基于Python 网络爬虫和可视化的房源信息的设计与实现
摘 要
一般来说,在房地产行业,房源信息采集,对企业来说至关重要,通过人工采集数据的方式进行数据收集,既耗时又费力,影响工作效率,还导致信息时效性变差,可靠性偏低,不利于数据分析和决策,而且不好去准确统计目前房地产的存量,往大的说,不利于国家进行房地产宏观调控,往小了说不利于企业和业主快速完成房源交易,降低了交易的频次。而快速获取一个好的房源信息要比找到一个客户更重要,因为一个好的房源信息背后隐藏很多潜在客户,而挖掘了一个客户却不一定就能签单。所以对于成功的房地产从业人员来说,高效的获取房源就是成功的关键,同时也可以实现房源信息汇总,可帮助企业和政府机构及时了解本地房源的最新情况。
基于Python scrapy框架的房源信息采集与可视化系统的出现适应了国家信息化建设的要求,使得房地产工作者和房地产政策制定人员更为高效准确的了解房源信息,节省了不少宝贵时间和大量的人力物力,也使房地产工作者更加方便,也利于企业实现将库存的目的,实现了资源高效利用,不仅盘活了房地产,提高了房源信息的开发和利用,而且实现了房地产降库存、提高房源流转,降低房地产的风险,也利于政府部门制定相应的政策提供数据依据。
本论文重点阐述了房源信息采集与可视化系统的开发过程,以实际运用为开发背景,运用了Python网络爬虫技术,充分保证系统的安全性和稳定性。本系统使用scrapy框架爬取北京链家房源信息,操作简单方便;可视化是通过echart来直接显示,在通过flask轻量化服务器部署展示。通过系统概述、系统分析、系统设计、数据库设计、系统实现这几个部分,详细的说明了系统的开发过程,最后并对整个开发过程进行了总结,该可视化系统主要功能包含北京地图、柱形图、复合柱形图、饼图、折线图等,最后都是通过图表形式部署展示这些房源信息的数据。
关键词:房源信息;信息采集;可视化;Python爬虫;scrapy
1.绪论
1.1 研究背景
随着科技技术的变革,人类社会环境发生了一次又一次的重大变化。各行各业都在科技的冲击下迅速发展,对于房地产来说,从传统的纸质记录房源信息到现在通过软件产品来记录,大大的提升了企业房地产数据采集的工作时间。对于企业来说除了记录房源信息记录外,企业还需要了解不同地区的房源售信息,基于这种情况开发了一个基于Python的房源信息数据采集与可视化系统。
本文基于Python技术和Excel、MySQL,针对北京房源信息数据方向建立了网络爬虫的房源信息数据采集与可视化系统。系统是为了通过大数据对房源信息进行分析,为了最终实现要求,本系统以PyCharm为开发平台。经过细心的调研和衡量,以Python技术为核心去编写后台和实现各业务接口,以echart作为数据的展示,flask轻量化服务器部署展示。
1.2 研究现状
很多时候,无论出于数据分析或产品需求,我们需要从某些网站,提取出我们感兴趣、有价值的内容,但是纵然是进化到21世纪的人类,依然只有两只手,一双眼,不可能去每一个网页去点去看,然后再复制粘贴。所以我们需要一种能自动获取网页内容并可以按照指定规则提取相应内容的程序,这就是爬虫。而爬虫数据获取的基础,经过这么多年的发展,除了面对surfaceweb(即表层Web,由网页沟通,网页之间通过超链接关联)的常用爬虫,各种面对垂直领域和特定主题的爬虫(focusedcrawler)成为热点。目前最常用的爬虫语言是Python爬虫,其中scrapy、beautifulsoup、selenium等常见框架。
这三种框架都有各自的特点:(1)Scrapy:很强大的爬虫框架,可以满足简单的页面爬取(比如可以明确获知url pattern的情况)。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据,是目前房源信息采集常用的一种框架。(2)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载JS。(3)selenium:这是一个调用浏览器的driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。
1.3 目的和意义
本系统解决了房地产从业人员和房地产政策制定者所依赖的数据来源的问题,帮助他们获取更多更有价值的数据。同时,本房地产网站上极有价值的数据,利用现有技术在项目中实现了免登陆、高效率爬取数据,同时针对爬取的数据进行了初步的筛选过滤,去掉多余信息,除了可以节省本地空间之外还方便地产从业人员和房地产政策制定者对数据进行二次清洗、提炼,从而得到更有价值的信息。本系统还针对爬虫的作用机制以及设计模式进行了优化,采用scrapy的技术框架可以提高采集效率,同时因为采用了合适的设计模式,可以及时地将内存中的数据导入到数据库中,极大地减少了内存资源的占用,使爬虫程序在运行期间,尽可能少地占用计算机资源。在辅助flask轻量化的服务器,结合pyecharts库,实现数据大屏可视化展示,让房地产从业人员和房地产政策制定者更直观更细致了解数据信息。
2.系统概述
2.1 系统的相关技术和运行环境
本系统以pycharm、MySQL、SQL数据库语言作为工具。系统概述以系统分析、系统设计、数据库设计、系统实现这几个部分,详细的说明了系统的开发过程。下面对这几种技术和方法进行概述。
-
Pycharm Pycharm 是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理,代码跳转,只能提示,自动完成,单元测试、脚本控制。此外,该IDE提供了一些高级功能,用于支持Django框架下的专业Web开发,同时支持Google App Engine,更酷的是Pycharm支持IronPython。
-
MySQL
由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。MySQL是一个多用户、多线程的关系型数据库管理系统。 工作模式是基于客户机/服务器结构。目前它可以支持几乎所有的操作系统,同时也可以和php完美结合。
简单的来说 ,MySql是一个开放的、快速的、多线程的、多用户的SQL数据库服务器。
3.系统分析
3.1 系统需求分析
3.1.1 房源信息采集
采集房源信息,使用的就是scrapy框架,首先确定爬虫中起始的url构造成request对象通过爬虫中间件传递给调度器,调度器把request传递给下载器,下载器发送请求,获取response响应经过下载中间件反馈给爬虫,爬虫提取url地址,组装成request对象传递给调度器,重复步骤2,爬虫提取数据最后经过管道处理,保存数据,其基本流程如下图。
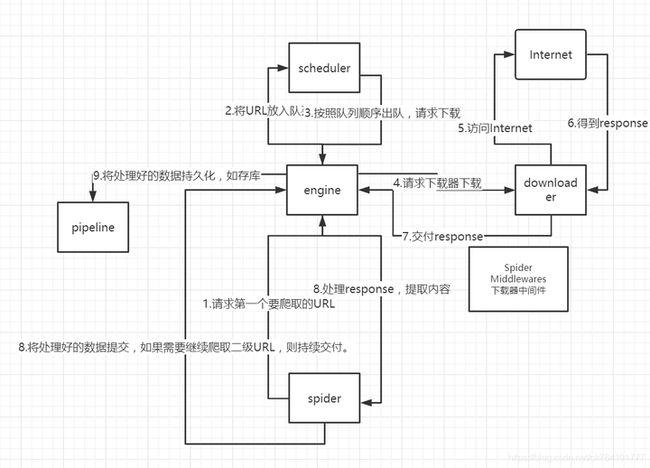
图3-1 scrapy框架数据采集流程图
3.1.2 房源信息保存
经过图3-1流程可以知道,在保存数据环节,本论文使用了三种存储方式,csv、MySQL和json三种格式,当然scrapy框架数据存储的时候,必须要先设定存储的优先级,这样才能保障存储优先顺序不会错乱。基本流程如下图。

图3-2 房源信息存储流程图
3.1.3 房源信息处理
存储完数据,要将数据可视化,必须对数据进行处理,处理成能够直接进行可视化的数据格式,本论文可视化是使用echart进行可视化,其默认的格式是json格式,所以要将数据转换成json格式的数据,为后面的可视化提供数据基础。
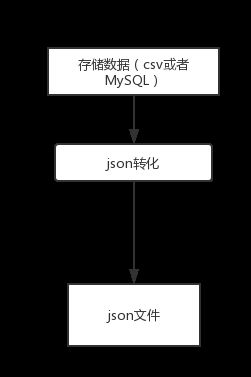
图3-3 房源信息数据处理流程图
3.1.4 房源信息可视化
在处理好数据之后,就将处理好的数据用echart里面的js文件,使用js技术处理成图表展示出来,为最后的可视化部署做准备。

图3-4 房源信息可视化
3.1.5 房源信息可视化部署
经过echart可视化之后,就利用flask部署,实现网页访问,展示可视化后的数据。

图3-5 房源信息部署流程图
3.2 系统需求分析
3.2.1 数据采集
Scrapy框架中的爬虫文件spider先确定采集的链接url,初始链接为‘https://bj.fang.lianjia.com/loupan/pg1’,反爬措施使用浏览器的标头,伪装成浏览器,爬取的数据为:房源名称、面积、房子类型、销售状态、地区、所在乡镇、地址、户型、卖点、单价、总价。
3.2.2数据存储
设置scrapy框架中的setting文件确定数据存储优先级,在管道piplines文件中设置存储格式csv、json、MySQL。
3.2.3 数据处理
文件中,定义了一个文件,初始化的时候产生详细的数据,图表的数据用json格式保存,在返回给echarts的时候js加载json文件形式。
3.2.4 数据可视化
对json文件数据进行可视化呈现。
3.2.5 数据部署
启动后端flask服务器,部署访问可视化页面
4.系统设计
4.1 系统总体设计
4.1.2 系统功能模块划分
按照房源信息采集与可视化系统目前的需要和系统需求分析的情况,房源信息采集与可视化系统分为以下5大模块:(1)数据采集;(2)数据存储;(3)数据处理;(4数据可视化;(5)数据部署。其主要功能模块设计如下图:
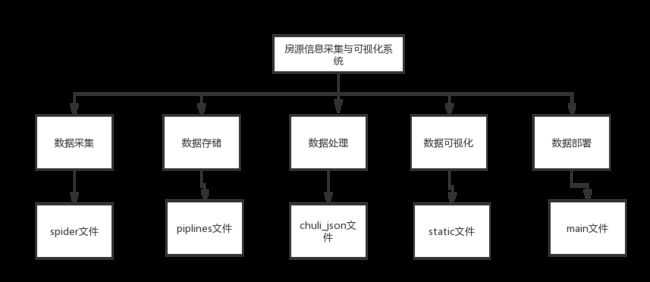
图4-1 房源信息采集与可视化系统模块图
4.2 系统数据库设计
3.2.1 主要数据表结构设计
表3-1 北京新房数据表
| 序号 |
列名 |
数据类型 |
长度 |
是否为主键 |
说明 |
|---|---|---|---|---|---|
| 1 |
title |
varchar |
50 |
否 |
|
| 2 |
area |
varchar |
50 |
否 |
|
| 3 |
house_dizhi |
varchar |
50 |
否 |
|
| 4 |
house_huxing |
varchar |
50 |
否 |
|
| 5 |
house_leixing |
varchar |
50 |
否 |
|
| 6 |
house_maidian |
varchar |
50 |
否 |
|
| 7 |
house_qu |
varchar |
50 |
否 |
|
| 8 |
house_xiangzhen |
varchar |
50 |
否 |
|
| 9 |
house_xiaoshou |
varchar |
50 |
否 |
|
| 10 |
money_danjia |
varchar |
50 |
否 |
|
| 11 |
money_zongjia |
varchar |
50 |
否 |
5.系统实现
5.1 数据采集
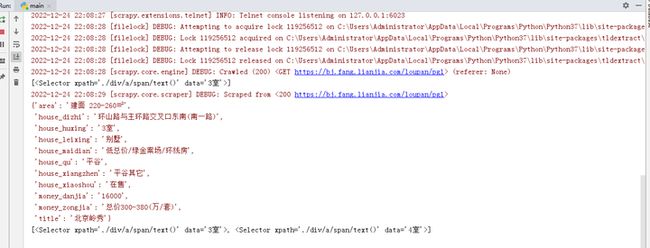
图5-1 数据采集
主要代码bj.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import scrapy
import time
from lianjia_bj.items import LianjiaBjItem
import random
class BjSpider(scrapy.Spider):
name = 'bj'
# allowed_domains = ['bj.lianjia.com'] # 爬取的域,防止跳转到其他链接
start_urls = ['https://bj.fang.lianjia.com/loupan/pg1'] # 目标URL
def parse(self, response):
divs = response.xpath('/html/body/div[3]/ul[2]/li')
for div in divs:
item = LianjiaBjItem()
item['title'] = div.xpath('./div/div[1]/a/text()')[0].extract()
item['area'] = div.xpath('./div/div[3]/span/text()')[0].extract()
item['house_leixing'] = div.xpath('./div/div[1]/span[1]/text()')[0].extract()
item['house_xiaoshou'] = div.xpath('./div/div[1]/span[2]/text()')[0].extract()
item['house_qu'] = div.xpath('./div/div[2]/span[1]/text()')[0].extract()
item['house_xiangzhen'] = div.xpath('./div/div[2]/span[2]/text()')[0].extract()
item['house_dizhi'] = div.xpath('./div/div[2]/a/text()')[0].extract()
house_huxing1=div.xpath('./div/a/span/text()')
house_maidian1 = div.xpath('./div/div[5]/span/text()')
item['money_danjia'] = div.xpath('./div/div[6]/div[1]/span[1]/text()')[0].extract()
item['money_zongjia'] = div.xpath('./div/div[6]/div[2]/text()')[0].extract()
if len(house_huxing1)==1:
item['house_huxing']=house_huxing1[0].extract()
elif len(house_huxing1)==2:
item['house_huxing'] = house_huxing1[0].extract()+'/'+house_huxing1[1].extract()
elif len(house_huxing1) == 3:
item['house_huxing'] = house_huxing1[0].extract() + '/'+house_huxing1[1].extract()+ '/'+house_huxing1[2].extract()
elif len(house_huxing1) == 4:
item['house_huxing'] = house_huxing1[0].extract() + '/'+house_huxing1[1].extract()+ '/'+house_huxing1[2].extract()+ '/'+house_huxing1[3].extract()
else:
item['house_huxing'] = house_huxing1[0].extract()
if len(house_maidian1)==1:
item['house_maidian']=house_maidian1[0].extract()
elif len(house_maidian1)==2:
item['house_maidian'] = house_maidian1[0].extract()+'/'+house_maidian1[1].extract()
elif len(house_maidian1) == 3:
item['house_maidian'] = house_maidian1[0].extract() + '/'+house_maidian1[1].extract()+ '/'+house_maidian1[2].extract()
elif len(house_maidian1) == 4:
item['house_maidian'] = house_maidian1[0].extract() + '/'+house_maidian1[1].extract()+ '/'+house_maidian1[2].extract()+ '/'+house_maidian1[3].extract()
else:
item['house_maidian'] = house_maidian1[0].extract()
# print(title,area,house_dizhi,house_huxing,house_leixing,house_maidian,house_qu,house_xiangzhen,house_xiaoshou,money_danjia,money_zongjia)
print(house_huxing1)
time.sleep(1)
yield item
next_url = 'https://bj.fang.lianjia.com/loupan/pg{page}'
# time.sleep(random(1,3))
for page in list(range(2, 51)): # 控制页数
yield scrapy.Request(next_url.format(page=page),callback=self.parse) # 回调
5.2 数据存储
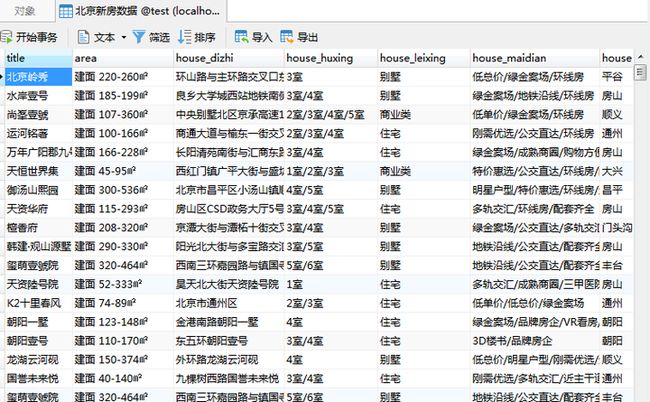
图5-2 数据存储
主要代码如下:
Setting.py
ITEM_PIPELINES = {
'lianjia_bj.pipelines.LianjiaBjPipeline_mysql': 300,
'lianjia_bj.pipelines.LianjiaBjPipeline_json': 200,
'lianjia_bj.pipelines.LianjiaBjPipeline_csv': 100,
}
Piplines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import scrapy
from itemadapter import ItemAdapter
import json
from openpyxl import Workbook
import pymysql
class LianjiaBjPipeline_json(object): # json格式
def __init__(self):
self.file = open('bj_job.json','w',encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item),ensure_ascii=False)+'\n'
self.file.write(content)
return item
class LianjiaBjPipeline_csv(object): # Excel
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['title','area','house_dizhi','house_huxing','house_leixing','house_maidian','house_qu','house_xiangzhen','house_xiaoshou','money_danjia','money_zongjia'])
def process_item(self, item, spider):
line = [item['title'],item['area'], item['house_dizhi'], item['house_huxing'],item['house_leixing'],item['house_maidian'], item['house_qu'], item['house_xiangzhen'],item['house_xiaoshou'],item['money_danjia'], item['money_zongjia']]
self.ws.append(line)
self.wb.save('bjxinfang.xlsx')
return item
def close_spider(self, spider):
self.wb.save('bjxinfang.xlsx')
class LianjiaBjPipeline_mysql(object):
"""
数据库pipline
"""
def __init__(self):
# 连接MySQL数据库
self.connect = pymysql.connect(host='localhost', user='root', password='root', db='test', port=3306)
self.cursor = self.connect.cursor()
self.cursor.execute('drop table if exists 北京新房数据')
sql = """CREATE TABLE `北京新房数据`(
`title` varchar (500) NOT NULL,
`area` varchar (50) NOT NULL,
`house_dizhi` varchar (500) NOT NULL,
`house_huxing` varchar (500) NOT NULL,
`house_leixing` varchar (500) NOT NULL,
`house_maidian` varchar (500) NOT NULL,
`house_qu` varchar (500) NOT NULL,
`house_xiangzhen` varchar (500) NOT NULL,
`house_xiaoshou` varchar (500) NOT NULL,
`money_danjia` varchar (500) NOT NULL,
`money_zongjia` varchar (500) NOT NULL
);"""
self.cursor.execute(sql)
print("创建北京新房数据表成功.")
def process_item(self, item, spider):
self.cursor.execute('insert into 北京新房数据(title,area,house_dizhi,house_huxing,house_leixing,house_maidian,house_qu,house_xiangzhen,house_xiaoshou,money_danjia,money_zongjia) VALUES ("{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")'.format(item['title'],item['area'], item['house_dizhi'], item['house_huxing'],item['house_leixing'],item['house_maidian'], item['house_qu'], item['house_xiangzhen'],item['house_xiaoshou'],item['money_danjia'], item['money_zongjia']))
self.connect.commit()
return item
def close_spider(self, spider):
self.cursor.close()
# 关闭游标
self.connect.close()
5.3 数据处理
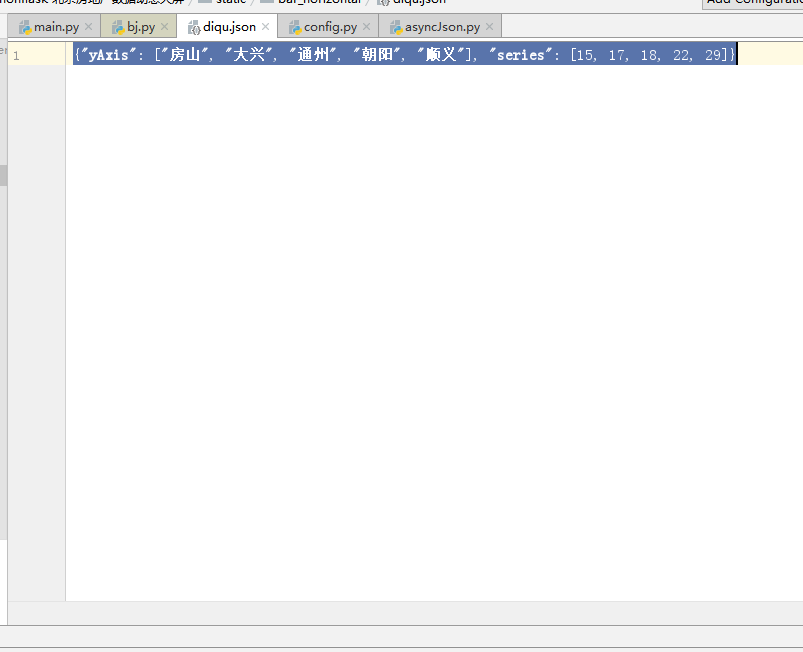
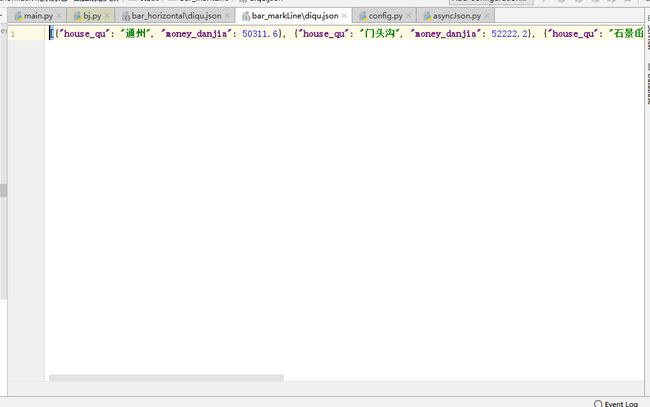
图5-3 数据处理
主要核心代码:
import pandas as pd
import json
data=pd.read_excel(r'C:\Users\Administrator\Desktop\crawl-chain-home-network链家scrapy\crawl-chain-home-network-data-master\lianjia_bj\bjxinfang.xlsx')
data.drop_duplicates(inplace=True)
diqu=data.groupby(by=['house_qu'])['title'].count().reset_index().sort_values(['title'])
print(diqu)
json_split = diqu['house_qu'].tolist()[-5:]
json_split1 = diqu['title'].tolist()[-5:]
dic={"yAxis":json_split,"series":json_split1}
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\bar_horizontal\diqu.json','w',encoding='utf-8')
json.dump(dic,file,ensure_ascii=False) diqu1=data.groupby(by=['house_qu'])['money_danjia'].mean().reset_index().round(1).sort_values(['money_danjia'])[-6:]
json_records = diqu1.to_dict(orient = "records")
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\bar_markLine\diqu.json','a',encoding='utf-8')
json.dump(json_records,file,ensure_ascii=False)
print(json_records)
for i in range(data.shape[0]):
if data.iloc[i,4]=='商业类':
data.iloc[i,4]='商业'
else:
pass
fenlei=data.groupby(by=['house_leixing'])['title'].count().reset_index().sort_values(['title'])
json_split = fenlei['house_leixing'].tolist()
json_split1 = fenlei['title'].tolist()
dic={"xAxis":{"data":json_split},"series":{"data":json_split1}}
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\bar_ROA\diqu.json','a',encoding='utf-8')
json.dump(dic,file,ensure_ascii=False)
print(fenlei)
jiage1=(data[data['house_qu']=='顺义']).groupby(by=['house_leixing'])['money_danjia'].mean().reset_index().round(1)
jiage2=(data[data['house_qu']=='房山']).groupby(by=['house_leixing'])['money_danjia'].mean().reset_index().round(1)
jiage3=(data[data['house_qu']=='大兴']).groupby(by=['house_leixing'])['money_danjia'].mean().reset_index().round(1)
list=[]
list.append(jiage1['money_danjia'].tolist())
list.append(jiage2['money_danjia'].tolist())
list.append(jiage3['money_danjia'].tolist())
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\bar_stacked\diqu.json','w',encoding='utf-8')
json.dump(list,file,ensure_ascii=False)
print(jiage1,jiage2,jiage3)
maidian=[] data['house_maidian1']=(data['house_maidian'].str).split('/',expand=True)[0] data['house_maidian2']=(data['house_maidian'].str).split('/',expand=True)[1]
data['house_maidian3']=(data['house_maidian'].str).split('/',expand=True)[2]
data['house_maidian4']=(data['house_maidian'].str).split('/',expand=True)[3]
maidian.extend(data['house_maidian1'].tolist())
maidian.extend(data['house_maidian2'].tolist())
maidian.extend(data['house_maidian3'].tolist())
maidian.extend(data['house_maidian4'].tolist())
a=set(maidian)
list1=[]
for i in a:
n=0
for j in maidian:
if i==j:
n+=1
else:
pass
if n>30 and n<90:
dic={"value":n,"name":i}
list1.append(dic)
else:
pass
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\funnel\diqu.json','w',encoding='utf-8')
json.dump(list1,file,ensure_ascii=False)
print(list1)
data['money_zongjia']=(data['money_zongjia'].str[2:-5])
data['money_zongjia']=data['money_zongjia'].str.split('-',expand=True)[0].astype('int')
diqu1=data.groupby(by=['house_qu'])['money_zongjia'].mean().reset_index().round(1).sort_values(['money_zongjia'])
json_split = diqu1['house_qu'].tolist()
json_split1 = diqu1['money_zongjia'].tolist()
dic={"xAxis":{"data":json_split},"series":{"data":json_split1}}
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\line_area_chart\diqu.json','w',encoding='utf-8')
json.dump(dic,file,ensure_ascii=False)
print(diqu1)
huxing=[]
data['house_huxing1']=(data['house_huxing'].str).split('/',expand=True)[0]
data['house_huxing2']=(data['house_huxing'].str).split('/',expand=True)[1]
data['house_huxing3']=(data['house_huxing'].str).split('/',expand=True)[2]
data['house_huxing4']=(data['house_huxing'].str).split('/',expand=True)[3]
huxing.extend(data['house_huxing1'].tolist())
huxing.extend(data['house_huxing2'].tolist())
huxing.extend(data['house_huxing3'].tolist())
huxing.extend(data['house_huxing'].tolist())
a=set(huxing)
list1=[]
for i in a:
n=0
for j in huxing:
if i==j:
n+=1
else:
pass
if n>14 and n<163:
dic={"value":n,"name":i}
list1.append(dic)
else:
pass
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\line_visualMap\diqu.json','w',encoding='utf-8')
json.dump(list1,file,ensure_ascii=False)
print(list1)
huxing=[]
data['house_huxing1']=(data['house_huxing'].str).split('/',expand=True)[0]
data['house_huxing2']=(data['house_huxing'].str).split('/',expand=True)[1]
data['house_huxing3']=(data['house_huxing'].str).split('/',expand=True)[2]
data['house_huxing4']=(data['house_huxing'].str).split('/',expand=True)[3]
huxing.extend(data['house_huxing1'].tolist())
huxing.extend(data['house_huxing2'].tolist())
huxing.extend(data['house_huxing3'].tolist())
huxing.extend(data['house_huxing'].tolist())
a=set(huxing)
list1=[]
for i in a:
n=0
for j in huxing:
if i==j:
n+=1
else:
pass
if n>14 and n<163:
dic={"value":n,"name":i}
list1.append(dic)
else:
pass
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\pie_source\diqu.json','w',encoding='utf-8')
json.dump(list1,file,ensure_ascii=False)
print(list1)
mianji=[]
# data['area']=(data['area'].str).split(' ',expand=True)[1]
# data['area']=data['area'].str[:-1]
# data['area1']=(data['area'].str).split('-',expand=True)[0]
# data['area2']=(data['area'].str).split('-',expand=True)[1]
# for i in range(data.shape[0]):
# if data.iloc[i,11] is None:
# data.iloc[i, 11]='0'
# if data.iloc[i, 12] is None:
# data.iloc[i, 12] = '0'
# else:
# pass
# data['area1']=data['area1'].astype('int')
# data['area2']=data['area2'].astype('int')
# data0=(data[data['area1']<100][data['area2']<200])['area1'].count()
# data11=(data[data['area1']>100][data['area2']<200])['area1'].count()
# data12=(data[data['area1']>200][data['area2']<300])['area1'].count()
# data13=(data[data['area1']>200][data['area2']>300])['area1'].count()
# list=[]
# list.append(data0)
# list.append(data11)
# list.append(data12)
# list.append(data13)
# list2=['min<100,max<200','min>100,max<200','min>200,max<300','min>200,max>300']
# print(list2)
# list1=[]
# for i in range(len(list)):
# dic={"value":float(list[i]),"name":list2[i]}
# list1.append(dic)
# file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\pie_source_rose\diqu.json','w',encoding='utf-8')
# json.dump(list1,file,ensure_ascii=False)
# print(list1)
ditu=[]
data['area']=(data['area'].str).split(' ',expand=True)[1]
data['area']=data['area'].str[:-1]
data['area1']=(data['area'].str).split('-',expand=True)[0]
data['area1']=data['area1'].astype('int')
data['money_zongjia']=(data['money_zongjia'].str[2:-5])
data['money_zongjia']=data['money_zongjia'].str.split('-',expand=True)[0].astype('int')
diqu=data.groupby(by=['house_qu'])['title'].count().reset_index()
diqu1=data.groupby(by=['house_qu'])['area1'].sum().reset_index()
diqu2=data.groupby(by=['house_qu'])['money_zongjia'].sum().reset_index()
list_1=diqu2['money_zongjia'].tolist()
list_2=diqu1['area1'].tolist()
list_3=diqu['title'].tolist()
list_4=diqu['house_qu'].tolist()
for i in range(len(list_1)):
dic={"name":list_4[i]+'区',"confirmAdd":list_3[i],"confirm":list_2[i],"nowConfirm":list_1[i]}
ditu.append(dic)
file=open(r'C:\Users\Administrator\Desktop\基于Python动态大屏\static\map_china_map\diqu.json','w',encoding='utf-8')
json.dump(ditu,file,ensure_ascii=False)
print(ditu)
5.4 数据可视化
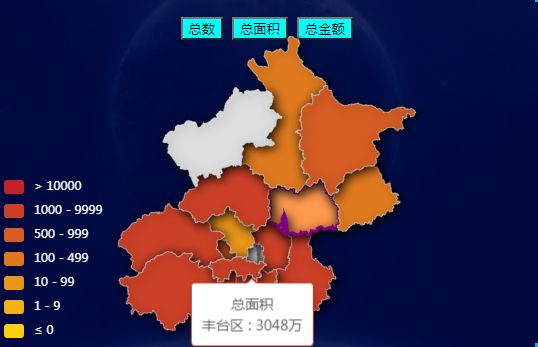
图5-4 数据可视化
主要代码:
Loader.js
// 加载主题,必须在echarts.init之前。
var gTheme = getQueryVariable("theme");
themeUrl = "theme/js/" + gTheme + ".js";
addScript(themeUrl);
// 加载地图依赖文件
var path_map_china_map = "map_china_map/";
addScript(path_map_china_map + "bmap.min.js");
addScript(path_map_china_map + "beijing.js");
addScript(path_map_china_map + "init.js");
// event事件,自动高亮地图各地区
// 高亮表盘事件
function emphasisData(container) {
var currentIndex = -1;
setInterval(function () {
var myChart = echarts.init(document.getElementById(container));
var dataLen = 0;
try {
dataLen = myChart.getOption().dataset[0]["source"].length;
} catch {
try {
dataLen = myChart.getOption().series[0]["data"].length;
} catch {
return;
}
}
// 取消之前高亮的图形
myChart.dispatchAction({
type: "downplay",
seriesIndex: 0,
dataIndex: currentIndex,
});
currentIndex = (currentIndex + 1) % dataLen;
// 高亮当前图形
myChart.dispatchAction({
type: "highlight",
seriesIndex: 0,
dataIndex: currentIndex,
});
// 显示 tooltip
myChart.dispatchAction({
type: "showTip",
seriesIndex: 0,
dataIndex: currentIndex,
});
}, 1000);
}
$(document).ready(function () {
var container = "container_8";
init_echart_map_china_map(container);
async_echart_china(
container,
path_map_china_map + "diqu.json",
"confirm"
);
// 定时5min执行数据更新函数
setInterval(function () {
async_echart_china(
container,
path_map_china_map + "diqu.json",
"confirm"
);
}, 300000);
emphasisData(container);
});
5.5 数据部署

图5-5 flask数据部署
主要代码:
# -*- coding:utf-8 -*-
import io
import os
import sys
from time import sleep
import urllib
import json
from flask import Flask
# 导入线程模块
import threading
# 导入动态修改数据模块
import asyncJson
import config
app = Flask(__name__, static_folder="static", template_folder="template")
@app.route('/')
def hello_world():
return 'Hello World!'
# 主程序在这里
if __name__ == "__main__":
# 开启线程,触发动态数据
a = threading.Thread(target=asyncJson.loop)
a.start()
# 开启 flask 服务
app.run(host='0.0.0.0', port=88, debug=True)
5.总结
5.1 总结
在这次毕业设计中,我们使用了scrapy框架,选择MySQL作为数据库,flask进行可视化部署访问。在设计开始之初,我也在苦恼于系统的逻辑功能的具体实现,因为我对于房源信息采集与可视化的概念还较为模糊,其间我也查询了大量的网上资料,清楚了解实际生活中房源信息采集与可视化主要面对的采集和可视化需要完成的基本功能。
虽然在这过程中也遇到了许多的困难,主要有系统逻辑功能不合适和系统设计中出错,当在自己查阅资料无法解们决之时,我们也会与同学和老师进行请教和讨论,所以在这个过程之中,也让我清楚的认识到自己的不足以及团队的力量才是最大,以后不论是在学习还是工作中,都要融入到集体之中,那样自己才会成长的更快。
当然,在此次设计中,仍然存在着很多的不足,本来之前我们想让其系统可以更为完美的实现集采集可视化于一体,但是也因为时间的不足以及本人的能力有限,并未完成,我们希望自己在以后的学习中继续完善,使这个系统更为的贴近实际的操作。
参考文献
[1] 马联帅. 基于Scrapy的分布式网络新闻抓取系统设计与实现[D]. 西安: 西安电子科技大学, 2015.
[2] 张笑天. 分布式爬虫应用中布隆过滤器的研究[D]. 沈阳: 沈阳工业大学, 2017.
[3] 安子建. 基于Scrapy框架的网络爬虫实现与数据抓取分析[D].长春: 吉林大学, 2017.
[4]马宁 基于Python的网站管理系统分析与设计[D].云南大学,2017.
[5]求是科技 Python信息管理系统开发实例导航[M].人民邮店出版社.2015
[6]杨宗志 Python入门与实作[M].科学出版社,2018
[7]曹锰 舒新峰 C#与Python程序设计[M].西安交通大学出版社,2017
[8]虞益诚 Mysql 2000[M].中国铁道出版社,2019
[9]董征宇 我国中小豆瓣电影教练电子商务盈利策略探析[J].中国商贸,2018,22:94-95
[10]张爱军 电子商务技术的创新发展趋势[J].电脑知识与技术,2016,26:61-67
[11]马桂林 中小音乐豆瓣电影教练经销商电子商务管理系统的设计[J].价值工程,2018,23:148-149
[12]蔡翔宇 电子商务与计算机网络应用[J].计算机应用研究,2017,2:366
[13]西尔伯沙茨(Silberschatz.A.) 计算机科学丛书:数据库系统概念(原书第6版)[M]. 机械工业出版社,2017,03..
[14]萨师煊 王珊 数据库系统概论[M].北京:高等教育出版社,2017:10-180.
[15] 夏伍珍.现行高校教材管理存在的问题及改革对策[J]. 产业与科技论坛. 2008(04)
[16] 吕炘.浅论网络环境下的高校教材管理工作[J]. 东莞理工学院学报. 2008(02)
[17] 杨守波. 基于WEB的高校教材管理系统的设计与实现[D]. 电子科技大学 2011
[18] 刘宁. 高校教材管理及其评价系统的研究与应用[D]. 华北电力大学 2011
[19] 伍轶群. 高校教材管理系统设计与实现[D]. 电子科技大学 2010
[20] 潘锦平.软件系统开发技术[M].西安:西安电子科大出版社,2002
[21] 李利锋.基于 Web 的高校教材管理系统的开发[J].山西农业大学学报:自然科学版,2008,28(4):474-477.
[22] 邓永海,李朝荣,邓梅.基于主/辅系统架构的高校教材订发模块的分析与设计[J].计算机与现代化,2011(5):141-143.
[23] 徐庆红. 高校教材管理网络化建设的思考与实践[J]. 南京财经大学学报. 2008(06)
[24] 张永军,张碧如. 高校教材信息化管理的创新和实践[J]. 中国成人教育. 2008(07)