深入理解DeepLab系列语义分割网络
语义分割是指在像素级别上进行分类,从而转换得到感兴趣区域的掩膜。说起语义分割的发展则肯定绕不开DeepLab系列语义分割网络,该系列网络由谷歌团队提出并发展,在VOC2012等公用语义分割数据集上,取得了较好的效果。
1.DeepLabV1
DeepLabV1[1]于2014年提出,在PASCAL VOC2012数据集上取得了分割任务第二名的成绩。该网络是研究FCN之后发现在FCN中池化层会使得特征图的长和宽不断下降,为了保证之后输出的尺寸不至于太小,FCN网络在第一层就对原图加了100的扩充,但这样会引入一些噪声,特征图尺寸的逐渐减小还会使得在语义分割时进行上采样,但是上采样并不能将丢失的信息全部无损的找回来,若是单单的去掉池化层,则会改变之前可用的结构,就不能再用以前的参数进行优化。因此DeepLab的研究人员提出了空洞卷积来解决这个问题,空洞卷积如图1所示。

图1 空洞卷积示意图
令卷积核为k,输入特征图为x,当空洞卷积作用于特征图时,输出特征图y上的每个位置i有:
![]()
r是空洞率。当r=1时 ,进行标准卷积操作,如图1(a)所示,当r>1时,就是在原图上每隔r-1个像素采样,如r=2时,进行空洞率为1的采样,如图1(b)所示,其中红点的权重不为0,其余的均为0,kernel size 依旧是3,但网络的感受野扩大到了7x7,图1(c)是r=4的卷积,能达到15x15的感受野。这样在不损失池化层的情况下,加大感受野,获得更大范围的信息。
在经过层层上采样和下采样之后,丢失了大量的位置信息,于是DeepLabv1直接采用双线性插值,然后使用全连接条件随机场对得到结果进行锐化处理,其能量函数为
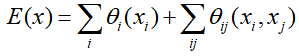
X是分配的像素标签。一元势函数 ![]() ,其中
,其中![]() 是DCNN计算像素i处的标签分配概率。点对势函数为
是DCNN计算像素i处的标签分配概率。点对势函数为

其中 ![]() 。故无论像素点之间的距离有多远,任何两个像素点之间都有一个点对势函数,因此叫做全连接条件随机场。每个
。故无论像素点之间的距离有多远,任何两个像素点之间都有一个点对势函数,因此叫做全连接条件随机场。每个![]() 是由i和j位置像素点特征决定的高斯核函数,并加权
是由i和j位置像素点特征决定的高斯核函数,并加权![]() ,考虑两个像素点之间的位置与颜色,高斯核函数为:
,考虑两个像素点之间的位置与颜色,高斯核函数为:

第一个核函数与像素点位置(p)和颜色强度(I)有关,第二个核函数与位置(p)有关,超参数
![]() 控制高斯核的作用范围。最终模型整体流程如图2所示。
控制高斯核的作用范围。最终模型整体流程如图2所示。

图2 整体流程图
2 DeepLabV2
DeepLabV2[2]在前一代的基础上进行改进,依旧是使用空洞卷积,但主干网络已经替换为ResNet,另外提出了空洞空间金字塔池化(ASPP)结构,如图3所示。

图3 空洞空间金字塔池化结构
其通过在固定的特征图上,使用不同空洞率的空洞卷积并行提取特征,能多比例捕获对象及上下文信息。其次由于V1全连接条件随机场会使得边界信息平滑粗糙,因此对二元势表达式进行更新为:

模型整体流程和图2类似,最终在当时公用语义分割数据集上达到了最优的性能,运行速度为8FPS,系统简单,高效。
3 DeepLabV3
DeepLabV3[3] 去掉了最后的全连接随机条件场,同时进一步探讨了空洞卷积的使用,让其在级联模块和空间金字塔池化的框架下获取更大的感受野,得到更多的信息,还有ASPP模块,由不同采样率的空洞卷积组成,以级联或并联的方式布局。
当存在多尺度物体时,需要多尺度特征图融合,主要是图像金字塔,编码-解码,上下文模块和空间金字塔方法,V3主干网络依旧是resnet, 探讨将空洞卷积作为一种上下文模块和空间金字塔池化的工具,于是涉及通过空洞卷积进一步深入网络模型,如图4所示。

图4 空洞卷积下的深度模型
其中 output stride是输入图像的空间分辨率和输出特征图的空间分辨率的比值。由论文中得,output stride越大,得到得效果越差,因为连续的下采样会降低特征映射的分辨率,细节信息被抽取,这只会语义分割是有害的,结果最好的output stride = 8 却需要占用较多的存储空间。
对于在V2中提出的ASPP模块,并行使用了四种采样率不同的空洞卷积表明了不同尺度采样是有效的。不过V3向其中加入了BN层,虽然不同采样率的空洞卷积确实可以有效捕获多尺度信息,但是随着采样率增加,滤波器的权重在减小,因此V3还在模型最后特征映射上应用了全局平均池化,将结果经过1x1x256卷积再双线性插值上采样得到目标的空间维度。
4 DeepLabV3+
DeepLabV3+[4]是在V3的基础上加入了简单有效的解码模块去细化分割结果,还进一步探讨了Xception模型和ASPP模块,构造了更快更强的编码-解码网络,整体结构如图5所示。

图5 DeepLabV3+结构
深度可分离卷积将一个标准卷积拆分为深度卷积和一个1x1卷积,极大的减少了计算复杂度。特别的,深度卷积独立的为输入特征的每个通道做卷积操作,然后使用1x1的卷积对深度卷积的输出进行通道间进行融合操作,这样就替代了一个标准卷积操作,即融合了空间信息,也融合了不同通道间的信息。V3+则将空洞率和深度可分离卷积结合起来称为空洞可分离卷积,极大的减少了所提出模型的计算复杂度,同时也维持了模型相似或更好的效果。
对于提出的解码模块,其编码模块是整个DeepLabV3,这样在编码层输出的特征先经过4倍双线性插值上采样,然后和编码层中骨干网络中拥有相同尺寸的浅层特征进行通道维度融合,在拼接之前需要对低级别特征进行1x1卷积,目的是减小低级别特征的通道数目,因为低级别特征通常含有大量的通道数目,这样底级别特征的重要性可能会超过解码层输出的富有语义信息的特征并使得训练更加困难。之后,对拼接结果进行了3x3卷积操作去细化特征,并随后又接了一个4倍的双线性插值上采样,得到最后的分割结果。实验证明:当编码层的输出步长为16时可以达到速度和精度的最好的权衡,而输出步长为8时,模型效果略有提升,但也相应增加了额外的计算复杂度代价。
最后是对于Xception的改进,使用一定步长的深度可分离卷积替代了最大池化操作,还有在每一个3x3的深度卷积之后添加额外的BN层和Relu操作,修改后的整体结构如图6所示。
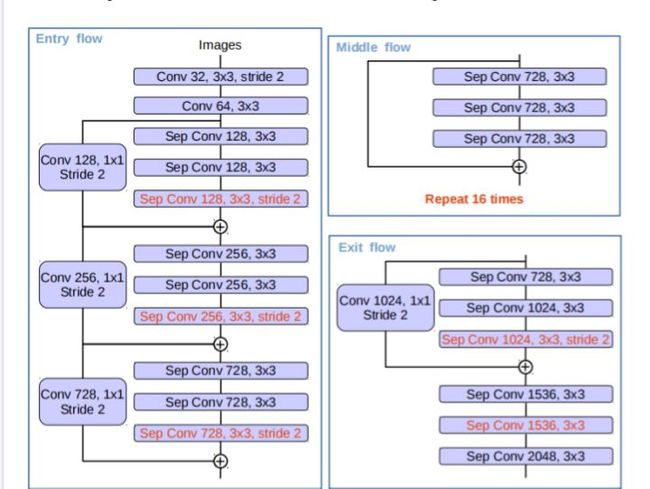
图6 Xception结构
最终该网络在TOP-5%上的错误率仅5.17%,在VOV2012数据集上MIOU达到了89.0%,是先进的表现。[5]
参考
- ^Chen L C, Papandreou G, Kokkinos I, et al. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs[J]. Computer Science, 2014(4):357-361.
- ^L. -C. Chen, G. Papandreou, I. Kokkinos, K. Murphy and A. L. Yuille, "DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 4, pp. 834-848, 2018
- ^Chen L C, Papandreou G, Schroff F, Adam H.: Rethinking atrous convolution for semantic image segmentation.2017, https://doi.org/10.48550/arXiv.1706.05587
- ^Chen L C, Zhu Y, Papandreou G, Schroff F, Adam H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. European Conference on Computer Vision, Berlin, 2018, pp. 833-851.
- ^https://blog.csdn.net/weixin_47658790/article/details/115420207?ops_request_misc=&request_id=&biz_id=102&utm_term=deeplabv3&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-115420207.142^v13^control,157^v14^new_3&spm=1018.2226.3001.418