轻松爬取网页数据:低代码&零编程技巧的自动化爬虫神器!
前言
在以前的文章中,我们学习了通过playwright+python+requests可以实现绕过浏览器鉴权进行接口请求。
在曾经的一次数据爬取的时候,我尝试去获取Boss直聘的岗位信息,可是很不巧,boss直聘的反爬机制把我的IP直接封了,妙啊。
在这里给大家推荐一款工具:亮数据。
他可以使用真实IP进行代理,从而对目标网站数据进行获取。
注册
注册地址:点击注册免费试用
进入中文版首页页面如下:

我们填写相关信息进行注册,注意姓名尽量写英文,我第一次注册的时候写中文好像没有验证成功,邮箱填本土的就可以。

这里注册的时候要注意,我们的密码要包含英文大小写+数字+特殊符号,缺一不可。从这来讲,亮数据的安全性考虑的不错。

登录
注册成功登录后界面如下:

功能展示
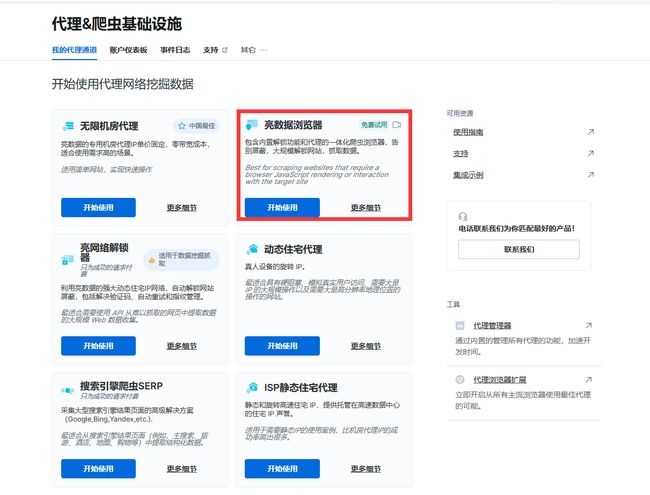
代理&爬虫基础设施
这个是有什么用呢?这个相当于一个远程浏览器,不需要像谷歌浏览器、火狐浏览器一样下载到本地,你可以通过远程连接这个浏览器,进行相关爬虫操作(这样即使封IP也封不到自己了,嘿嘿嘿~),后文我会以python-playwright进行示列。
这个浏览器的核心优势:
自动绕过验证码、封锁和限制
兼容Puppeteer, Playwright、Selenium

看到第一个了吗。这个就是我们可以使用的亮数据浏览器,点进去里面会有相关信息。

在右侧我们可以获取demo进行运行,我们分别以python语言-selenium-playwright进行操作。
python-selenium演示
pip3 install selenium
这里的主机名和其他信息改成上文中截图的,用你们自己注册的哈。
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = 'https://brd-customer-hl_8dfe8c6c-zone-scraping_browser:[email protected]:9515'
def main():
print('Connecting to Scraping Browser...')
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating to https://example.com...')
driver.get('https://example.com')
# CAPTCHA handling: If you're expecting a CAPTCHA on the target page, use the following code snippet to check the status of Scraping Browser's automatic CAPTCHA solver
# print('Waiting captcha to solve...')
# solve_res = driver.execute('executeCdpCommand', {
# 'cmd': 'Captcha.waitForSolve',
# 'params': {'detectTimeout': 10000},
# })
# print('Captcha solve status:', solve_res['value']['status'])
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
main()
python-playwright演示
pip3 install playwright
这里的主机名和其他信息改成上文中截图的,用你们自己注册的哈。
import asyncio
from playwright.async_api import async_playwright
SBR_WS_CDP = 'wss://brd-customer-hl_8dfe8c6c-zone-scraping_browser:[email protected]:9222'
async def run(pw):
print('Connecting to Scraping Browser...')
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to https://example.com...')
await page.goto('https://example.com')
# CAPTCHA handling: If you're expecting a CAPTCHA on the target page, use the following code snippet to check the status of Scraping Browser's automatic CAPTCHA solver
# client = await page.context.new_cdp_session(page)
# print('Waiting captcha to solve...')
# solve_res = await client.send('Captcha.waitForSolve', {
# 'detectTimeout': 10000,
# })
# print('Captcha solve status:', solve_res['status'])
print('Navigated! Scraping page content...')
html = await page.content()
print(html)
finally:
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
if __name__ == '__main__':
asyncio.run(main())
数据集展示
在亮数据中,我们可以看到很多现成的数据集。
进入数据商城,在右侧我们可以根据行业分类,看到各式各样的数据集,非常非常多

比如我们要查看TikTok的粉丝量大于一百万的,你可以选择CSV格式下载或者是JSON格式进行下载,这样大大方便了自己去爬取。

使用
进入代理&爬虫基础设施,选择亮数据浏览器
可以点击旁边的免费使用按钮,显示演示视频

这个功能适合以下需求的客户:
抓取过程需要需要交互(点击、悬停、在页面之间导航等)或JavaScript rendering以访问数据的网站。
核心优势:
自动绕过验证码、封锁和限制
兼容Puppeteer, Playwright、Selenium
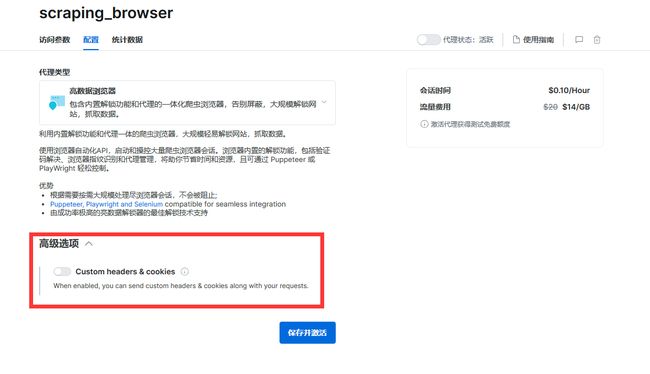
scraping_browser
你还可以设置你自己的用户请求头和cookie信息
亮数据爬虫IDE

进来之后我们可以看到亮数据使用JS编写的爬取其他网站信息的源码,并且可以直接在线运行。(这里可以进行借鉴学习爬虫技巧。)

这里我选取了一个tiktok的爬虫demo,我们可以看到右侧可以直接展示当前爬虫的操作过程。

自定义自己的数据集
示列:爬取CSDN的数据。
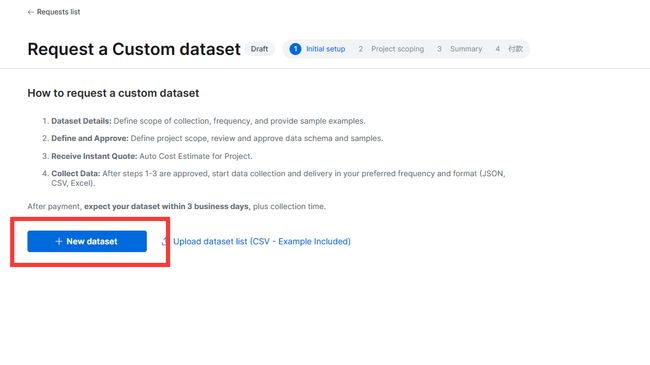
步骤一:选择按需定制数据集

步骤二:新建数据集
步骤三:填入目标网址
爬取CSDN后端内容
https://blog.csdn.net/nav/back-end
https://blog.csdn.net/nav/web

步骤四:进行提交

提交后就会自动抓取

抓取完成后点击查看

亮数据会抓取很多字段,我们需要编辑对应的字段,可以根据自己的需求进行删减,也可以对字段进行相关的备注修改。

如果你不想自己自定义,也可以使用AI-defined schema
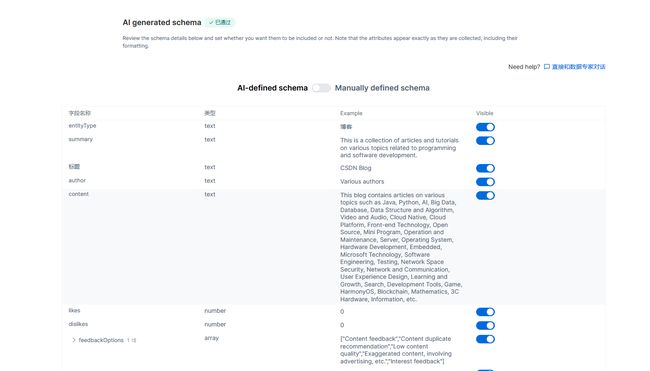
都编辑好了之后,就滑到最后面点击接受。
设置爬取的条数,这里我设置爬了100条

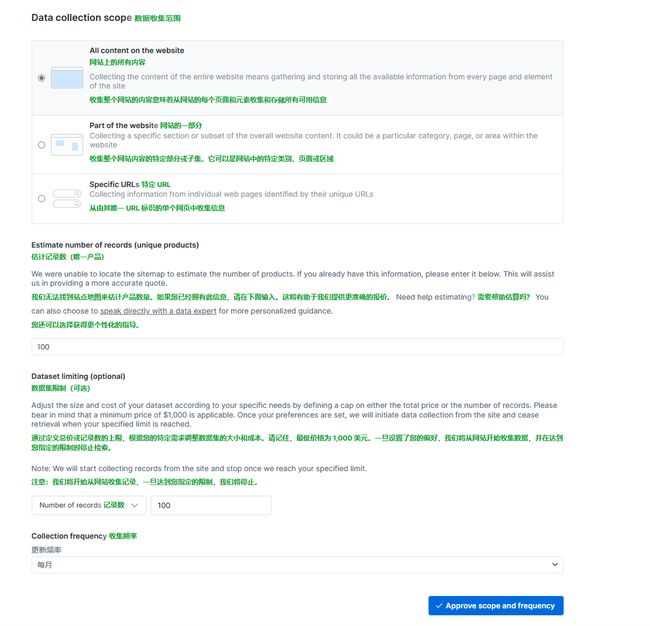
点击提交,之后你可以对爬取到的数据进行直接下载。
更多内容直接注册亮数据即可免费试用:https://get.brightdata.com/szx9v3lbk0ty
点击注册免费试用