Debezium发布历史97
原文地址: https://debezium.io/blog/2020/11/04/streaming-vitess-at-bolt/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
Bolt 的 Vitess 直播
十一月 4, 2020 作者: Kewei Shang, Ruslan Gibaiev
维特斯
这篇文章最初出现在Bolt Labs Engineering 博客上。
传统上,MySQL 已用于为Bolt 的大部分后端服务提供支持。我们设计模式时将它们分成不同的 MySQL 集群。每个 MySQL 集群都包含一个数据子集,并由一个主节点和多个复制节点组成。
一旦数据持久化到数据库,我们就使用Debezium MySQL Connector捕获数据更改事件并将其发送到 Kafka。这为我们提供了一种简单可靠的方式来在后端微服务之间传达更改。
维特斯在博尔特
Bolt 在过去几年中大幅增长,写入 MySQL 的数据量也随之增加。手动数据库分片已经成为一个相当昂贵且持久的过程,并且容易出错。因此我们开始评估更具可扩展性的数据库,其中之一就是Vitess。Vitess是一个基于MySQL的开源数据库集群系统,并为其提供水平可扩展性。它起源于 YouTube 并经过实际检验,后来开源并被 Slack、Github、JD.com 等公司用来为其后端存储提供支持。它将重要的 MySQL 功能与 NoSQL 数据库的可扩展性结合在一起。
Vitess 提供的最重要的功能之一是其内置分片。它允许数据库通过以对后端应用程序逻辑透明的方式添加新分片来水平增长。对于您的应用程序来说,Vitess 就像一个巨大的单一数据库,但实际上数据在幕后被划分为多个物理分片。对于任何表,都可以选择任意列作为分片键,所有插入和更新都将由 Vitess 本身无缝定向到适当的分片。
下图 1说明了后端服务如何与 Vitess 交互。在较高级别上,服务通过负载均衡器连接到无状态 VTGate 实例。每个 VTGate 都将 Vitess 集群的拓扑缓存在其内存中,并将查询重定向到正确的分片以及分片内正确的 VTablet(及其底层 MySQL 实例)。更多关于 VTablet 的内容写在下面。
图片来自于原文

图 1.Vitess 架构。参考: https: //www.planetscale.com/vitess
Vitess 提供的其他有用功能包括:
故障转移(又称重新父子关系)对于客户来说既简单又透明。客户端仅与 VTGate 通信,VTGate 透明地负责新主节点的故障转移和服务发现。
它会自动重写可能导致数据库性能下降的“有问题”查询。
它具有缓存机制,可以防止重复查询同时到达底层 MySQL 数据库。只有一个查询将到达数据库,其结果将被缓存并返回以回答重复的查询。
它有自己的连接池,消除了MySQL连接的高内存开销。因此,它可以轻松地同时处理数千个连接。
连接超时和事务超时可以配置。
进行重新分片操作时,它的停机时间最少。
下游 CDC 应用程序可以使用其 VStream 功能从 Vitess 读取更改事件。
流媒体 Vitess 选项
捕获数据变化并将其发布到 Apache Kafka 的能力是 Bolt 采用 Vitess 的要求之一。我们考虑过几种不同的选择。
选项 1:使用 Debezium MySQL 连接器
应用程序连接到 Vitess VTGate 以发送查询。VTGate支持MySQL协议并具有SQL解析器。您可以使用任何 MySQL 客户端(例如 JDBC)连接到 VTGate,VTGate 将您的查询重定向到正确的分片并将结果返回给您的客户端。
然而,VTGate 并不等于 MySQL 实例,它而是各种 MySQL 实例的无状态代理。为了让 MySQL 连接器接收更改事件,Debezium MySQL 连接器需要连接到真实的 MySQL 实例。更明显的是,VTGate 还存在一些已知的兼容性问题,这使得连接到 VTGate 与 MySQL 不同。
另一种选择是使用 Debezium MySQL Connector 直接连接到不同分片的底层 MySQL 实例。它有其优点和缺点。
一个优点是,对于未分片的键空间(Vitess 的数据库术语),MySQL 连接器可以继续正常工作,我们不需要包含额外的逻辑或特定实现。它应该工作得很好。
最大的缺点之一是重新分片操作会变得更加复杂。例如,原始MySQL实例的GTID在重新分片时会发生变化,MySQL连接器依赖于GTID才能正常工作。我们还认为,将 MySQL 连接器直接连接到每个底层 MySQL 实例违背了 Vitess 操作简单性的目的,因为每次重新分片时都必须添加(或删除)新的连接器。更不用说这样的操作会导致 Kafka 代理内部的数据重复。
选项 2:使用 JDBC 源连接器
我们还考虑过使用JDBC Source Connector。它允许将任何支持 JDBC 驱动程序的关系数据库中的数据获取到 Kafka 中。因此,它与Vitess VTGate兼容。它也有其优点和缺点。
优点:
它与 VTGate 兼容。
它可以更好地处理 Vitess 重新分片操作。在重新分片操作期间,读取会简单地自动重定向(由 VTGate)到目标分片。它不会生成任何重复项或丢失任何数据。
缺点:
它是基于轮询的,这意味着连接器按定义的时间间隔(通常每隔几秒)轮询数据库以查找新的更改事件。这意味着与 Debezium MySQL 连接器相比,我们的延迟会高得多。
其偏移量由表的增量主键或表的时间戳列之一管理。如果我们使用时间戳列作为偏移量,则必须为每个表创建时间戳列的二级索引。这对我们的后端服务增加了更多限制。如果我们使用增量主键,我们将错过行更新的更改事件,因为主键根本没有更新。
JDBC 连接器创建的主题名称不包括表的架构名称。使用topic.prefix连接器配置意味着我们每个模式都有一个连接器。在 Bolt,我们有大量的模式,这意味着我们需要创建大量的 JDBC 源连接器。
在 Bolt,我们的下游应用程序已经设置为使用 Debezium 的数据格式和主题命名约定,例如,我们需要将下游应用程序的解码逻辑更改为新的数据格式。
不捕获行删除。
选项 3:使用 VStream gRPC
VTGate 公开了一个名为 VStream 的 gRPC 服务。它是一种服务器端流媒体服务。任何 gRPC 客户端都可以订阅VStream服务,以从底层 MySQL 实例获取连续的更改事件流。VStream发出的更改事件与底层MySQL实例的MySQL二进制日志具有类似的信息。单个 VStream 甚至可以订阅给定键空间的多个分片,这使其成为构建 CDC 工具的相当方便的 API。
在幕后,如图2所示,VStream 从多个VTablet读取更改事件,每个分片一个 VTablet。因此,它不会从给定分片的多个 VTablet 发送重复项。每个 VTablet 都是其 MySQL 实例的代理。典型的拓扑将包括一个主 VTablet 及其相应的 MySQL 实例,以及多个副本 VTablet,每个副本都是其自己的副本 MySQL 实例的代理。VTablet 从其底层 MySQL 实例获取更改事件,并将更改事件发送回 VTGate,VTGate 又将更改事件发送回 VStream 的 gRPC 客户端。
当订阅VStream服务时,客户端可以指定VGTID和平板电脑类型(例如MASTER,REPLICA)。VGTID 告诉 VStream 开始发送更改事件的位置。本质上,VGTID 包括(键空间、分片、分片 GTID)元组的列表。Tablet 类型告诉我们从每个分片中的哪个 MySQL 实例(主实例或副本实例)读取更改事件。
图片来自于原文
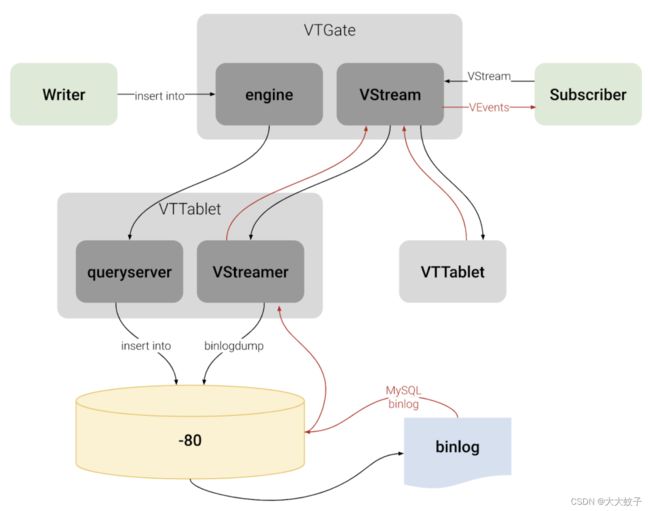
图 2.VStream 架构。参考: https: //vitess.io/docs/concepts/vstream
使用 VStream gRPC 的一些优点包括:
这是从 Vitess 接收更改事件的简单方法。Vitess 的文档中还建议使用 VStream 构建下游 CDC 流程。
VTGate 隐藏了连接到各种源 MySQL 实例的复杂性。
它具有较低的延迟,因为更改事件一旦发生就会立即传输到客户端。
更改事件不仅包括插入和更新,还包括删除。
最大的优点之一可能是更改事件包含每个表的架构。因此,您不必担心提前获取每个表的架构(例如,通过解析 DDL 或查询表的定义)。
更改事件包含 VGTID,CDC 进程可以存储该 VGTID 并将其用作下次重新启动 CDC 进程的位置的偏移量。
同样重要的是,VStream 旨在与 Vitess 操作(例如重新分片和移动表)良好配合。
也有一些缺点:
尽管它包含表模式,但仍然缺少一些重要信息。例如,Enum和Set列类型尚未提供所有允许的值。不过,这应该在下一个主要版本(Vitess 9)中修复。
由于 VStream 是一项 gRPC 服务,因此我们无法开箱即用地使用 Debezium MySQL Connector。然而,用其他语言实现 gRPC 客户端非常简单。
考虑到所有因素,我们决定使用 VStream gRPC 来捕获来自 Vitess 的更改事件,并基于 Debezium 的所有最佳实践来实现我们的 Vitess 连接器。
Vitess 连接器深入研究和开源
在我们决定实现 Vitess 连接器之后,我们开始研究各种 Debezium 源连接器(MySQL、Postgres、SQLServer)的实现细节,以借鉴一些想法。几乎所有这些都是使用通用的连接器开发框架来实现的。因此很明显,我们应该在其基础上开发 Vitess 连接器。鉴于我们是 MySql Connector 的非常活跃的用户,并且我们从它的开源中受益,因为它允许我们为它贡献我们自己所缺少的东西。因此,我们决定回馈社区,并在 Debezium 的保护下开源 Vitess 源连接器代码库。请随时在Debezium Connector Vitess了解更多信息。我们欢迎并重视任何贡献。
在较高级别上,如下所示,连接器实例是在 Kafka Connect 工作线程中创建的。在撰写本文时,您有两种选择来配置连接器以从 Vitess 读取数据:
选项 1(推荐):
如图3所示,每个连接器捕获特定键空间中所有分片的更改事件。如果键空间未分片,连接器仍然可以从键空间中的唯一分片捕获更改事件。当连接器第一次启动时,它会从键空间中所有分片的当前 VGTID 位置读取。由于它订阅了所有分片,因此它不断捕获所有分片的更改事件并将其发送到 Kafka。它自动支持Vitess Reshard操作,不存在数据丢失,也不重复。
图片来自于原文
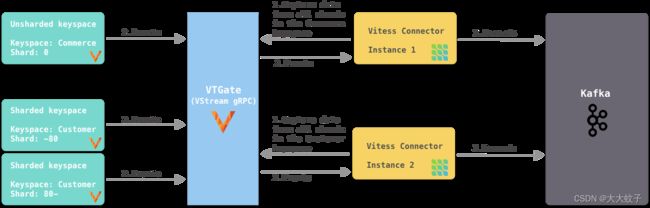
图 3. 每个连接器订阅特定键空间的所有分片
选项2:
如图4所示,每个连接器实例捕获来自特定键空间/分片对的更改事件。连接器实例从 VTCtld gRPC(另一个 Vitess 组件)获取密钥空间/分片对的初始(当前)VGTID 位置。每个连接器实例独立地使用它获得的 VGTID 订阅 VStream gRPC,并持续捕获来自 VStream 的更改事件并将其发送到 Kafka。为了支持Vitess Reshard操作,您需要更多的手动操作。
图片来自于原文
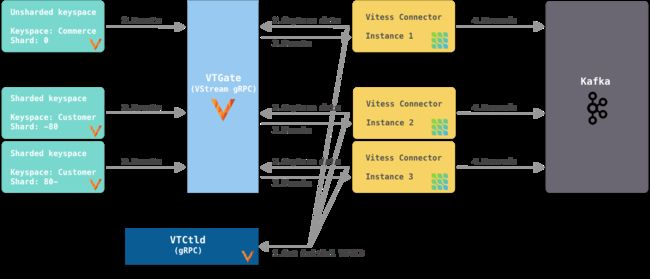
图 4. 每个连接器订阅特定密钥空间的一个分片
在内部,每个连接器任务使用 gRPC 线程不断接收来自 VStream 的更改事件,并将事件放入内部阻塞队列中。连接器任务线程从队列中轮询事件并将其发送到 Kafka,如图5所示。
图片来自于原文
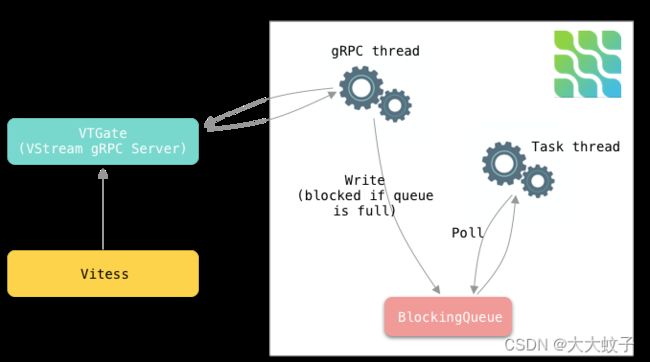
图 5. 每个连接器任务的内部工作原理
复制挑战
在我们实施 Vitess Connector 并深入挖掘 Vitess 的同时,我们也意识到了一些挑战。
维特斯·雷沙德
当连接器配置为订阅给定键空间的所有分片时,Vitess 连接器支持 Vitess Reshard 操作。VStream 发送一个 VGTID,其中包含所有分片的分片 GTID。Vitess 重新分片对用户是透明的。完成后,Vitess 将发送新分片的 VGTID。因此,连接器将在重新分片后使用新的 VGTID。但是,您需要确保在进行重新分片操作时连接器已启动并正在运行。特别是在删除旧分片之前请检查连接器的偏移主题是否具有新的 VGTID。这是因为,如果旧分片被删除,VStream将无法识别旧分片中的VGTID。
如果您决定为每个连接器订阅一个分片,则该连接器不会为 Vitess 重新分片提供开箱即用的支持。支持重新分片的一种手动解决方法是为每个目标分片创建一个新连接器。例如,一个用于commerce/-80分片的新连接器,以及另一个用于commerce/80-分片的新连接器。请记住,因为它们是新连接器,所以默认情况下会创建新主题,但是,您可以使用Debezium 逻辑主题路由器将记录路由到相同的 Kafka 主题。
偏移管理
VStream 在其响应中包含 VGTID 事件。我们将VGTID保存为Kafka偏移主题中的偏移量,因此当连接器重新启动时,我们可以从保存的VGTID开始。但是,在极少数情况下,当事务包含大量行时,VStream 会将更改事件批处理为多个响应,并且只有最后一个响应具有 VGTID。在这种情况下,我们没有收到的每个更改事件的 VGTID。我们有几种选择来解决这个特定问题:
我们可以将所有更改事件缓冲在内存中,并等待包含 VGTID 的最后一个响应到达。因此,所有事件都将具有与其关联的正确 VGTID。一些缺点是,在将事件发送到 Kafka 之前,我们会有更高的延迟。此外,由于缓冲,内存使用量可能会增加很多。缓冲还增加了逻辑的复杂性。我们也无法控制 VStream 发送给我们的事件数量。
我们可以使用我们拥有的最新 VGTID,这是来自先前 VStream 响应的 VGTID。如果连接器在处理如此大的事务时发生故障并重新启动,它将从上一个 VStream 响应的 VGTID 重新启动,从而重新处理一些事件。因此,它具有至少一次事件传递语义,并且期望下游是幂等的。由于大多数事务都不够大,因此大多数 VStream 响应都会在响应中包含 VGTID,因此出现重复的可能性很低。最后,我们选择这种方法是因为它的至少一次交付保证和设计简单性。
模式管理
VStream 的响应还包括一个FIELD事件。这是一个特殊事件,包含受影响行的表的架构。例如,假设我们有 2 个表,A并且B。如果我们向表中插入几行A,则FIELD事件将仅包含表A的架构。VStream 足够智能,只FIELD在必要时才包含事件。例如,当 VStream 客户端重新连接时,或者当表的架构更改时。
旧版本的VStream仅包含列类型(例如Integer,Varchar),没有附加信息,例如该列是否是主键,该列是否有默认值,Decimal类型的小数位数和精度,Enum类型的允许值等。
VStream 的较新版本 (Vitess 8) 开始在每一列中包含更多信息。这将帮助连接器更准确地反序列化某些类型,并在发送到 Kafka 的更改事件中拥有更精确的模式。
未来的开发工作
我们可以使用VStream的API从最新的VGTID位置开始流式传输,而不是从VTCtld gRPC获取初始VGTID位置。这样做将消除对 VTCtld 的依赖。
我们尚不支持从更改事件中自动提取主键。目前,默认情况下,发送到 Kafka 的所有更改事件都具有null作为键,除非message.key.columns指定连接器配置。Vitess 最近在 VStream FIELD 事件中添加了每一列的标志,这使我们能够很快实现此功能。
添加对初始快照的支持,以在流式传输更改之前捕获所有现有数据。
概括
MySQL 已用于为 Bolt 的大部分后端服务提供支持。由于数据量和操作复杂性的大幅增长,Bolt 开始评估 Vitess 的可扩展性和重新分片等内置功能。
为了从 Vitess 捕获数据更改,就像我们使用 Debezium MySQL Connector 所做的那样,我们考虑了一些选项。最终,我们基于通用的 Debezium 连接器框架实现了自己的 Vitess Connector。在实施 Vitess 连接器时,我们遇到了一些挑战。例如,支持Vitess重新分片操作、偏移量管理和模式管理。我们思考了应对挑战的方法以及我们制定的解决方案。
我们还收到了多个社区对该项目的相当大的兴趣,我们决定在 Debezium 的保护下开源Vitess Connector 。请随时了解更多信息,我们欢迎并重视任何贡献。