere中比较成型的产品主要包含核心的ShardingJDBC以及ShardingProxy两个产品,以及一个用于数据迁移的子项目ElasticJob,另外还包含围绕云原生设计的一系列未太成型的产品。
ShardingSphere经过这么多年的发展,已经不仅仅只是用来做分库分表,而是形成了一个围绕分库分表核心的技术生态。他的核心功能已经包括了数据分片、分布式事务、读写分离、高可用、数据迁移、联邦查询、数据加密、影子库、DistSQL庞大的技术体系。
客户端分库分表与服务端分库分表
ShardingSphere最为核心的产品有两个:一个是ShardingJDBC,这是一个进行客户端分库分表的框架。另一个是ShardingProxy,这是一个进行服务端分库分表的产品。他们代表了两种不同的分库分表的实现思路。(本篇主要介绍ShardingJDBC的5.x版本)
ShardingJDBC客户端分库分表
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等。
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
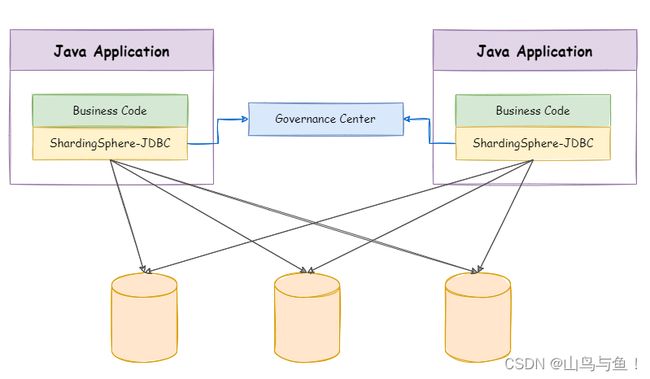
应用层只需要修改配置文件,使用跟正常单库一样。(灵活的胖子)
ShardingProxy服务端分库分表
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供MySQL和PostgreSQL协议,透明化数据库操作,对DBA更加友好。
向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
兼容MariaDB等基于MySQL协议的数据库,以及openGauss等基于PostgreSQL协议的数据库。
适用于任何兼容MySQL/PostgreSQL协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat等。

应用通过访问ShardingProxy服务端来访问数据库,统一管理。(呆板的管家)
ShardingSphere实现分库分表的核心概念
1. 虚拟库: ShardingSphere的核心就是提供一个具备分库分表功能的虚拟库,他是一个 ShardingSphereDatasource实例。应用程序只需要像操作单数据源一样访问这个 ShardingSphereDatasource即可。
2. 真实库: 实际保存数据的数据库。这些数据库都被包含在ShardingSphereDatasource实例当中,由 ShardingSphere决定未来需要使用哪个真实库。
3. 逻辑表: 应用程序直接操作的逻辑表。
4. 真实表: 实际保存数据的表。这些真实表与逻辑表表名不需要一致,但是需要有相同的表结构,可以分布在 不同的真实库中。应用可以维护一个逻辑表与真实表的对应关系,所有的真实表默认也会映射成为 ShardingSphere的虚拟表。
5. 分布式主键生成算法: 给逻辑表生成唯一主键。由于逻辑表的数据是分布在多个真实表当中的,所有,单表 的索引就无法保证逻辑表的ID唯一性。ShardingSphere集成了几种常见的基于单机生成的分布式主键生成 器。比如SNOWFLAKE,COSID_SNOWFLAKE雪花算法可以生成单调递增的long类型的数字主键,还有 UUID,NANOID可以生成字符串类型的主键。当然,ShardingSphere也支持应用自行扩展主键生成算法。比 如基于Redis,Zookeeper等第三方服务,自行生成主键。
6. 分片策略: 表示逻辑表要如何分配到真实库和真实表当中,分为分库策略和分表策略两个部分。分片策略由 分片键和分片算法组成。分片键是进行数据水平拆分的关键字段。如果没有分片键,ShardingSphere将只能 进行全路由,SQL执行的性能会非常差。分片算法则表示根据分片键如何寻找对应的真实库和真实表。简单的 分片策略可以使用Groovy表达式直接配置,当然,ShardingSphere也支持自行扩展更为复杂的分片算法。
ShardingJDBC实战
ShardingJDBC是整个ShardingSphere最早也是最为核心的一个功能模块,他的 主要功能就是数据分片和读写分离,通过ShardingJDBC,应用可以透明的使用 JDBC访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数 据如何分布。
引入依赖
org.apache.shardingsphere
shardingsphere-jdbc-core-spring-boot-starter
5.2.1
snakeyaml
org.yaml
org.yaml
snakeyaml
1.33
配置文件
# 在控制台打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true
# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#------------------------分布式序列算法配置
# 雪花算法,生成Long类型主键id。
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker.id=1
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.column=cid
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.key-generator-name=alg_snowflake
#-----------------------实际分片节点m0,m1
spring.shardingsphere.rules.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
#MOD分库策略
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-algorithm-name=course_db_alg
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.props.sharding-count=2
#给course表指定分表策略 standard-按单一分片键进行精确或范围分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-algorithm-name=course_tbl_alg
# 分表策略-INLINE:按单一分片键分表
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{cid%2+1}
实体类
public class Course {
private Long cid;
// 如果使用id作为主键,注意MyBatis会默认对id字段生成主键。
// private Long id;
private String cname;
private Long userId;
private String cstatus;
public Long getCid() {
return cid;
}
public void setCid(Long cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getCstatus() {
return cstatus;
}
public void setCstatus(String cstatus) {
this.cstatus = cstatus;
}
@Override
public String toString() {
return "Course{" +
"cid=" + cid +
", cname='" + cname + '\'' +
", userId=" + userId +
", cstatus='" + cstatus + '\'' +
'}';
}
}mapper文件
public interface CourseMapper extends BaseMapper {
} 数据库sql
-- 创建两个数据库coursedb、coursedb2,分别执行以下sql
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(20) NOT NULL,
`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for course_1
-- ----------------------------
DROP TABLE IF EXISTS `course_1`;
CREATE TABLE `course_1` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(20) NOT NULL,
`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for course_2
-- ----------------------------
DROP TABLE IF EXISTS `course_2`;
CREATE TABLE `course_2` (
`cid` bigint(20) NOT NULL,
`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(20) NOT NULL,
`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingTest {
@Resource
private CourseMapper courseMapper;
@Test
public void addcourse() {
for (int i = 0; i < 10; i++) {
Course c = new Course();
c.setCname("java");
c.setUserId(1001L);
c.setCstatus("1");
courseMapper.insert(c);
System.out.println(c);
}
}
}按照上述配置,执行结果如下:


coursedb中的course_1表有数据,coursedb2中的course_2表有数据。
本案例使用的INLINE分表策略。
如果说我们想要实现均匀的分布到两库中四个表,需要修改分表策略规则以及修改雪花算法。
#如果需要做到均匀分片,修改算法同时,还要修改雪花算法。把SNOWFLAKE换成MYSNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=MYSNOWFLAKE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{((cid+1)%4).intdiv(2)+1}
改进的雪花算法如下(来自图灵楼兰老师):
/**
* 改进雪花算法,让他能够 %4 均匀分布。
*/
public final class MySnowFlakeAlgorithm implements KeyGenerateAlgorithm, InstanceContextAware {
public static final long EPOCH;
private static final String MAX_VIBRATION_OFFSET_KEY = "max-vibration-offset";
private static final String MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS_KEY = "max-tolerate-time-difference-milliseconds";
private static final long SEQUENCE_BITS = 12L;
private static final long WORKER_ID_BITS = 10L;
private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1;
private static final long WORKER_ID_LEFT_SHIFT_BITS = SEQUENCE_BITS;
private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS + WORKER_ID_BITS;
private static final int DEFAULT_VIBRATION_VALUE = 1;
private static final int MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS = 10;
private static final long DEFAULT_WORKER_ID = 0;
private static TimeService timeService = new TimeService();
public static void setTimeService(TimeService timeService) {
MySnowFlakeAlgorithm.timeService = timeService;
}
private Properties props;
@Override
public Properties getProps() {
return props;
}
private int maxVibrationOffset;
private int maxTolerateTimeDifferenceMilliseconds;
private volatile int sequenceOffset = -1;
private volatile long sequence;
private volatile long lastMilliseconds;
private volatile InstanceContext instanceContext;
static {
Calendar calendar = Calendar.getInstance();
calendar.set(2016, Calendar.NOVEMBER, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
EPOCH = calendar.getTimeInMillis();
}
@Override
public void init(final Properties props) {
this.props = props;
maxVibrationOffset = getMaxVibrationOffset(props);
maxTolerateTimeDifferenceMilliseconds = getMaxTolerateTimeDifferenceMilliseconds(props);
}
@Override
public void setInstanceContext(final InstanceContext instanceContext) {
this.instanceContext = instanceContext;
if (null != instanceContext) {
instanceContext.generateWorkerId(props);
}
}
private int getMaxVibrationOffset(final Properties props) {
int result = Integer.parseInt(props.getOrDefault(MAX_VIBRATION_OFFSET_KEY, DEFAULT_VIBRATION_VALUE).toString());
Preconditions.checkArgument(result >= 0 && result <= SEQUENCE_MASK, "Illegal max vibration offset.");
return result;
}
private int getMaxTolerateTimeDifferenceMilliseconds(final Properties props) {
return Integer.parseInt(props.getOrDefault(MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS_KEY, MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS).toString());
}
@Override
public synchronized Long generateKey() {
long currentMilliseconds = timeService.getCurrentMillis();
if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {
currentMilliseconds = timeService.getCurrentMillis();
}
if (lastMilliseconds == currentMilliseconds) {
// if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) {
currentMilliseconds = waitUntilNextTime(currentMilliseconds);
// }
} else {
vibrateSequenceOffset();
// sequence = sequenceOffset;
sequence = sequence >= SEQUENCE_MASK ? 0:sequence+1;
}
lastMilliseconds = currentMilliseconds;
return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence;
}
private boolean waitTolerateTimeDifferenceIfNeed(final long currentMilliseconds) {
if (lastMilliseconds <= currentMilliseconds) {
return false;
}
long timeDifferenceMilliseconds = lastMilliseconds - currentMilliseconds;
Preconditions.checkState(timeDifferenceMilliseconds < maxTolerateTimeDifferenceMilliseconds,
"Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastMilliseconds, currentMilliseconds);
try {
Thread.sleep(timeDifferenceMilliseconds);
} catch (InterruptedException e) {
}
return true;
}
private long waitUntilNextTime(final long lastTime) {
long result = timeService.getCurrentMillis();
while (result <= lastTime) {
result = timeService.getCurrentMillis();
}
return result;
}
@SuppressWarnings("NonAtomicOperationOnVolatileField")
private void vibrateSequenceOffset() {
sequenceOffset = sequenceOffset >= maxVibrationOffset ? 0 : sequenceOffset + 1;
}
private long getWorkerId() {
return null == instanceContext ? DEFAULT_WORKER_ID : instanceContext.getWorkerId();
}
@Override
public String getType() {
return "MYSNOWFLAKE";
}
@Override
public boolean isDefault() {
return true;
}
}通过使用此种算法,我们先清空之前的数据,然后重新执行测试方法如下:
coursedb库中两表的数据


coursedb2库中两表的数据
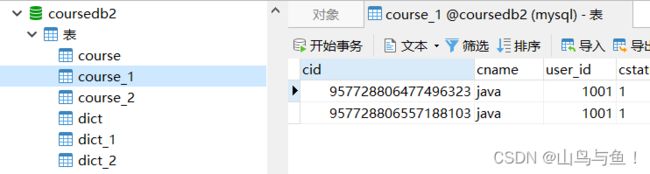
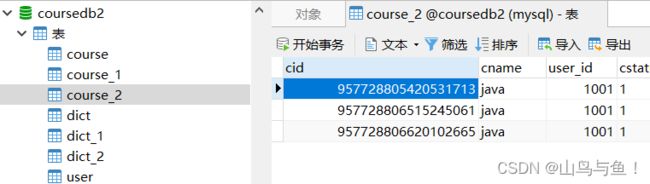
可以看到,数据均匀的分布到了四个表中。
数据已经插入到库中,以下测试查询
@Test
public void queryCourse() {
QueryWrapper wrapper = new QueryWrapper();
wrapper.eq("cid",957728805420531713L);
// wrapper.in("cid",957728805420531713L,957728806460719106L,3L);
//带上排序条件不影响分片逻辑
// wrapper.orderByDesc("user_id");
List courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
} 执行SQL过程及结果

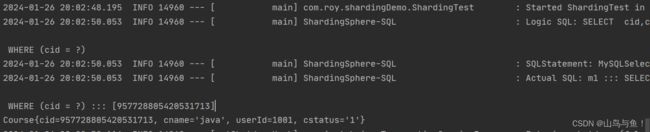
如果是in操作,执行结果如下


像= 和 in 这样的操作,可以拿到cid的精确值,所以都可以直接通过表达式计算出可能的真实库以及真实表, ShardingSphere就会将逻辑SQL转去查询对应的真实库和真实表。这些查询的策略,只要配置了sql-show参数, 都会打印在日志当中。
如果不使用分片键cid进行查询
@Test
public void queryCourse() {
QueryWrapper wrapper = new QueryWrapper();
List courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
} ![]()
可以看到使用union执行了两次SQL进行全表查询。
以上案例使用的INLINE策略,后续演示其他策略。