欺骗大模型却能大幅提升效果的骚操作!
在大模型的提示工程中,少样本提示,思维链提示(CoT)都是行之有效的方法,通过为大模型提供几个样例,为模型提供更多更相关的上下文,让模型回答时有所参照,可以提高模型性能。
没想到,骗大模型说有样例,实则并没有提供样例,也能实现模型性能提升,如下图所示:

通过提示模型查看“样例”部分中的样例,并利用该部分中的样例和信息执行以下任务。此处的 “样例”部分在上下文中并不存在。
好家伙,无招胜有招啊!还能这么玩。

今天介绍的这篇论文发现通过如此简单提示,可以提高模型在大多数任务上的性能。相比zero-shot,使用GPT-3.5 Turbo在算术推理任务上改进高达33.94%。
由于样例部分为空,论文将这种提示取名为 ∅-shot或者Null-Shot。
为了与GPT-3的论文《Language Models are Few-Shot Learners》呼应,作者还将论文标题定为:
《Large Language Models are Null-Shot Learners》
论文链接:
https://arxiv.org/pdf/2401.08273.pdf
论文的思想很简单但也很独特,我们直接来看看实验分析过程。
实验与分析
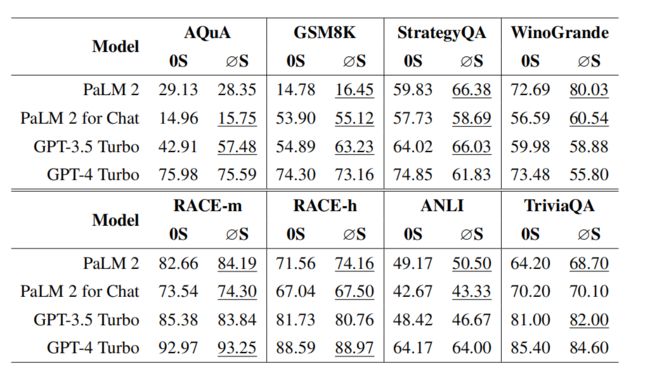
为了评估∅-shot提示的性能,主实验使用的LLM模型分别是PaLM 2,PaLM 2 for Chat,GPT-3.5 Turbo和GPT-4 Turbo,扩展分析使用的LLM模型是Llama 2 7B和Llama 2 7B Chat。主要评估对比了在八个数据集上的六个任务中∅-shot提示和zero-shot提示的性能,如下图所示:

-
在相同的数据集下,与其他模型相比,GPT-3.5 Turbo 在算术推理任务中使用 ∅-shot 提示时呈现出最显著的性能提升,即 AQuA-RAT 和 GSM8K 分别增加了33.94% 和 15.19%。
-
PaLM 2在除了 AQuA-RAT 之外的所有数据集上的性能有所提升。
-
∅-shot提示对GPT-4 Turbo似乎作用不大,甚至表现出反效果,特别是在StrategyQA 和 WinoGrande 这两个常识推理任务中。
为什么会出现这样的结果呢?我们来看看作者给出的部分示例:
-
使用GPT-4 Turbo对StrategyQA数据集进行∅-shot提示生成的输出:

-
使用 GPT-3.5 Turbo对StrategyQA数据集进行∅-shot提示生成的输出:

可以看到针对∅-shot提示“查看示例部分中的示例,并利用该部分中的示例和信息执行以下任务。”,GPT-4 Turbo诚实的指出没有额外的示例可以参考,而GPT-3.5 Turbo在各项任务中受∅-shot提示影响比较大,居然自己现编了一个示例出来。
作者认为,这样的示例可能来自于模型自身的内部知识,即经过训练的权重参数。
由此可以看出,GPT-3.5 Turbo更容易被忽悠,所以∅-shot提示所带来的增益比GPT-4 Turbo大得多,这也从侧面反映出GPT-3.5 Turbo更容易产生幻觉。
∅-shot提示可用于幻觉检测
作者认为∅-shot提示会到来性能提升得力于大模型遵循指令,没有提供样例,就从模型内部生成样例来符合指令的要求,从而引发幻觉。
而GPT-4 Turbo在各项任务中受∅-shot提示引发的幻觉较少。这表明GPT-4 Turbo更擅长处理幻觉,而像∅-shot提示中引入的非事实性短语对该模型的效果较小。这与先前的报告表明GPT-4模型相比GPT-3.5模型不容易发生幻觉的观点一致。
这样看来,可以∅-shot提示不仅可以提高产生幻觉的LLM模型的性能,而且还可以作为确定LLM模型中幻觉程度的检测方法。换句话说,与基线相比,由于∅-shot提示产生的性能提升越高,模型产生幻觉回复的可能性就越大。
从上面的实验结果可以看出,PaLM 2模型是四个模型中最容易产生幻觉的,它在∅-shot提示评测中性能提升是最大的。而进一步针对PaLM 2进行聊天对话的微调的模型则没那么大,因此可以判断PaLM 2 for Chat缓解了部分幻觉。
这种利用∅-shot提示进行模型幻觉程度检测的方法不需要任何专门的幻觉检测数据集,可以应用于各种任务的任何现有基准数据集中。
消融实验
模型大小的影响
本文还探索了∅-shot提示对较小模型的效果,主要在Llama 2 7B和Llama2 7B Chat上进行了实验。
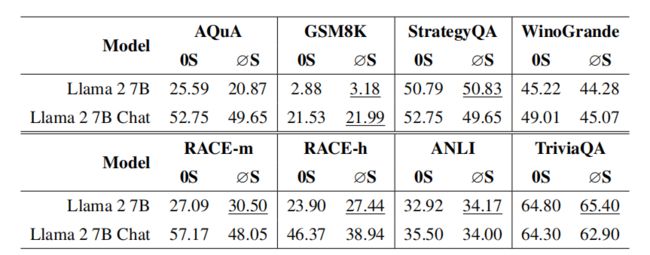

从上图中可以看出,在使用Llama 2 7B时, 除了AQuA和WinoGrande,所有任务的性能都有所 提高。但使用Llama 2 7B Chat仅在GSM8K数据上有效果,其他数据集性能有所下降。
这与PaLM 2和PaLM 2 for Chat呈现出类似的模式,即在同一系列模型中,基础版本相对于聊天版本的性能提升更多,这也说明Llama 2 7B Chat在处理幻觉方面更为出色。这与提出Llama 2的研究相吻合。
混合零样本CoT的∅-shot提示
由于零样本CoT提示(0CoT)显示出性能的显著提升,作者将0CoT与∅-shot提示结合成∅CoT提示。

与原始的0CoT进行比较,结果如下表:

-
与0CoT提示相比,∅CoT提示在大部分任务上失效。这可能是因为这两种提示方法都要求模型逐步进行推理和解释,而我们的∅CoT提示可能会妨碍模型的推理能力,导致其性能劣于0CoT提示。
-
在WinoGrande数据集中,∅CoT提示对于GPT-4 Turbo非常有效。突然的性能提高可能表明该任务很可能需要推理(来自0CoT部分)和无效示例(来自∅-shot)。也就是说,∅CoT提示有可能在更强的模型中突破用于减少幻觉的措施,特别是在需要复杂推理的任务中。
∅-shot提示短语放置位置的影响
作者将短语放置在任务指令之前和提示语末尾进行比较,如下图所示,∅-shot提示放在句首能够展现出更高的效果,除了GSM8K数据集,该数据集要求模型生成任意数值型答案。


作者认为这是因为将内容放在句首展示出更强的条件性强度,这让这些模型在生成输出时更加依赖这一条件。
结论
本文提出了一种假装有示例样本的提示——∅-shot提示,通过这种手段引导模型利用自身的内部知识。另外,作者通过分析发现∅-shot提示也是一个很简单有效的幻觉检测方式。除此之外,作者进行了多种消融研究,探索缩放效应,推理变体,以及提示短语的位置效果和短语中每个组成部分的性能贡献。
未来的研究可以探索将∅-shot提示用于检测LLM中的幻觉以及与其他提示工程技术结合的可能性。

