论文笔记:多任务学习模型:渐进式分层提取(PLE)含pytorch实现
整理了RecSys2020 Progressive Layered Extraction : A Novel Multi-Task Learning Model for Personalized Recommendations)论文的阅读笔记
- 背景
- 模型
- 代码
论文地址:PLE
背景
多任务学习(multi-task learning,MTL):给定 m 个学习任务,这m个任务或它们的一个子集彼此相关但不完全相同。简单地说就是一个模型有多个输出对应多个任务的结果。
多任务学习在推荐系统中已经有很多成功的应用。但是存在一些问题,文章的作者观察到了一个跷跷板现象,即一个任务的性能通常通过损害其他任务的性能来提高。当任务相关性复杂时,相应的单任务模型相比,多个任务无法同时提高。
基于这一点,本文提出了一种渐进分层提取(PLE)模型。明确分离共享组件和特定任务组件,采用渐进式路由机制,逐步提取和分离更深层次的语义知识。
模型
利用门结构和注意网络进行信息融合在之前的模型中已经很常见,比如MMoE,单层的MMoE如图:

在这种模型中,没有任务特定的概念,所有的专家被所有的任务共享,PLE就是在MMoE的基础上修改的,在PLE中,明确地分离了任务公共参数和任务特定参数,以避免复杂任务相关性导致的参数冲突。单层的PLE(CGC模块)是这样的:
 和MMoE的区别就很明显了,在MMoE中,所有的任务同时更新所有的专家网络,没有任务特定的概念,而在PLE中,明确分离了任务通用专家和特定任务专家,特定于任务的专家仅接受对应的任务tower梯度更新参数,而共享的专家则被多任务结果更新参数,这就使得不同类型 experts 可以专注于更高效地学习不同的知识且避免不必要的交互。另外,得益于门控网络动态地融合输入,CGC可以更灵活地在不同子任务之间找到平衡且更好地处理任务之间的冲突和样本相关性问题。
和MMoE的区别就很明显了,在MMoE中,所有的任务同时更新所有的专家网络,没有任务特定的概念,而在PLE中,明确分离了任务通用专家和特定任务专家,特定于任务的专家仅接受对应的任务tower梯度更新参数,而共享的专家则被多任务结果更新参数,这就使得不同类型 experts 可以专注于更高效地学习不同的知识且避免不必要的交互。另外,得益于门控网络动态地融合输入,CGC可以更灵活地在不同子任务之间找到平衡且更好地处理任务之间的冲突和样本相关性问题。
对CGC模型进行扩展,就形成了具有多级门控网络和渐进式分离路由的广义PLE模型: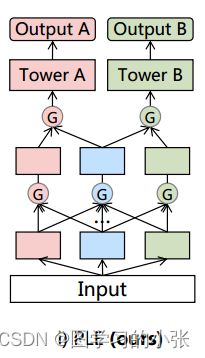
具体的CGC(Customized Gate Control)模型:
具体的PLE模型:
代码
由于博主不是做这个方向的,仅记录这篇文章的思想,就不推公式和实验了,PLE的代码似乎没有公开,但是在网上找了一个可用的pytorch版本,稍微调试一下就可用了,代码修改自博客【推荐系统多任务学习 MTL】PLE论文精读笔记(含代码实现)
import numpy as np
import torch
from torch import nn
'''专家网络'''
class Expert_net(nn.Module):
def __init__(self, feature_dim, expert_dim):
super(Expert_net, self).__init__()
p = 0
self.dnn_layer = nn.Sequential(
nn.Linear(feature_dim, 256),
nn.ReLU(),
nn.Dropout(p),
nn.Linear(256, expert_dim),
nn.ReLU(),
nn.Dropout(p)
)
def forward(self, x):
out = self.dnn_layer(x)
return out
'''特征提取层'''
class Extraction_Network(nn.Module):
'''FeatureDim-输入数据的维数; ExpertOutDim-每个Expert输出的维数; TaskExpertNum-任务特定专家数;
CommonExpertNum-共享专家数; GateNum-gate数(2表示最后一层,3表示中间层)'''
def __init__(self, FeatureDim, ExpertOutDim, TaskExpertNum, CommonExpertNum, GateNum):
super(Extraction_Network, self).__init__()
self.GateNum = GateNum # 输出几个Gate的结果,2表示最后一层只输出两个任务的Gate,3表示还要输出中间共享层的Gate
'''两个任务模块,一个共享模块'''
self.n_task = 2
self.n_share = 1
'''TaskA-Experts'''
for i in range(TaskExpertNum):
setattr(self, "expert_layer" + str(i + 1), Expert_net(FeatureDim, ExpertOutDim).cuda())
self.Experts_A = [getattr(self, "expert_layer" + str(i + 1)) for i in
range(TaskExpertNum)] # Experts_A模块,TaskExpertNum个Expert
'''Shared-Experts'''
for i in range(CommonExpertNum):
setattr(self, "expert_layer" + str(i + 1), Expert_net(FeatureDim, ExpertOutDim).cuda())
self.Experts_Shared = [getattr(self, "expert_layer" + str(i + 1)) for i in
range(CommonExpertNum)] # Experts_Shared模块,CommonExpertNum个Expert
'''TaskB-Experts'''
for i in range(TaskExpertNum):
setattr(self, "expert_layer" + str(i + 1), Expert_net(FeatureDim, ExpertOutDim).cuda())
self.Experts_B = [getattr(self, "expert_layer" + str(i + 1)) for i in
range(TaskExpertNum)] # Experts_B模块,TaskExpertNum个Expert
'''Task_Gate网络结构'''
for i in range(self.n_task):
setattr(self, "gate_layer" + str(i + 1),
nn.Sequential(nn.Linear(FeatureDim, TaskExpertNum + CommonExpertNum),
nn.Softmax(dim=1)).cuda())
self.Task_Gates = [getattr(self, "gate_layer" + str(i + 1)) for i in
range(self.n_task)] # 为每个gate创建一个lr+softmax
'''Shared_Gate网络结构'''
for i in range(self.n_share):
setattr(self, "gate_layer" + str(i + 1),
nn.Sequential(nn.Linear(FeatureDim, 2 * TaskExpertNum + CommonExpertNum),
nn.Softmax(dim=1)).cuda())
self.Shared_Gates = [getattr(self, "gate_layer" + str(i + 1)) for i in range(self.n_share)] # 共享gate
def forward(self, x_A, x_S, x_B):
'''Experts_A模块输出'''
Experts_A_Out = [expert(x_A) for expert in self.Experts_A] #
Experts_A_Out = torch.cat(([expert[:, np.newaxis, :] for expert in Experts_A_Out]),
dim=1) # 维度 (bs,TaskExpertNum,ExpertOutDim)
'''Experts_Shared模块输出'''
Experts_Shared_Out = [expert(x_S) for expert in self.Experts_Shared] #
Experts_Shared_Out = torch.cat(([expert[:, np.newaxis, :] for expert in Experts_Shared_Out]),
dim=1) # 维度 (bs,CommonExpertNum,ExpertOutDim)
'''Experts_B模块输出'''
Experts_B_Out = [expert(x_B) for expert in self.Experts_B] #
Experts_B_Out = torch.cat(([expert[:, np.newaxis, :] for expert in Experts_B_Out]),
dim=1) # 维度 (bs,TaskExpertNum,ExpertOutDim)
'''Gate_A的权重'''
Gate_A = self.Task_Gates[0](x_A) # 维度 n_task个(bs,TaskExpertNum+CommonExpertNum)
'''Gate_Shared的权重'''
if self.GateNum == 3:
Gate_Shared = self.Shared_Gates[0](x_S) # 维度 n_task个(bs,2*TaskExpertNum+CommonExpertNum)
'''Gate_B的权重'''
Gate_B = self.Task_Gates[1](x_B) # 维度 n_task个(bs,TaskExpertNum+CommonExpertNum)
'''GateA输出'''
g = Gate_A.unsqueeze(2) # 维度(bs,TaskExpertNum+CommonExpertNum,1)
experts = torch.cat([Experts_A_Out, Experts_Shared_Out],
dim=1) # 维度(bs,TaskExpertNum+CommonExpertNum,ExpertOutDim)
Gate_A_Out = torch.matmul(experts.transpose(1, 2), g) # 维度(bs,ExpertOutDim,1)
Gate_A_Out = Gate_A_Out.squeeze(2) # 维度(bs,ExpertOutDim)
'''GateShared输出'''
if self.GateNum == 3:
g = Gate_Shared.unsqueeze(2) # 维度(bs,2*TaskExpertNum+CommonExpertNum,1)
experts = torch.cat([Experts_A_Out, Experts_Shared_Out, Experts_B_Out],
dim=1) # 维度(bs,2*TaskExpertNum+CommonExpertNum,ExpertOutDim)
Gate_Shared_Out = torch.matmul(experts.transpose(1, 2), g) # 维度(bs,ExpertOutDim,1)
Gate_Shared_Out = Gate_Shared_Out.squeeze(2) # 维度(bs,ExpertOutDim)
'''GateB输出'''
g = Gate_B.unsqueeze(2) # 维度(bs,TaskExpertNum+CommonExpertNum,1)
experts = torch.cat([Experts_B_Out, Experts_Shared_Out],
dim=1) # 维度(bs,TaskExpertNum+CommonExpertNum,ExpertOutDim)
Gate_B_Out = torch.matmul(experts.transpose(1, 2), g) # 维度(bs,ExpertOutDim,1)
Gate_B_Out = Gate_B_Out.squeeze(2) # 维度(bs,ExpertOutDim)
if self.GateNum == 3:
return Gate_A_Out, Gate_Shared_Out, Gate_B_Out
else:
return Gate_A_Out, Gate_B_Out
class PLE(nn.Module):
# FeatureDim-输入数据的维数;ExpertOutDim-每个Expert输出的维数;TaskExpertNum-任务特定专家数;CommonExpertNum-共享专家数;n_task-任务数(gate数)
def __init__(self, FeatureDim, ExpertOutDim, TaskExpertNum, CommonExpertNum, n_task=2):
super(PLE, self).__init__()
# self.FeatureDim = x.shape[1]
'''一层Extraction_Network,一层CGC'''
self.Extraction_layer1 = Extraction_Network(FeatureDim, ExpertOutDim, TaskExpertNum, CommonExpertNum, GateNum=3)
self.CGC = Extraction_Network(ExpertOutDim, ExpertOutDim, TaskExpertNum, CommonExpertNum, GateNum=2)
'''TowerA'''
p1 = 0
hidden_layer1 = [64, 32]
self.tower1 = nn.Sequential(
nn.Linear(ExpertOutDim, hidden_layer1[0]),
nn.ReLU(),
nn.Dropout(p1),
nn.Linear(hidden_layer1[0], hidden_layer1[1]),
nn.ReLU(),
nn.Dropout(p1),
nn.Linear(hidden_layer1[1], 1))
'''TowerB'''
p2 = 0
hidden_layer2 = [64, 32]
self.tower2 = nn.Sequential(
nn.Linear(ExpertOutDim, hidden_layer2[0]),
nn.ReLU(),
nn.Dropout(p2),
nn.Linear(hidden_layer2[0], hidden_layer2[1]),
nn.ReLU(),
nn.Dropout(p2),
nn.Linear(hidden_layer2[1], 1))
def forward(self, x):
Output_A, Output_Shared, Output_B = self.Extraction_layer1(x, x, x)
Gate_A_Out, Gate_B_Out = self.CGC(Output_A, Output_Shared, Output_B)
out1 = self.tower1(Gate_A_Out)
out2 = self.tower2(Gate_B_Out)
return out1, out2
return Gate_A_Out, Gate_B_Out