【C++编程调试秘籍】| 总结归纳要点
文章目录
-
- 一、编译器是捕捉缺陷的最好场合
-
- 1 如何使用编译器捕捉缺陷
- 二、在运行时遇见错误该如何处理
-
- 1 该输出哪些错误信息
- 2 执行安全检查则会减低程序效率,该如何处理呢
- 3 当运行时遇到错误时,该如何处理
- 4 结合Backtrace的安全检查
- 四、索引越界
-
- 1 动态数组
- 2 静态数组
- 3 多维数组
- 5 指针运算
- 6 无效的指针、引用和迭代器
- 七、未初始化的变量
-
- 1 初始化的数值
- 2 未初始化的布尔值
- 八、内存泄漏
-
- 1 引用计数指针
- 2 作用域指针
- 3 用智能指针实行所有权
- 九、解引用NULL指针
- 十、拷贝构造函数和赋值操作符
- 十一、避免在析构函数中编写代码
- 十二、怎样编写一致的比较操作符
- 十三、使用标准C函数库的错误
- 十四、基本的测试原则
- 十五、调试错误的策略
- 十六、使代码更容易调试
一、编译器是捕捉缺陷的最好场合
原因:
- 可以准确的看到缺陷时发生在哪一行、哪一个文件、以及错误的描述;
- 节省时间;
1 如何使用编译器捕捉缺陷
- 可以新增一项安全检查,确保传递给函数的值必须位于指定区域内;
新增安全检查
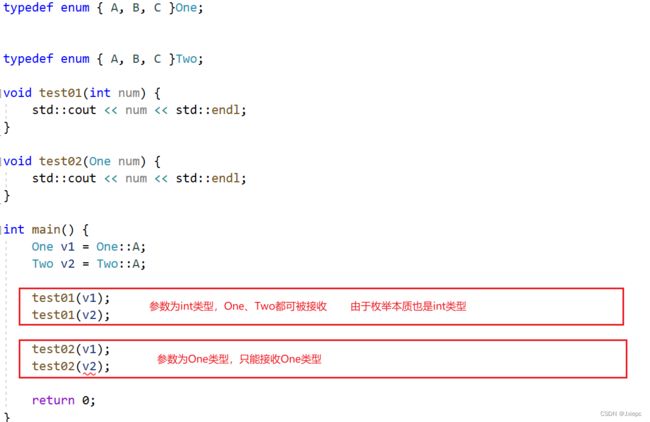
- 禁止隐式类型转换,用explicit声明一个接收1个参数的构造函数,并避免使用转换操作符;
- 使用不同的类来表示不同的数据类型(后续提到);
- 用typedef来重命名该类型;
二、在运行时遇见错误该如何处理
如:打开一个文件不存在或没有权限,或访问链接不可用等,为运行时错误;
为此,我们需要输出错误信息:输出错误的原因,错误的地方,相关的变量值,并采取适当的操作;
1 该输出哪些错误信息
使用该宏,当条件为假时即可触发,将错误信息输出;
#define ASSERT(condition, msg) \
if(!(condition)) { \
std::cerr << "in file: "__FILE__; \
std::cerr << " #" << __LINE__ << ": "; \
std::cerr << msg; \
exit(1);\
}
int main() {
ASSERT(0 > 1, "test");
}
// 示例:
/**
ASSERT(index < array.size(), "Index " << index << " is out of bounds " << array.size());
输出足够的信息,让该错误信息更有意义;
*/
2 执行安全检查则会减低程序效率,该如何处理呢
- 我们可以将安全检查分为
生产使用和测试使用,当不需要时,则可以将其关闭,从而不降低程序的执行效率; - 那么何时使用生产、何时使用测试,需要
开发者来决定,需要考虑该处使用安全检查其调用频率、执行时间(条件的执行时间)等; - 且在初次编写代码时,就需要
一同编写安全检查,而不是过后在做补充;
#define TEST_ASSERT_ON // 若定义就开启
#ifdef TEST_ASSERT_ON
#define TEST_ASSERT(condition, msg) ASSERT(condition, msg)
#else
#define TEST_ASSERT(condition, msg)
#endif
#define ASSERT(condition, msg) \
if(!(condition)) { \
std::cerr << "in file: "__FILE__; \
std::cerr << " #" << __LINE__ << ": "; \
std::cerr << msg; \
exit(1);\
}
int main() {
TEST_ASSERT(0 > 1, "test");
}
3 当运行时遇到错误时,该如何处理
- 终止程序:一般用于
测试时,立即中断程序,修改后继续尝试; - 抛出异常:在程序实际工作中,不宜将程序直接终止,而是抛出一个异常,在将具体的错误信息交给
错误处理函数,并在顶层代码中捕捉该异常,将其记录在日志文件中,不会干扰到其他功能的正常运行;
// 一
#ifdef THROW_EXCEPTION_ON_BUG
throw std::logic_error("error");
#else
std::cout << "exit" << std::endl;
exit(1);
#endif
// 二
int main() {
try {
double stock_price{ 100.0 };
ASSERT(
0 < stock_price && stock_price <= 1e6,
"Stock price " << stock_price << " is out of range.");
stock_price = -1.;
ASSERT(
0 < stock_price && stock_price <= 1e6,
"Stock price " << stock_price << " is out of range.");
}
catch (const std::exception& ex) {
std::cerr << "Exception caught in " << __FILE__
<< " #" << __LINE__ << ":\n"
<< ex.what() << std::endl;
}
return 0;
}
4 结合Backtrace的安全检查
- 在上述的ASSERT中我们不仅可以打印当前错误的文件、行号信息等还可以通过嵌入backtrace将调用栈详细地打印出来更加明了;
》》》》》》》》参考sylar《《《《《《《《
std::vector<std::string>& Backtrace(int size, size_t skip) {
void **array = (void**)malloc(sizeof(void*) * size);
size_t s = ::backtrace(array, size);
std::vector<std::string> rt;
char** str = backtrace_symbols(array, s);
if(str == nullptr) {
std::cerr << "backtrace_symbols error" << std::endl;
return;
}
for(size_t i=skip; i<s; ++i) {
rt.push_back(str[i]);
}
free(str);
free(array);
}
std::string BacktraceToString(int size, size_t skip, const std::string& prefix) {
auto vc = Backtrace(size, skip);
std::stringstream ss;
for(size_t i=0; i<vc.size(); ++i) {
ss << prefix << vc[i] << std::endl;
}
return ss.str();
}
#define ASSERT(condition, msg) \
if(!(condition)) { \
std::cerr << "in file: "__FILE__; \
std::cerr << " #" << __LINE__ << ": "; \
std::cerr << BacktraceToString(100, 2, " ") \
std::cerr << msg; \
exit(1);\
}
四、索引越界
- 不要使用
静态或动态分配的数组,改用array或vector模板; - 不要使用带
[]的new和delete操作符,让vector模板为多个元素分配内存; - 继承vector,对需要
增加安全检查的进行重写; - 对于多维数组,通过
()访问元素,并提供越界检查;
1 动态数组
若出现越界的情况,则会返回错误的信息;但对于vector提供了at使用,该方法能够抛出一个out_of_range异常,但会降低代码的效率;
故,我们可以自己捕捉目标并改写;
namespace scpp {
template <typename T>
class vector : public std::vector<T> {
public:
typedef unsigned size_type;
explicit vector(size_type n = 0)
: std::vector<T>(n) { }
vector(size_type n, const T& value)
: std::vector<T>(n, value) { }
template <class InputIterator> vector(InputIterator first,
InputIterator last)
: std::vector<T>(first, last) { }
T& operator[] (size_type index) {
std::stringstream stringStream;
SCPP_TEST_ASSERT(index < std::vector<T>::size(),
stringStream << "Index " << index
<< " must be less than "
<< std::vector<T>::size());
return std::vector<T>::operator[](index);
}
const T& operator[] (size_type index) const {
std::stringstream stringStream;
SCPP_TEST_ASSERT(index < std::vector<T>::size(),
stringStream << "Index " << index
<< " must be less than "
<< std::vector<T>::size());
return std::vector<T>::operator[](index);
}
};
}
vector注意事项
- 当不断向vector插入数据后,vector插入数据可能变得
缓慢,故我们需要预先给vector分配内存;
vector<int> vec(n, 0); // 具有初始化的内存分配
vector<int> vec; // 无初始化的内存分配
vec.reserve(n);
从vector中派生新类的注意事项
若基类的析构函数不为虚函数,则在多态使用时则子类的析构函数不会被执行到;
- 故不对子类中添加任何数据成员;
- 不使用多态的特性;
class Base{
public:
~Base(); // 非虚拟
};
class Derived : public Base {
public:
~Derived() {} // 非虚拟
};
Base* p = new Derived;
delete p; // 此时delete调用的是基类的析构,不会调用子类的析构
2 静态数组
- 静态数组从
堆栈上分配内存,而vector是通过new分配,速度较慢些,但最好使用array模板(静态数组); - 建议不要使用静态、动态数组而是使用vector或array模板;
3 多维数组
- 多维一般不使用vector的vector,它需要多次分配内存,是
低效的; - 采用一维度的数组进行存储,在索引上做处理,通过
()对元素进行访问,由于[]操作符只能接受1个参数;
template<typename T>
class matrix {
public:
typedef unsigned size_type;
matrix(size_type rows, size_type cols)
:m_rows(rows), m_cols(cols) {
ASSERT(m_rows > 0, "rows must be positive");
ASSERT(m_rows > 0, "cols must be positive");
}
matrix(size_type rows, size_type cols, const T& init_val)
:m_rows(rows), m_cols(cols), m_data(m_row*m_cols, init_val) {
ASSERT(m_rows > 0, "rows must be positive");
ASSERT(m_rows > 0, "cols must be positive");
}
size_type getRows() const { return m_rows; }
size_type getCols() const { return m_cols; }
T& operator() (size_type row, size_type col) {
return m_data[index(row, col)];
}
const T& operator() (size_type row, size_type col) const {
return m_data[index(row, col)];
}
private:
size_type index(size_type row, size_type col) const {
ASSERT(row < m_rows, "Row " << row << " must be less than " << m_rows);
ASSERT(col < m_cols, "Col " << col << " must be less than " << m_cols);
return col * row + col;
}
private:
size_type m_rows;
size_type m_cols;
std::vector<T> m_datas;
};
5 指针运算
- 避免使用
指针运算,使用vector模板或数组索引;
6 无效的指针、引用和迭代器
#include ![]()
- 出现上述原因是由于&v[3]的地址发生变化,当vector添加元素超出当前容量时,会重新分配一块内存将当前所有值都移植过去,旧的内存将被销毁;
- 引用也与指针相同,引用只是解引用的指针;
- 故任何指针、引用或迭代器在修改后都不应被再使用,即使有些容器其迭代器仍有效;
七、未初始化的变量
- 对于类的数据成员,不要使用内置类型;
- 重新定义该类型,还可获取编译时类型安全的优点;
1 初始化的数值
- 在类中,当添加一个数据成员时,即需要在构造函数中对它进行初始化,若有多个构造函数,而没添加数据成员都需要做修改,则需要做大量的工作;
- 该初始化只针对内置类型,由于内置类型不会有默认的构造函数将它初始化,而类型string类型,则会被默认初始化;
template<typename T>
class TNumber {
public:
TNumber(const T& x = 0) : m_data(x) {}
operator T() const { return m_data; }
TNumber& operator=(const T& x) {
m_data = x;
return *this;
}
TNumber operator++(int) {
TNumber<T> copy(*this);
++m_data;
return *this;
}
TNumber& operator++() {
++m_data;
return *this;
}
TNumber& operator+=(T x) {
m_data += x;
return *this;
}
TNumber& operator-=(T x) {
m_data -= x;
return *this;
}
TNumber& operator*=(T x) {
m_data *= x;
return *this;
}
TNumber& operator/=(T x) {
ASSERT(x!=0, "Attmpt to divide by 0");
m_data /= x;
return *this;
}
T operator/(T x) {
ASSERT(x != 0, "Attmpt to divide by 0");
return m_data / x;
}
private:
T m_data;
};
typedef TNumber<int> Int;
...
class A {
public:
Int m_a; // 此时即可被初始化
};
2 未初始化的布尔值
class Bool {
public:
Bool(bool x = false)
:m_data(x) {}
operator bool() const { return m_data; }
Bool& operator=(bool x) {
m_data = x;
return *this;
}
Bool& operator&=(bool x) {
m_data &= x;
return *this;
}
Bool& operator |= (bool x) {
m_data |= x;
return *this;
}
private:
bool m_data;
};
std::ostream& operator<<(std::ostream& os, Bool val) {
if (val) {
os << "True";
}
else {
os << "False";
}
return os;
}
八、内存泄漏
》》》》》》》》内存泄漏参考链接《《《《《《《《
- 当分配到新内存是,需要立即把指向该内存的指针赋值给智能指针;
内存泄漏:实际是被分配的内存的所有权丢失;
对象的所有权:删除该内存的责任;
可能出现内存泄漏的原因
- 分配内存后,没有释放即离开当前作用域;
- 当前内存地址赋给了其他值;
- 程序运行时,一直保留不在使用的指针;
- 循环引用导致得不到释放;
- 对指针赋值NULL,丢失该对象;
注意事项
- 使用完毕需要删除这块内存;
- 释放任务只执行一次;
- delete时,需要注意是否有带[];
1 引用计数指针
该类型的指针销毁时刻为最后消亡的那个对它进行删除;
》》》》》》》》智能指针参考链接《《《《《《《《
该类型指针存在的问题
- 不是多线程安全;
- 内存会在堆上new一个整数,速度相对慢;
2 作用域指针
- 该指针用于不需要复制指针,只想保证被分配的资源被正确的回收;
- 该指针没有赋值和拷贝方法,不需要再堆上分配整数对它进行拷贝计数;
3 用智能指针实行所有权
当使用一个函数来获取一个指针时,可能会出现的潜在错误,避免对象的所有权不明确等原因,让函数返回一个智能指针;
std::shared_ptr<MyClass> MyFactoryClass::Create(const Input& inputs);
// or
void MyFactoryClass::Create(const Inputs& inputs, auto_ptr<MyClass>& result);
九、解引用NULL指针
当我们试图解引用NULL指针时,将会导致程序崩溃,为此以下提供一种不删除它所指向对象的半智能指针;
template<typename T>
class Ptr {
public:
explicit Ptr(T* p = nullptr)
: m_ptr(p) {}
T* Get() const { return m_ptr; }
Ptr<T>& operator=(T* p) {
m_ptr = p;
return *this;
}
T* operator->() const {
ASSERT(m_ptr != nullptr, "Attempt to use operator -> on NULL pointer.");
return m_ptr;
}
T& operator*() const {
ASSERT(m_ptr != nullptr, "Attempt to use operator -> on NULL pointer.");
return *m_ptr;
}
private:
T* m_ptr;
};
上述指针的特性
- 它不拥有它所指向的对象的所有权,是相同情况下原始指针的替代品;
- 它默认被初始化为NULL;
- 提供了运行时诊断,当它为NULL时,若进行解引用,则可对该行为进行检测;
十、拷贝构造函数和赋值操作符
- 依赖编译器自动创建的默认版本;
- 将拷贝构造函数和赋值操作符声明为私有,不提供实现禁止任何复制;
- 尽量避免编写自己的版本;
十一、避免在析构函数中编写代码
- 在设计类的时候,尽量将析构函数保持为空函数;
何时需要在析构中编写
- 在基类中,可能需要声明虚拟析构函数;
- 需要对数据成员进行一个释放;
比较有实质性的做法可能就是在析构中对类中资源的释放,但该做法可能交给智能指针去处理并不需要交给我们手动处理;
交给智能指针的好处
- 若在构造中new一块内存时,需要new第二块内存,此处出现错误,若使用智能指针,则内存都会被释放掉;
- 不需要在类的析构中对它进行清理;
十二、怎样编写一致的比较操作符
- 即使我们本身不需要比较操作符,但后续其他人在使用时可能需要,特别是将其存储在容器中;
- 比较操作符:
> < <= >= == !=; - 则,我们编写一个Compare函数,然后使用宏来实现所有比较操作符;
class MyClass {
public:
int CompareTo(const MyClass& that) const;
public:
#define SCPP_DEFINE_COMPARISON_OPERATORS(Class) \
bool operator<(const Class& that) const { return CompareTo(that) < 0; } \
bool operator>(const Class& that) const { return CompareTo(that) > 0; } \
bool operator<=(const Class& that) const { return CompareTo(that) <= 0; } \
bool operator>=(const Class& that) const { return CompareTo(that) >= 0; } \
bool operator!=(const Class& that) const { return CompareTo(that) != 0; } \
bool operator==(const Class& that) const { return CompareTo(that) == 0; } \
};
十三、使用标准C函数库的错误
- 对于strlen(),该用size()方法;
- 对于strcpy(),可仅仅使用字符串赋值操作符来复制;
- 对于strcat(),可改用ostringstream;
- C库中的函数并不安全,甚至速度不及C++类,故应多使用C++类;
十四、基本的测试原则
- 对每个类都进行所有的测试,且包括对一组类协同作用时的所有测试,还要包括对整个应用程序的测试;
- 在允许的范围内需要尝试创建一个可重复生成的测试,保证重复测试时能产生相同的结果;
- 好的设计时每个层次的类只能调用下面层次的类;
- 对输入代码需要测试正确和不正确的输入,查看其表现;
- 对于接受可变长度的输入,需要测试其时间复杂度;
- 算法的是否高效,使用随机法或穷举法进行测试;
十五、调试错误的策略
- 在打开安全检测时运行代码,试图覆盖所有可能的情况;
- 若有任何安全检测失败,修正代码返回步骤1;
- 若进入步骤3,可合理工作;
十六、使代码更容易调试
若代码中的处理方法可以有多种,可以选择在debug中和release中进行区分;
#ifdef DEBUG
// 处理1
#else
// 处理2