fastjson反序列化方法JSON.parseObject(String str,Class clazz)
fastjson这一工具包帮助我们进行java对象和json格式的字符串之间的相互转换。对象到字符串的过程,我们称之为序列化;反之,我们称为反序列化。
现在我们就来谈谈fastjson提供的反序列化方法,本篇只讨论按照指定的字节码返回相应对象的的反序列化方法,该方法有多种重载形式,按照重叠构造的模式设计。常用的入口为:JSON.parseObject(String text, Class
JSON.parseObject(String text, Class
这样最终实际调用的方法及其参数值为:parseObject(input, clazz, ParserConfig.getGlobalInstance(), null, DEFAULT_PARSER_FEATURE, new Feature[0])。
我们关注下ParserConfig.getGlobalInstance(),每次调用返回同一个ParserConfig对象。这样其实保证了以JSON.parseObject(String text, Class
我们看看ParserConfig对象在fastjson反序列化过程中的作用:
作用一:维护了常用类型和反序列化器之间的对应关系,存放到IdentityHashMap
作用二:创建字段反序列化器FieldDeserializer,而这些FieldDeserializer会维护到ObjectDeserializer的IdentityHashMap
重点关注FieldDeserializer的生成,通过源码分析,通常情况下会调用ASMDeserializerFactory.getInstance().createFieldDeserializer(parserConfig, clazz, fieldInfo)生成字段反序列化器。
if (fieldClass == int.class || fieldClass == long.class || fieldClass == String.class) {
return createStringFieldDeserializer(mapping, clazz, fieldInfo);
}
通过上面createFieldDeserializer中的源码可以看出,针对int、long和String类型做了特殊处理,进一步分析发现其内部利用asm字节码增加技术对IntegerFieldDeserializer、LongFieldDeserializer以及StringFieldDeserializer做了扩展,动态生成了新的类。
类名为:String name = "Fastjson_ASM__Field_" + clazz.getSimpleName();
name += "_" + fieldInfo.getName() + "_" + seed.incrementAndGet();(注意seed此种场景下是单例的)
该类主要是新增了setValue()方法,应该是用来对字段进行赋值操作的(PS:关于对象序列化和字段序列化器的内部处理逻辑有机会可进一步分析研究)
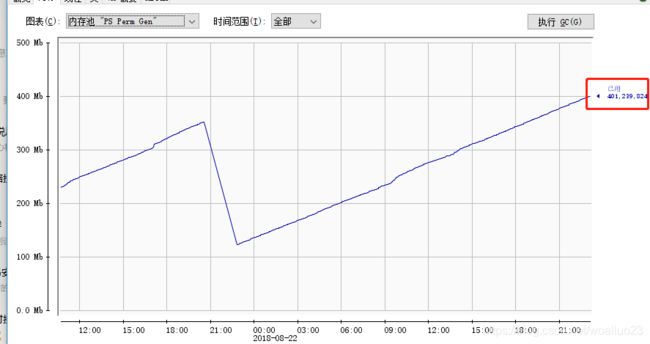
综上:针对保留了永久代的jvm,对于如上三种类型的字段,在创建FieldDeserializer时会动态生成新的类,造成jvm加载的类的数目上升,永久代内存的增加。当然通常情况,一个项目中需要反序列化的类是有限的,并且因为常用情况下ParseConfig是单例,相应字段对应的字段序列化器类生成一份后就不在重复生成了,永久代内存通常情况下也就不会溢出。
JSON.parseObject ( reqMsg, ReqMsgDto.class, new ParserConfig() , JSONObject.DEFAULT_PARSER_FEATURE )
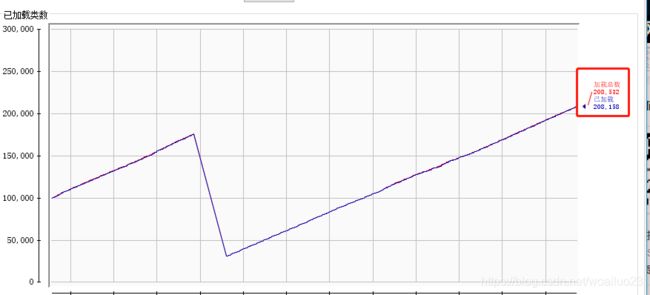
但若如上进行api的调用,此种情况下ParserConfig不在全局唯一,就可能会持续不断的生成字段序列化器类,从而造成java.lang.OutOfMemoryError: PermGen space。此种场景下应将ParserConfig的实例作为类变量或者成员变量,以避免每次调用都会创建新的字段序列化类。