【计算机视觉】从数字图像处理到计算机视觉的大致发展历程
引言:出于一个很偶然的机会,最近开始进入计算机视觉的领域之中,故因此对这个领域进行一些总结记录。总的来说,这是一个十分复杂且年轻的领域,尚有许多问题有待解决。
1.研究生物视觉工作原理
早在二战结束后20年,就有很多科学家开始研究生物的视觉是如何进化而来的,它的运作原理是什么。其实眼睛的进化过程目前也是一个未解之谜(目前研究发现出了多个不同进化分支,最终都进化成眼睛的模样),它是如何和大脑连接并有效运作的,人们尚未能得知其中奥秘。
初入数字图像处理和计算机视觉的朋友不必深究其中奥秘,我们只需要知道这是一个目前还有很多未解之谜的科学领域。
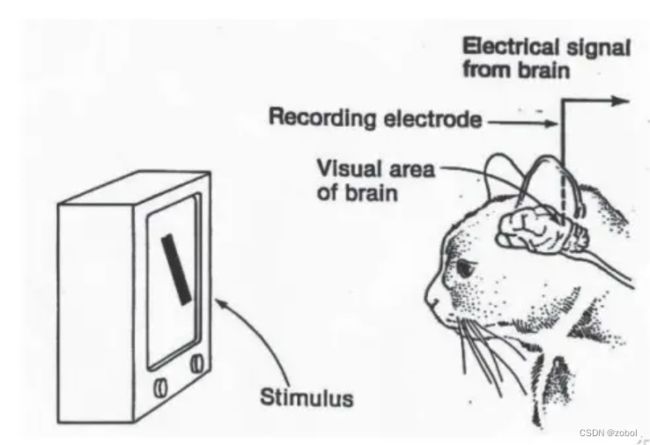
人们总是在探索着他们所处世界中的万事万物—这其中当然包括人类自身。20世纪50年代左右,生物学家们做了很多努力来试图理解动物的视觉系统,其中比较有名的是Hubel和Wiesel的一些研究成果。他们从电生理学的角度来分析猫(据说选择猫的原因在于它和人类的大脑比较相近)的视觉皮层系统,从中发现了视觉通路中的信息分层处理机制,并提出了感受野的概念,他们也因此获得了诺贝尔生理学或医学奖。
1959年,神经生理学家David Hubel和Torsten Wiesel通过猫的视觉实验,首次发现了视觉初级皮层神经元对于移动边缘刺激敏感,发现了视功能柱结构,为视觉神经研究奠定了基础——促成了计算机视觉技术40年后的突破性发展,奠定了深度学习之后的核心准则。
2. 卫星遥感和医学的发展需求
从上个世界1950年代开始,当时的世界对数字图像处理的需求就开始高速增长,主要来自于卫星拍摄的大量高清图像和医学领域的三维重建。
随着冷战各国的太空技术进步,大量卫星拍摄处理的数据需要进行处理,这一阶段主要是一些图像增强的需求。很多滤波手段都是这一时期提出并应用的。此时,这一领域还不能被称为计算机视觉,称为数字图像处理比较合适。
1959年,Russell和他的同学研制了一台可以把图片转化为被二进制机器所理解的灰度值的仪器——这是第一台数字图像扫描仪,处理数字图像开始成为可能。
1972年,亨斯菲尔德爵士(Sir. Godfrey Newbold Hounsfield)在英国EMI实验室进行了相关的计算机和重建技术的研究并取得显著突出,发明了CT扫描仪。
CT技术的发明,代表着计算机视觉中的三维领域开始逐步应用。
3.计算机视觉理论的出现-第一位计算机视觉博士
在1960年左右,很多科学家就已经不满足于简单地处理卫星图像,做一些滤波,数据增强工作。当时计算机的发展已经开始蓬勃起来(再过10年,C++之父就要到伦敦读博,顺便创造C++语言了),许多人都在考虑如何用计算机来进行识别,也就是模仿我们人类去识别物体类型。
1965年, Lawrence Roberts《三维固体的机器感知》描述了从二维图片中推导三维信息的过程。——现代计算机视觉的前导之一,开创了理解三维场景为目的的计算机视觉研究。他对积木世界的创造性研究给人们带来极大的启发,之后人们开始对积木世界进行深入的研究,从边缘的检测、角点特征的提取,到线条、平面、曲线等几何要素分析,到图像明暗、纹理、运动以及成像几何等,并建立了各种数据结构和推理规则。
这位叫Lawrence Roberts的博士被认为是计算机视觉的先驱,许多文章介绍这位是世界上第一位计算机视觉博士,不过其实他拿的是MIT的电气博士学位,后半生的主要工作在互联网协议的搭建上。
不过他的论文《Machine perception of three-dimensional solids》三维固体的机器感知,确实是公认的开创了计算机视觉领域。
当时,Dr. L.G. Roberts的导师Prof. P. Elias买了一个相机,然后跟Roberts说: "我们现在有一台电脑,也有一个相机,给你一个暑假的时间,把这个电脑装上眼睛(相机),然后让它像人类一样感知这个世界。" Roberts费尽九牛二虎之力, 花了数年时间,终于实现了通过二维图形反求物体的三维结构,”草草“结束了这个”暑假活“
当时Lawrence Roberts遇到的难点之一,就是计算机的计算力不够,导致图像算法计算难以被复现。不过这篇文章,现在也可以下载,版权已经失效了。
Machine perception of three-dimensional solids -MIT
4.1970,1980年代,计算机视觉的理论体系构建
许多计算机视觉的理论和项目开始在MIT的实验室出现,此时早期AI技术已经被应用到计算机视觉领域,从此数字图像处理正式进阶成为了计算机视觉,科学家的研究重点就转为了如何像人类一样识别图像中的物体。
1982年,David Marr发表了有影响的论文-“愿景:对人类表现和视觉信息处理的计算研究”。基于Hubel和Wiesel的想法视觉处理不是从整体对象开始, David介绍了一个视觉框架,其中检测边缘,曲线,角落等的低级算法被用作对视觉数据进行高级理解的铺垫。同年《视觉》(Marr, 1982)一书的问世,标志着计算机视觉成为了一门独立学科。
到了1990年,计算机视觉的理论体系已经基本构建完毕。
1977年David Marr在MIT的AI实验室提出了,计算机视觉理论(Computational Vision),这是与 Lawrence Roberts当初引领的积木世界分析方法截然不同的理论。计算机视觉理论成为80年代计算机视觉重要理论框架,使计算机视觉有了明确的体系,促进了计算机视觉的发展。
20世纪80年代,逻辑学和知识库等理论在人工智能领域占据了主导地位。人们试图建立专家系统来存储先验知识,然后与实际项目中提取的特征进行规则匹配。这种思想也同样影响了计算机视觉领域,于是诞生了很多这方面的方法。例如,David G. Lowe在论文“Three-Dimensional Object Recognition from Single Two-Dimensional Images”中提出了基于知识的视觉(Knowledge-based Vision)的概念
5.1990年代,商业化工业化困难重重
1982年 日本COGEX公司于生产的视觉系统DataMan,是世界第一套工业光学字符识别(OCR)系统。
但是,大部分计算机视觉算法,还是无法从实验室走出,人们不得不寻找其他办法,神经网络开始进入计算机视觉领域。
此时计算机视觉虽然已经发展了几十年,但仍然没有得到大规模的应用,很多理论还处于实验室的水平,离商用要求相去甚远。人们逐渐认识到计算机视觉是一个非常难的问题,以往的尝试似乎都过于“复杂”,于是有的学者开始“转向”另一个看上去更简单点儿的方向—图像分割(Image Segmentation)。后者的目标在于运用一些图像处理方法将物体分离出来,以此作为图像分类的第一步。
1997年,伯克利教授Jitendra Malik(以及他的学生Jianbo Shi)发表了一篇论文,描述了他试图解决感性分组的问题。研究人员试图让机器使用图论算法将图像分割成合理的部分(自动确定图像上的哪些像素属于一起,并将物体与周围环境区分开来)
1999年, David Lowe 发表《基于局部尺度不变特征(SIFT特征)的物体识别》,标志着研究人员开始停止通过创建三维模型重建对象,而转向基于特征的对象识别。
6.21世纪的第一个十年,机器学习兴起,许多工业化成果出现。
Paul Viola和Michael Johns等人利用Adaboost算法出色地完成了人脸的实时检测,并被富士公司应用到商用产品中。
然后,大量的特征算法被提出,计算机视觉进入了大规模工业化和商业化阶段,国内最早应该是钢铁行业比较多?目前能查到一本书《计算机科学与技术前沿研究丛书:机器视觉表面缺陷检测技术及其在钢铁工业中的应用》。
7.21世纪的第二个十年,CNN兴起,超大型数据库出现
① 计算机运算能力呈现指数级的增长。
② ImageNet、PASCAL等超大型图片数据库(见图19-14)使得深度学习训练成为可能(注:大型图片数据库虽然在2000年后期就已经出现了,但真正大放异彩还是在最近十年),同时,业界一些极具影响力的竞赛项目(例如ILSVRC)激励了全世界范围内的学者们竞相加入,从而催生了一个又一个优秀的深度学习框架。

后记:
说实话作为初学者,我们去搞懂什么是特征算法,它们的本质原理是什么,其实是不太实际的,也没有公司会允许职工花一年时间去学习这个。很多时候,我觉得很多时候不要把自己当初计算机视觉科学家去工作,很多时候觉得要学会做一个好“工人”,好“技师”。
这一行现在学的人也多,高学历人才也多,需求也大,但产品复用也方便。未来肯定是一小撮专家级程序员,带着一大堆工人级别程序员来做。不要一入门,就觉得能赚很多钱,已经不是15年的计算机界了。
2023.5.15 写于中国深圳